What is the Right Fabric Representation for Robotic Manipulation?
As many readers probably know, I am interested in robotic fabric manipulation. It’s been a key part of my research – see my Google Scholar page for an overview of prior work, or this BAIR Blog post for another summary. In this post, I’d like to discuss two of the three CoRL 2021 papers on fabric manipulation. The two I will discuss propose Visible Connectivity Dynamics (VCD) and FabricFlowNet (FFN), respectively. Both rely on SoftGym simulation, and my blog post here about the installation steps seems to be the unofficial rule book for its installation. Both papers approach fabric manipulation using quasi-static pick-and-place actions.
However, in addition to these “obvious” similarities, there’s also the key issue of representation learning. In this context, I view the term “representation learning” as referring to how a policy should use, process, and reason about observational data of the fabric. For example, if we have an image of the fabric, do we use it directly and propagate it through the robotic learning system? Or do we compress the image to a latent variable? Or do we use a different representation? The VCD and FFN papers utilize different yet elegant approaches for representation learning, both of which can lead to more efficient learning for robotic fabric manipulation. Let’s dive into the papers, shall we?
Visible Connectivity Dynamics
This paper (arXiv) proposes the Visible Connectivity Dynamics (VCD) model for fabric manipulation. This is a model-based approach, and it uses a particle-based representation of the fabric. If the term “particle-based” is confusing, here’s a representative quote from a highly relevant paper:
Our approach focuses on particle-based simulation, which is used widely across science and engineering, e.g., computational fluid dynamics, computer graphics. States are represented as a set of particles, which encode mass, material, movement, etc. within local regions of space. Dynamics are computed on the basis of particles’ interactions within their local neighborhoods.
You can think of particle-based simulation as discretizing items into a set of particles or “atoms” (in simulation, they look like small round spheres). An earlier ICLR 2019 paper by the great Yunzhu Li shows simulation of particles that form liquids and rigid objects. With fabrics, a particle-based representation can mean representing fabric as a grid of particles (i.e., vertices) with bending, shearing, and stiffness constraints among neighboring particles. The VCD paper uses SoftGym for simulation, which is built upon NVIDIA Flex, which uses position-based dynamics.
The VCD paper proposes to tackle fabric smoothing by constructing a dynamics model over the connectivity of the visible portion of the cloth, instead of the entire part (the full “mesh”). The intuition is that the visible portion will include some particles that are connected to each other, but also particles that are not connected to each other and just happen to be placed nearby due to some folds or wrinkles. Understanding this connectivity structure should then be useful for planning smoothing. While this is a simplification of the full mesh prediction problem and seems like it would throw away information, it turns out this is fine for smoothing and in any case is much easier to learn than predicting the full mesh’s dynamics.
Each fabric is represented by particles, which is then converted into a graph consisting of the standard set of nodes (vertices/particles) and edges (connections between particles), and the dynamics model over these is a graph neural network (GNN). Here is an overview of the pipeline with the GNN, which also shows a second GNN used for edge prediction:
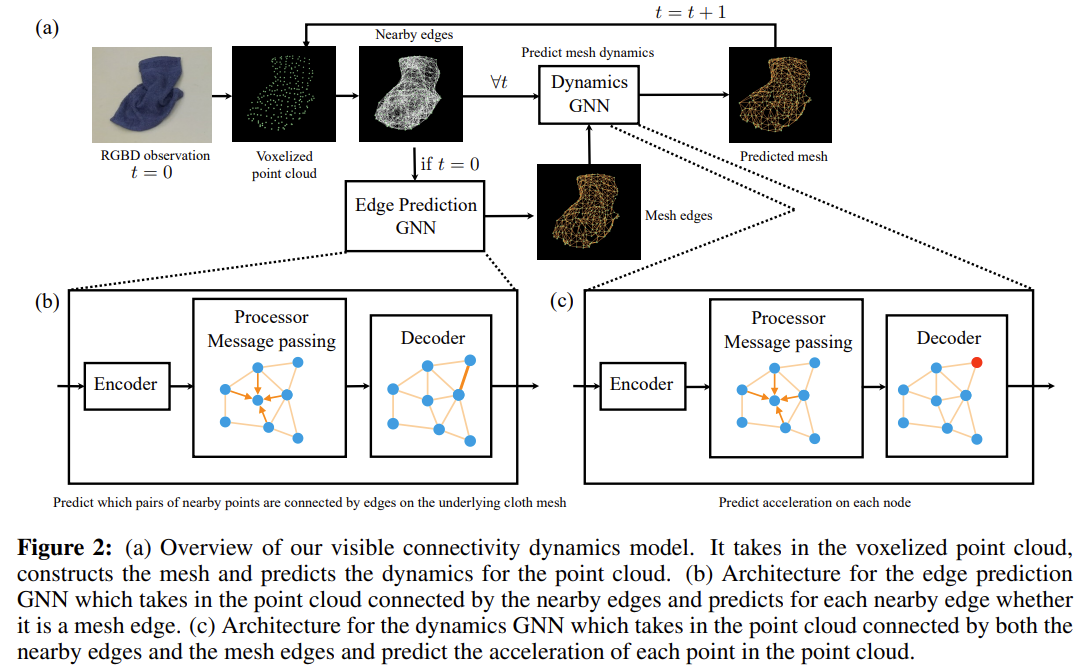
The architecture comes from this paper which simulates fluids, and there a chance that this might also be a good representation for fabric in that it can accurately model dynamics.
To further expand upon the advantages of the particle-based representation, consider that the fabric representation used by the graph dynamics model does not encode information about color or texture. Hence, it seems plausible that the particle-based representation is invariant to such features, and domain randomizing over those might not be necessary. The paper also argues that particles capture the inductive bias of the system, because the real world consists of objects composed of atoms that can be modeled by particles. I’m not totally sure if this translates to accurate real world performance given that simulated particles are much bigger than atoms, but it’s an interesting discussion.
Let’s recap the high-level picture. VCD is model-based, so the planning at test time involves running the learned dynamics model to decide on the best actions. A dynamics model is a function $f$ that given $f(s_t,a_t)$ can predict $s_{t+1}$. Here, $s_t$ is not an image or a compressed latent vector, but the particle-based representation from the graph neural network.
The VCD model is trained in simulation using SoftGym. After this, the authors apply the learned dynamics model with a one-step planner (described in Section 3.4) on a single-arm Franka robot, and demonstrate effective fabric smoothing without any additional real world data. The experiments show that VCD outperforms our prior method, VisuoSpatial Foresight (VSF) and two other works from Pieter Abbeel’s lab (covered in our joint blog post).
While VCD does an excellent job at handling fabric smoothing by smoothing out wrinkles (in large part due to the particle-based representation), it does not do fabric unfolding. This follows almost by construction because the method is designed to reason only about the top layer and thus ignores the part underneath, and knowing the occluded parts seems necessary for unfolding.
FabricFlowNet
Now let us consider the second paper, FabricFlowNet (FFN) which uses the idea of optical flow as a representation for goal-conditioned fabric manipulation, for folding fabric based on targets from goal images (or subgoal images). Here is the visualization:
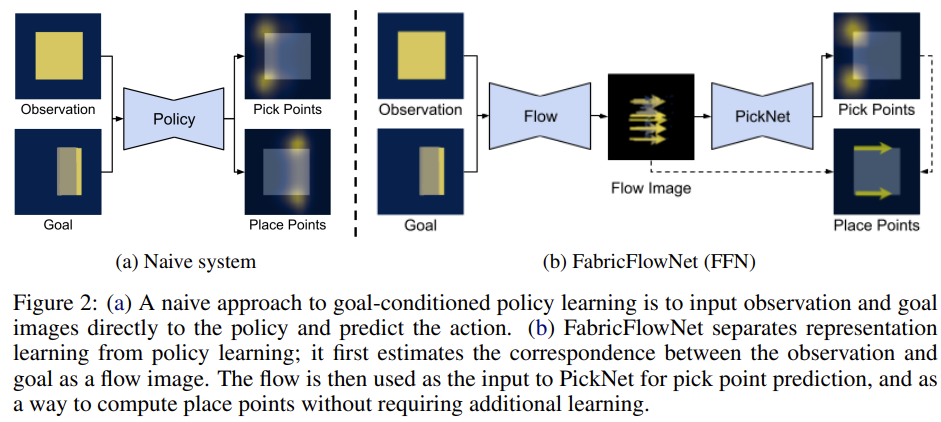
The goal-conditioned setup means they are trying to design a policy \(\pi\) that takes in the current image \(x_t\) and the current sub-goal \(x_i^g\), and produces \(a_t = \pi(x_t, x_i^g)\) so that the fabric as represented in \(x_t\) looks closer to the one represented with \(x_i^g\). They assume access to the subgoal sequence, where the final subgoal image is the ultimate goal.
The paper does not pursue the naive approach where one inputs both the current observation and (sub)goal images and runs it through a standard deep neural network, as done in some prior goal-conditioned work such as our VisuoSpatial Foresight work and my work with Google on Goal-Conditioned Transporter Networks. The paper argues that this makes learning difficult as the deep networks have to reason about the correct action and the interplay between the current and goal observations.
Instead, it proposes a clever solution using optical flow, which is a way of measuring the relative motion of objects in an image. For the purposes of this paper, optical flow should be interpreted as: given an action on a fabric, we will have an image of the fabric before and after the action. For each pixel in the first image that corresponds to the fabric, where will it “move to” in the second image? This is finding the correspondence between two images, which suggests that there is a fundamental relationship between optical flow and dense object neworks.
Optical flow is actually used twice in FFN. First, given the goal and observation image, a flow network predicts a flow image. Second, given pick point(s) on the fabric, the flow image automatically gives us the place point(s).
Both of these offer a number of advantages. First, as an input representation, optical flow can be computed just with depth images (and does not require RGB) and will naturally be invariant to fabric color. All we care about is understanding what happens between two images via their pixel-to-pixel correspondences. Moreover, the labeling for predicting optical flow can be done entirely in simulation, with labels automatically generated in a self-supervised manner. One just has to code a simulation environment to randomly adjust the fabric, and doing so will give us ground truth images of before and after labels. We can then compute optical flow by using the standard endpoint error loss, which will minimize the Euclidean distance of the predicted versus actual correspondence points.
The second, using optical flow to give us placing point(s), has an obvious advantage: it is not necessary for us to design, integrate, and train yet another neural network to predict the placing point(s). In general, predicting a place point can be a challenging problem since we’re regressing to a single pixel, and this can introduce more imprecision. Furthermore, the FFN system decouples the observation-goal relationship and the pick point analysis. Intuitively, his can simplify training, since the neural networks in FFN have “one job” to focus on, instead of two.
There are a few other properties of FabricFlowNet worth mentioning:
-
For the picking network, FFN sub-divides the two pick points into separate networks, since the value of one pick point should affect the value of the other pick point. This is the same idea as proposed in this RSS 2020 paper, except instead of “pick-and-place,” it’s “pick-and-pick” here. In FFN, the networks are also fully convolutional networks, and hence do picking implicitly, unlike in that prior work.
-
An elegant property of the system is that it can seamlessly alternate between single-arm and bimanual manipulation, simply by checking whether the two picking points are sufficiently close to each other. This simultaneously enforces a safety constraint by reducing the chances that the two arms collide.
-
The network is supervised by performing random actions in simulation using SoftGym. In particular, the picking networks have to predict heatmaps. Intuitively, the flow provides information on how to get to the goal, and the picking networks just have to “match heatmaps.”
What is the tradeoff? The system has to assume optical flow will provide a good signal for the placing point. I wonder when this would not hold? The paper also focuses on short-horizon actions (e.g., 1 or 2 actions) starting from flat fabric, but perhaps the method also works for other scenarios.
I really like the videos on the project website – they show a variety of success cases with bimanual manipulation. The experiments show that it’s much better than our prior work on VisuoSpatial Foresight, along with another method that relies on an “FCN-style” approach to fabric manipulation; the idea of this is covered in my prior blog post.
I think this paper will have significant impact and will inspire future work in flow-based manipulation policies.
Concluding Thoughts
Both VCD and FFN show that, with clever representations, we can obtain strong fabric manipulation tasks, outperforming (in some contexts) our prior method VisuoSpatial Foresight, which uses perhaps the most “straightforward” representation of raw images. I am excited to see what other representations might also turn out to be useful going forward.
References:
-
Xingyu Lin*, Yufei Wang*, Zixuan Huang, David Held. Learning Visible Connectivity Dynamics for Cloth Smoothing. CoRL 2021.
-
Thomas Weng, Sujay Bajracharya, Yufei Wang, Khush Agrawal, David Held. FabricFlowNet: Bimanual Cloth Manipulation with a Flow-based Policy. CoRL 2021.