Uncertainty in Artificial Intelligence (UAI) 2017, Day 1 of 5
Sadly, the day did not start out well. When I opened my inbox this morning (August 11), I saw this from the transcription agency which was supposed to (spoiler alert!) provide captioning services:
Hi Daniel,
Thank you for the confirmation. As at 9:00pm yesterday we were still awaiting confirmation of the details and were not sure that the stenographer was still required for today. As such, it is unlikely that [name redacted] will make it to the venue today. I have spoken with her this morning and she will be there ready to go on Tuesday morning.
I have passed on the information below and [name redacted] has your phone no.
I am very sorry that we are not able to cover the captions for today. It has been difficult, with the lack of communication this week, to know what was happening.
Good luck with today.
Ouch. Where to begin?
I had carefully arranged for captioning services to be arranged for this conference. I looked at my email records. On June 15 I sent an email to Berkeley’s DSP, and received acknowledgement from them that same day, that we should arrange for accommodation services (either captioning or sign language interpreting). The conference, as you know, starts August 11. That’s almost two months. And the paper got accepted on June 12 so I couldn’t have known I would be attending UAI before June 12.
A month later, on July 15, I had sent (and again, received acknowledgment from them) the day and times of the talks, which included August 11. I’m not sure if the exact rooms had been set up, but at least the times were known. And of course, we all knew that UAI was in the ICC Sydney building. Once again, I couldn’t send this email earlier since the schedule was not available on the conference website until then.
Thus, on July 15, I thought that the captioning services were essentially set up. Indeed, after I had repeatedly questioned Berkeley’s DSP, they sent me this email on August 3 which implied that things were OK:
Moving forward. The CART provider(s?) are booked, and I’ve passed the schedule updates along.
I’ll put you in touch with them before the end of the week to discuss details and logistics, as well as prep materials if possible.
Yet on August 11, the day the conference began … I got that email above. Gee, doesn’t that directly contradict the August 3 email from Berkeley’s DSP? I double checked, and the schedule I sent to them on or before that day definitely included August 11, not to mention that I explicitly included August 11 in the written portion of the email (and not in an attachment).
I was also intrigued by the fact that the transcription agency emailed me directly about this, but didn’t do so until late at night on August 10 (and I had gone to sleep early due to jetlag). Why didn’t they email me so sooner? It’s also not like my contact information is completely invisible; a simple Google search of my name (even if it’s from Australia) should have this blog as the #1 hit. Moreover, I saw an email thread between Berkeley’s DSP and the transcription agency that went back a few days which was forwarded to me on the morning of August 11. It appears that the transcription agency was aware of my email on or before August 9 (to be fair, I’m not sure the time zone). Somewhere, there must have been some massive mis-communication.
Yeah. I got completely blindsided.
I think back to my previous grievances with accommodations: see here for my prelims and here for the BAIR retreat. One thing that would especially help in these cases is if I could directly contact the agencies providing those accommodations.
After I return to Berkeley, I am going to talk to DSP and demand that for future conferences, I am able to contact whatever captioning (or sign language interpreting) agency they use. I will always copy Berkeley’s DSP to these emails, and DSP is certainly free to email and/or talk to them so long as they always copy me in emails and give me the details of any phone conversation. Always.
If they refuse, then I will figure out how to sue DSP.
In addition, I will switch to figuring out how to get an automated captioning system set up on my laptop for future conferences as I have lost interest in the hassle of setting up accommodations.
In a foul mood, I trudged over to the room of the talk (see picture below) and hoped for the best.
 The room where the tutorials were located. This was actually taken after the
first tutorial, but I decided to put this picture first in the blog post because
... artistic license.
The room where the tutorials were located. This was actually taken after the
first tutorial, but I decided to put this picture first in the blog post because
... artistic license.
Tutorial 1 of 4
Fortunately, my mood soon brightened once the first talk began at around 8:45am, featuring Assistant Professor John Duchi of Stanord University. He’s known as a machine learning rockstar. I’ve always wondered how he is able to produce so much mathematical research and have time for pursuing other physical activities such as running and participating in triathlons. (When I was applying to graduate school, he told me he was considering accepting the University of Washington’s faculty position, and I sheepishly thought that I could be one of his students there.) I knew I was in for some great content, and on the plus side, his voice is relatively easy to understand. I took a lot of notes (in Google Docs) of his talk. It was divided into two parts: convex optimization and non-convex optimization. Yeah, not the most creative division, but it’s the content that matters.
He started by providing some basic definitions of convex optimization and so forth. Given my background in EE 227BT and EE 227C in Berkeley, I was fortunately aware of this material. Nonetheless, I was happy he went over the concepts slowly. He introduced us to the style of convergence proofs that people use in his sub-field, which often involves relating expressions of the form \(\|x_{k+1}-x^\star\|_2\) and \(\|x_k-x^\star\|_2\).
John then moved on to discuss interesting topics ranging from AdaGrad — which is probably his most well-known research contribution — and about how to transform non-convex problems into convex problems, which is a technical way of saying “let’s make the hard problems easy.” Along the way, he inserted some humor here and there. For instance, when talking about the slide in the following image, John referred to the function as “Batman”:
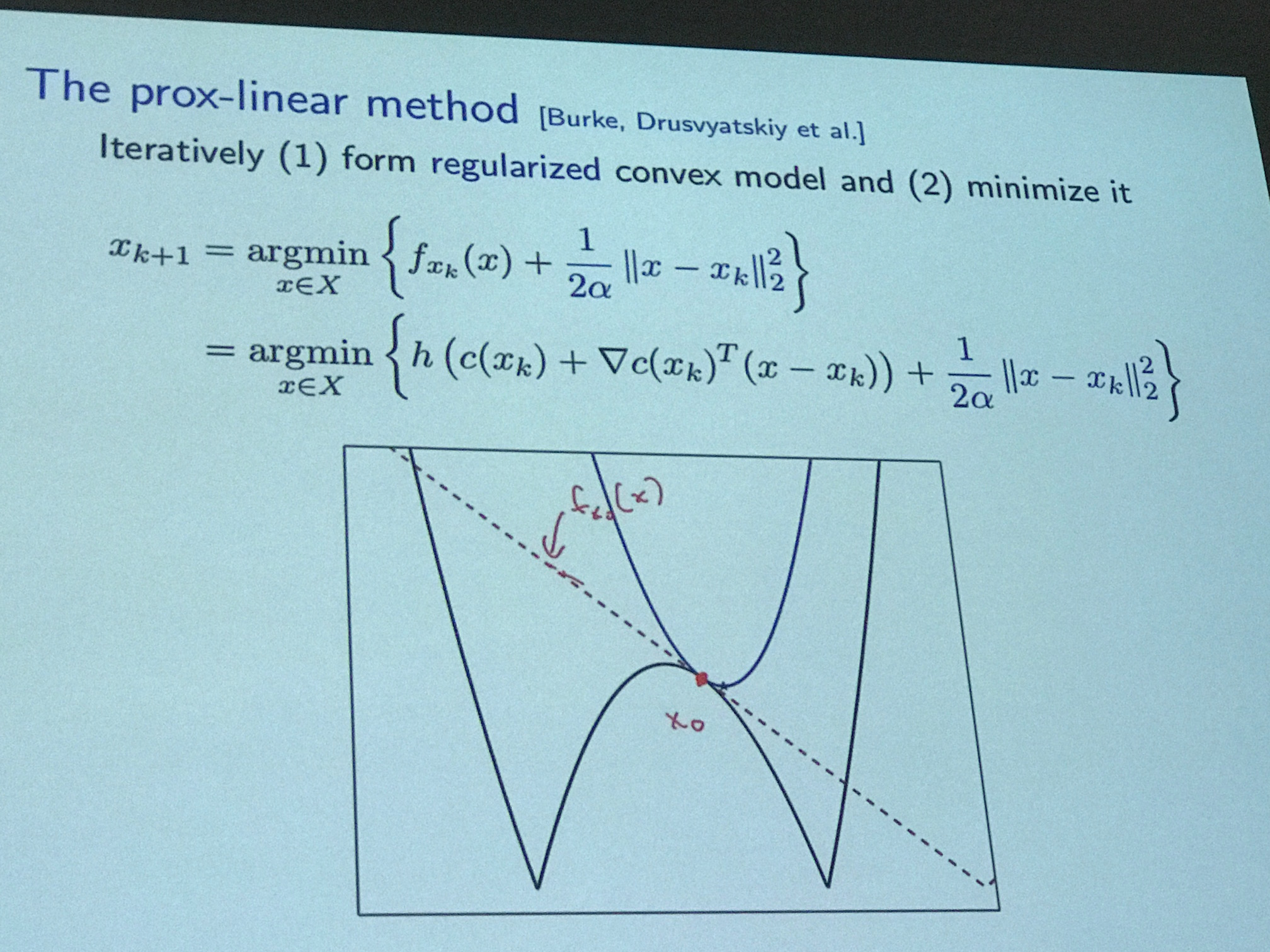 The "Batman function", according to John Duchi.
The "Batman function", according to John Duchi.
Because, hey, doesn’t that look like Batman, he asked rhetorically. John then said he was watching too much Batman. I must have misheard because I don’t believe that one iota.
There were a lot of references to go through in the last few slides. I hope to skim a few of them to get a feel for the work, but unfortunately John hasn’t posted the slides online anywhere. But I remember that a lot of them were his own papers anyway.
Tutorial 2 of 4
After a quick coffee break (thanks but no thanks, that lovely cappuccino from the hotel’s buffet was more than enough to keep me awake), the second speaker, Arthur Gretton, gave his talk on comparing probability distributions. The main idea: given samples from two distributions \(P\) and \(Q\), do the two distributions differ? In addition, what can we learn about these distributions, and can we figure out their dependency relationship? Many interesting questions arise out of this, and anyone who has been following machine learning seriously should know that problem of trying to distinguish between samples from two probability distributions is precisely what the Discriminator tries to do in Generative Adversarial Networks.
 Anything GAN-related is going to catch my attention!
Anything GAN-related is going to catch my attention!
Indeed, Gretton discussed GANs for a few slides, and in fact I think he may have talked more about GANs than Shakir and Danilo did in their Deep Generative Models tutorial later in the afternoon. However, GANs weren’t the entirety of the talk. Much of it was dedicated to some of the technical details regarding “Maximum Mean Discrepancy” and other metrics for comparing distributions.
Unfortunately, I couldn’t really follow the talk. Aside from the stuff on GANs, and even not entirely that — I don’t know how Wasserstein GANs work, for instance — I barely understood what was going on at the technical level. Yes, I know the talk is about distinguishing between two distributions, and yes that’s obviously useful. I just didn’t get the technical gist of the talk.
On top of it all, I could not understand the speaker’s voice despite sitting in literally the seat which was located closest to where he was talking.
Tutorial 3 of 4
The third talk was the one I was most excited about: Deep Generative Models, presented by Shakir Mohamed (blog) and Danilo Rezende (blog), both of whom are research scientists at Google DeepMind, and both of whom have excellent blogs. I hope that mine will soon be as useful to machine learning researchers as theirs are!
 The speakers do some last-minute discussion before giving their joint. Gal
Elidan (to the right) is one of the conference organizers.
The speakers do some last-minute discussion before giving their joint. Gal
Elidan (to the right) is one of the conference organizers.
Danilo took over the first half of the talk and gave a long, borderline overkill motivation for why we like generative models, but I liked the examples and it’s important to try and sell one’s research. For the more technical part of the talk, he discussed fully observed and latent variable generative models, and frequently compared different sub-approaches with pros and cons of each. Unfortunately I wasn’t too familiar with many of these models, and I couldn’t understand his voice, so I didn’t get much out of this.
I benefited more from Shakir’s half of the talk since he was relatively easier for me to understand. (By the way, I have to reiterate that when I talk about not understanding speakers, it’s emphatically not a criticism of them but simply a limitation of what I can understand given my hearing limitations.) Shakir was extremely engaged and talked about the score function estimator and the reparameterization trick, both of which are featured on his blog and which I had previously read beforehand. It was also nice for Shakir to discuss all the ways in which people name these; I learned that Radon-Nikodym derivatives are another way of referring to the policy gradient used in REINFORCE (i.e. Vanilla Policy Gradients).
I certainly think I learned more about the big picture of deep generative models after Shakir’s half, so the talk was on the whole positive for me.
Tutorial 4 of 4
The fourth and last tutorial for the day was about Machine Learning in Healthcare. In general, health care-related talks don’t have much to do with the majority of UAI papers, but the plus side is that they’re much more readily applicable to the real world. And, y’know, that’s important!!
Unfortunately, due to visa issues, Suchi Saria (the speaker) couldn’t attend the tutorial. Thus, her talk was pre-recorded and provided as a video. I stuck around for the first few slides, but unfortunatey, I couldn’t understand what she was saying. It would have been hard enough to understand her in person, but having it via video made it even worse. The slides were informative, but the material isn’t related to my research. Thus, I quietly left the talk after the first few slides, took a seat with a nice view of Darling Harbour, and got to work on my blog.
 The fourth speaker couldn't attend due to visa issues, so her talk was
pre-recorded.
The fourth speaker couldn't attend due to visa issues, so her talk was
pre-recorded.
But in all fairness, put yourself in my shoes. I think if you were someone who could not understand what a speaker was saying and had the choice between sitting for an hour to listen to a pre-recorded talk that wasn’t in your area of research, I think you would do the same.