My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
Programming with Java, Swing, and Squint
Since I’m going to build a complete compiler for a subset of the Java programming language this fall in my Compiler Design course1, I thought it would be prudent to at least look through an introductory Java book over the summer. I want to make sure I didn’t forget much in the one-year period from last summer to this one, where I didn’t touch Java at all. Upon some thinking and exploration, I decided to do a speed read of the 337-page book Programming with Java, Swing, and Squint. (You can find the entire book online, in the link that lists all the chapters.) Having just finished the book, I can offer some of my comments.
This book was written by a Williams College computer science professor and is intended to be supplementary reading material for our introductory programming class. Since I never took the first (or second!) courses in the typical sequence for the CS major, this might help me fill in some holes in my knowledge as compared to other Williams College students. According to what I’ve read and heard, our first CS class is a straightforward intro-to-Java course, with a special emphasis on the understanding of networks and digital communication.
Programming with Java, Swing and Squint therefore does not assume any prior Java knowledge and
is relatively easy to read. For those who are wondering, Swing is a widely-used application
programming interface that one can import into Java code (put the line import javax.swing.*;
at the top of your code) to provide graphical user interfaces (GUIs) for user programs,
and Squint is a library specifically designed for the Williams intro CS course.
The book doesn’t waste any time in introducing the reader to small programs that construct simple GUI interfaces. At first, the author makes the necessary claim that one has to accept certain incantations of Java as “magic words” that must be included in code in order for it to run, e.g. the “public class XXX” text, but he explains this stuff in the appropriate (and humorly-named) subsequent chapters. Even the other examples in the book — email interfaces, building a calculator, etc. — are simple enough yet comprehensively presented and introduce the programmer to a variety of concepts, including (but not limited to) primitives, objects, classes, methods, control structures, loops, recursion, and arrays. While there is at least one substantial program for each chapter, the book doesn’t include any programming exercises or exercises/solutions. Thus, readers may find that they need to search elsewhere for additional programming tasks.
My final opinion: this can be useful as a first book for someone who has no programming experience but is interested in writing Java scripts immediately. Even a more advanced programmer can probably use this book for the purpose of figuring out how to explain a programming concept to a complete newbie. There were many facts about programming and Java that I subconsciously knew but couldn’t explain clearly to a layman before today. Thus, I’m happy to have read this book even though I already knew almost all of the material.
-
Side note: I only have three classes this semester: Compiler Design, Artificial Intelligence, and Complex Analysis. My fourth “class” is actually my senior thesis, and my fifth “extra class” consists of the graduate school applications. ↩
My Pre-College Education as a Deaf Mainstreamed Student
Introduction
I probably have an unusual pre-college education compared to most Williams College students, so I thought it would be interesting to share my experience.
Pre-School and Elementary School
I know I participated in some sort of pre-school education, but obviously my memory is quite fuzzy here. I was in a program where I’d attend a few sessions a week with other deaf and hard-of-hearing (DHH) students and had teachers who knew sign language. I’m not sure how much “learning” went on, since it’s pre-school.
Then came elementary school. But before I discuss that, I just want to briefly point out the concept of mainstreamed education. As I was a mainstreamed student, I can provide my own definition in the context of deaf and hard of hearing education: this means we take part in regular education with most of the other (hearing) students in our grade, but will occasionally sit in “special education” sessions that specifically cater to our needs. Typically, we’ll have some sort of accommodation in the regular classes, such as a microphone/FM system, while the special education classes have no need for them since the teachers are trained to teach such students.
Anyway, while in elementary school, It was here that I believe I first experienced the distinction of having the two styles of classes. I was assigned to be in regular courses for all my “core” classes (English, Math, Science, and Social Studies) along with a few other DHH students my grade, but I also took part in sessions designed specifically for DHH students. For instance, I took speech and social work sections, which teach skills that are harder (on average) for deaf students to acquire as compared to hearing students. A quick note: some DHH students take their core courses in the special education classes, so they essentially receive all their education there. It all depends on the student’s education plan.
My elementary school was unique in that it actually had these kind of special education classes. Most schools don’t, which means many DHH students are forced to take long bus rides to an appropriate school. I was one of them during elementary school, but as far as I can tell I was better off than some of the students, especially those who had to undergo two hour rides each day to and from school (four hours of being on the bus a day!).
Middle School
My split between taking part in regular and special education classes continued in middle school, but with a more skewed focus to the regular classes. This is necessary, after all; while special education classes are useful, they almost always can’t provide as much material as a regular class.
At the time I was a student, my middle school had nine forty-minute periods in a day. One of these was a daily “tutorial” period where students don’t have a class and can focus on their work (or play games). My tutorial room was located in the same room where most of the other DHH students took classes. Unfortunately, the tutorial period wasn’t standardized for students; in other words, my school essentially divided the students into nine groups, each with their own specific tutorial period. This limited the time I could interact with other DHH students, since it was rare that we would have the chance to meet in the tutorial room at the same period. They could also be in the middle of a class even if they were there, further restricting socialization.
There were a few DHH students in my grade, and in an effort to make efficient use of interpreters (and other resources), my school auto-assigned us to be in the same classes, so at least I wasn’t completely alone in those classes.
I continued to take speech and social work sessions throughout middle school, in the same classroom as the tutorial room for all DHH students, but I never took any academic classes there. As I mentioned earlier, I did have about two or three other DHH students in my core courses as well as a few secondary ones, such as Health, Music, and Physical Education.
The process of taking important examinations was also unique for me. If there was a normal test made by a teacher, I would take it in class with the other students. But for state-administered exams, I would take it in a separate, private room with an interpreter by my side in case I needed to listen to instructions. Obviously, they weren’t allowed to actually take the exam for me. It was pretty convenient for me, since I didn’t have to worry about the distraction of other students.
High School
At the time I was a student, my high school was designed so that there were four kinds of days (A, B, C, and D), and we would cycle through them during the academic year. On “B” and “D” days, during the second of four designated, 85-minute “blocks” of the day, there would be an “advisory” period, which is basically like study hall — students are assigned to a class, but there’s not going to be a lecture, so we can work on whatever we want.
Naturally, being a DHH student, I was assigned to be in the same advisory classroom as the other DHH students. This was much better than the situation in middle school, where my tutorial period wouldn’t coincide with the tutorial periods of other DHH students. While my advisories were often filled with work — I was regularly juggling several Advanced Placement classes at a time — I occasionally found time to play several rounds of chess and other games with other DHH students. The advisory period was also useful for organizing activities among the DHH students, since we were all together in one period. We would sometimes have special days that included an annual picnic, a trip to an amusement park (e.g., this one), and food provided during holiday seasons.
I still took some speech and social work classes and most of my midterms, final exams, and state-administered exams in a separate room. But after an agreement with my teachers, I no longer had to take speech and social work classes. I had about ten years of those classes, and we all agreed that further improvement due to these sessions would be negligible.
Finally, in high school, we had more freedom to pick their own schedule. Thus, I was no longer guaranteed to have other DHH students in my classes. In fact, I think the only true high school class I had that included other DHH students was physical education.
Thoughts
I was fortunate to live near a school district that was able to effectively provide me with what I needed in order to perform well in school. I’m now a student at Williams College, where there are no other deaf students, so at this point, I’m basically “on my own.” The transition from a mainstreamed pre-college education to a mainstreamed/hearing college is now complete.
No More Computer Science GRE Subject Test Exam
A while back, I said I was planning on taking the computer science subject exam for graduate school. I knew it wasn’t going to be too much of a big deal for my application, but it would at least give me an extra data point.
Of course, I didn’t realize that I was actually behind the times. The computer science GRE subject test is no longer offered; the last time it was administered was in April 2013. The following rationale is from the Educational Testing Service (ETS) website.
Over the last several years, the number of individuals taking the Computer Science Test has declined significantly. Test volume reached a point where ETS could no longer support the test psychometrically. As a result, the GRE Program discontinued the Computer Science Test after the April 2013 test administration. Scores will continue to be reportable for five years.
All I can say is that I’m relieved, since the test wouldn’t have helped me that much and it saves me the studying time. Furthermore, these subject tests tend to be more helpful for those applications who either (1) don’t come from a top school, or more importantly, (2) didn’t major in computer science. Since that doesn’t describe my scenario, I didn’t need to depend on the subject test at all.
There are others who are perfectly fine with seeing the test discontinued. Such viewpoints are present in, for instance, this blog post.
Of course, I’m just as guilty of bias as anyone else. Someone who didn’t major in computer science will probably disagree with me. Also, I’ve heard that foreign students made up much of the high scores on the exam, so this may hurt them a little. (But my knowledge here is sketchy.)
Regardless, though, all this really means is that we can get back to our research.
Recap of the 2013 Algorithmic Combinatorics on Words REU

Yesterday, I arrived back home after spending the previous eight weeks at the 2013 Algorithmic Combinatorics on Words REU. It was a great experience overall, so I thought I’d share a bit about what happened.
The Experience
I arrived in Greensboro, NC, on June 2, and was greeted by one of the research assistants (RAs) and a few other student participants who had arrived at roughly the same time. The RAs had generously offered to drop us off at our apartments, and they also assisted us in getting settled during the first day by providing keys, taking us out to dinner, etc. The following morning, we met our REU coordinator, Professor Francine Blanchet-Sadri and went through a typical orientation process. (She gave me permission to address her on a first-name basis, so hopefully it’s okay if I use “Francine” in the rest of this post.)
One of the unique things about this REU is that there’s only one faculty advisor here (Francine) who advises all the student research groups. From what I know, most REUs are structured such that several faculty members offer their own projects, and students have to apply to the REU while ranking them according to preference. The faculty members also typically advise only one team of students. At UNCG, all students and the RAs (who conduct their own research here as well) essentially work in the field of algorithmic combinatorics on words in teams of two, though some individuals paired together may agree to split and work by themselves.
We spent the first few days going over background material in Algorithmic Combinatorics on
Words and listening to Francine (or the RAs) give seven talks about different subfields in which
we could perform research. After we were through with the background material, the fourteen of us
— eleven student participants and three research assistants — ranked the seven projects
and attempted to match up the groups as fairly as possible. After some unlawful coercion
gentle negotiation, we eventually settled on an alignment of two students to each of the seven
possible topics. Note that Francine demanded that all seven topics be used, so we had to make sure
that there were people working on the less popular topics. I was assigned to work with another
student on the topic entitled Abelian and Subword Complexity.
As it turned out, we only seriously investigated abelian complexity. I won’t get into too much depth here, but I figure it can’t hurt to at least give an extremely basic introduction. If we define a word \(w\) to be a sequence of characters over some alphabet, then the abelian complexity of that word with respect to \(n\), denoted \(\rho_{w}^{ab} (n)\), is simply the number of abelian equivalence classes of subwords of length \(n\) in \(w\). Two words are abelian equivalent (and thus in the same equivalence class) if and only if each letter in a given alphabet shows up the same amount of times in the two words; for instance, words \(x_1 = 010\) and \(x_2 = 100\) are abelian equivalent since both have two 0s and one 1, but \(y_1 = 011\) and \(y_2 = 001\) are not abelian equivalent. With this in mind, suppose we have the word \(w_0 = 010110\) over the binary alphabet \(A_k = \{0,1\}\). We have \(\rho_{w_0}^{ab} (4) = 2\) because we can form a length-4 subword of \(w_0\) with using two 0s and two 1s (e.g. 0101) or one 0 and three 1s (e.g. 1011). To make things more interesting, I investigated infinite words, but that’s a topic for another day.
The first few weeks were primarily devoted to background reading provided with the set of notes Francine compiled for our particular research topic. Even though we mostly read papers with the dreaded “in progress” label (in other words, they’re littered with typos and confusing English), the reading wasn’t too bad, and I began brainstorming a bunch of ideas and possible avenues for research.
There was a major open conjecture posed in one of the longer papers I read, and during the third week, I felt like I began seeing ways to prove it. Thus, I spent days putting my ideas into writing and verifying them with a variety of my own Python scripts.
The problem, of course, was that there was always at least one case/example that wouldn’t work.
I suspect I’m not the only one who got roadblocked this way. I came up with idea after idea, but my programs came up with counterexample after counterexample, and eventually, I had to choose between (a) splitting my already numerous cases into smaller cases with little hope that I could cover all of them, or (b) abandon the conjecture for now and move on to a different topic.
Fortunately, my research partner actually knew what he was doing, and during the time I had spent trying to solve the open question, he had found some interesting patterns regarding abelian complexity in a certain class of words. For instance, with the help of Mathematica, he showed me graphs of abelian complexities for infinite words that resembled fractal patterns. We soon made his findings our primary research focus and dedicated ourselves to explaining why these graphs showed up the way they did, and if there was an efficient algorithm to actually compute abelian complexities.
Over the next few weeks, we would prove a variety of lemmas, come up with additional conjectures, create almost a hundred Python scripts, and write up our results in what would eventually become a 25-ish page paper that we gave to Francine just before the conclusion of the program. Thus, what started out as a bunch of pictures eventually turned into algorithms and mathematically rigorous theorems. I never did prove the conjecture I first worked on, and after contacting the person who actually formed the conjecture (he was in the REU last year), it seemed like he had tried a similar version of a proof — albeit on a smaller scale — that I had done but failed as well.
Overall, I believe this REU really gives students a sense of research beyond the stereotypical advisor-student relationship. Previously, my research — even at another REU — mostly consisted of the following cycle:
Faculty Advisor: “Do task X”
Me: “Yes, sir/ma’am”
Instead, it was more like we really got to look at what we wanted to explore. Heck, one student somehow made heavy use of complex analysis in his research. I still haven’t been able to figure out the connection.
My learning obviously wasn’t just limited to algorithmic combinatorics on words. For instance, I found out that I’m as clear a type one personality as it gets (though I was close to testing as a type six), that my diet is incredibly strange, that machine learning is more important to the national government than theory or algebraic geometry, and a whole host of other things. (Actually, I suspected these were true prior to coming, but my experience there all but confirmed them. Also, I don’t know anything about algebraic geometry.) I do hope, though, that I was able to teach the other students as much as they taught me.
Other Thoughts
One of the defining features of this REU is that it’s heavily structured. The work day is six days a week from nine to five daily, with Sundays off. (Note to future/prospective REU students: If you plan on setting aside a full weekend for your own non-research related activities in the summer, then this program isn’t for you.) Students are expected to be in our designated classroom by 9:00 AM each morning. At that time, Francine comes into the room and briefly meets with each group to discuss their progress and to provide feedback.
The classroom itself is where many students do research, which reminds me of Google-style facilities where there are no individual offices or labs. There are tradeoffs to this kind of “open plan” work environment; it allows for greater interaction among groups and quick feedback, but it can get distracting at times. Fortunately, there’s a computer science lab nearby where students can work if they want a more serene environment. I sometimes worked there even though I could have simply turned off my hearing aids in the classroom and not get distracted. (Turning off my hearing aids presents a whole host of problems.) Even if one wants complete isolation, there are so many accessible classrooms in the science building that this objective is not difficult to accomplish.
Saturdays are unique work days, with REU-sponsored pizza for lunch and typically some sort of event, such as a presentation on LaTeX. During the end of the fourth and eighth weeks of the REU, we all convened together to present our research. This consisted of about seven fifty-minute talks, so it does consume the full work day. There is a coffee machine in the classroom, so unless you’re like me and hate coffee, you should get enough caffeine to stay focused.
Surprisingly, this REU isn’t all about work. At least from my experience, the RAs and students formed social activities such as hiking (see the image at the top of this post), card games, movie nights, and dinners. We had a Facebook group to help in this regard, which was especially useful since the fourteen of us were divided among five different houses, which were not next to each other. Incidentally, housing quality will obviously depend on whichever house you’re assigned to live in. I was probably assigned to the worst one, but I still had a decent-sized bedroom and a functioning bathroom/kitchen, so I survived.
The campus and nearby area is decent enough. There are plenty of restaurants and eating places near the working area, which means it’s possible to go out for lunch at Subway, Jimmy Johns, Thai food, etc. There are also a variety of fields, basketball courts, and a gym where people can participate in sports and other activities outside of work. The weight room — located in the student recreation center — isn’t that bad, since it actually has a power rack. Yes, it has its share of bozos who spend their entire gym sessions doing curls and who can’t squat correctly, but I did meet two other guys there who actually knew a thing about barbell training. And I was even able to convince another REU student to join me in the gym. (Here, a one out of thirteen ratio is impressive.)
I’m probably forgetting a whole host of other things I wanted to write about, but I think the above summarizes some of the interesting things about the REU.
Good luck to everyone who went and I wish you all the best.
Machine Learning (Part 1 of 4): Introduction

This summer, I’ve spent a good amount of time analyzing the content of my blog. By looking at
the composition of my computer science entries, I realized that I don’t talk about the subject
material in my classes a whole lot. Most of my posts in that category are related to programming,
research, and other areas. I do have four course-related posts thus far in a “theory of
computation” series, which you can access by looking at the recently-added directory of
blog entries1, but other than that, there’s honestly not much.
I’m hoping to change that as the summer turns into fall. One way is to revive my theory of computation series, which is motivated in part because I’m going to be a theory teaching assistant this fall. Entries are currently being drafted behind the scenes.
And another way is to introduce a new series of posts relating to one of my favorite classes at Williams, machine learning. This is also the subject area of my senior research thesis, so I’ll definitely be committed to writing about the subject. This will be a four-post series, with this one being the first.
This post will give an introduction the field and, along with the second post, will discuss the variety of learning algorithms (I’ll explain what these are later) that are commonly studied in machine learning. The third post will involve analyzing the advantages and disadvantages of the learning algorithms and discuss scenarios where some may be preferable over others. The fourth and final post will discuss some of my possible future research in the field.
Introduction to Machine Learning
So what is machine learning anyway? First, let’s go over the corresponding Williams College course description:
Machine Learning is an area within Artificial Intelligence that has as its aim the development and analysis of algorithms that are meant to automatically improve a system’s performance. Automatic improvement might include: (1) learning to perform a new task; (2) learning to perform a task more efficiently or effectively; or (3) learning and organizing new facts that can be used by a system that relies upon such knowledge.
At the heart of machine learning, then, is dealing with the question of how to learn from data. After all, our goal in this field is to figure out how to train a computer to adequately perform some task, and those almost always involve some sort of data manipulation. Possibly the most ubiquitous such “task” in machine learning is classifying data. The canonical example of this is separating spam email from non-spam email. Somehow, someway, we must use our vast repositories of spam and non-spam email to train an email client how to detect spam email with high precision and recall. That way, we can be reasonably confident when deploying it in the real world.
Needless to say, this is an important but inherently complicated task. Sure, there are some emails that are obviously spam, such as ones that are filled with nothing but dangerous URLs and non-English text. But what about those kinds of emails where someone’s writing to ask you about money? Most would consider those as spam, but what if a relative was actually serious about asking money, but without knowing it, wrote in a style that was similar to those guys from unknown countries? (Perhaps the relative doesn’t use email much?) Furthermore, we can also run into the problem of ambiguity. If there exist perplexing emails such that even knowledgeable human readers can’t come with a consensus on spam vs non-spam, how can the computer figure out something like this?
Fortunately, with email, we won’t usually have such confusion. Spam tends to be fairly straightforward for the human eye to detect — but can the same be said for a computer? The key is to take advantage of existing data that consists of both spam and non-spam emails. The more recent the emails (to take into account possible changes over time) and the more diverse the emails (to take into account the many different writing styles of people and spam engines) the better. We can take a large subset of the data and “train” our email client. We assume that each email will have a label stating whether it is “spam” or “not spam” (if we relax this assumption, then things get harder — more on that later) and we must use some kind of algorithm to teach the client to recognize the common characteristics of emails in both categories. Then, we can take a “test” set, which might consist of all the remaining data that we didn’t use for training, and see how well the email client performs.
The advantage with this approach is that, since we assumed the data are labeled, we can judge and analyze the results, taking into account not just basic factors — such as percentage of emails classified correctly — but also if there are any trends or patterns that might give us insight as to when our learning algorithm works and doesn’t work. We can continue to modify our learning algorithm and its parameters until we feel satisfied with its performance on the testing set. Only then do we “deploy” it into the real world and watch it in action, where it has to deal with unlabled email.
In fact, a good analogy of machine learning in the context of humans seems to be sports referees. These people have to undergo a period of education and training before they can get tested on some “practice” games. They will then get feedback before moving on to the more serious competitions. Current NBA referees, for instance, might have been trained via this simple algorithm: “Read Book W, Pass Written Exam X_1 and Physical Exam X_2, Referee Summer League Game Y, and if performance is satisfactory, Referee Actual NBA Game Z.”
Hopefully this makes sense. As the previous example and general concepts imply, machine learning can make an impact in many fields other than computer science. Statistics, psychology, biology, chemistry, and many other areas have benefitted from machine learning tactics. In fact, such learning algorithms are even used in fraud detection.
Now let’s move on to some more formal definitions.
The Problem Setting
We have a computer capable of performing classification, which is the process of assigning a given category to each element in the data. The specific categories may or may not be known to the learner, but in general, knowing the categories ahead of time makes for far easier machine learning. A learning algorithm is something that can be used to help a machine (i.e. a computer) better perform a task when given data. “Better perform” can obviously mean different things depending on the circumstances or evaluation methodology used, but for the sake of simplicity, let’s suppose we’re only focusing on accuracy, or correctness.
To carry out the machine learning and evaluate performance, we’ll need some data in the form of feature vectors, which store the relevant attributes of our samples, and usually includes its class label. For instance, with the email example earlier, the vector might include attributes such as the number of characters present in the index zero, then the number of words present in index one, and the email domain in index two, and so on. Attributes can be real-valued or categorical. One element in the feature vector — possibly the last one — might be reserved for the true classification of SPAM vs NON-SPAM. The machine will then use these feature vectors with a learning algorithm to build a learning model.
There are multiple ways of performing this learning. Three common methods are supervised learning, unsupervised learning, and reinforcement learning. Supervised learning involves the use of labeled training data to build a clear model for output, while unsupervised learning has unlabeled training data and generally performs tasks such as clustering (i.e. identifying similar elements). Reinforcement learning is when a grade is given to some output. This allows the learner to know what’s going right and wrong. A good analogy is when a young child touches a radiator and gets burned. He will typically learn from his error and avoid touching radiators in the near future, even if they are not actually hot.
My machine learning class did not discuss reinforcement learning, so for now we can focus on supervised and unsupervised learning.
To allow machine learning to happen in supervised learning, it is common to divide our data into training, validation, and testing sets.
-
The training set’s primary purpose is to build the learning model that the machine can utilize to classify future examples. The ideal training set is large, diverse, and is accurately labeled, which might involve humans hand-labeling the data.
-
Validation sets are used to check how well a model has performed before we move on to testing. We may have multiple approaches and might use our validation set to pick the top candidates or slightly modify some parameters.
-
Testing sets tend to be used to officially evaluate the performance of our proposed learning model. The learner is generally not going to have access to these elements to build the model, since that would defeat the point of testing.
There are different ways to partition data into those sets. It is common, in my experience, to simply combine the validation and testing sets, but the validation set is used enough to make it worth mentioning. If we have very little data, then we might consider omitting the validation set, or perhaps even treating the entire data set as both training and testing as a last resort. This is not desirable because we want to train a machine to perform well on the entire distribution of relevant data, not just our own samples, so there’s a danger of overfitting. In other words, we build the model so tightly towards our present data that it fails to generalize to the larger population.
On the other hand, unsupervised learning deals with clustering. The goal here is to find groups of examples that are similar to each other but distinct from other groups of examples. We’ll get to this more when I discuss clustering algorithms.
Learning Algorithms
I believe the easiest learning algorithm to discuss is decision stumps, since it has just one clear component. We pick an attribute and associate a rule to it. If it’s categorical, then we can have multiple groups for each of the possible values for that attribute, and assign elements accordingly. If it’s real-valued, we often associate a threshold to it and divide elements based on that rule. For instance, if we have real-valued data such as the number of words in an email message, we might set a threshold of 500 words. All emails with fewer than that quantity are spam, and all emails with at least 500 words are not spam.
That’s it! Obviously, in our particular example, this is a terrible classification. The simplicity of decision stumps is one of its major drawbacks, since we have to rely on one single attribute to make our choice of classification; many times, it is unreasonable for this to result in an acceptable classification. On the other hand, the fact that it’s so simple means we can easily explain this model to a group of non-technical people. Don’t neglect this important fact! Scientists and mathematicians must know how to communicate with people from a variety of fields.
In the next post, I’ll discuss an obvious extension of this problem to decision trees, which are not restricted to classifying after just one decision.
-
This was removed when the blog migrated to Jekyll in May 2015. ↩
Grad School Applications, Stage 1: The Quiet before the Storm
I’m about to enter my senior year at Williams College, and my goal is to pursue a Ph.D. in computer science directly after graduation. Thus, I have to write some graduate school applications.
Since this seems to be a topic that interests many college students across the country, I thought it would be interesting to show readers how I progress through this crucial stage of my life. Perhaps this will be informative to the random student who happens to come across this blog.
Also, since I haven’t actually started the applications, it makes sense to write now so that it’s ultra-clear what I was thinking, planning, etc. Hence, this post is called “Stage 1.”
Now, in computer science, zero is the new one, so we tend to start numbering from zero. But it doesn’t make sense to do that for this blog entry. In my opinion, “Stage 0″ consists of everything one does before the application season: doing well in computer science courses, getting solid research experience, reading about and understanding graduate school life, GREs, etc. Obviously, anyone who hasn’t done most of these and wants to pursue a C.S. Ph.D. now is pretty much screwed.
For me, though, I’m almost through with Stage 0. I think I’ve done fairly well at Williams so far, and I have some research experience. I’ve also read some writings that I found extremely helpful to me; two of the best are Professor Philip Guo’s PhD Grind, and Professor Mor Harchol-Balter’s PhD advice. Finally, I took the general GRE back in April, so I’m good to go with that. I have not taken the subject test, though … and I’ll probably take it anyway, even if some schools don’t require it (more on that later).
Thus, I’ll define Stage 1 (i.e. right now) as the process of determining where to apply and setting a schedule for completing the application materials.
First and foremost, I hope to attend a well regarded computer science department. Sure, I can take the C.S. rankings straight off of the U.S. News & World Report, but I need to be careful not to pick a school because of its overall prestige, only to realize that it’s not as strong in my projected research areas as it is in other fields. (Even worse is a school that has great overall prestige, but has a virtually nonexistent computer science department.)
Context matters. As an example, I once knew a guy who turned down an offer from a top four school to go to one that was ranked well outside the top ten. I thought he was crazy — until I realized that the school he went to was extremely strong in his research area.
So what are the benefits of attending a prestigious graduate school institution other than the prestige? Professor Jeff Erickson suggests that one reason is the average quality of the graduate students. It makes sense that the better the graduate students, the more they can help and motivate each other to advance the field of computer science. (Of course, it also helps if they’re not enormously cut-throat!) The professors at the top school will also be leaders in their field, but I need to be careful again here because a famous professor does not imply an excellent advisor. Is it possible to gain knowledge on an advisor’s effectiveness by investigating the career paths of his or her Ph.D. students?
The strength of the department is clearly going to be my primary factor in graduate school. But there are a few other factors to consider. One is the location; I’m probably going to be happy in a place that’s not too rural nor right in the middle of a city. If I had to choose one of the extremes, I’d opt for the urban environment, and one of the reasons is that in a larger city, it’s probably easier for me to secure accommodations. In fact, I’d suggest this is true for anyone with a documented disability. A city also makes it easier to have direct fights instead of time-consuming stoppages, and would give me a break of mountains and forests after spending four years in Williamstown.
Anyway, that’s enough wishful thinking and non-application stuff. Right now I really need to obey the following schedule:
- Finish first drafts of applications by the end of August
- Study for the computer science subject test from the period of mid-August to mid-October, and take the exam sometime then or shortly after
- Secure letters of recommendation by the start of September, and give the recommenders all the relevant information about me by some scheduled date
- Finish second drafts of applications by the end of September
I figure it can’t hurt to at least take the computer science GRE subject test. If a school requires it, then I’ll have done it. If not, then I can still see what areas I need to study in further detail.
Ten Things Python Programmers Should Know
Update May 18, 2017: It’s been almost four years since I wrote this original blog post. It has become, according to Google Analytics, the most popular blog post that I’ve ever written. Also, during that four-year range, I have had much more experience programming in Python as part of my computer science undergraduate major followed my my Ph.D. studies, so I think it’s about high time I provide an update soon. Stay tuned for a new blog post! (This post will remain archived for historical reasons, and because I like to look back at my earlier writing.)
I used to program in Java, before I transitioned to Python. And now that I’ve become a huge Python fan, I thought I’d provide ten basic but important facts or concepts about Python. All of these were useful to me within the past year as I made Python my primary programming language. If you’re just getting to grips with Python or am interested in seeing what this language has to offer, you might find this overview helpful. This entry does assume that you are comfortable with elementary programming terminology and Python syntax, such as understanding the role of Python’s whitespace.
I also make substantive use of code throughout this post, so just be aware that one-line comments in
Python are preceded by a hashtag #. To comment a block of text in Python, we can wrap the text
around with three quotation marks """ at the start and end. This method makes it easier
to comment multiple lines, since we don’t have to put slashes at the start of each line.
Finally, before we get to the meat of the post, if one plans to seriously use Python, then it is essential to familiarize himself or herself with the following websites:
- Official Python Website
- Python 2 Documentation (Ignore this if using only Python 3)
- Python 3 Documentation
- Stack Overflow
I’m including Stack Overflow because ever since it opened up, people have been asking an absurd amount of Python programming questions there. If you’ve got a basic syntax error, try to avoid asking the question on Stack Overflow since someone has probably done it already. In fact, in many cases, Stack Overflow has become the documentation. (But that’s a story for another day.)
That said, let’s discuss ten of some of the important concepts that Python programmers should know.
1. Python Version Numbers
While this is technically not a programming feature, it’s still crucial to know the current versions of Python just so we’re all on the same page. Python versions are numbered as A.B.C., where the three letters represent (in decreasing order) important changes in the language. So, for instance, going from 2.7.3 to 2.7.4 means that the Python build made some minor bug fixes, while going from 2.xx to 3.xx represents a major change. Note the ‘x’ here, which is intentional; if a Python feature can apply to version number 2.7.C for any valid ‘C’ value, then we put in an ‘x’ and refer to Python 2.7.x. We can also omit the ‘x’ entirely and just use 2.7.
As of this writing (July 2013), Python has two stable versions commonly used: 2.7 and 3.3. Less important is the third character, but right now 2.7.5 and 3.3.2 are the current versions, both of which were released on May 15, 2013. The short answer is that, while both 2.7 and 3.3 are perfectly fine to use, 3.3 is the future of the language and someone just starting Python today should probably use Python 3.3 over 2.7. Of course, if one is in the middle of an extensive research project that makes heavy use of 2.7, then it might not make sense to upgrade to 3.3 right away. This is actually quite similar to my current situation, since I’m using a good number of my own Python 2.7 scripts to help me analyze algorithmic combinatorics on words. Once August arrives, I’ll fully transition to Python 3.3. In the meantime, though, I’ve done quite a bit of reading on Python 3’s new versions and I have 3.3.2 installed (in addition to 2.7.4) on my laptop, so this post and its code syntax will assume that we’re using Python 3.
One important thing to note, though, is that Python 3 is intentionally backwards incompatible. Backward compatibility is often a desired feature of programming languages and software that routinely undergo revisions, since it means that input from older versions (e.g. older Python programs) can still run under the latest builds. In this case, Python 2 code will not be guaranteed to run successfully if using Python 3, so some conversion may be necessary to allow code to properly run. Backwards incompatibility was necessary in order to allow Python 3 to be more clear, concise and use additional features.
In the meantime, what’s the difference between Python 2 and 3, anyway That’s beyond the scope of this post, but I’ve added in references at the end of the section based on the official Python documentation. I suppose the main improvement is that there’s better Unicode support, but there’s also been some minor fixes here and there, improving some of the annoying features of 2.7. Still, while there are enough changes to warrant a 2.x to 3.x change, Guido van Rossum says in his overview that:
Nevertheless, after digesting the changes, you’ll find that Python really hasn’t changed all that much – by and large, we’re mostly fixing well-known annoyances and warts, and removing a lot of old cruft.
A note: Guido van Rossum is Python’s creator, and still maintains his leadership over the programming language’s development, so if there’s something he says about Python, it can usually be taken as correct.
By the way, if you’re curious to see your version of Python, you can simply paste the following into a program:
import sys
print("My version Number: {}".format(sys.version)) Here, the text inside the quotation marks gets printed as it is, except for the
brackets { and }, which transform into the sys.version or in
other words, the Python version. This is classic string formatting.
Alternatively, if you’re using a Linux or Mac computer, you can do the same stuff directly in the Python interpreter on the command line interpreter (i.e. Unix Shell) or the Mac OS X Terminal. Windows users will need to install third party software, such as Cygwin, since there is no built-in command line interface. But in the meantime, this incredibly useful Terminal brings us to our next point …
2. Using the Python Shell
Without a doubt, one of the most useful aspects of Python is that it comes
auto-installed with its own shell. The Python Shell can be executed by typing in
python from the command line (in Windows, there should be an application
that you can just double-click). By doing so, you’ll see the default
version number, a copyright notice, and three arrows (or “r-angles” in
LaTeX-speak) >>> asking for your input. If you have multiple versions of
Python installed, you may need to add in the version number python3.3 to
get the correct version.
So why is the Python shell so useful? Simply put, it lets you test out simple commands in isolation. In many cases, you’ll be able to detect if there’s going to be a syntax or logical error in some command you want to use before it gets tested in some gigantic script that could consume memory or be time-intensive.
Below, I’ve included a screenshot of me performing some commands on my Macbook Pro’s Terminal, using the 3.3 Python shell.
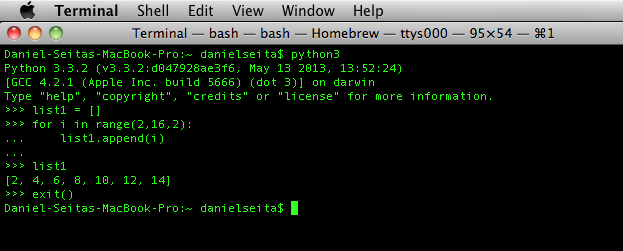
This set of commands sets up an empty list (list1) and adds to it all the even integers in
the range \([2, 16)\).
For the sake of showing why this shell might be useful, suppose I had forgotten to put in the last
parameter of range so I had typed in range(2,16) instead. Then when I printed the
contents of the list after the for loop, I would have seen all the numbers between 2 and 15
inclusive, rather than just the even numbers. But since I want only the even numbers in my
“real” program that I’ve been working on, this would remind me to add in that last
parameter. It’s a silly example, but it really shows how checking what you do in the shell
before you insert it in a real program can be beneficial. I’ll be using the shell in some
other code bits in this post, which you can recognize by the three “r-angles” >>>.
Other popular languages such as C++ and Java have their own versions of the Python shell, but I believe you would need to install something. And installing Linux-style programs can be nontrivial since often times there is no nice clickable GUI that can do the installation immediately.
3. Using ‘os’ and ‘sys’
I find both the os and sys modules to be incredibly useful to me for the purposes of conveniency and generality.
First, let’s go over the sys module. Possibly the biggest advantage that it offers to
the programmer is the use of command line inputs to the program. Say you’ve built a large
program that will perform some task that depends on inputs from the user. For instance, in my
machine learning class last semester, I implemented the k-means clustering algorithm. This is
a learning algorithm that is given data and can classify it into groups depending on how many
clusters are given as input. It’s clear that this can be useful in many life applications.
Someone who has standardized data on medical patients’ records (e.g. blood-sugar levels,
height, weight, etc.) may want to classify patients into two “clusters,” which could be
(1) healthy or (2) ill. Or perhaps there could be n clusters, where patients classified into lower
numbered clusters have a better outlook than those with high numbers.
To perform k-means clustering, then, we logically need two inputs: (1) the data itself and (2) the number of clusters. One idea is to put these directly into the program, and then run it. But what happens if we want to keep changing the data file we’re using or the number of clusters? Each time the program has finished executing, we’d have to go back into our text editor and modify it before re-executing it.
A better way would be to use command line arguments. Changing inputs on the command line is usually faster than opening a text editor and retyping the variables. We can do this with sys.argv, which takes in input from the command line. As an extra protection, one can also make sure that the user inputs the correct number of parameters. I have done this in the following code snippet from my k-means clustering algorithm.
import sys
# If number of parameters is incorrect, terminate.
if (len(sys.argv) != 3):
print("USAGE: kmeans_clustering.py [file] [clusters]")
sys.exit()
num_clusters = int(sys.argv[2])
with open(sys.argv[1], 'r') as feature_file:
# Do stuff with the file Here, sys.argv represents the list of command line arguments, with the
name of the code as the first element. If I’ve put in the correct parameters,
then the program should proceed smoothly, with sys.argv[1] and
sys.argv[2] seamlessly incorporated.
In addition to speed, another advantage of command line arguments is that they
can be used as part of a process to automate the same script over and over
again. Suppose I wanted to run my kmeans_clustering script over and over
again with the cluster value ranging from 2 to 100. One way is to tediously call
kmeans_clustering on the command line with ‘2’ as the last
parameter, then do the same with ‘3’ after the first run has
finished, and then do ‘4’ and so on. In other words, I’d have to
call the program 99 times!
A better way is to make another Python script and use os.system to call
kmeans_clustering as many times as I want. And this is as easy as changing
the input to os.system. It takes in a string, so I would set a for loop
that would create its unique string which would then act as input to the command
line. See the following code for an example, where file1.arff is the
made-up file that I’m using as an example.
import os
for i in range(2,101):
input_string = "python kmeans_clustering file1.arff " + str(i)
os.system(input_string) So now this program will call kmeans_clustering 99 times automatically, each time with a different parameter for the number of clusters. Quite useful, isn’t it? This is one of the biggest benefits of using a program to call another program. Just be wary that if you make a change to a program while another script is calling it, then those changes will be reflected the next time the program gets called.
4. List Comprehension
In my opinion, list comprehension, or the process of forming lists out of other lists or structures, is something that exemplifies the beauty and simplicity of Python programming. Remember the code I wrote earlier which set up a list that contained all the even integers in \([2,16)\)? I could have just written the following one-liner:
>>> list1 = [i for i in range(2,16,2)]
>>> list1
[2, 4, 6, 8, 10, 12, 14] To understand the syntax, it’s helpful to refer to the (old) Python 2.7.5 documentation, which has a nice explanation (emphasis mine):
A list display yields a new list object. Its contents are specified by providing either a list of expressions or a list comprehension. When a comma-separated list of expressions is supplied, its elements are evaluated from left to right and placed into the list object in that order. When a list comprehension is supplied, it consists of a single expression followed by at least one for clause and zero or more for or if clauses. In this case, the elements of the new list are those that would be produced by considering each of the if or if clauses a block, nesting from left to right, and evaluating the expression to produce a list element each time the innermost block is reached.
In other words, we’ll be given some expression that becomes an element of the list, and it will be subject to some restriction based on our series of for or if causes. Sometimes, if there are multiple loops and conditionals to evaluate, it can be more easily viewed if split into multiple chunks. I do this in the comments in the below code example. (If it’s absolutely necessary to introduce line breaks to better understand some list comprehension, the code might be a tad too complicated, but I believe it’s perfectly fine to use list comprehension in this example I provide.)
list2 = [(x, x**2, y) for x in range(5) for y in range(3) if x != 2]
'''
list2 = [(0, 0, 0), (0, 0, 1), (0, 0, 2), (1, 1, 0), (1, 1, 1), (1, 1, 2), (3, 9, 0), (3, 9, 1), (3, 9, 2), (4, 16, 0), (4, 16, 1), (4, 16, 2)]
This expression can be easily understood as:
list2 = [(x, x**2, y) for x in range(5):
for y in range(5):
if x != 2]
'''As the documentation clearly states, it’s also possible to create nested lists via list comprehension. This can be useful if one wants to initialize something like a table or a matrix. When I wrote my first Python program a year ago, I indeed used list comprehension to construct a table of elements that I would update as part of a dynamic programming algorithm.
>>> list3 = [[0 for i in range(3)] for i in range(3)]
>>> list3
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]5. Slicing
Slicing is the process of taking a subset of some data. It is most commonly applied to strings and lists. My backstory for how I first learned about slicing was when I had to repeatedly iterate through a list and apply a function to all but its last element. I kept using an ugly loop that iterated through the indices of the list and performed a check each time to ensure that I wasn’t at that last element.
I eventually realized that this was one of the dumbest things I was doing, so I
searched about how to obtain everything but the last element. And that was when
I began my slicing journey. For this particular example, we can just use
[:-1] to obtain everything but the element with index negative one,
which will be the last element. (If one makes a list with \(N\) elements, then
the element located at index \(N-1\) also has an equivalent index of \(-1\),
and similarly for the indices \(N-2\) and \(-2\), and so on.)
# The bad way
for index in range(len(list4)):
if (index != len(list4)-1):
# Do something
# The better way
for element in list4[:-1]:
# Do something Fortunately, slicing isn’t limited to just getting rid of one element.
Letting list1 be an arbitrary list, we can make list2 be a new list
taking on a specified subset of list1s values by using the following
general syntax:
list2 = list1[start:stop:step] Here, start is the index of the first element we want, stop is the
index of the first element we don’t want (remember that in Python, ending
indices are often exclusive rather than inclusive), and step represents
the number \(k\) where we take each \(k\)-th value. It can be negative, too,
which would indicate that we’re moving backwards through the list. Not all
of these values are needed; if the step is omitted, it defaults to +1. And
as the example earlier should make clear, if either start or stop
are omitted, they should default to 0 and the length of the list, respectively.
To gain a better intuition of slicing, it also helps to know how the indexing process works for negative numbers. In the official documentation, there’s a nice ASCII-style diagram (with the text “Python” in it) in the Strings section that suggests you think about Python indices as pointing between elements of data.
It’s also important to understand the role that the colons play in splicing syntax. In the
code above, I used [:-1] to refer to all but the last element in a list. If I had omitted that
earlier colon, that would have resulted in just getting the last element of the list! If I had put
the colon to the right of the -1, then I would still only obtain the last element, since that starts
from the last-indexed element and gets all values beyond that (of which there are none). The
following code shows how differences in colon placement and the number of parameters present affect
splicing. An easy way to understand where colons should be placed is to just put in all three start,
stop, and step values and delete the ones that are set at their default values (0, length of list,
and +1, respectively). What’s left is how the colons can be formatted, though if
‘step’ is at its default value, we don’t need the colon preceding it at the end.
For instance, list[2::] is the same as list[2:], and list[:4:] is the same as
list[:4].
>>> list1 = [3,4,5,6,7,8]
>>> list1[2:4]
[5, 6]
>>> list1[2:]
[5, 6, 7, 8]
>>> list1[:4]
[3, 4, 5, 6]
>>> list1[::2]
[3, 5, 7]
>>> list1[::-1]
[8, 7, 6, 5, 4, 3]
>>> list1[:5:2]
[3, 5, 7]
>>> list1[:4:2]
[3, 5] (Yes, it’s interesting that [::-1] reverses a list.)
I advise anyone to play around with semi-complicated slicing before using it in code. This is where the Python shell becomes extremely useful. (See #2 on this post.)
6. Dictionaries and Sets
Lists are by far the most common data structure I use when Python programming, but I still make extensive use of dictionaries, sets, and other data structures, since they have their own advantages.
A set is simply a container that holds items, like a list, but only holds
distinct elements. That is, if you add in element X to a set already
containing X, the set doesn’t change. This can be an advantage of sets
over lists, since I often need to ignore duplicates when I’m managing lists, and
making a set based on a pre-existing list is as easy as typing in
set(list_name).
But possibly an even bigger advantage with sets is their super fast lookup. Testing if an element is in a list takes \(O(n)\) time. With sets, however, membership testing is constant, \(O(1)\)-time. Of course, this requires set elements to be hashable, which means that items need to be associated with some constant number (i.e. “hash value”) so that they can be looked up in a table quickly.
>>> example1 = [i for i in range(5)]
>>> example2 = [i for i in range(3,8)]
>>> example3 = example1 + example2
>>> example1
[0, 1, 2, 3, 4]
>>> example2
[3, 4, 5, 6, 7]
>>> example3
[0, 1, 2, 3, 4, 3, 4, 5, 6, 7]
>>> set_example1 = set(example3)
>>> set_example1
{0, 1, 2, 3, 4, 5, 6, 7} Of course the downside with sets over lists is that they don’t support indexing of elements, so there’s no ordering. This is a pretty big drawback, but regardless, if you don’t care about order and duplicates, and want speedy membership testing, sets are the way to go.
In addition to sets, I find dictionaries to be an incredibly useful data structure. A dictionary is something that associates to each key a value, so it’s essentially a function that pairs up elements together.
>>> dict_example = {'Bob' : 21, 'Chris' : 33, 'Dave' : 40}
>>> dict_example
{'Bob': 21, 'Dave': 40, 'Chris': 33}
>>> dict_example['Adam'] = 11
>>> dict_example
{'Adam': 11, 'Bob': 21, 'Dave': 40, 'Chris': 33}
>>> dict_example['Bob']
21 There are many scenarios where dictionaries are useful. As an added benefit, searching the values by key is efficiently done in constant time, just like in sets. Due to their widespread use, dictionaries are one of the most heavily optimized data structures in basic Python.
7. Copying Structures (and Basic Memory Management)
Since it’s so easy to make a list in Python, one might think copying it is also straightforward. When I was first starting out with the language, I would often try to make separate copies of lists using simple assignment operators.
>>> list1 = [1,2,3,4,5]
>>> list2 = list1
>>> list2.append(6)
>>> list2
[1, 2, 3, 4, 5, 6]
>>> list1
[1, 2, 3, 4, 5, 6] Notice what happens? I make list1 and try to make list2 be a copy of that list via
assignment. But if I modify list2, such as by adding in the number 6, it also modifies
list1! This is a deceptive but important point. Making lists equal to other lists will
essentially create two variable names pointing to the same list in memory. This will apply to any
‘container’ item, such as dictionaries.
Since simple assignment does not create distinct copies, Python has a built-in list statement, as well as generic copy operations. It’s also possible to perform copies using slicing. Some solutions are shown below.
>>> list3 = list(list1)
>>> list1
[1, 2, 3, 4, 5, 6]
>>> list3
[1, 2, 3, 4, 5, 6]
>>> list3.remove(3)
>>> list3
[1, 2, 4, 5, 6]
>>> list1
[1, 2, 3, 4, 5, 6]
>>> import copy
>>> list4 = copy.copy(list1) There’s also another thing to be worried about — what if you have containers within containers? While implementing a machine learning algorithm last semester, I ran into the problem of copying dictionaries that contained dictionaries. I thought I was okay using the straightforward dict operation, but I realized that if I changed a dictionary within one of those dictionaries, that change would be reflected in both of the larger dictionaries!
An example of this error is shown below, where I modify dict2s first dictionary by adding in
the 'z1' -> 60 mapping. That key-value pair will also be reflected in dict1s first
dictionary.
>>> dict1 = {'a': {'x1' : 20, 'y1' : 40}, 'b': {'x2' : 15, 'y2' : 30}}
>>> dict2 = dict(dict1)
>>> dict2
{'a': {'x1': 20, 'y1': 40}, 'b': {'x2' : 15, 'y2': 30}}
>>> dict2['a']['z1'] = 60
>>>
>>> dict2
{'a': {'x1': 20, 'y1': 40, 'z1': 60}, 'b': {'x2': 15, 'y2': 30}}
>>> dict1
{'a': {'x1': 20, 'y1': 40, 'z1': 60}, 'b': {'x2': 15, 'y2': 30}} The solution to this is to use the deepcopy method, which will copy everything. This is the most memory-intensive operation of the copying solutions I’ve discussed here, so use it only if the other methods won’t work.
8. Generators
Remember all the stuff about lists I’ve talked about? If you’ve been thinking about memory management, you might wonder why we need to store gigantic lists in memory if we might not even access their values. This is where generators come into play.
Generators in Python provide us with the advantageous concept of lazy evaluation, so when we “construct” generators, we don’t actually evaluate some value within it unless it’s absolutely needed. One of the biggest benefits of lazy evaluation is in memory footprint. If we construct a generator that consists of the numbers 1 through N for large N, and our code ends up only needing the first three numbers, then Python doesn’t need to construct and store the remaining numbers in memory as it would for a list. (This hypothetical scenario could happen because there might be a function with different N values for each call that uses a generator.) If you’re curious, the Wikipedia page has additional information about lazy evaluation.
The first time I was introduced to generators was when I read a Stack Overflow post that said Python
2.x programmers should always use xrange() over range(), because xrange() is a
generator, or at least, has the generator-like quality of lazy evaluation. For the record, even
though I almost always use xrange() over range() in Python 2.7 code, range() does have
its uses, such as if one needs an actual list.
Basically, range() and xrange() perform the same task, but the difference is that
range(n) will literally construct a list consisting of the numbers 0 through n-1, while
xrange(n) only provides us with those numbers when we need them.
As a testament to the usefulness of generators, Python 3 changed range() so that it now
possesses xrange() qualities. The xrange() function has been omitted, as the Python 3
shell indicates:
>>> [i for i in range(10)]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> [i for i in xrange(10)]
Traceback (most recent call last):
File "", line 1, in
NameError: name xrange is not defined There are other sites that can explain generators better than I can, such as the Python Wiki page on
generators. One thing to note is that if we do need a list out of a generator, then we can
just call the list() method that I used earlier (in #7, on copying stuff). Generators also
have their own version of list comprehension, called generator comprehension.
So why do we even use lists anyway? I can illustrate some reasons in the following code.
>>> list1 = ['adam', 'bob', 'chris', 'dave']
>>> gen1 = (x for x in list1)
>>> gen1
at 0x1006a68c0>
>>> for i in gen1:
... print(i)
...
adam
bob
chris
dave
>>> for i in gen1:
... print(i)
...
>>> I made a generator, gen1, out of an list containing four common English names, but if I try to
print the generator, I instead get a “generator object” expression. Values in
generators don’t “exist” until they’re needed on demand.
A second tricky point about generators is that if we iterate through it, we can’t iterate it again like we would during the first time. The second loop fails to print anything.
So generators do have their place in Python, but so do lists and other non-generators. To understand generators better, it might also be useful to incorporate the yield keyword in Python. This (fantastic) Stack Overflow question and answer explains it far better than I can, and I learned a lot about generators just by reading that page.
9. File Management
With many Python scripts using files as input, such as my kmeans_clustering
code I posted earlier, it’s important to know the correct ways to incorporate
files in one’s code. The official documentation explains that the open
keyword is used for this purpose. It is pretty straightforward, and we can loop
through the file to analyze it line by line. Alternatively, we can use the
readlines() method to create a list consisting of each line in the file,
but just be wary if the file is large.
f = open('test.txt', 'r')
for line in f:
# Read each line
f.close() The f.close() is is important, since it’s done to free up memory. From the official
documentation:
When you’re done with a file, call f.close() to close it and free up any system resources taken up by the open file. After calling f.close(), attempts to use the file object will automatically fail.
I almost never use f.close() though, because I can use the with keyword, which will
automatically close the file for me once the code exits its block. In fact, I posted an example of
this earlier when I talked about my kmeans_clustering code. Here’s the relevant parts of it
reproduced below.
# Note: sys.argv[1] is the file, and 'r' means I'm reading it
with open(sys.argv[1], 'r') as feature_file:
all_lines = feature_file.readlines()
for i in xrange(len(all_lines)):
# Do stuff hereNow, in most cases, I believe that you don’t absolutely need to take advantage of
f.close(), since if a script that was reading in a basic text file (but doesn’t close
it) finishes running, then that text file should automatically be closed anyway. I can imagine that
things can get more complicated with multiple files and scripts running together, so I’d get
in the habit of using with to read in files.
If you’re interested in writing files, you can change the r parameter to w (or
r+ which will enable both reading and writing) and use the file.write() method. This is
common in research settings, where you might have to modify text files in accordance to some
experiment.
10. Classes and Functions
It’s pretty easy to define a function in Python, using def, such as the
following trivial example, which counts the number of zeros in the input, which
will be a string.
def count_zeros(string):
total = 0
for c in string:
if c == 0:
total += 1
return total
print(count_zeros('00102')) # Will return 3 Recursive functions are also straightforward, and behave as in most major object-oriented programming languages.
Compared to Java, I haven’t used too many classes in my Python Programs, so my expertise in this realm is quite limited. Still, classes are an important part of object-oriented languages, and Python is (contrary to some people’s opinions) object-oriented, so it’s worth it to read the Classes documentation if you have the time. The documentation page I just linked to, though, states affirmatively that:
Python classes provide all the standard features of Object Oriented Programming: the class inheritance mechanism allows multiple base classes, a derived class can override any methods of its base class or classes, and a method can call the method of a base class with the same name. Objects can contain arbitrary amounts and kinds of data. As is true for modules, classes partake of the dynamic nature of Python: they are created at runtime, and can be modified further after creation.
A really simple example of a Python class (with Python 2.7 syntax) is shown here.
Conclusion
I hope you found this overview comprehensive yet concise. Obviously, this will depend on your prior skill level and experience with programming. In order to really understand these concepts, though, I urge you to write up some programs. You don’t need to make your own full-blown module; just write up something that’s interesting to you (Google around for solvable problems if necessary) and see if you can incorporate some of these concepts. There are also some important concepts that I’ve skipped over for the purposes of keeping this post targeted at a more beginner-oriented audience. Python decorators, for instance, are something that a serious programmer should be sure to understand. If you’re ambitious, you can also check out this Stack Overflow question and try to loosely follow the most up-voted answer’s suggestions on how to go from beginner to intermediate/expert.
If you have any further questions or comments, feel free to reply to this post or Google around. Have fun programming in Python!
Summer Academy for Advancing Deaf and Hard of Hearing in Computing: The Last Summer
The summer of 2013 will mark the final time that the Summer Academy for Advancing Deaf and Hard of Hearing in Computing is offered. I received the news from the program coordinator, who announced it on the Summer Academy alumni Facebook group page. My reaction to the news was a mixture of appreciation and distress, but also one of realization. Alas, all things must come to an end.
As I’ve mentioned earlier, the Summer Academy for Advancing Deaf and Hard of Hearing in Computing (the “Summer Academy”) is a nine-week residential program at The University of Washington (UW) at Seattle’s campus. About ten to thirteen deaf or hard of hearing students nationwide are offered spots in the program based on a written application, their transcripts, and letters of recommendation. Some of the benefits of the program include
- Taking an undergraduate-level computer science course at UW, as well as an animation class specifically created for the summer program.
- Meeting deaf professionals in the workforce via field trips or having them as guest speakers on campus.
- Fostering relationships among other talented deaf and hard of hearing students in computing.
- Gaining the experience of living independently and away from home for a summer (mostly applies to pre-college students).
All in all, it’s an extremely impressive offering, and it’s free for students since it’s fully funded by a variety of organizations, such as the National Science Foundation and the Bill & Melinda Gates Foundation. I bet that most students — if not all — end up with many positive experiences. I know I did. (I was a 2011 Summer Academy alumni.)
So why’s it going to end? There are two primary reasons.
- The man who started the program and got its funding, Professor Richard Ladner, is retiring and becoming Professor Emeritus. He’s had a 42-year career as a faculty member at UW.
- Rochester Institute of Technology (RIT) was supposed to “claim” the Summer Academy so that it would continue on RIT’s campus, but somehow that arrangement did not work. I don’t know the details about why this happened.
Professor Ladner and the program coordinator did not reapply for funding, and thus the Summer Academy will no longer continue. About 90 students in all will have been served in the Summer Academy’s seven years of existence. As of this writing, the 2013 session is well underway, but the era will come to an end on August 24, 2013.
New Closed-Captioning Glasses
Soon after my junior year at Williams College, I went to see a movie with some friends at a local Regal Cinema theater.
Yes, a real movie at a real theater.
It’s been a while since I’ve been to one, because I have to first check that I’m interested in the movie and that — more importantly — the theater provides captions.
But on that day, I had the fortune of trying out these closed-captioning glasses. Instead of having the captions appear on the screen with the movies, they are essentially projected holographically by the glasses. Thus, moving the glasses (e.g. by rotating one’s head) will cause the captions to shift. Apparently, this is all new technology that’s been finalized in 2012 or 2013. Even though I’ve only used them once, I can already see some of the benefits and drawbacks to this device.
Pros
First of all, these captioning glasses clearly work. It can take a couple of minutes to get used to it, though, since the captions won’t be in the same spot all the time unless one has abnormal neck-stabilizing ability.
But the even bigger benefit is that caption services can be provided for all movies at supported Regal theaters. Now, we won’t have to deal with hearing people ranting about annoying captions clogging up the screen. Instead, they’ll be complaining about the quality of their seats or other picayune matters.
Cons
While I didn’t really have any issues with stabilizing the captions, I can see why some would feel uncomfortable with a non-stable reading location. I also remember that there was a slight issue with the color of the text. I believe the text is some yellow-green color (I’m colorblind, so this is my best guess) and it can sometimes blend in with the screening.
Finally, since I wear prescription glasses, I had to take some extra time to adjust the captioning glasses so they could fit outside of the ones I wear daily. People with especially large or bulky prescription glasses may have a more difficult time wearing a second pair of glasses.
Conclusion
This is yet another example as to how today’s world has become unquestionably more accessible to deaf people than in previous eras. It’s also what I would consider a deaf-friendly tactic. Now, the next step would be to accomplish the harder task of having these glasses for everyday use. That means if I’m wearing them, the captions should display what someone is saying to me in real time. (Actually, this is theoretically impossible, but we need to aim high, right?)
The Deaf Academics Mailing List
Last January, I joined the Deaf Academics mailing list (a “listserv”), which is co-owned by Dr. Teresa Burke and Dr. Christian Vogler. As I mentioned earlier, Dr. Vogler is one of three deaf computer science Ph.Ds today, and he invited me to join the list after we met (via Skype) in January.
It’s been about six months, so I’ve had the chance to read some of the many adventures, discussions, and opinions of other deaf and hard of hearing professionals. It’s a highly active listserv. I would estimate that there’s been about 800 emails sent since the time I joined, so I’ve only had the time to read a fraction of them. Most of the emails are sent by a handful of people who are really dedicated to the list and often write several messages daily. With many emails seemingly written as if they were carefully composed 400-word blog entries, the average quality of emails is significantly higher than those in other mailing lists, such as the Access STEM one shown in the screenshot.
As a result, some of the discussions have been quite interesting and eye-opening to me. Given that many of the active listserv users are social scientists and/or writers, the themes prevalent in the mailing list primarily revolve around deaf culture, deaf education, deaf history, and stories about people’s experiences, lives, and current occupations.
Here’s a sample of the discussion in this listserv. As you can see, the scope of these topics can be quite deep and theoretical.
-
Deaf/blind-deaf/blind marriages and deaf/blind marrying other, non-deaf and non-blind people. A deaf and blind man asked why deaf/blind-deaf/blind marriage rates were so low despite today’s technology that increasingly allows for long-distance contact. He talked about his own community of deaf people and noticed that many married “outsiders” (i.e. hearing people). He made a parallel to marriages among Asians and Caucasian, and furthered the discussion by considering partnerships among the LGBT community.
-
The use of webpages to make one’s academic presence known. Since a lot of information is exchanged through conversation, whether it be at a conference or during an informal lunch, deaf people can lose out on those benefits, which perhaps means we need stronger web presences with links to all of our work to better allow other scientists to work with us.
-
A debate over whether the old “Deaf and Dumb” phrase should be eradicated or recycled into something positive. In the past, the “dumb” part meant that a deaf person was mute, but a person on the listserv claimed that when oral deaf people — those who speak and generally do not sign — became more prominent, they viewed the “dumb” part as meaning stupid. (The ensuing conversation in the listserv became a bit rough, so one of the co-owners had to intervene to warn against further asperity.)
-
The history of deaf studies and deaf education. An older deaf woman commented that most of the scholars studying and describing deaf education were hearing and Caucasian. She felt that there was too much of a disconnection between the scholars and the people in the deaf community and argued that, as a result, deaf studies is filled with unproven and possibly facetious theorems. Her initial message also spawned a discussion about the failings of current deaf education.
-
Last, but not least … captioning in airline movies! A middle-aged dead woman said she had been on a United Airlines flight and couldn’t understand the movies because there was no closed captioning. Does this sound like a familiar story? Others responded immediately to the original email, with some saying that it was a violation of the Americans with Disabilities Act and the succeeding people correcting them by pointing out that airlines are under the Air Carrier Access Act. This discussion prompted me to post my (as of today) only message to the listserv, linking my blog entry and sharing my experience with airline movies. I was then pleasantly surprised to see that a deaf man who I met a few years ago was actually a subscriber to the list and had seen my message, so he became yet another person who has seen my growing blog.
I have to say that I was surprised that a mailing list like this existed and was active. It’s actually been around since 2002, so I wonder why I didn’t know about it earlier. But now that I have joined and blogged about it, hopefully this leads to another aspiring deaf academic to join the list. In the meantime, I’ve already started thinking about possible blog entries that expand some of the themes I explored in the mailing list.
First Thoughts on the Contego R900 FM System

I’m almost done with my first week at The University of North Carolina at Greensboro’s algorithms and combinatorics REU, and I’ve also had my first experience with the Contego R900 FM system.
For some reason, I’m particularly prone to worrying about technical difficulties, so I’m happy to report that the Contego R900 certainly works. It’s been particularly useful this past week given that my research advisor is relatively soft-spoken and has a high-pitched accent. As part of the REU schedule, she gave — in the span of two days — a total of seven research talks, each of which was about 45 minutes long. Fortunately, the FM system made it so that strictly understanding what she was saying was generally not the limiting factor in how much material I could comprehend from the presentations.
As you can see in the picture I posted above, the Contego R900 system includes headphones and an inductive T-Coil loop. Until the time of this writing, I actually thought that the loop was just a lanyard, so I used headphones to connect to the receiver. In general, I don’t like headphones, because to me they aren’t aesthetically pleasing and it’s hard to align them with hearing aids to allow maximum benefit. They can also cause some feedback, that classic “ringing” noise that every hearing-aid user knows. The man at Greensboro who provided me with the materials actually said that most people who use this system don’t even wear it with hearing aids. Later that day, I ran a quick test with a YouTube video on my laptop and using the FM system (which I placed on the laptop) without hearing aids. I had to churn up the receiver’s volume to its maximum level in order to obtain a reasonable level of hearing, so using the system without hearing aids was not an option for me.
I ended up putting the headphones just above the top of my hearing aids. Fortunately, they remained in place and caused no ringing.
Nonetheless, I’m going to switch to using the T-Coil loop in the future. I again ran some tests using my laptop, and it’s pretty weird how it works. The loop is made so that a person essentially has to be wearing it as if it were a lanyard in order to benefit from increased transmission.
I’m looking forward to using the Contego R900 in the remaining seven weeks of the REU. Later in the summer, I’ll probably write up a long comparison between the Contego R900 and the Phonak Smartlink FM systems.
Sublime Text
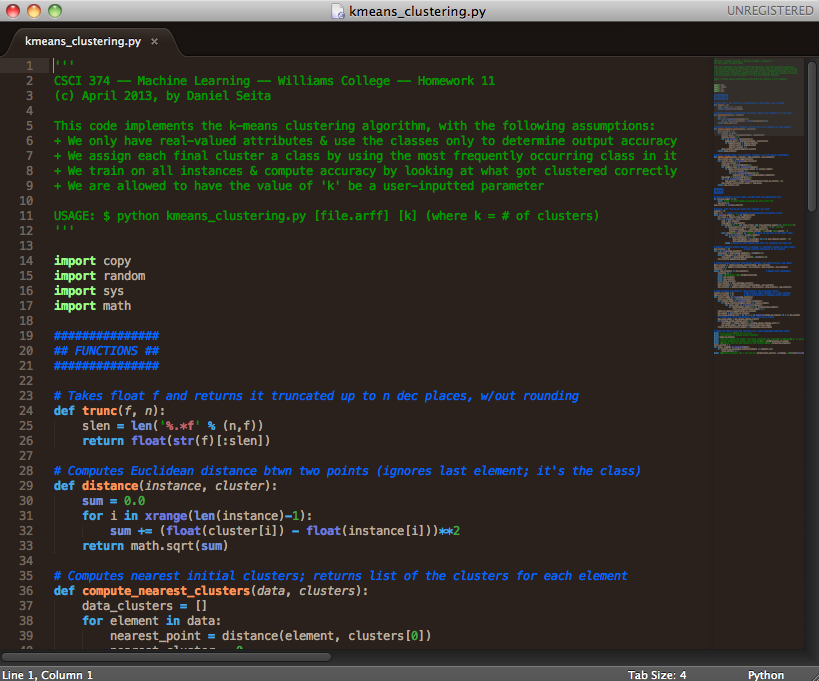
All right, let’s give this a shot.
This summer, I’ll be experimenting with the Sublime Text text editor. I remember being impressed by its visual appeal after seeing a classmate use it — so why not try it for myself? The above image demonstrates Sublime Text with my implementation of the k-means clustering algorithm, written using the Python programming language. To switch programming languages, all one has to do is click on the bottom right corner (where it says “Python” in the above image) and there will be about thirty options for languages, including C++ and Java but also some lesser known ones such as Erlang and Lua. This way, we get the indentation and coloring to look good. Better colors = better programming.
What about emacs, though? Possibly the biggest difference between Sublime Text and emacs, which for the past year was my editor of choice, is that Sublime Text generally requires fewer “special commands” to program and thus has a shorter learning curve. Emacs also seems to encourage the programmer to have his or her hands on the keyboard at the same spot all the time, since the manual recommends not using the arrow keys but using Ctrl+N, Ctrl+P, and other command to move the cursor over. This is because our hands won’t leave their natural position, unlike in the case when we use arrow keys.
I don’t think I’m at the point in my career where I need to really worry about this. If it’s really necessary for some situation, ideally I’ll know it in advance and can spend the months (years?) prior to it prepping by using emacs nonstop.
Now, if Sublime Text starts requiring us to pay for continued use, then I’m likely gone. Hopefully that won’t happen.
A Summer Without Sign Language Interpreters

When I know I’m participating in some structured activity or event (e.g. an internship), I typically try to get sign language interpreters.
This summer, though, I’ll be doing something different. As I mentioned before, I am going to be a research intern at the University of North Carolina at Greensboro’s REU in algorithms and combinatorics. In the linked entry, I actually said that I was trying to negotiate the use of ASL interpreting services.
I’m starting to think that this may not be the best idea for this particular setting, and I’ll have the summer to experiment with my new plan. The problem is one that’s been easily identified, both by me and by others. To put it simply, sign language offers comparatively little benefit to me when used in scientific and technical settings as compared to an English seminar.
Essentially, there must exist some technical/interpreting-benefit curve, where the two factors are inversely correlated. At the very technical end, such as a mathematics research talk given to people who are assumed to already know the topic in some detail, interpreting benefits are negligible. At the low end of the technical spectrum include English seminars, political talks, historical news, etc. I’m happy to have interpreters for those events.
I observed the high-end of the technical curve at the Bard College REU last summer. Even with the help of interpreters, I had enormous difficulty following any of the technical talks that were not in my area of focus (machine learning). And when I did understand concepts, it wasn’t due to the interpreters — it was because I focused intently on the speaker and whatever presentation accessories he or she had in hand.
This was clearly a factor in my decision not to have interpreting services at Greensboro. Another factor was my positive experience in my machine learning tutorial last semester. As part of the tutorial class format, I had weekly one-hour meetings with the professor and another student. Given that there were only three of us, and that we would be discussing highly technical concepts, it made sense for me to decline services, especially given that I had enough hearing to make it through those meetings. I sometimes used my FM system from Williams College, but it wasn’t necessary. An FM system, though, might be more useful for a research talk than a tutorial meeting.
So this summer, I asked and obtained permission to use Greensboro’s FM system, the Contego R900. This way, I’ll be entirely focused on the speaker, which I’m sure will do wonders for my comprehension. Adding in the fact that the groups at Greensboro will be researching in topics more correlated to each other than the Bard groups means that I am optimistic about what this summer has in store.
What’s it Like Being an Undergraduate Teaching Assistant?
I have been a teaching assistant (TA) at Williams College for the past four semesters, and will likely continue TA duties during my entire senior year, for a full six semesters of TA experience. (May update: I will be the theory of computation TA during the fall 2013 semester.) I therefore believe I can offer a reasonable explanation for what a TA does at a primarily undergraduate institution, especially if one is working in STEM fields.
First, a TA’s primary duty will be grading problem sets. The questions will range from straightforward computation to proof-oriented to programming. Grade them according to whatever scale or rigor the professor desires.
A second common duty will be to actually help students. These take the form of office hours (“TA Sessions”), but can also involve some lab supervision. In my opinion, this is a much more pleasant aspect of being a TA. Ideally, one will act like a professor and provide guidance to the student. It is crucial, though, not to give away big ideas or answers, though I understand if some students may want to check their results for some computation-heavy questions.
I do not believe it is standard for a TA to be grading exams, because those tend to be worth a much larger percentage of a course grade and there can be more peer pressure that could adversely affect one’s judgement. Furthermore, in undergraduate institutions, the professor has to do some grading, right?
For me, being deaf so far has not seemed to hinder my TA performance. TA sessions are rarely crowded, so it’s easy to get some one-on-one interaction with students. When it does get crowded, I tell everyone to calm down.
Anyway, I thought I would give three tips on how to be a good TA from the perspective of a person who has been on both ends of the student-TA interaction:
-
Don’t give away answers to complicated proofs right away. If a student doesn’t know where to start, offer initial guidance. If a student’s almost done, look and point out the weaknesses. Do not tell students to ask classmates for answers. (Incredibly, I had a TA tell me that before!)
-
If there are complicated problems that are hard to grasp, review them (and any solutions, if possible) before the TA sessions.
-
Do not read right from the solutions manual during TA sessions unless absolutely necessary. It makes students believe that TA sessions are a pure question-and-answer session.
And here are three extra tips for the aspiring TA who wants to maximize his or her experience:
-
Aim to TA courses where a high proportion of students type their homework, preferably in LaTeX. I’ve had enough trouble reading bad handwriting these past few years.
-
Aim to TA courses where at least two hours (but not much more than that) of TA sessions are required.
-
Aim to TA the upper-level courses, where students tend to be more serious about their subject. As a side note, they may be less likely to ask “What’s the answer?” and similar dumb questions.
An Inside View of RIT’s Accommodation Policy and its Limitations
During my senior year of high school, I was debating between two choices for college: Rochester Institute of Technology (RIT) and Williams. This comparison is unusual in a variety of ways and reflects my unique background and approach to the college admissions game. On the one hand, it doesn’t seem like most people were making this comparison. As someone who has talked to many other Williams students, most of the other schools they considered were among the elite liberal arts colleges (LACs) such as Amherst and Swarthmore, or they were renowned research institutions such as MIT and Cornell. From what I can tell, I might have been the only student in my Williams College graduating class to have seriously considered RIT. A few years ago, I discussed my situation with another Williams student, who promptly told me: “an obvious decision, right?” Unfortunately, it’s not that simple. The catch is that while Williams can claim to have benefits such as a significantly larger endowment and better college rankings, one of RIT’s advertised advantages is its accommodation policies that have been specifically catered to its large deaf and hard of hearing student population. Here are some of the interesting facts about RIT taken from their website (emphasis mine):
The RIT student body consists of approximately 15,000 undergraduate and 2,900 graduate students. Enrolled students represent all 50 states and more than 100 countries. RIT is an internationally recognized leader in preparing deaf and hard-of-hearing students for successful careers in professional and technical fields. The university provides unparalleled access and support services for the more than 1,300 deaf and hard-of-hearing students who live, study, and work with hearing students on the RIT campus.
The same page lists additional benefits for deaf and hard of hearing (DHH) students, such as paying reduced tuition. In addition, RIT is also cognizant of how deaf students may not be able to or may not want to use a traditional phone. When they provide a phone number for prospective students to call and ask questions, there is an alternative videophone number to call. A videophone is similar to Skype, except it is often used to call a regular phone number and allows a sign language interpreter to act as an intermediate messenger in relaying the hearing person’s voice over to the deaf person’s eye, and in some cases, relaying the deaf person’s signing to the hearing person’s ears.
Hence why I was forced to make a unique decision. On the one hand, I had a spot at a college that was ranked number one not just for small colleges, but for all American universities for two consecutive years (2010 and 2011) in the Forbes college rankings. On top of that, Williams had a renowned mathematics program, which was my intended major at the time of applying (I did not consider the computer science major seriously until my second year). But on the other hand, I knew that because they had no experience with deaf students, that I would have to continually advocate for myself and explain what was necessary to allow me to succeed. That presumably would not be a problem at a place like RIT which as mentioned earlier has over a thousand such students and has a whole staff of sign language interpreters employed by the college. The social aspect was also a positive for RIT; I can communicate with other students in sign language if necessary and have an easier time engaging in group discussions as compared to a situation with hearing students. I had to consider how much my family would pay. A Williams education costs significantly more than an RIT education (even with my needs-based financial aid), and I also received the best available scholarship for an RIT student, which would have reduced tuition to just a few thousand dollars a year. How, then, did I decide to attend Williams College? And after a few years of being able to reconsider my situation, can I say I pleased with my decision? Are there other things I’ve learned from RIT that affected my stance? I’ll investigate most of these questions in future blog entries.
Today, I want to focus on what I’ve learned from RIT and its accommodations over the past few years. Notice my wording earlier about RIT’s advantages. I mentioned that these are advertised advantages. But what is advertised may sometimes gloss over the truth, and I hope to shed light on this issue. As a disclaimer, please don’t view this article as an attack on RIT, even though it may seem like that occasionally. I still have an enormous amount of respect for RIT providing this much assistance to DHH students. I just want to emphasize that RIT, like any university, is not a “Utopia.” There are flaws in their accommodation policies system that I would like to point out. Many of them can be fixed.
But since I am not a student there, how much information can I know about RIT? And is it fair to emphasize my view of RIT, which is no doubt different from those of many other DHH students? I’ll present my case here and you can be the judge. First, I have visited the RIT campus many times, most notably during the summer before my senior year of high school. I participated in a weeklong residential program for prospective DHH students. Furthermore, I have also gleaned insight from other RIT students. Outside of Williams, I probably know more students at RIT than any other college. I have had the fortune of being able to interact with many DHH RIT students in my life, such as those hailing from my high school or the Summer Academy. Finally, my brother is a student there. Like me, he’s also deaf, and we have similar academic interests. Both of us are computer science majors and will be working at REUs this summer. But his experience at RIT thus far has revealed some inadequacies in their access services. I now focus on two of them in particular.
One of the defining points of RIT is its accommodation policies. On paper, if a deaf student requests interpreting services for a class, he or she should get it. What’s not entirely clear is whether a deaf student can have these services for classes that have multiple sections. During his first quarter at RIT, my brother wanted to enroll in a psychology elective course. As is the case in many universities, psychology is a popular subject, and the introductory course has multiple sections. Unfortunately, only one of the four or so sections offered that quarter had ASL (American Sign Language) support. The session with ASL services was in a poor time slot; it met just once per week from 6:00 to 10:00 PM. Furthermore, my brother had to take a required computer programming course the following morning
Now, you could argue that my brother had to live with this schedule. But if a hearing student wanted to maximize his or her study productivity and flexibility, it makes sense that such a student would sign up for a psychology course in a better time. DHH students are therefore denied the ability to have schedule flexibility. What RIT really tries to do is save money by packing as many DHH students in one section as possible. When my family tried to resolve this issue by emailing my brother’s academic advisor and the disability services department, we got no response. (The academic advisor, by the way, has to help about 700 students and can only offer generic high-level advice, which isn’t my idea of a helpful advisor.) After a week of negotiation and getting dangerously close to the start of the quarter, my brother was finally able to get services for a better class time after we emailed the Provost of the College with a lengthy written request. Discussions with other deaf RIT students — such as my brother’s roommate — confirmed these sentiments that RIT can “hurt” their schedule by forcing them to take classes at possibly undesirable time frames. I fortunately do not have this problem at Williams College, because the policy there is that I pick my courses, and the accommodations are then built in for me, not the other way around.
A second issue is that RIT’s classes can sometimes violate their own principles. During the spring 2013 quarter, my brother enrolled in an elective course about Viking history. Unfortunately, the class violated RIT’s accommodation policies. About half (literally) of the Viking history class time was devoted to watching movies that had no closed captioning. (This, by the way, seems ridiculous to me — why waste half of valuable lecture time watching movies?) This is despite how RIT has a rule stating that videos shown in class need to be captioned. When grading is weighted so heavily on participation and understanding movies, how is that class not able to escape such a basic requirement for deaf students? As every deaf student should know, sign language interpreters and other popular accommodations such as CART are no substitute for captioning. So I am certainly a little confused about this situation.
Even worse, when my brother wanted to drop the course, he couldn’t because the drop period (one week from the start of school) had passed. The course was taught in one four-hour session each week, and my brother learned in the second class that uncaptioned movies would be routine for half the class time. My brother’s only option was to withdraw from the course, but he would have received a “W” on his transcript, which would indicate to future employers that he was struggling in class due to his academic deficiencies. (Hint: he wasn’t.) He then had to do a lot of additional work to convince RIT to drop the class and avoid receiving an unjust “W” on his transcript. After another long and time-consuming effort, he was finally allowed to drop the course.
The previous two scenarios indicate the difficulty my family experienced in trying to protect my brother’s academic needs and rights. I don’t believe it should take a full family struggle to achieve two basic academic rights. My parents know the intricacies of both RIT’s policies and the American legal system and are willing to use this knowledge to achieve basic rights. What about the many other students who do not have this advantage and do not know they can petition to earn them? I suppose the message I want to send to prospective DHH students to RIT is that, while for the most part you’ll have what you need, you will still be at a disadvantage as compared to other hearing students and will continue to have to work extra hard to obtain privileges that hearing students might take for granted.
On a final note, another unfortunate incidence has popped up relating to RIT’s accommodations policies that I didn’t know of until the final draft of this post. I’m going to keep it confidential until I know more information, but it might be something I’ll investigate later.