My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
Review of Computer Vision (CS 280) at Berkeley
Last semester, I took Berkeley’s graduate-level computer vision class (CS 280) as part of my course requirements for the Ph.D. program. My reaction to this class in three words: it was great.
Compared to what happened in classes I took last semester, there were a lot fewer cases of head-bashing, mental struggles, and nagging doubts in CS 280. One reason for this favorable outcome is that I eschewed captioning in favor of sign language interpreting, which is the accommodation type I’m most used to experiencing. What may have played an even bigger role than that, however, was the professor himself. The one who taught my class was Professor Jitendra Malik, a senior faculty member who’s been at Berkeley since 1986 and was recently elected to the National Academy of Sciences (congratulations). I realized after the first few classes that he really takes his time when lecturing. He talks relatively slowly, explains things at a high level, and repeatedly asks “Does this make sense?” He is slowest when dissecting math he’s scribbled on the whiteboard. In fact, I was often hoping he would speed up when he was strolling through basic linear algebra review that should have been a prerequisite for taking CS 280. If someone like me wants a faster class pace, that means everyone else must have wanted the same thing!
For obvious reasons, the slow lecture pace was well-suited for the two sign language interpreters who worked during lectures. They sat near where the power point slides were displayed, which made it relatively easy to move my eyes back and forth across the front of the room. As usual, I hope no one else got distracted by the interpreters. Unfortunately, the seat next to mine (I sat on the edge of the first row, no surprise) would remain suspiciously empty for a long time, and would only fill up once all the other seats were occupied save for a few hard-to-reach center ones.
I should warn future CS 280 students: this is a popular graduate-level course, for reasons that will be clear shortly. The auditorium we had was designed to seat about 80-90 people, and we probably had over 100 when the class began. It did eventually drop to 80 — aided by some forced undergraduate drops — but before those drops, the tardy students had to sit on the floor. This is a real problem with Berkeley EECS courses, but I guess the university is short on funds?
Anyway, let’s discuss the work. While the lectures were informative, they did not go in great detail on any topic. Professor Malik, when faced with an esoteric concept he didn’t want to explain, would say “but I won’t explain this because you can read the [academic] paper for yourself, or Wikipedia.” Well, I did use Wikipedia a lot, but the thing that really helped me understand computer vision concepts were the homework assignments. We only had three of them:
-
Homework 1 was a jack-of-all-trades assignment which asked us questions on a wide variety of subjects. The questions were related to perspective projection, rotation analysis (e.g., Rodriguez’s formula), systems of equations, optical flow, and the Canny edge detector, which we had to implement. I think it is too hard to implement the Canny edge detector from the original 1986 paper, and I’m pretty sure most of the students relied on a combination of Wikipedia and other sources to get the algorithm pseudocode. Overall, this homework took a really long time for me to finish (I blame the perspective projection questions), but we did have two weeks to do this, and we all got an extension of a few days.
-
Homework 2 was a smaller assignment that focused on classifying hand-written digits using SVMs (part 1) and neural networks (part 2). The first part was not too bad, as we just had to write some short MATLAB scripts, but the second part, which required us to use the open-source, Berkeley-developed caffe software, probably took everyone a longer time to finish. To put it politely, research software is rarely easy to use1, and caffe is no exception. I could tell that there were a lot of headaches based on the complaints in Piazza! Oh, and I should also mention that caffe had a critical update happen a few days before the deadline, which broke some of the older data format. Be warned, everyone. To no one’s surprise, we all got an extension for this homework after that surprise update.
-
Homework 3 was another small assignment, and it was about reconstructing a 3-D scene using points measured from multiple cameras with different centers. We had to implement a matching algorithm that would match the different coordinate systems to determine the true coordinates of a point. Our online textbook went through the algorithm in detail, so it wasn’t too bad to read the textbook and apply what was there (and possibly supplement with external sources). Unfortunately, this homework’s due date was originally set to be on the same day as the midterm! After some more Piazza complaints (none from me!), we all got yet another extension2.
One thing I didn’t quite like was that Homework 1 took significantly longer than the second one, which took significantly longer than the third one. There wasn’t quite much balance, it seems. On the other hand, we could work in groups of two, which made it easier.
Aside from the homeworks, the other two aspects of our grade were the midterm and the final project. The midterm was in-class, set to be eighty minutes, but the administrative assistant was a little late in printing the tests, so we actually started ten minutes late. Fortunately, Professor Malik gave us five extra minutes, and told us we didn’t have to answer one of the questions (unfortunately, it was one that I could have answered easily). As for the midterm itself, I didn’t like it that much. I felt like it had too many subjective multiple-choice questions (there were some “select the best answer out of the following…”). I don’t mind a few of those, but it’s a little annoying to see thirty percent of the points based on that and to see that you lost points because you didn’t interpret the question correctly. The average score appeared to be about 60 percent.
With regards to my final project, I did enjoy it, even if what I produce almost always falls under initial expectations. I paired up with another student to focus on extracting information from videos, but we basically did two separate projects in parallel and tried to convince the course staff that they could be combined in “future work” in our five-page report. What I did was take YouTube video frames from Eclipse, Excel, Photoshop, or SketchUp videos and trained a neural network (using caffe, of course) to recognize, for a given frame, to which movie it belonged. Thus, the neural network had to solve a four-way classification problem for each frame. The results were impressive: my network got over 95 percent accuracy!
The final project was also enjoyable because each group had to give a five minute presentation to the class. This is better than a poster session because I don’t have to go through the hassle of going to people and saying “Hi, I’m Daniel, can I look at what you did?” One amusing benefit of these class presentations is that I get to learn the names of people in this class; it’s definitely nothing like Williams where we are expected to know our classmates’ names. When I see names that are familiar from Piazza, I think: whoa, that was the person who kept criticizing me!
To wrap it up, I’d like to mention the increasing importance of computer vision as a research field, which is one of the reasons why I took this class. Computer vision is starting to have some life-changing impacts to real life. It has long been used for digit recognition, but with recent improvements, we’ve been able to do better object detection and scene reconstruction. In the future, we will actually have automated cars that use computer vision to track their progress. It’s exciting! (One of my interpreters was terrified at this thought, though, so there will be an “old guard” that tries to stop this.) A lot of progress, as Professor Andrew Ng mentions in this article, is due to the power of combining the ages-old technique of neural networks with the massive amounts of data we have. One of the things that motivated this line of thinking was a 2012 paper published at NIPS, called ImageNet Classification with Deep Convolutional Neural Networks, that broke the ImageNet classification record. It spawned a huge interest in the application of neural networks to solving object detection and classification problems, and hopefully we may end up seeing neural networks become a household name in the coming years.
-
Moses, for statistical machine translation, is also not an exception. It is extremely hard to install and use, as I discussed last November. ↩
-
If there had been a fourth homework assignment, I would have been tempted to say the following on Piazza: “To the TAs/GSIs: I would like to ask in advance how long the incoming homework extension will be for homework four?” ↩
The Joy of Talking To Others
I had a vision of what I wanted to be like before I entered graduate school. Some things have worked out, and others haven’t. One thing that hasn’t — and not necessarily in a bad way — is my changing opinion of how I want to structure my schedule so as to talk to others.
Originally, I wanted to be someone who could hunker down at his desk for sixteen hours a day and tenaciously blast his way through a pesky math or programming problem. I wanted to possess laser-sharp, Andrew Wiles-level focus, and channel it to work on computer science all day without a need to have others hinder my progress with meetings and various requests.
That vision has not become reality. The key factor? I really want to talk to people.
For most of my life, I never viewed myself as “normal.” This was largely a consequence of being deaf and being isolated in social settings. But I am normal in the sense that I thrive on talking and socialization.
My isolation in recent years has made me hungrier and hungrier to socialize, and when I don’t get that opportunity and see people my age establishing new friendships on a regular basis, I relentlessly beat myself up for failing to take the necessary initiative. Is there something they do that I should be doing? Am I not painting the correct impression of myself?
As a result, sometimes those “uninterrupted hours” that I’ve gone through during work have really been “interrupted” by my brain1, which is constantly telling me that I should socialize. Somehow.
My brain will often go further than that, in a peculiar way. I don’t know how common this is with people, but my brain is constantly creating and envisioning fictional social situations involving me. A typical scene will be me and a few other people socializing. Interestingly enough, I will be participating in these conversations much more often than is typical for me, and the other people will be more engaging towards me than usual. That’s it — those are the key commonalities in these scenes. I don’t know … is my brain trying to form what my hope would be for a normal social situation? Is it trying to compensate for some real-life deficiency? This kind of hypothetical scene formation, for lack of a better way to describe it, happens more often when I am in bed and trying to sleep. I will usually go through cycles of social scenes, with an intriguing rotation of settings and conversationalists2.
During the day, I find that if I go too long without talking to someone, these thoughts may appear in a similar form as those that occur in the evening. Recently, they seem to begin when I think about how I’m missing out because I don’t know many people and don’t always have the courage to talk to others. Unfortunately, there’s a paradox: most of the time, when I have tried attending social events, I tend to feel worse. Huh.
One-on-one meetings, of course, are the main exception to this rule. Even if such meetings are not strictly for social purposes (e.g., a student-advisor relationship), I usually feel like they have served a social purpose, and that they fulfill my minimum socialization goal for the day. It’s no surprise that after meetings, my mood improves regardless of the outcome, and I can get back to my work in a saner state.
I think it’s more important for someone like me to have meetings and to talk to others while at work. The rationale is that I don’t get to talk to many people, so any small conversation in which I do participate provides more utility to me as compared to that other person, because he or she will have had more social opportunities throughout the day.
As a result, I now try to stagger my schedule so that, instead of having three days completely free and one day with four meetings, I’ll have one meeting per day. Having just one half-hour meeting can completely change the course of a day by refreshing my “focus” and “motivation” meters so that I can finish up whatever task I need to finish.
You know, for someone who doesn’t socialize much, I sure do think about socialization a lot! Case in point: this short essay! The reason why I am just now writing this post is due to a recent visit at the Rochester Institute of Technology (RIT) to discuss some research with several colleagues. While I was at RIT, I had an incredibly easy time talking with my colleagues in sign language.
More than ever, I appreciate the enormous social benefit of RIT to deaf students. While I may have issues with how RIT handles academic accommodations, it has one thing that no other university can boast: a thriving, intelligent deaf population of computer scientists and engineers. Wouldn’t that be my ideal kind of situation?
My visit to RIT made me again wonder how my life would have been different had I decided to pick RIT for undergrad. Life, however, is full of tradeoffs, and whatever social benefit from going to RIT would have been countered by a possible reduction in my future opportunities. If I had attended RIT, I doubt I would have gotten in the Berkeley Ph.D. program, because the reputation of one’s undergraduate institution plays a huge (possibly unfair) role in determining admission.
I don’t want to suggest that all deaf people can follow my footsteps. I know that the only reason why I had that kind of “choice privilege” to decide between a hearing-oriented versus a hearing-and-deaf-oriented school is that my level of hearing (with hearing aids) and speech are just good enough so that I can thrive in a hearing-dominated setting. By thrive, I mean academically (in most cases); I am always at the bottom of the social totem pole.
When I think about my social situation, I sometimes get angry. Then I react by reminding myself of how lucky I am in other ways. With the exception of hearing, I have a completely functional body with excellent mobility. My brain appears to be working fine and can efficiently process through various computer science problems that I face in my daily work. I live in a reasonably nice apartment in Berkeley, in an area that is reasonably safe. I have a loving family that provides an incredible amount of support to me.
In fact, almost every day since entering college five years ago, I’ve reminded myself of how lucky I am in these (and other) regards. I wish I could say I did this every day, but I’ve forgotten a few times. Shame on me.
I make no illusions. I am really lucky to be able to have conversations with hearing people, and I treasure these moments to what may seem like a ridiculous extent. Not all deaf people can do this on a regular basis. I do get frustrated when I communicate with others and don’t always get the full information.
But it could be a lot worse.
Finished the Wordpress-to-Jekyll Migration
In my last post, I talked about the process of migrating my Wordpress.com blog into this Jekyll blog. I finally finished this process — at least, to the extent where nothing is left but touch-ups — so in this post, I’d like to explain the final migration steps.
The Manual Stuff
Let’s start with the stuff that I put off as long as possible: checking every single post to fix every single blog-to-blog post link and every single image. With 150 posts, this was not the most fun activity in the world.
Due to the transition to Jekyll, the old blog-to-blog links1 that I had in my blog posts
were no longer valid. To fix those up, I went through every single blog post, checked if it
referenced any other blog posts as links, and changed the link by replacing seitad.wordpress.com
with danieltakeshi.github.io. Remember, this is only valid because I changed the Wordpress.org way
of permalinks to match Jekyll’s style. If I had not done that, then this process would have
involved more editing of the links.
I also fixed the images for each post. For each post that uses images, I had to copy the
corresponding file location in my old folder that contained my Wordpress.com images, and paste them
into the assets folder here. Then, I fixed the image HTML in the Markdown file so that they looked
like this:
<img src="https://danieltakeshi.github.io/assets/image_name" alt="some_alt_text">
By keeping all images in the same directory, they have a common “skeleton” which makes life easier,
and image_name is the file name, including any .png, .jpg, etc. stuff. The some_alt_text is
in case the image does not load, so an alternative text will appear in place of the image.
The Interesting Stuff
Incorporating LaTeX into my posts turned out to be easier than expected. Unlike in Wordpress, where
I had to do a clumsy $latex ... $ to get math, in Jekyll + MathJax (which is the tool to
get LaTeX to appear in browsers) I can do $$ ... $$. For example: $$\int_0^1 x^2dx$$ results in
\(\int_0^1 x^2dx\). It does require two extra dollar signs than usual, but nothing is perfect.
Note: to get MathJax, I pasted the following code at the end of my index.html file:
<script type="text/javascript"
src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML">
</script>
There were a few other things I wanted to do after incorporating math, and they also required
modifying index.html:
- To have all the post content appear on the front page rather than only the titles. The latter case forces the user to click on the title to see any of the content.
- To add pages on the home page so that the first page (the default one) would display the 20 most recent posts, then the next page would list the next 20, etc.
To get the post content to appear, in index.html where it loops through the posts in the site,
there is a place where one can post the content by using the post.content variable2. To
get the pages, see this blog post which explains that one needs to add the paginage: X line
in the _config.yml file, where X is clearly the amount of posts per page. Then, one can loop
through the paginator.posts variable to loop through the posts. To get a page counter at the
bottom that lets you jump from page to page, you need to use the paginator.previous_page,
paginator.page, and paginator.next_page variables. Again, see the linked blog post, which
explains it clearly.
The Future
There are certainly a bevy of things I could do to further customize this blog. I’ll probably add some Google Analytics stuff later to track my blog statistics, but I don’t view that as a high priority. Instead, I would like to start writing about more computer science topics.
-
Just to be clear: these are when blog posts link to another blog posts in the text, such as by saying “click HERE to see my earlier statement”, where “HERE” is replaced with the link. ↩
-
It’s also possible to use
post.excerptwhich will only display part of a post on the home page, but I found that it messed up the links within the post. ↩
Seita's Place has Migrated from Wordpress to Jekyll!
A New Era
This post marks the beginning of a new era for my blog. For almost four years (!), which saw 151 posts published (this post is #152), Seita’s Place was hosted by Wordpress.com. Over the past few months, though, I’ve realized that this isn’t quite what I want for the long run. I have now made the decision to switch the hosting platform to Jekyll.
Many people others (e.g., Vito Botta and Tomomi Imura) have provided reasons why they migrated from Wordpress to Jekyll, so you can read their posts to get additional perspectives.
In my case, I:
- wanted to feel like I had more control over my site, rather than writing some stuff and then handing it over to a black-box database to do all the work.
- wanted to write more in Markdown and use git/GitHub more often, which will be useful for me as I continue to work in computer science.
- wanted to more easily be able to write code and math in my posts.
- wanted to use my own personal text editor (vim is my current favorite) rather than Wordpress’s WYSIWYG editor.
- was tired of various advertisements underneath my posts.
- wanted to be more of a hacker and less like the “ignorant masses,” no offense intended =).
Jekyll, which was created by GitHub founder Tom
Preston-Werner1, offers
a splendid blogging platform with minimalism and simplicity in mind. It allows users like me to
write posts in plain text files using Markdown syntax. These are all stored in a _posts file in
the overall blog directory. To actually get the site to appear online, I can host it on my GitHub
account; here is the GitHub repository
for this site2. By default, such sites are set to have a URL at username.github.io, which for me
would be danieltakeshi.github.io. That I can use GitHub to back up my blog was a huge factor in my
decision to switch over to Jekyll for my blog.
There’s definitely a learning curve to using Jekyll (and Markdown), so I wouldn’t recommend it for those who don’t have much experience with command-line shenanigans. But for me, I think it will be just right, and I’m happy that I switched.
How Did I Migrate?
Oh boy. The migration process did not go as planned. I was hoping to get that done in about three hours, but it took me much longer than that, and the process spanned about four days (and it’s still not done, for reasons I will explain later). Fortunately, since the spring semester is over, there is no better time for me to work on this stuff.
Here’s a high-level overview of the steps:
- Migrate from Wordpress.com to Wordpress.org.
- Migrate from Wordpress.org to Jekyll
- Migrate comments using Disqus
- Proofread and check existing posts
The first step to do is one that took a surprisingly long time for me: I had to migrate from Wordpress.com to Wordpress.org. It took me a while to realize that there even was a distinction: Wordpress.com is hosted by Wordpress and they handle everything (including the price of hosting, so it’s free for us), but we don’t have as much control over the site, and the extensions they offer are absurdly overpriced. Wordpress.org, on the other hand, means we have more control over the site and can choose a domain name to get rid of that ugly “wordpress” text in the URL. Needless to say, this makes Wordpress.org extremely common among many professional bloggers and organizations.
In my case, I had been using Wordpress.com for seitad.wordpress.com, so what I had to do was go to
Bluehost, pay to create a Wordpress.org site, which I named
seitad.com, and then I could migrate. The migration process itself is pretty easy once you’ve
got a Wordpress.org site up, so I won’t go into detail on that. The reason why I used Bluehost is
because it’s a recommended Wordpress provider, and on their website there’s a menu option that you
can click to create a Wordpress.org site. Unfortunately, that’s about it for my praise, because I
otherwise really hate Bluehost. Did anyone else feel like Bluehost does almost nothing but shove
various “upgrade feature XXX for $YZ” messages down our throats? I was even misled by their pricing
situation and instead of paying $5 to “host” seitad.com for a month, I accidentally paid $71 to
host that site for a year. I did notice that they had a 30-day money back guarantee, so hopefully
I can hastily finish up this migration and request my money back so so I won’t have to deal with
Bluehost again3.
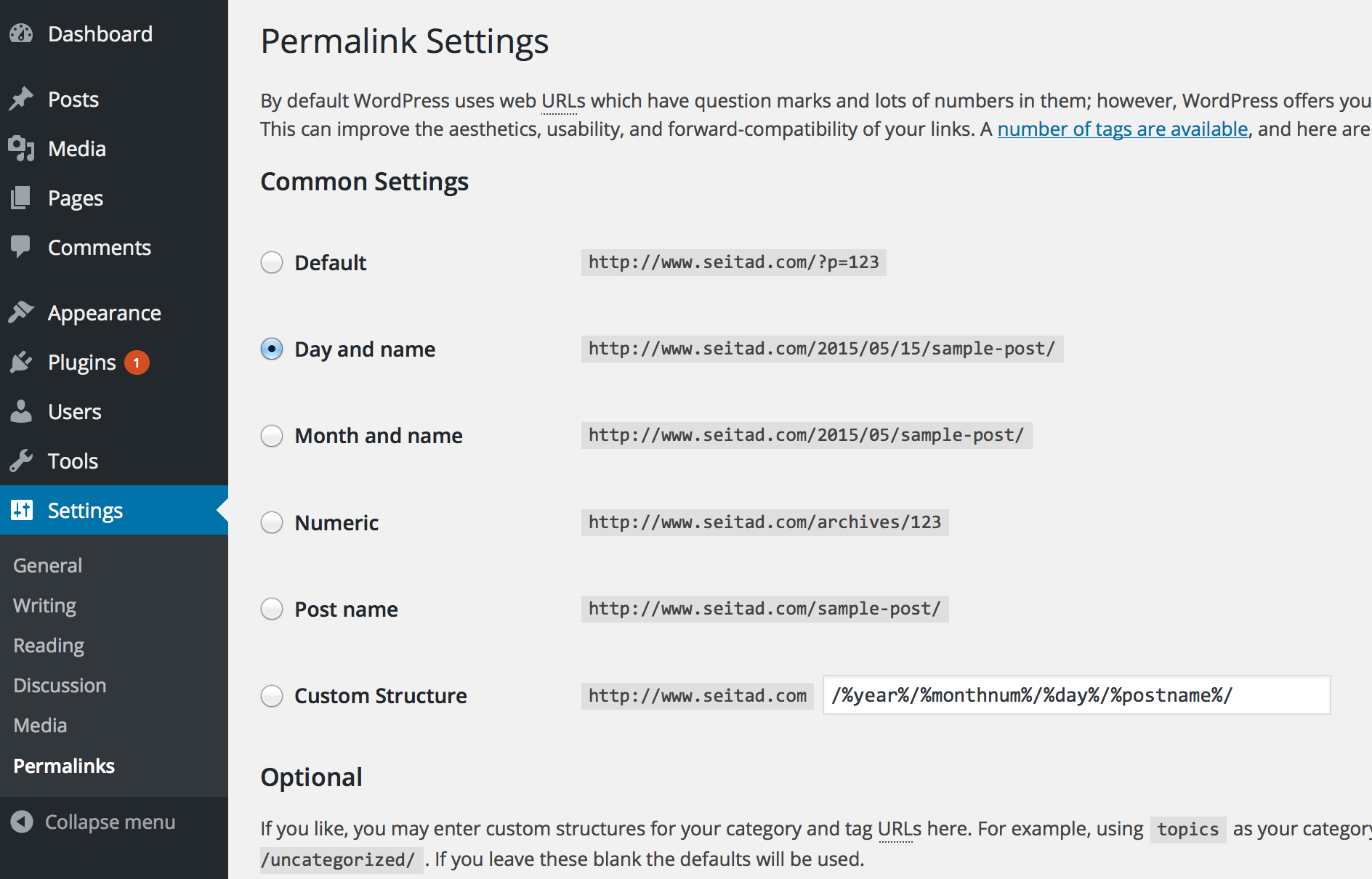
To clarify, the only reason why I am migrating to Wordpress.org is because the next step, using a Wordpress-to-Jekyll exporter plugin, only works on Wordpress.org sites, because Wordpress.com sites don’t allow external plugins to be installed. (Remember what I said earlier about how we don’t have much control over Wordpress.com sites? Case in point!) But before we do that, there’s a critical step we’ll want to do: change the permalinks for Wordpress to conform to Jekyll’s default style.
A permalink is the link extension given to a blog post after the end of the site URL. For
instance, suppose a site has address http://www.address.com. It might have a page called “News”
that one can click on, and that could have address http://www.address.com/news, and news would
be the permalink.
Modifying permalinks is not strictly necessary, but it will make importing comments later easy.
The default Wordpress.org scheme seems like it appends a “p” followed by an integer, and then a
question mark. We want to change it to match Jekyll’s default naming scheme, which is
/year/month/day/title, and we can do that by modifying the “Permalinks” section in the Wordpress
dashboard.
Now let’s discuss that Wordpress-to-Jekyll exporter I recently mentioned. This plugin, created by GitHub staff member Ben Balter, can be found (you guessed it) on GitHub. What you need to do is go to the “Releases” tab and download a .zip file of the code; I downloaded version 2.0.1. Then unzip it and follow the instructions that I’ve taken from the current README file:
- Place plugin in
/wp-content/plugins/folder - Activate plugin in WordPress dashboard
- Select Export to Jekyll from the Tools menu
Steps (2) and (3) shouldn’t need much explanation, but step (1) is the trickiest. The easiest way to
do this is to establish what’s known as an FTP connection to the Wordpress.org server, with the
“host name” field specified by the URL of the old site (in my case, seitad.com). What I did
was download FileZilla, a free FTP provider, and used its
graphical user interface to connect to my Wordpress.org site.
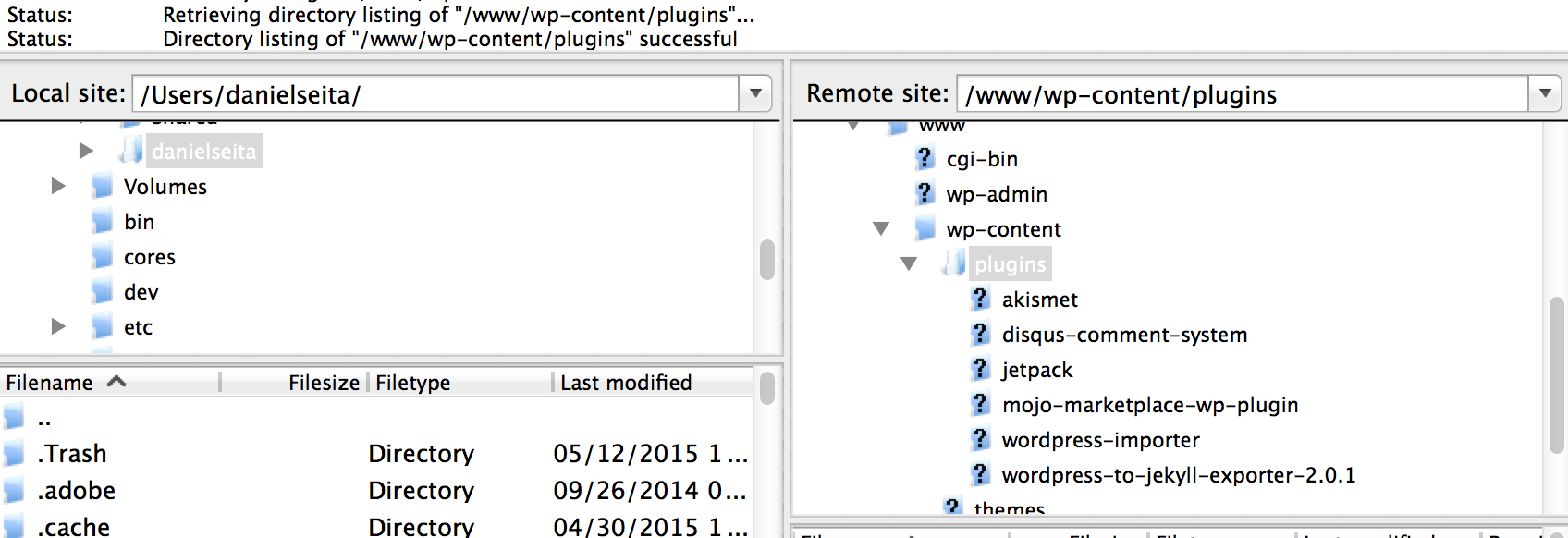
Note that to connect to the site, one does not generally use his or her Wordpress.org’s login, but
instead, one needs to use the login information from Bluehost4! Once I got over my initial
confusion, I was able to “drag and drop” the wordpress-to-jekyll exporter plugin to the Wordpress
site. You can see in the above image (of Filezilla) that I have the plugin in the correct directory
on the remote site. Executing steps (2) and (3) should then result in a jekyll-export.zip file
that contains the converted HTML-to-Markdown information about blog entries, as well as other
metadata such as the categories, tags, etc.
All right, now that we have our zip file, it’s time to create a Jekyll directory with the jekyll new
danieltakeshi.github.io command, where danieltakeshi should be replaced with whatever GitHub
username you have. Then take that jekyll-export.zip file and unzip it in this directory. This
should mean that all your old Wordpress posts are now in the _posts directory, and that they
are converted to Markdown, and that they contain some metadata. The importer will ask if you want
to override the default _config.yml file; I chose to decline that option, so _config.yml was
still set to be what jekyll new ... created for me.
The official Jekyll documentation contains a tool that you can use to convert from Wordpress (or Wordpress.com) to Jekyll. The problem with the Wordpress.com tool is that the original Wordpress.com posts are not converted to Markdown, but instead to plain HTML. Jekyll can handle HTML files, but to really get it to look good, you need to use Markdown. I tried using the Wordpress.org (not Wordpress.com) tool on the Jekyll docs, but I couldn’t get it to work due to missing some Ruby libraries that later caused a series of dependency headaches. Ugh. I think the simplicity and how the posts actually get converted to Markdown automatically are the two reasons why Ben’s external jekyll plugin is so popular among migrators.
At this point, it makes sense to try and commit everything to GitHub to see if the GitHub pages will
look good. The way that the username.github.io site works is that it gets automatically refreshed
each time you push to the master branch. Thus, in your blog directory, assuming you’ve already
initialized a git repository there, just do something like
$ git add .
$ git commit -m "First commit, praying this works..."
$ git push origin master
These commands5 will update the github repository, which automatically updates
username.github.io, so you can refresh the website to see your blog.
One thing you’ll notice, however, is that comments by default are not enabled. Moreover, old comments made on Wordpress.org are not present even with the use of Ben’s Wordpress-to-Jekyll tool. Why this occurs can be summarized as follows: Jekyll generates static pages, but comments are dynamic. So it is necessary to use an external system, which is where Disqus comes into play.
Unfortunately, it took me a really long time to figure out how to import comments correctly. I’ll summarize the mini-steps as follows:
- In the Admin panel for Disqus, create a new website and give it a “shortname” that we will need
later. (For this one, I used the shortname
seitasplace.) - In the Wordpress.org site, install the Disqus comment plugin6 and make sure your comments are “registered” with Disqus. What this means is that you should be able to view all comments in your blog from the Disqus Admin panel.
- Now comes the part that I originally missed, which took me hours to figure out: I had to import the comments with Disqus! It seems a little confusing to me (I mean, don’t I already have comments registered?), but I guess we have to do it. On Disqus, there is a “Discussions” panel, and then there’s a sub-menu option for “Import” (see the following image for clarification). There, we need to upload the .xml file of the Wordpress.org site that contains all the comments, which one can obtain without a plugin by going to Tools -> Export in the Wordpress dashboard.
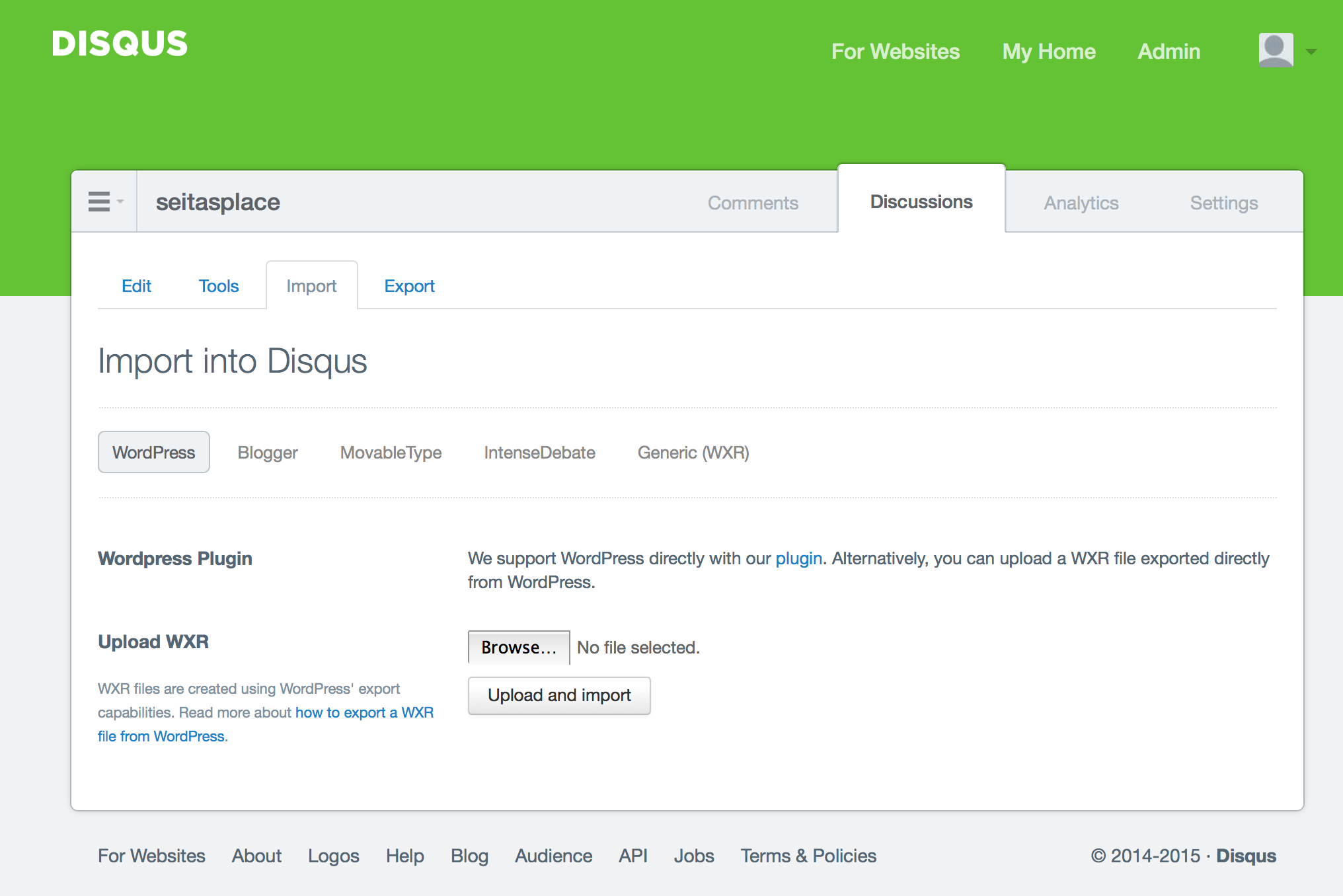
- You will also likely need to do some URL mapping. Comments in Disqus are stored relative to a URL, and the default URL is obviously the source from where it was imported! But if we’re migrating from source A to source B, doesn’t it make sense to have the comments default to source B’s URL instead of source A? In my case, I used a mapper in the “Tools” menu (in the above image) to convert all the comment links to be based on the current site’s URL. That way, if the original source (i.e., the Wordpress site) gets deleted, we still retain the comments7. If you made sure the permalinks match, then this process should be pretty easy.
- Finally, the last thing to do is to actually install Disqus comments in the code for wordpress.
For that, I went to the “Universal Code” option for Disqus, and pasted the HTML code there into
the
_layouts/post.htmlfile.
After several restarts due to some random issues with Disqus/Wordpress having problems with deleted material, I was finally able to get comments imported correctly, and they had the same names assigned to the commentators! Excellent! The traceback comments, which are created by Wordpress when one blog post links to another blog post, did not get copied over here, but I guess that’s OK with me. I mostly wanted the human comments, for obvious reasons.
Whew! So we are done, right? Oh, never mind – we have to proofread each post! Since I
had 151 posts from Wordpress to import, that meant I had to proofread every single one of them.
Ben’s importer tool is good but not perfect, and code- or math-heavy posts are especially difficult
to convert correctly. Even disregarding code and math, a common issue was that italicized text
wouldn’t get parsed correctly. Sometimes the Markdown asterisks were “one space too ahead”, e.g., if
the word code needs to be italicized, the Markdown syntax for that is *code*, but sometimes the
importer created *code *, and that danging space can create some ugly asterisks visible in the
resulting HTML.
Even after basic proofreading, there are still additional steps one needs to take in order to ensure a crisp blog. One needs to
- fix the links for the images, since the images by default are set to the original Wordpress
address. The Wordpress-to-Jekyll plugin will put the images in the
wp-contentfolder, but I (and the official Jekyll documentation) recommend copying those images over to anassetsfolder. The defaultwp-contentfolder contains too many folders and sub-directories for my liking, but I guess it’s useful if a blog contains thousands of images. - fix the post-to-post hyperlinks in each post to refer to the current Jekyll version. In vim, this should be easy as I can do a bunch of find-and-replace calls to each file. Ensuring that the Wordpress permalinks follow Jekyll-style permalinks makes this task easier.
- incorporate extra tools to get LaTeX formatting.
I haven’t been able to do all these steps yet, but I’m working on it8.
Whew! The best part about the migration is that you only have to do it once. Part of the problem is that I had to rely on a motley collection of blog posts to help me out. The Jekyll documentation itself was not very helpful9.
Post-Migration Plan
In addition to the actual migration, there are some sensible steps that users should take to ensure that they can extract maximal utility from Jekyll. For me, I plan to
- learn more Markdown10! And in addition, it makes sense to use a text editor that can
handle Markdown well. I’m using vim since it’s my default, but it’s actually not that useful to
me, because I set the syntax mode off (using
:syntax off) and by default vim does not have a Markdown highlighter. I’m sure someone has created a Markdown syntax add-on to vim, so I’ll search for that. - actually make the site look better! I don’t mind the simplicity of default Jekyll, but a little more “piazza” wouldn’t hurt. I’d like to at least get a basic “theme” up and running, and to include excerpts from each post on the front page.
- make a site redirect from my old Wordpress.com site, so that it redirects users to this site. I’d rather not delete the old site all of a sudden (even though I will delete it eventually). But I will get rid of that Wordpress.org site that I had to pay to create, all just to help me migrate to Jekyll.
Incidentally, now that we’ve covered the migration pipeline, I thought I should make it clear how
one would go about using Jekyll. To add new posts, one simply adds a file in the _posts directory
that follows the convention YYYY-MM-DD-name-of-post.ext and includes the necessary front matter,
which contains the title, the date, etc. Looking at the raw Markdown code of sample posts is
probably the easiest way to learn.
One could update the site with each edit by adding, committing, and pushing to GitHub, but probably
a better way is to update locally by running jekyll build; jekyll serve. This will create a local
copy of Jekyll that one can have open in a web browser even if one doesn’t have Internet access.
Each time one saves a post, the server will update, so by refreshing, we can see the edit. It won’t
catch all edits — I had to push to GitHub and then update the local copy to get images to show up
correctly — but it is useful enough that I thought I’d share (and suggest) it. Furthermore, if
the website is public, it’s best to update/push polished versions of posts rather than
works-in-progress.
Hopefully these personal notes prove useful to future Wordpress.{com,org}-to-Jekyll migrators. In the meantime, I’m going to fix up the rest of this site and prepare some new entries that accentuate some of Jekyll’s neat features.
-
By the way, saying something like “GitHub co-founder Tom …” is the computer programming equivalent of the law school saying “Yale Law School graduate Bob …”. The fact that he founded GitHub immediately hightens my opinion of him. Oh, by the way, do you like how Jekyll does footnotes? Just click the little arrow here and you’ll be back up to where you were in the article! ↩
-
If you have experience using GitHub, then you can even fork my repository on GitHub to serve as a launching point for your own site or to test out Jekyll. ↩
-
Just to be clear, if you host a site on a public GitHub repository, then it’s free. That’s yet another reason to use Jekyll/GitHub! ↩
-
This username information should be included in the first email (or one of the first, I think) you got from Bluehost. The password should be the password you use to log into Bluehost to get to your user control panel. ↩
-
If you’re wondering how I was able to get a code block highlighted like that, I wrap the commands with three tildas (
~~~) before and after the text. This is with thekramdownMarkdown scheme. ↩ -
Fortunately, you can find this plugin by searching in Wordpress directly; there’s no need to engage in fancy FTP stuff. ↩
-
Actually, I haven’t tested this yet. I hope this works. ↩
-
If you see things like dead links or any “weird” looking text here, please contact me. ↩
-
Interestingly enough, the Jekyll docs for migrating from Wordpress.com to Jekyll currently link to an external blog post from March 2011. I found that blog post to be reasonably helpful, but it didn’t really do what I needed, which tends to be a problem when following such guides. ↩
-
To add to the complexity, there are several different versions of Markdown. My site is currently using the
kramdownstyle, but another popular one (that GitHub pages use) isredcarpet, but that style messed up my footnotes, so I eschewed from using it. ↩
Why It’s Difficult for me to Drop Classes
At this time, many Berkeley students are selecting their tentative courses for the Fall 2015 semester. I’m doing the same as well. I’m thinking of taking EE 227BT, Convex Optimization, which is a math class describing the wonders and treasures of convexity, and maybe CS 287, Advanced Robotics, which pertains to the math behind robot motion and decision making. In a few weeks, I’ll need to let Berkeley’s Disabled Students Program (DSP) know about my courses so that they can make arrangements to secure semester-long services.
I have to make such course decisions early and I have to be sure about what I am taking. The reason is that it is difficult for me to add or drop a class once a semester starts.
Most students do not have this problem. Schools usually have an add/drop period during the beginning of the semester. In that time, students can show up to a variety of classes and decide to drop a few that turned out not to be what they expected. (The overwhelming reason why students drop a class is because it demands more work than they can handle.) Depending on the class policies, students can also enroll in new classes within this period even if they didn’t show up to the first few lectures.
For me, I don’t have that luxury because class accommodations require weeks of advance preparation. To start, I must inform Berkeley’s Disabled Student Program about the classes I am taking so that they can make the necessary preparations. Securing a semester-long CART provider or sign language interpreter is not automatic because availability varies; I have experienced cases where I got accommodations with a day’s notice, and others where I couldn’t get any despite a week’s notice or more.
Those were for one-time events, though. It takes a longer time to secure CART providers or interpreters for semester-long jobs, and if I were to show up to a class for a few weeks and decide to drop it when there were still eight weeks to go, then those people would effectively lose up to eight weeks’ worth of money. (Replacing the funding with other interpreting jobs is not always easy, because demand occurs at varying times and locations.) In fact, when I was in my second semester at Williams, I enrolled in a class’s lab section that met on Thursday afternoons. I quickly secured accommodations for that lab session … and then just before the semester began, I decided to switch to having that session meet on Wednesday afternoons, because it greatly simplified my schedule.
It was a routine switch, but doing so cost that Thursday interpreter about $600 dollars’ worth of payment in a month. While I did secure a different interpreter for that lab session, the original one did not work for me again in my remaining time at Williams, and I constantly regret my choice to switch sessions. He obviously had the opportunity to work for me in later semesters, but because I dropped that lab session on short notice, he (understandably) did not want to take the risk of losing more money. Furthermore, Williams is isolated and does not have an interpreting workforce, so the interpreters I did have (from Albany, New York) had to drive long distances to get to work. Thus, a one-hour commitment at the school could have easily taken up four hours in a day, which reduces the chances of finding other interpreting work in the same day. This is one reason why I often tried to schedule consecutive classes to maximizes the monetary benefit for my interpreters.
As a result of that experience, I did not drop any Williams classes other than that lab session, which barely counts since it was part of the same general course. It does mean I have to “tough it out” in classes that turn out to be really difficult or boring, but I was a good student so this usually was not an issue. This line of thinking is carrying over to Berkeley, where I aim to complete all classes I enroll in and to minimize sudden schedule chances. I really want to maintain a good relationship between Berkeley’s DSP and the San Francisco agency that provides interpreting services.
Nevertheless, it’s important to retain perspective and realize the best case, most probable case, and worst case scenarios. Having hassles relating to adding and dropping classes is better than not getting any accommodations.
The Missing Deaf American Politician

It’s time to gear up for the 2016 United States Presidential election race! Ted Cruz, Rand Paul, Hillary Clinton, and Marco Rubio — in that order — have all announced or will announce that they will be running for president.
Now marks the beginning of the inevitable wait until Rand Paul becomes the next president. But in the meantime, I wonder about whether the United States has ever had a prominent deaf politician. Anyone in the Senate? How about the House of Representatives? Or even a member in a state legislature, or a mayor for a large city? Due to their average age, I’m sure we have had some slightly hearing-impaired politicians, but those don’t count to me. I’m talking about someone who was born deaf or became deaf at a young age, and who knows sign language, and who has strong connections to the Deaf community? Here, I’m using the capital “D” to indicate association with the community.
Unfortunately, to the best of my knowledge, America has never had one. On Wikipedia, there’s currently two relevant pages: “Deaf politicians” and “List of Deaf People“. (I know there are politicians who don’t have Wikipedia pages, but the simple existence of such a page indicates that there is some prestige to the position to which the politician is elected.)
The “Deaf politicians” page currently lists 14 relevant names. What’s interesting to me is that none of these people are or were American politicians. There are four British, two Hungarian, one French, one Austrian, one Greek, one Belgian, one Icelander, one Canadian, one South African, and one New Zelander.
It’s also intriguing that the list of deaf politicians is dominated by Europeans. It seems like a future topic of investigation would be to see if there exist additional biases against deaf people in non-European countries as compared to European countries. I’m particularly curious about the treatment of deaf people in Asian countries.
That second page, “List of Deaf People” does not provide any new deaf politicians outside of what the first page did.
Thus, it looks like America has lacked prominent deaf politicians in its entire existence. From my investigation, the closest thing we have had as a deaf politician is that Canadian guy, Gary Malkowski, because he spoke in American Sign Language while on the job. (Here is a biography of him, and another one on lifeprint.com, which is also an excellent resource for getting up-to-speed on ASL.) Mr. Malkowski was probably the first truly elected deaf politician in the world, serving on the Legislative Assembly of Ontario from 1990 to 1995 and becoming one of the world’s foremost advocates of rights for people with disabilities. Not being Canadian, I don’t have a good idea of how prestigious his position was, but I imagine it’s comparable to being a member of an American state legislature? His background includes a Bachelor’s degree in Social Work and Psychology from Gallaudet University.
While it is disappointing that the Deaf American Politician has never come into play, I am sure that within the next thirty years, we will be seeing at least one such person, given how numerous barriers have eroded over the years to allow a more educated deaf population, though I’m guessing there will be some debate over the “level of deafness” of such a candidate who shows up. I would bet that if this future politician has a background in American Sign Language and has even a weak connection to the Deaf Community, he or she will be able to win the vote of most of the severely hearing-impaired population (which includes the Deaf Community). The main question, of course, would be if the general population can provide the necessary votes.
To be clear, a deaf person should not automatically vote for a deaf politician, akin to how a black person should not automatically vote for Barack Obama or a woman should not automatically vote for Hillary Clinton. But such demographic information is a factor, and people can relate to those who share similar experiences. For instance, being deaf is key for positions such as the presidency of Gallaudet University.
To wrap up this post, here’s my real prediction for the two ultimate candidates for the 2016 U.S. Presidential Election: Hillary Clinton and Scott Walker. Jeb Bush is not winning his party’s nomination since voters will (possibly unfairly) associate him with his brother.
I’ll come back to this post in a little over a year to see if I predicted correctly. By then, hopefully there will be a deaf person who is making a serious run for a political position, but I doubt it.
Do I Inconvenience You?
Like many deaf people, I often have to request for assistance or accommodations for events ranging from meetings and social events in order to benefit from whatever they offer. These accommodations may be in the traditional realm of sign language interpreters, note-taking services, and captioned media, but they can also be more informal, such as asking a person to talk in a certain manner, or if I can secure a person who will stay with me at all times throughout a social event. (Incidentally, I’ve decided that the only way I’ll join a social event nowadays is if I know for sure that someone else there is willing to stay with me the entire time, since this is the best way to prevent the event from turning into a “watch this person talk about a mysterious subject for thirty seconds and then switch to watching another person” situation.)
On the other hand, when I request for assistance, I worry that I inconvenience others. This is not new for me (I wrote about this a year and a half ago), but with the prospect of having to attend more group meetings and events in the future, I worry about if others will view me as a burden, if they do not think so already.
Unfortunately, I preoccupy myself about whether I inconvenience others way too often than is healthy or necessary. For instance, I often wonder if sign language interpreters distract other students. I remember my very first class at Williams (wow, that was a long time ago…) where the professor remarked that a lot of the students were exchanging glances at the sign language interpreters (though to be clear, she was not saying this in a derogatory manner, and I have never had another professor say this in any other class). So other students do notice them, but for how long? For the sake of their own education, I hope the novelty factor wears off in the first few minutes and then it will be as if they were in a “normal” lecture without sign language interpreters. Now that I think about this, I really should have asked the people who shared many classes with me about if the interpreters affected their focus. I also wonder about how this affects whoever is lecturing. My professors have varied wildly in how much they interact with the interpreters, both during and outside of class.
Sign language interpreting services are the prominent reason why I worry I inconvenience others because they are very visible. Another, possibly less intrusive accommodation would be captioned media. I use captions as much as possible, but hearing people don’t need them. If they are there, is it an inconvenience for them? Captions that have white text and black background can obscure a lot of the screen. This is why even though I’ve only used them twice, I am already a huge fan of closed captioning glasses. They provide the best case scenario: high-quality accommodations with minimal hassle to others.
The vast majority of people do not express overtly negative reactions when my accommodations are present, but likewise, I have had few direct reassurances from others that I do not inconvenience them. I remember exactly one time where a non-family member told me I was not inconveniencing her: a few years ago, a Williams professor relieved me of a few concerns when she told me that having extra accommodations in lectures was not distracting her at all.
While this blog post might convey a bleak message, there is, oddly enough a very simple yet hard to follow method to ensure that you don’t feel like you are inconveniencing others, especially in workforce-related situations.
That method is to do outstanding work. If you can do that, and others are impressed, then you know that you’ve been able to overcome the various minor hassles related to accommodations and that you’re an accepted member of the community. If not, then either the situation doesn’t fit in this kind of framework, or it might be necessary to re-evaluate your objectives.
Another Hearing Aid Fails to Live Up to Its Water Resistant Label

Today, I played basketball for the first time since I arrived in Berkeley. It was a lot of fun, and I was at Berkeley’s Rec Sports Facility for 1.5 hours. Unfortunately, I also received a sobering reminder that my water resistant hearing aids are not actually water resistant.
My Oticon Sensei hearing aids worked great for about half an hour … then I heard that all-too-familiar beeping sequence in both ears, and then a few minutes later, the hearing aids stopped working. So I didn’t have any hearing and had to rely on various body language cues and last-resort tactics (honed over the years) to understand what others were saying. Fortunately, in basketball, communication among players in game situations tends to be blunt and simple and from experience, I’ve learned what players typically say to each other.
It is not uncommon for my hearing aids to stop working while I’m engaging in some physical activity. In fact, I get surprised if my hearing aids last through a session of pickup basketball. Thus, I already knew that I would have to reduce the amount of sweat near my hearing aids. I tried using my shirt and the gym’s towel cloth to absorb some of it, but they can only help out so much.
I understand that water resistant does not mean water proof, but I just cannot fathom how a water resistant hearing aid stops functioning after a half hour of physical activity. Out of curiosity, I re-checked my manual and it states that the Oticon Sensei has an IP57 classification. This means that it was still able to function properly after being immersed in water for 30 minutes at a depth of 1 meter.
I am somewhat surprised, because 30 minutes is about the time it took for the hearing aids to stop working after playing basketball. Oh well. At least I have a functional hearing aid dryer. Within a few hours after arriving home, I had them working. But it’s still incredibly annoying. Honestly, the biggest problem with hearing aid breakdowns is not the lack of communication on the court, but what happens off the court. Between pickup games, players are constantly talking to each other about who should be playing the next game or what they want to do after basketball’s over. A more important issue is that I drive to the gym, and driving without working hearing aids is something I would rather avoid.
Make the Best Peer Reviews Public
The annual Neural Information Processing Systems (NIPS) conference is arguably the premier machine learning conference along with the International Conference on Machine Learning (ICML). I read a lot of NIPS papers, and one thing I’ve only recently found out was that NIPS actually makes the paper reviews (somewhat) public.
As I understand it, the way NIPS works is:
- Authors submit papers, which are eight pages of text, and a ninth one for references. Unlimited supplementary material is allowed with the caveat that reviewers do not need to read it.
- The NIPS committee assigns reviewers to peer-review the submissions. These people are machine learning faculty, graduate students, and researchers. (It has to be like that because there’s no other qualified group of people to review papers.) One key point is that NIPS is double-blind, so reviewers do not know the identity of the papers they read while reviewing, and authors who submit papers do not know the identity of the people reviewing their papers.
- After a few months, reviewers make their preliminary comments and assign relative scores to papers. Then the original authors can see the reviews and respond to them during the “author rebuttal” phase. Naturally, during all this time, the identity of the authors and reviewers is a secret, though I’ve seen cases when people post submitted NIPS papers to Arxiv before acceptance/rejection, and Arxiv requires full author identity, so I guess it is the reviewer’s responsibility to avoid searching for the identity of the authors.
- After a few more months, the reviewers make their final decision on which papers get accepted. Then the authors are notified and have to modify their submitted papers to include their actual names (papers in submissions don’t list the authors, of course!), any acknowledgments, and possibly some minor fixes suggested by the reviewers.
- A few months after that (yeah, we’re getting a lot of months here), authors of accepted papers travel to the conference where they discuss their research.
This is a fairly typical model of a computer science conference, though possibly an aytpical model when compared to other academic disciplines. But I won’t get into that discussion; what I wanted to point out here is that NIPS, as I said earlier, makes their reviews public, though the identity of the reviewers is not shown. Judging by the list of NIPS proceedings, this policy of making reviews public began in 2013, and happened again in 2014. I assume NIPS will continue with this policy. (You can click on that link, then click on the 2013/2014 papers lists, click on any paper, and then there’s a “Reviews” tab.) Note that the author rebuttals are also visible.
I was pleasantly surprised when I learned about this policy. This seems like a logical step towards transparency of reviews. Why don’t all computer science conferences do this?
On the other hand, I also see some room for improvement. To me, the obvious next step is to include the name of the reviewers who made those reviews (only for accepted papers). NIPS already gives awards for people who make the best reviews. Why not make it clear who wrote the reviews? It seems like this would incentivize a reviewer to do a good job since their reviews might be made public. Incidentally, those awards should be made more prestigious, perhaps by announcing them in the “grand banquet” or wherever the entire crowd gathers?
You might ask, why not make the identity of reviewers known for all reviews (of accepted papers)? I think there are several problems with this, but none seem to be too imposing, so this might not be a bad idea. One is that the current model for computer science seems to assign people too many papers to review, which necessarily lowers the quality of each individual review. I am not sure if it is necessary or fair to penalize an overworked researcher for making his/her token reviews public. Another is that it is a potential source of conflict between future researchers. I could image someone obsessively remembering a poor public review and using that against the reviewer in the future.
These are just my ideas, but I am not the only one thinking about the academic publishing model. There’s been a lot of discussion on how to change the computer science conference model (see, for instance, “Time For Computer Science to Grow Up“), but at least for the current model, NIPS got it mostly right by making reviews somewhat public. I argue that one additional step towards greater clarity would be helpful to the machine learning field.
Review of Natural Language Processing (CS 288) at Berkeley
This is the much-delayed review of the other class I took last semester. I wrote a little bit about
Statistical Learning Theory a few weeks months ago, and now, I’ll discuss
Natural Language Processing (NLP). Part of my delay is due to the fact that the semester’s
well underway now, and I have real work to do. But another reason could be because this class was so
incredibly stressful, more so than any other class I have ever taken, and I needed some amount of
time to pass before writing this.
Before I get to that, let’s discuss what the class is about. Natural Language Processing (CS 288) is about the study of natural languages as it pertains to computers. It applies knowledge from linguistics and machine learning to develop algorithms that computers can run to perform a variety of language-related applications, such as automatic speech recognition, parsing, and machine translation. My class, being in the computer science department, was focused on the statistical portion of NLP, where we focus on the efficiencies of algorithms and justify them probabilistically.
At Berkeley, NLP seems to be offered every other year to train future NLP researchers. Currently we only have one major NLP researcher, Dan Klein, who teaches it (Berkeley’s hiring this year so maybe that number will turn into two). There are a few other faculty that have done work in NLP, most notably Michael Jordan and his groundbreaking Latent Dirichlet Allocation algorithm (over 10,000 Google Scholar citations!), but none are “pure” NLP like Dan.
CS 288 was a typical lecture class, and the grading was based exclusively on five programming projects. They were not exactly easy. Look at the following slide that Dan put up on the first day of class:

I come into every upper-level computer science expecting to be worked to oblivion, so this slide didn’t intimidate me, but seeing that text there gave me an initial extra “edge” to make sure I was focused, doing work early, and engaging in other good habits.
Let’s talk about the fun part: the projects! There were five of them:
- Language Modeling. This was heavy on data structures and efficiency. We had to implement Kneser-Ney Smoothing, a fairly challenging algorithm that introduced me to the world of “where the theory breaks down.” Part of the difficulty in the project comes from how we had to meet strict performance criteria, so naive implementations would not suffice.
- Automatic Speech Recognition. This was my favorite project of the class. We implemented automatic speech recognition based on Hidden Markov Models (HMMs), which provided the first major breakthrough in performance. The second major breakthrough came from convolutional neural networks, but HMMs are surprisingly a good architecture on their own.
- Parsing. This was probably the most difficult project, where we had to implement the CYK parsing algorithm. I remember doing a lot of debugging and checking indices of matrices to make sure they were aligned. There’s also the problem of dealing with unary expressions, since that’s a special case that’s not commonly described in most textbook descriptions of the CKY parsing algorithm (actually, the concept of “special cases not described by textbook descriptions” could be applied to most projects we did…).
- Discriminative Re-ranking. This was a fairly relaxing project because a lot of the code structure was built for us and the objective is intuitively obvious. Given a candidate set of parses, the goal was to find the highest ranking one. The CYK parsing algorithm can do this, but it’s better if that algorithm gives us a set of (say) 100 parses, and we run more extensive algorithms on those top parses to pick the best of those, hence the name “re-ranking.”
- Word Alignment. This was one that I had some high-level experience with before the class. Given two sentences of different languages, but which mean the same thing, the goal is to train a computer to determine the word alignment. So for an English-French sentence pair, the first English word might be aligned to the third French word, the second English word might be aligned to *no *French word, etc.
I enjoyed most of my time thinking about and programming these projects. They trained me to stretch my mind and to understand when the theory would break down for an algorithm in practice. They also forced me to brush up my non-existent debugging skills.
Now, that having been said, while the programming projects were somewhat stressful (though nothing unexpected given the standards of a graduate level class), and the grading was surprisingly lax (we got As just for completing project requirements) there was another part of the class that really stressed me out, far beyond what I thought was even possible. Yes, it was attending the lectures themselves.
A few months ago, in the middle of the semester, I wrote a little bit about the frustration I was having with remote CART, a new academic accommodation for me. Unfortunately, things didn’t get any better after I had written that post, and I think they actually worsened. My CART continued to be plagued by technical issues, slow typing, and the rapid pace of lecture. There was also construction going on near the lecture room. I remember at least one lecture that was filled with drilling sound while the professor was lecturing. (Background noise is a killer for me.)
I talked to Dan a few weeks into the course about the communication issues I was having in the class. He understood and thanked me for informing him, though we both agreed that slowing down the lecture rate might reduce the amount of material we could cover (for the rest of the students, of course, not for me).
Nonetheless, the remaining classes were still insanely difficult for me to learn from, and during most lectures, I found myself completely lost within ten minutes! What was also distressing was knowing that I would never be able to follow the question/answer discussions that students had with the professor in class. When a student asks a question, remote CART typically puts in an “inaudible” text due to lack of reception and the relatively quiet voice of the students. By my own estimate, this happened 75 percent of the time, and that doesn’t mean the remaining 25 percent produced perfect captions! CS 288 had about 40-50 students, but we were in a small room so everyone except me could understand what students were asking. By the way, I should add that while I do have hearing from hearing aids and can sometimes understand the professor unaided, that hearing ability virtually vanishes when other students are asking questions or engaging in a discussion.
This meant that I didn’t have much confidence in asking questions, since I probably would have embarrassed myself by repeating an earlier question. I like to participate in class, but I probably spoke up in lecture perhaps twice the entire semester. It also didn’t help that I was usually in a state of confusion, and asking questions isn’t always the ticket towards enlightenment. In retrospect, I was definitely suffering from a severe form of imposter syndrome. I would often wonder why I was showing up to lecture when I understood almost nothing while other students were able to extract great benefits from them.
Overall verdict: I was fascinated with the material itself, and reasonably liked the programming projects, and the course staff was great. But the fact that the class made it so hard for me to sit comfortably in lecture caused way more stress than I needed. (I considered it a victory if I learned anything non-trivial from a lecture.) At the start of the semester, I was hoping to leave a solid impression on Dan and the other students, but I think I failed massively at that goal, and I probably asked way too many questions on the class Piazza forum than I should have. It also adversely affected my CS 281a performance, since that lecture was right after CS 288, which meant I entered CS 281a lectures in a bad mood as a result of CS 288.
Wow, I’m happy the class is done. Oh, and I am also officially done with all forms of CART.
Harvard and MIT’s Lack of Closed Captions
Update February 25, 2017: Check out a related blog post about Stanford’s CS 231n class.
In the future, I will try not to discuss random news articles here, because often the subject might be a fad and fade in obscurity. Today, I’ll make an exception with this recent New York Times article about how Harvard and MIT are being sued over lack of closed captions. The actual suing/lawsuit action itself will probably be forgotten by most soon, but the overall theme of lack of captions and accessibility is a recurring news topic. Online education is real, and accommodations for those materials will also be necessary to ensure a maximal range of potential beneficiaries.
I don’t take part in online courses or video resources that much since there’s already plenty that I can learn from standard in-person lectures, and the material that I need to know (advanced math, for instance) is not something that I can learn from MOOCs, which by their very definition are for popular and broadly accessible subjects. For better or worse, the concepts I do need to know inside-out are embedded in dense, technical research papers.
Fortunately, the few online education resources I have experience with provide closed captions. The two that I’m most familiar with are MIT OpenCourseWare and Cousera, and both are terrific with captions. Coursera is slightly better, being more “modern” and also allows the video to be paused and sped up, while for MIT OCW one needs to use external tools, but both are great.
Apparently, using MIT OCW and Coursera (and sparingly at that) has probably led me to forget about how most online sources do not contain closed captions. It’s especially frustrating to me since in the few cases when I want to look at videos, I have to rely on extensive rewinding and judicious pauses to make sense of the material. I think in the next few years, I may need to employ those cumbersome tactics when I watch research talks.
It’s nice to see that captions are getting more attention, and I believe this issue will continue to reappear in news in the near future. Perhaps the brand names of “Harvard” and “MIT” are playing a role here, but I don’t view that as a bad sign: if they can take the initiative and be leaders in accessibility, then other universities should try and emulate them. After all, those universities want Harvard and MIT’s ranking…
Day in the Life of a Graduate Student
I was recently thinking about my daily routine at Berkeley, because I always feel like I am never getting enough work done. I wonder how much of my schedule is common among other graduate students (or among people in other, vastly unrelated careers). Let’s compare! Here’s my typical weekday:
5:45am: Wake up, shower, make and eat breakfast, which is usually three scrambled pastured eggs, two cups of berries, and a head of raw broccoli. Pack up a big-ass salad to bring with me to work.
6:45am: Leave for work. I usually drive — it takes ten minutes at this time — though at least one day of the week I’ll take the bus.
7:00am: Arrive at Soda Hall. Angrily turn off the lights in the open areas outside of my office after finding out that the people there last night left them on after leaving. Put my salad in the refrigerator. Unlock the door to my shared office, turn on laptop, pull out research and classwork notes. Check calendar and review my plan for the day.
7:15am to 9:15am: Try to make some headway on research. Check latest commits on github for John Canny‘s BID Data Project. Pull out my math notes and double-check related code segment from last night’s work to make sure it’s working the way it should be. Make some modifications and run some tests. Find out that only one of my approaches gets even a reasonable result, but it still pales in comparison to the benchmark I’ve set. Pound my fist on the table in frustration, but fortunately no one else notices because I’m still the only one on this floor.
9:30am: Realize that a lecture for my Computer Vision class is about to start. Fortunately, this is Berkeley, where lectures strangely start ten minutes after their listed time, but I need to get there early to secure a front row seat so I can see the sign language interpreters easily. (I can always ask people to move if I have to, and they probably will, but it’s best if I avoid the hassle.)
9:40am to 11:00am: Jitendra Malik lectures about computer vision and edge detectors. I concentrate as hard as I can while rapidly switching my attention between Jitendra, his slides, and my interpreters. Make mental notes of which concepts will be useful for my homework due the following week.
11:00am: Class is finished. Attempt to walk around in the huge crowd of entering/leaving students. Decide that since I don’t have anyone to eat lunch with, I’ll grab something from nearby Euclid street to take to my office.
11:15am to 11:45am: Eat lunch by myself in my office, wishing that there was someone else there. Browse Wikipedia-related pages for Computer Vision concepts from lecture today. Get tripped up by some of the math and vow that I will allocate time this weekend to re-review the concepts.
noon to 2:00pm: Try to get back to research regarding the BID Data Project. Write some more code and run some tests. Get some good but not great results, and wish that I could be better, knowing that John Canny would have been able to do the same work I do in a third of the time. Skim and re-read various research papers that might be useful for my work.
2:00pm to 3:00pm: Take a break from research to have a meeting with another Berkeley professor who I hope to work with. Discuss some research topics and what would be good but not impossible problems to focus on. Tell him that I will do this and that before our next meeting, and conclude on a good note.
3:15pm to 4:30pm: Arrive back in my office. Get my big-ass salad from the refrigerator and drizzle it with some Extra Virgin Olive Oil (I keep a bottle of it on my desk). My office-mate is here, so I strike up a quick chat. We talk for a while and then get back to work. My mood has improved, but I suddenly feel tired so end up napping by mistake for about fifteen minutes. Snap out of it later and try to get a research result done. End up falling short by only concluding that a certain approach will simply not work out.
4:30pm to 5:00pm: Decide to take a break from research frustration to make some progress on my Computer Vision homework. Get stuck on one of the easier physics-related questions and panic. Check the class Piazza website, and breathe a sigh of relief upon realizing that another classmate already asked the question (and got a detailed response from the professor). Click the “thanks” button on Piazza, update my LaTeX file for the homework, and read some more of the class notes.
5:00pm to 5:30pm: Take a break to check the news. Check Google Calendar just in case I didn’t forget to go somewhere today. Check email for the first time today. Most are from random mailing lists. In particular, there are 17 emails regarding current or forthcoming academic talks by visiting or current researchers, but they would have been a waste of time for me to attend anyway due to lack of related background information, and the short notice means it can be hard to get interpreting services. Some of those talks also provide lunches, but I hate going to lunches without having someone already with me, since it’s too hard to break into the social situation. Delete most of the email, respond to a few messages, and soon my inbox is quite clean. (The advantage of being at the bottom of the academic and social totem poles is that I don’t get much email, so I don’t suffer from the Email Event Horizon.)
5:45pm to 6:30pm: Try to break out of “email mood” to get some more progress done on homework. Rack my brain for a while and think about what these questions are really asking me to do. Check Piazza and Wikipedia again. Make some brief solution sketches for the remaining problems.
6:40pm to 7:00pm: Hit a good stopping point, so drive back home. (Still not in the greatest mood, but it’s better than it was before my 2:00pm meeting.) At this point most cars have disappeared from Hearst parking lot, which makes it easier for me to exit. Cringe as my car exits the poorly-paved roadway to the garage, but enjoy the rest of the ride back home as the roads aren’t as congested as I anticipated.
7:15pm: Think about whether I want to go to Berkeley’s Recreational Sports Facility to do some barbell lifting. It’s either going to be a “day A” session (5 sets of 5 for the squat, 5 sets of 5 for the bench) or a “day B” session (3 sets of 5 for the squat, 5 sets of 5 for the overhead press, and 1 set of 5 for the deadlift). I didn’t go yesterday, which means I have to go either now or tomorrow night. After a brief mental war, conclude that I’m too exhausted to do some lifting and mark down “RSF Session” on my calendar for tomorrow night.
7:30pm to 8:00pm: Cook and eat dinner, usually some salad (spring mix, spinach, arugula, carrots, peppers, etc.), more berries (strawberries or blueberries) a half-pound of meat (usually wild Alaskan salmon), and a protein shake. Browse random Internet sites while I eat in my room or out on my apartment’s table.
8:30pm to bedtime: Attempt to get some more work done, but end up getting making no progress, so pretend to be productive by refreshing email every five minutes and furiously responding to messages. Vow that I will be more productive tomorrow, and set my alarm clock an hour before I really should be waking up.
Deaf-Friendly Tactic: Provide an Email Address
Update 1/31/2015: I realized just after writing this that video relay is possible with the same phone number … whoops, that shows how long it’s been since I’ve made a single phone call! But in any case, I think the ideas in this article are still valid, and not every deaf person knows sign language.
Original article: In my search for deaf-friendly tactics that are straightforward to implement, I initially observed that it’s so much easier for me to understand someone when he or she speaks clearly (not necessarily loudly). I also pointed out that in a group situation, two people (me and one other person) is optimal (not three, not four…). Two recent events led me to think of another super simple deaf-friendly tactic. In retrospect, I’m surprised it took me a few years to write about it.
I recently had to schedule an appointment with Toyota of Berkeley to get my car serviced. I also received a jury duty summons for late February, and I figured that it would be best if I requested a sign language interpreter to be with me for my summons. Unfortunately, for both of these cases, calling Toyota and the California courts, respectively, seemed to be the only way that I could achieve my goals.
In fact, my jury summons form said the following:
Persons with disabilities and those requiring hearing assistance may request accommodations by contacting the court at [phone number redacted].
There was nothing else. I checked the summons form multiple times. There was no email address, no TTY number, no video relay service number, nothing. Yes, I am not joking. Someone who is hearing impaired — and logically will have difficulty communicating over the phone — will have to obtain jury duty accommodations by … calling the court! I actually tried to call with my iPhone 6. After multiple attempts, I realized that there was a pre-recorded message which said something like: “for doing X, press 1, for doing X, press 2…”, so I had to press a number to talk to a human. Actually, I think it’s probably best that there was no human on the other end, because otherwise I probably would have frustrated him or her by my constant requests for clarification.
I will fully admit that the iPhone 6 is not perfect for hearing aid users because its Hearing Aid Compatible rating is M3, T4 rather than the optimal M4, T4 rating, but still, even after about five or six attempts at calling, I did not understand what numbers corresponded to what activities. Sure, I’m rusty since I make around two phone calls a year to people outside of my immediate family, but I don’t see experience being much of a factor here.
This motives the following simple deaf-friendly tactic:
Provide an email address (perhaps in addition to a telephone number) that people can use to contact for support, scheduling services, and other activities.
I am aware that deaf people can easily use alternative services, such as TTY or video relay. Such services, however, are far inferior to email in many ways. Email nowadays is so prevalent in our lives and is incredibly easy to use. It’s rare when I don’t have some form of Internet access, so I can effectively check email whenever I want. The fact that I’m also writing instead of talking means that I can do things like revise my ideas more clearly and paste relevant web links. The process of forming an email can sometimes result in me resolving my own situation! I’ve often been in the process of writing an email, but then I realized I needed to add more information to show the person on the other end that I had done my research, but then that extra research I do can lead to an answer.
Furthermore, the set of people who regularly use email form effectively a proper superset over those people who use TTY and video relay services. In other words, the vast majority of TTY and video relay users also use email, but the converse is not true. In my case, I have not used TTY and video relay in years; email forms the foundation of almost all my communication nowadays. As long as it doesn’t become an obsession (as in checking it 50 times a day), I don’t see how it interferes that much in my daily life, and I would argue that a telephone call can drag on and on.
Conclusion: if you’re going to provide a phone number for contact, I would strongly urge you to also provide an email address.
New Year’s Resolutions: 2015 Edition
It’s that time of the year when many people are creating New Year’s resolutions.
Wait, scratch that. We’re a week into 2015, so I think it’s more accurate for me to say: it’s that time of the year when many people have forgotten or given up on their New Year’s resolutions. After all, this guy from Forbes claims that only eight percent of people achieve their resolutions.
Why am I discussing this subject? Last semester, I was in a continuous “graduate student” state where I would read, read, take a few notes, attend classes, do homework, read more research papers, do odd hobbies on weekends, and repeat the cycle. I rarely got the chance to step back and look at the big picture, so perhaps some New Year’s resolutions would be good for me. And before you claim that few people stick with them, I also had New Year’s resolutions for 2014, and I kept my text document about it on my desktop. Thus, I was able to keep them in mind throughout the full year, even if I ended up falling short on many goals (I set the bar quite high).
For a variety of reasons, I had a disappointing first semester, so most of my resolutions are about making myself a better researcher. I think one obstacle for me is the pace in which I read research papers. I’ve always thought of myself as someone who relies less on lectures and more on outside reading in classes than most (Berkeley computer science graduate) students, so I was hoping that my comparative advantage would be in reading research papers. Unfortunately, to really understand even an 8-page conference paper that I need for research, I may end up spending days just to completely get the concepts and to fill in the technical details omitted from the paper due to page limits.
When reading research papers, it’s not uncommon for me to lose my focus, which means I spend considerable time backtracking. Perhaps this could be rectified with better reading habits? I’m going to try and follow the advice in this blog post about reading real books, rather than getting all my news from condensed newspaper or blog articles. (Ironically, I just broke my own rule, but I will cut back on reading blogs and arbitrary websites … and also, I came up with this idea about two weeks ago, so it’s nice to see that there’s someone who agrees with me.) Last week, I read two high-octane thrillers — Battle Royale and The Maze Runner — to get me back into “reading mode” and am moving on to reading non-fiction, scholar-like books. Maybe books will help me quit Minecraft for good (so far, it’s working: I’ve played zero seconds of Minecraft in 2015).
I’ve also recorded some concrete goals for weight lifting (specifically, barbell training), which is one of my primary non-academic hobbies. For the past four years, my motivation to attend the gym has been through the roof. I’ve never missed substantial gym time unless I was traveling. In retrospect, I think programs like Stronglifts and Starting Strength (which I loosely follow) are so popular because they generate motivation. Both use the same set of basic, compound lifts, but as you proceed throughout the programs, you add more weight if it is safe to do so. Obviously, the more weight you can lift, the stronger you are! I often juxtapose weight lifting and addictive role-playing games (RPGs), where my personal statistics in real life barbell lifts correspond to a hypothetical “strength” attribute in an RPG game that I continually want to improve.
Here’s a video of me a few days ago doing the bench press, which is one of the four major lifts I do, the others being the squat, deadlift, and overhead press. I know there’s at least one reader of this blog who also benches, and we’re neck-to-neck on it so maybe this will provide some motivation (yeah, there’s that word again…).
This is one set of five reps for 180 pounds; I did five sets that day. (The bar is 45 pounds, the two large plates on both sides are 45 pounds, and each side has two 10-pound plates and one 2.5-pound plate.) I remember when I was a senior in high school and couldn’t do a single rep at 135 pounds, so seeing these new results shows how far I’ve come from my earlier days. I’m definitely hoping the same feeling will transition to my research and motivation in general.
Motivation. It’s an incredibly powerful concept, and a must for graduate students to possess with respect to research.
Independent Component Analysis — A Gentle Introduction
In this post, I give a brief introduction to independent component analysis (ICA), a machine learning algorithm useful for a certain niche of problems. It is not as general as, say, regression, which means many introductory machine learning courses won’t have time to teach ICA. I first describe the rationale and problem formulation. Then I discuss a common algorithm to solve ICA, courtesy of Bell and Sejnowski.
Motivation and Problem Formulation
Here’s a quick technical overview: the purpose of ICA is to explain some desired non-Gaussian data by figuring out a linear combination of statistically independent components. So what does that really mean?
This means we have some random variable — or more commonly, a random vector — that we observe, and which comes from a combination of different data sources. Consider the canonical cocktail party problem. Here, we have a group of people conversing at some party. There are two microphones stationed in different locations of the party room, and at time indices \(i = \{1, 2, \ldots \}\), the microphones provide us with voice measurements \(x_1^{(i)}\) and \(x_2^{(i)}\), such as amplitudes.
For simplicity, suppose that throughout the entire party, only two people are actually speaking, and that their speech signals are independent of each other (this is crucial). At time index \(i\), they speak with signals \(s_1^{(i)}\) and \(s_2^{(i)}\), respectively. But since the two people are in different locations of the room, the microphones each record signals from a different combination of the two people’s voices. The goal of ICA is, given the time series data from the microphones, to figure out the original speakers’ speech signals. The combination is assumed to be linear in that
\[x_1^{(i)} = a_{11}s_1^{(i)} + a_{12}s_2^{(i)}\] \[x_2^{(i)} = a_{21}s_1^{(i)} + a_{22}s_2^{(i)}\]for unknown coefficients \(a_{11},a_{12},a_{21},a_{22}\).
Here’s a graphical version, from a well-known ICA paper. The following image shows two (unrealistic) wavelength diagrams of two people’s voices:
The data that is observed from the two microphones is in the following image:
The goal is to recover the original people’s wavelengths (i.e., the two graphs in the first of the two images I posted) when we are only given the observed data (i.e., the two graphs from the second image). Intuitively, it seems like the first observed wavelength must have come from a microphone closer to the first person, because its shape more closely matches person 1’s wavelength. The opposite is true for the second microphone.
More generally, consider having \(n\) microphones and \(n\) independent speakers; the numerical equality of microphones and speakers is for simplicity. In matrix form, we can express the ICA problem as \(x^{(i)} = As^{(i)}\) where \(A\) is an unknown, square, invertible mixing matrix that does not depend on the time interval. Like the assumptions regarding \(n\), the invertibility of \(A\) is to make our problem simple to start. We also know that all \(x^{(i)}\) and \(s^{(i)}\) are \(n\)-dimensional random vectors. The goal is to recover the unseen sources \(s^{(i)}\). To simplify the subsequent notation, I omit the \(i\) notation, but keep in mind that it’s there.
How does the linear combination part I mentioned earlier relate to this problem formulation? When we express problems in \(x = As\) form, that can be viewed as taking linear combinations of components of \(s\) along with the appropriate row of \(A\). For instance, the first component (remember, there are \(n\) of them) of the vector \(x\) is the dot product of the first row of \(A\) and the full vector \(s\). This is a linear combination of independent source signals \(s_1,s_2,\ldots,s_n\) with coefficients \(a_{11},a_{12}, \ldots, a_{1n}\) based on the first row of \(A\).
Before moving on to an algorithm that can recover the sources, consider the following insights:
- What happens if we know \(A\)? Then multiply both sides of \(x = As\) by \(A^{-1}\) and we are done. Of course, the point is that we don’t know \(A\). It is what computer scientists call a set of latent variables. In fact, one perspective of our problem is that we need to get the optimal \(A^{-1}\) based on our data.
- The following ambiguities regarding \(A\) will always hold: we cannot determine the variance of the components of \(s\) (due to scalars canceling out in \(A\)) and we also cannot determine ordering of \(s\) (due to permutation matrices). Fortunately, these two ambiguities are not problematic in practice1.
- One additional assumption that ICA needs is that the independent source components \(s_1, s_2, \ldots, s_n\) are not Gaussian random variables. If they are, then the rotational symmetry of Gaussians means we cannot distinguish among the distributions when analyzing their combinations. This requirement is the same as ensuring that the \(s\) vector is not multivariate Gaussian.
Surprisingly, as long as the source components are non-Gaussian, ICA will typically work well for a range of practical problems! Next, I’d like to discuss how we can “solve” ICA.
The Bell and Sejnowski ICA Algorithm
We describe a simple stochastic gradient descent algorithm to learn the parameter \(A^{-1}\) of the model. To simplify notation, let \(W = A^{-1}\) so that its rows can be denoted by \(w_i^\top\). Broadly, the goal is to figure out some way of determining the log-likelihood of the training data that depends on the parameter \(W\), and then perform updates to iteratively improve our estimated \(W\). This is how stochastic gradient descent typically works, and the normal case is to take logarithms to make numerical calculations easier to perform. Also, we will assume the data \(x_i\) are zero-mean, which is fine because we can normally “shift” a distribution to center it at 0.
For ICA, suppose we have \(m\) time stamps \(i = \{1, 2, \ldots, m\}\). The log-likelihood of the data is
\[\ell(W) = \sum_{i=1}^{m} \left( \log |W| + \sum_{j=1}^{n} \log g'(w_j^\top x^{(i)}) \right)\]where we note the following:
- The determinant of \(W\) is denoted with single vertical bars surrounding it
- \(g'\) is the derivative of the sigmoid function \(g\) (not the sigmoid function itself!)
Let’s explain why this formula makes sense. It comes from taking logarithms of the density of \(x^{(i)}\) at each time stamp. Note that \(x = As\) so if we let \(p\) denote the density function of \(x^{(i)}\), then \(p(x^{(i)}) = |W| \prod_{j=1}^{n} p_j(w_j^\top x^{(i)})\), where \(p_j\) is the density of the individual source \(j\). We can split the product this way due to the independence among the sources, and the \(w_j\) terms are just (vector) constants so they can be separated as well. For a more detailed overview, see Andrew Ng’s lecture notes; in particular, we need the \(|W|\) term due to the effect of linear transformations.
Unfortunately, we don’t know the density of the individual sources, so we approximate them with some “good” density and make them equal to each other. We can do this by taking the derivative of the sigmoid function:
The reason why this works is that the sigmoid function satisfies the properties of a cumulative distribution function, and by differentiating such a function, we get a probability density function. And since it works well in practice (according to Andrew Ng), we might as well use it.
Great, so now that we have the log-likelihood equation, what is the stochastic gradient descent update rule? It is (remember that \(g\) is the sigmoid function):
\[W_{t} = W_{t-1} + \alpha \left( \begin{bmatrix} 1-2g(w_1^\top x^{(i)}) \\ 1-2g(w_2^\top x^{(i)}) \\ \vdots \\ 1-2g(w_n^\top x^{(i)}) \end{bmatrix} (x^{(i)})^\top + ((W_{t-1})^\top)^{-1} \right)\]where \(\alpha\) is the standard learning rate parameter, and the \(i\) that we pick for each iteration update varies (ideally sampling from the \(m\) training data pieces uniformly). Notice that the term in the parentheses is a matrix: we’re taking an outer product and then adding another matrix. To get that update rule from the log-likelihood equation, we take the gradient \(\nabla_W \ell(W)\), though I think we omit the first summation over \(m\) terms. Matrix calculus can be tricky and one of the best sources I found for learning about this is (surprise) another one of Andrew Ng’s lecture notes (look near the end). It took a while for me to verify but it should work as long as the \(m\) summation is omitted, i.e., we do this for a fixed \(x^{(i)}\). To find the correct outer product vectors to use, it may help to use the sigmoid’s nice property that \(g'(x) = g(x) (1-g(x))\). Lastly, don’t forget to take the logarithm into account when taking the derivatives.
There are whole books written on how to decide when to stop iterating, so I won’t get into that. Once it converges, perform \(s^{(i)} = Wx^{(i)}\) and we are done, assuming we just wanted the \(s\) vectors at all times (not always the case!).
Well, that’s independent component analysis. Remember that this is just one way to solve related problems, and it’s probably on the easier side.
References and Further Reading
-
According to Professor Ng. ↩