Paper Notes: Learning to Teach
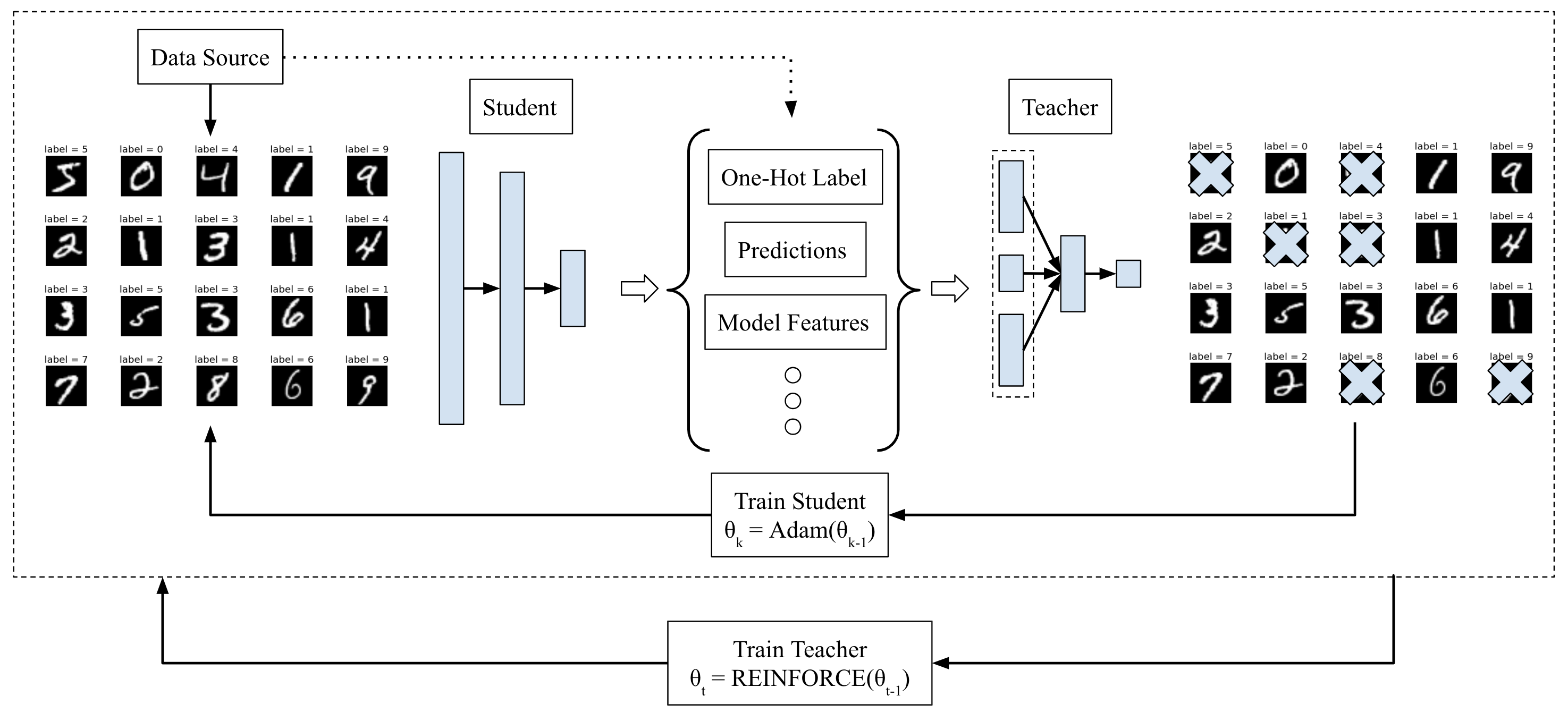
My overview of the "Learning to Teach" pipeline, using their example of
classifying MNIST images. The pipeline first samples a minibatch of data from
MNIST, and passes it through the student network to obtain statistics such as
the predicted class probabilities, the loss function value, and so on. No
training is done yet. The student architecture, incidentally, is a fully
connected 784-500-10 network. Then, these predictions, along with other
meta-data (e.g., training iteration number, one-hot vector labels, etc.) are
concatenated (shown in the dashed rectangle) and passed as input to the teacher
network, which determines whether to keep or reject the sample in the minibatch.
The teacher's architecture is (in the case of MNIST classification) a fully
connected 25-12-1 network. Only the non-rejected samples are used for the
purposes of updating the student network, via Adam gradient updates. Finally,
after a few updates to the student, the teacher network is adjusted using the
REINFORCE policy gradient rule, with a sparse reward function based on how soon
the student achieves a pre-defined accuracy threshold. Once the teacher and
student have been sufficiently trained, the teacher network can then be deployed
on other students --- even those with different neural network architectures and
testing on different datasets --- to accelerate learning.
Sorry for the post-free month — I was consumed with submitting to ICRA 2019 for the last two months, so I am only now able to get back to my various blogging and reading goals. As usual, one way I tackle both is by writing about research papers. Hence, in this post, I’ll discuss an interesting, unique paper from ICLR 2018 succinctly titled Learning to Teach. The OpenReview link is here, where you can see the favorable reviews and other comments.
Whereas standard machine learning investigates ways to better optimize an agent attempting to attain good performance for some task (e.g., classification accuracy on images), the machine teaching problem generally assumes the agent — now called the “learner” — is running some fixed algorithm, and the teacher must figure out a way to accelerate learning. Professor Zhu at Wisconsin has a nice webpage that summarizes the state of the art.
In Learning to Teach, the authors formalize their two player setup, and propose to train the teacher agent by reinforcement learning with policy gradients (the usual REINFORCE estimator). The authors explain the teacher’s state space, action space, reward, and so on, effectively describing the teaching problem as an MDP. The formalism is clean and well-written. I’m impressed. Kudos to the authors for clarity! The key novelty here must be that the teacher is updated via optimization-based methods, rather than heuristics or rules as in prior work.
The authors propose three ways the teacher can impact the student and accelerate its learning:
- Training data. The teacher can decide which training data to provide to the student. This is curriculum learning.1
- Loss function. The teacher can design an appropriate loss for the student to optimize.
- Hypothesis space. The teacher can restrict the potential hypothesis space of the student.
These three spaces make sense. I was disappointed, though, upon realizing that Learning to Teach is only about the training data portion. So, it’s a curriculum learning paper where the teacher is a reinforcement learning agent which designs the correct data input for the student. I wish there was some stuff about the other two categories: the loss function and the hypothesis space, since those seem intuitively to be much harder (and interesting!) problems. Off the top of my head, I know the domain agnostic meta learning (RSS 2018) and evolved policy gradients (NIPS 2018) papers involve changing loss functions, but it would be nice to see this in a machine teaching context.
Nonetheless, curriculum learning (or training data “scheduling”) is an important problem, and to the credit of the authors, they try a range of models and tasks for the student:
- MLP students for MNIST
- CNN students for CIFAR-10
- RNN students for text understanding (IMDB)
For the curriculum learning aspect, the teacher’s job is to filter each minibatch of data so that only a fraction of it is actually used for the student’s gradient updates. (See my figure above.) The evaluation protocol involves training the teacher and student interactively, using perhaps half of the dataset. Then, the teacher can be deployed to new students, with two variants: to students with the same or different neural network architecture. This is similar to the way the Born Again Neural Networks paper works — see my earlier blog post about it. Evaluation is based on how fast the learner achieves certain accuracy values.
Is this a fair protocol? I think so, and perhaps it is reflective of how teaching works in the real world. As far as I understand, for most teachers there is an initial training period before they are “deployed” on students.
I wonder, though, if we can somehow (a) evaluate the teacher while it is training, and (b) have the teacher engage in lifelong learning? As it is, the paper assumes the teacher trains and then is fixed and deployed, and hence the teacher does not progressively improve. But again, using a real-life analogy, consider the PhD advisor-student relationship. In theory, the PhD advisor knows much more and should be teaching the student, but as time goes on, the advisor should be learning something from its interaction with the student.
Some comments are in order:
-
The teacher features are heavily hand-tuned. For example, the authors pass in the one-hot vector label and the predicted class probabilities of each training input. This is 20 dimensions total for the two image classification tasks. It makes sense that the one-hot part isn’t as important (as judged from the appendix) but it seems like there needs to be a better way to design this. I thought the teacher would be taking in features from the input images so it could “tell” if they were close to being part of multiple classes, as is done in Hinton’s knowledge distillation paper. On the other hand, if Learning to Teach did that, the teachers would certainly not be able to generalize to different datasets.
-
Policy gradients is nothing more than random search but it works here, perhaps since (a) the teacher neural network architecture size is so small and (b) the features heavily are tuned to be informative. The reward function is sparse, but again, due to a short (unspecified) time horizon, it works in the cases they try, but I do not think it scales.
-
I’m confused by these sudden spikes in some of the CIFAR-10 plots. Can the authors explain those? It makes me really suspicious. I also wish the plots were able to show some standard deviation values because we only see the average over 5 trials. Nonetheless, the figures certainly show benefits to teaching. The gap may additionally be surprising due to the small teacher network and the fact that datasets like MNIST are simple enough that, intuitively, teaching might not be necessary.
Overall, I find the paper to be generally novel in terms of the formalism and teacher actions, which makes up for perhaps some simplistic experimental setups (e.g., simple teacher, using MNIST and CIFAR-10, only focusing on data scheduling) and lack of theory. But hey, papers can’t do everything, and it’s above the bar for ICLR.
I am excited to see what research will build upon this. Some other papers on my never-ending TODO list:
- Iterative Machine Teaching (ICML 2017)
- Towards Black-box Iterative Machine Teaching (ICML 2018)
- Learning to Teach with Dynamic Loss Functions (NIPS 2018)
Stay tuned for additional blog posts about these papers!
-
Note that in the standard reference to curriculum learning (Bengio et al., ICML 2009), the data scheduling was clearly done via heuristics. For instance, that paper had a shape recognition task, where the shapes were divided into easy and hard shapes. The curriculum was quite simple: train on easy shapes, then after a certain epoch, train on the hard ones. ↩