Sample-Efficient Reinforcement Learning: Maximizing Signal Extraction in Sparse Environments
Sample efficiency is a huge problem in reinforcement learning. Popular general-purpose algorithms, such as vanilla policy gradients, are effectively performing random search in the environment1, and may be no better than Evolution Strategies, which is more explicit about acting random (I mean, c’mon). The sample-efficiency problem is exacerbated when environments contain sparse rewards, such as when it consists of just a binary signal indicating success or failure.
To be clear, the reward signal is an integral design parameter of a reinforcement learning environment. While it’s possible to engage in reward shaping (indeed, there is a long line of literature on just this topic!) the problem is that this requires heavy domain-specific engineering. Furthermore, humans are notoriously bad at specifying even our own preferences; how do we expect us to define accurate reward functions in complicated environments? Finally, many environments are most naturally specified by the binary success signal introduced above, such as whether or not an object is inserted into the appropriate goal state.
I will now summarize two excellent papers from OpenAI (plus a few Berkeley people) that attempt to improve sample efficiency in reinforcement learning environments with sparse rewards: Hindsight Experience Replay (NIPS 2017) and Overcoming Exploration in Reinforcement Learning with Demonstrations (ICRA 2018). Both preprints were updated in February so I encourage you to check the latest versions if you haven’t already.
Hindsight Experience Replay
Hindsight Experience Replay (HER) is a simple yet effective idea to improve the signal extracted from the environment. Suppose we want our agent (a simulated robot, say) to reach a goal \(g\), which is achieved if the configuration reaches the defined goal configuration within some tolerance. For simplicity, let’s just say that \(g \in \mathcal{S}\), so the goal is a specific state in the environment.
When the robot rolls out its policy, it obtains some trajectory and reward sequence
\[(s_0, a_0, r_0, s_1, a_1, r_1, \ldots, s_{T-1}, a_{T-1}, r_{T-1}, s_{T}) \sim \pi_b, P, R\]achieved from the current behavioral policy \(\pi_b\), internal environment dynamics \(P\), and (sparse) reward function \(R\). Clearly, in the beginning, our agent’s final state \(s_T\) will not match the goal state \(g\), so that all the rewards \(r_t\) are zero (or -1, as done in the HER paper, depending on how you define the “non-success” reward).
The key insight of HER is that during those failed trajectories, we still managed to learn something: how to get to the final state of the trajectory, even if it wasn’t what we wanted. So, why not use the actual final state \(s_T\) and treat it as if it was our goal? We can then add the transitions into the experience replay buffer, and run our usual off-policy RL algorithm such as DDPG.
In OpenAI’s recent blog post, they have a video describing their setup, and I encourage you to look at the it along with the paper website — it’s way better than what I could describe. I’ll therefore refrain from discussing additional HER algorithmic details here, apart from providing a visual which I drew to help me better understand the algorithm:
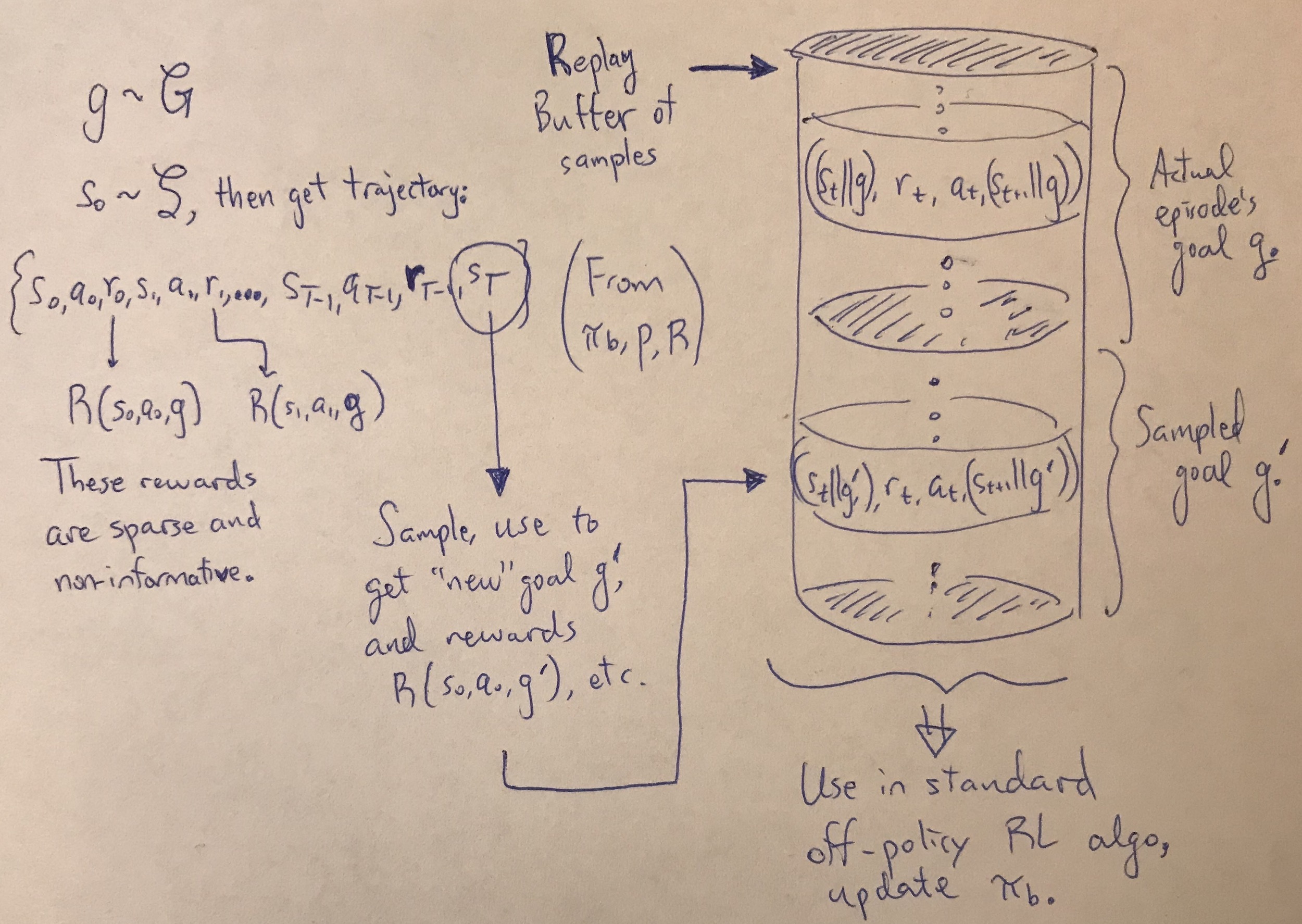
My visualization of Hindsight Experience Replay.
There are a number of experiments that demonstrate the usefulness of HER. They perform experiments on three simulated robotics environments and then on a real Fetch robot. They find that:
-
DDPG with HER is vastly superior to DDPG without HER.
-
HER with binary rewards works better than HER with shaped rewards (!), providing additional evidence that reward shaping may not be fruitful.
-
The performance of HER depends on the sampling strategy for goals. In the example earlier, I suggested using just the last trajectory state \(s_T\) as the “fake” goal, but (I think) this would mean the transition \((s_{T-1},a_{T-1},r_{T-1},s_T)\) is the only one which contains the dense reward \(r_{T-1}\); there would still be \(T-1\) other states with the non-informative reward. There are alternative strategies, such as sampling more frequent states. However, doing this too much has a downside in that “fake” goals can distract us from our true objective.
-
HER allows them to transfer a policy trained on a simulator to a real Fetch robot.
Overcoming Exploration in Reinforcement Learning with Demonstrations
This paper extends HER and benchmarks using similar environments with sparse rewards, but their key idea is that instead of trying to randomly explore with RL algorithms, we should use demonstrations from humans, which is safer and widely applicable.
The idea of combining demonstrations and supervised learning with reinforcement learning is not new, as shown in papers such as Deep Q-Learning From Demonstrations and DDPG From Demonstrations. However, they show several novel, creative ways to utilize demonstrations. Their algorithm, in a nutshell:
-
Collect demonstrations beforehand. In the paper, they obtain them from humans using virtual reality, which I imagine will be increasingly available in the near future. This information is then put into a replay buffer for the demonstrator data.
-
Their reinforcement learning strategy is DDPG with HER, with the basic sampling strategy (see discussion above) of only using the final state as the new goal. The DDPG+HER algorithm has its own replay buffer.
-
During learning, both replay buffers are sampled to get the desired proportion of supervisor data and data collected from environment interaction.
-
For the actor (i.e., policy) update in DDPG, they add the Behavior Cloning loss in addition to the normal gradient update for DDPG (function denoted as \(J\)):
\[\lambda_1 \nabla_{\theta_\pi}J - \lambda_2 \nabla_{\theta_\pi} \left\{ \sum_{i=1}^{N_D}\|\pi(s_i|\theta_\pi ) - a_i\|_2^2 \right\}\]I can see why this is useful. Notice, by the way, that they are not just using the demonstrator data to initialize the policy. It’s continuously used throughout training.
-
There’s one problem with the above: what if we want to improve upon the demonstrator performance? The behavior cloning loss function prevents this from happening, so instead, we can use the Q-filter, a clever contribution:
\[L_{BC} = \sum_{i=1}^{N_D}\|\pi(s_i|\theta_\pi ) - a_i\|_2^2 \cdot \mathbb{1}_{\{Q(s_i,a_i)>Q(s_i,\pi(s_i))\}}.\]The critic network determines \(Q\). If the demonstrator action \(a_i\) is better than the current actor’s action \(\pi(s_i)\), then we’ll use that term in the loss function. Note that this is entirely embedded within the training procedure: as the critic network \(Q\) improves, we’ll get better at distinguishing which terms to include in the loss function!
-
Lastly, they use “resets”. I initially got confused about this, but I think it’s as simple as occasionally starting episodes from within a demonstrator trajectory. This should increase the presence of relevant states and dense rewards during training.
I enjoyed reading about this algorithm. It raises important points about how best to interleave demonstrator data within a reinforcement learning procedure, and some of the concepts here (e.g., resets) can easily be combined with other algorithms.
Their experimental results are impressive, showing that with demonstrations, they outperform HER. In addition, they show that their method works on a complicated, long-horizon task such as block stacking.
Closing Thoughts
I thoroughly enjoyed both of these papers.
-
They make steps towards solving relevant problems in robotics: increasing sample efficiency, dealing with sparse rewards, learning long-horizon tasks, using demonstrator data, etc.
-
The algorithms are not insanely complicated and fairly easy to understand, yet seem effective.
-
HER and some of the components within the “Overcoming Exploration” (OE) algorithm are modular and can easily be embedded into well-known, existing methods.
-
The ablation studies appear to be done correctly for the most part, and asking for more experiments would likely be beyond the scope of a single paper.
If there are any possible downsides, it could be that:
-
The HER paper had to cheat a bit on the pick-and-place environment by starting trajectories from when the gripper grips the block.
-
In the OE paper, their results which benchmark against HER (see Section 6.A, 6.B) were done with only one random seed, and that’s odd given that it’s entirely in simulation.
-
Their OE claim that the method “can be done on real robot” needs additional evidence. That’s a bold statement. They argue that “learning the pick-and-place task takes about 1 million timesteps, which is about 6 hours of real world interaction time” but does that mean we can really execute the robot that often in 6 hours? I’m not seeing how the times match up, but I guess they didn’t have enough space to describe this in detail.
For both papers, I was initially disappointed that there wasn’t code available. Fortunately, that has recently changed! (OK, with some caveats.) I’ll go over that in a future blog post.
-
I’m happy to see that Professor Ben Recht has a new batch of reinforcement learning blog posts, as he’s a brilliant, first-rate machine learning researcher. I’ve been devouring these posts, and I remain amused at his perspective on control theory versus reinforcement learning. He has a point in that RL seems silly if we deliberately constrain the knowledge we can provide to the environment (particularly with model-free RL). For instance, we wouldn’t deploy airplanes and other machines today without a deep understanding of the physics involved. But those are thoughts for another day. ↩