My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
The UNC at Greensboro’s CS/Math REU
This summer, I am going to participate in the University of North Carolina at Greensboro algorithmic combinatorics on words REU. The research there pertains to algorithms and theory of computation, so I’m diverging from machine learning (at least for a short while). This will be my second REU experience, and I hope to make the most of my eight weeks there. Now, the task is to contact their administrators — starting today — so that I can set up my accommodation services (sign language interpreters). I don’t know of a way to do this other than to just keep emailing them about suggestions, so that’s what I’ll be doing.
I haven’t done a whole lot of writing this past month, and it’s going to be even more difficult with the general GREs coming up in less than a week. But I’ll probably do more writing after that.
Why Grades Are More Important for Deaf Students

I have long wondered how much effort students should expend to achieving high grades. Dr. Philip Guo has a nice article about this that I found to be accurate and straightforward. Those applying to medical school and competitive law or graduate school positions need high grades. On the other end of the scale, students inheriting a family fortune need not worry about graduating with honors. As expected, the amount of effort and dedication a student spends on getting good grades is dependent on a variety of circumstances. Students should also understand that putting too much focus on doing well academically might mean they neglect other important aspects of preparing for the workforce.
One other thing I would like to add on is that the importance of grades also matters when considering a person’s skills in intermingling, networking, and socializing. Intuitively, the reasoning seems obvious: people who are the best networkers and orators can reach out to a broader audience and can translate those skills into benefits while on the job. If a student was not among the top half of his class in college, but absolutely dominated the work he did in a summer internship by taking advantage of his extroverted personality and social understanding, then he will be the one getting a full-time job offer after college.
This does not bode well for deaf students. Many people in the workforce will, unfortunately, have a natural tendency to worry about a potential deaf employee. This may be worse in jobs that require tremendous communication among workers. And very often, deaf people will have a harder time making up for that difference with social ability.
That is why I argue that deaf students should spend lots of effort towards their grades.
The claim that high grades matter can be supported by arguments that simultaneously show the benefits of attending a prestigious undergraduate institution, which Dr. Guo has also written about on his website. The biggest one is that they help recent college graduates get started. Here’s what Dr. Guo says:
Carrying a name-brand diploma gives you the largest boost in credibility right when you graduate, the proverbial “helping to get your foot into the door.” […] As you progress in your career and move onto successive jobs, then carrying a name-brand college diploma matters less: Intermediate and senior job candidates are evaluated mainly based on their prior work experience, so if you’ve done a great job and received positive recommendations, then that could more than make up for your lack of a name-brand diploma.
You can say similar things about GPA. It matters more to a 25-year-old candidate for his first software engineering job, but it matters less when interviewing for upper-level management positions. As a current example — literally, since the linked article was posted up seven hours before this blog entry — a math professor at my college was just named Southwestern University’s 15th president. Do you think Southwestern’s evaluation committee placed a heavy emphasis on his GPA? Not a chance, even though he did graduate summa cum laude from Connecticut College. (But wait … that might have gotten him in graduate school in the first place!) The selection committee probably highlighted his experience as a renowned innovator of mathematical education, as evident by his well-earned Robert Foster Cherry Award for Great Teaching.
Likewise, a high GPA can help make up for an employer’s initial negative impression of a deaf job applicant. (Notice that I’m not implying that people do this. I can only speak for my own experience and those of other deaf people I know. And this doesn’t imply that all employers do this, nor does this vitiate their recruitment process.)
Once people can successfully get started in a job, it’s up to them to live up to expectations.
Why Computer Science is a Good Major for Deaf Students

Many people have asked why I am drawn to computer science. I thought that instead of trying to come up with an answer extempore each time, I would put this in writing to provide a better quality explanation. I will place a special emphasis on how computer science can particularly benefit deaf people. (As well as those who are hard-of-hearing.) This post will probably be one of the few that I’ll regularly come back to revise in the future.
What is Computer Science?
Before delving deeper, we need to understand the definition of computer science. Before coming to college, I held the naive assumption that computer programming == computer science. But that’s far from the truth, even though many aspects of computer science involve programming. In the context of computer science, I view programming as a mechanism for expressing something that I have learned or have rigorously analyzed and derived. To modify a phrase my math professor once wrote, m**ost programs in computer science courses are mostly trivial. This means if you understand what you’re supposed to be doing, the programming itself isn’t all that challenging. There might be some syntax issues or compiler errors that you’ll have to deal with, but for the most part, those should be straightforward to correct. Analyze error messages and read documentation to find the fix, or ask on StackOverflow. The difficulty, as mentioned before, is understanding what you need to do conceptually before performing the application.
That being said, let’s take a look at what a computer science major entails. I focus chiefly on the computer science major and not related majors, such as computer engineering or electrical engineering. A typical undergraduate course load in computer science will take on some of the following classes:
- Programming 1 (Introduction to syntax, control structures, etc.)
- Programming 2 (Data Structures)
- Algorithms
- Architecture
- Artificial Intelligence
- Compiler Design
- Concurrent, Parallel, or Distributed Systems
- Graphics
- Networks
- Operating Systems
- Programming Languages (Not to be confused with introductory programming)
- Software Development and Engineering
- Theory of Computation
- Several math and statistics classes
- Advanced versions of any of the previous classes, as in a graduate-level class
I asseverate that, in general, students take the two programming classes first, followed by algorithms and architecture in some order, and then as many of the other classes that fit their interests or are required. (In my school, programming languages and theory are required.) Architecture and algorithm courses are both crucial for a complete computer science education. Architecture focus on how computers function at the lowest level, discussing issues ranging from hardware to digital logic, while algorithms takes a more mathematical perspective and involves analyzing the efficiency of solutions to problems.
The programming classes tend to form the introductory courses of a computer science major because it is essential that students are acclimated to programming for the upper-level classes. Consequently, the primary objective for those beginning classes is to form a working program. For upper-level courses, creating a program is no longer the main bottleneck; they are simply necessary to carry out, express, prove, or support an experiment or project.
So hopefully I gave a nice introduction for those who aren’t familiar with computer science. With that in mind, we can focus on its benefits, with a bent towards the needs of deaf students. We’ll first talk about benefits within a collegiate or university setting, and then for post-college life.
Group Work & Easier Communication
In my opinion, it is much harder for deaf students to socialize among hearing students. There are a variety of reasons for this, the most notable of which is the barrier between speech and hearing. I believe that a good major for a deaf person will incorporate a significant social aspect to it. And that’s one of the ways computer science can help.
Many computer science courses allow students to collaborate together in groups on homework assignments or projects. I know of many classes, some of which I have taken, that required group work. This is already a boon, but it gets magnified upon realizing that computer science group works tends to be group programming, so most of the work is in text, which should not a barrier for deaf people. A strong group for a lengthy computer science project will utilize extensive code documentation and a journal of the group’s progress, all of which pose no more difficulty for a deaf person to follow and comprehend as compared to a hearing person. In the case of when no interpreters are around and a deaf person can’t communicate, the group can use their computers to quickly write down any necessary instructions or objectives.
No Seminars!
A seminar is a class composed of small students who discuss on a certain topic, with the expectation that students will actively participate. They are predominant in the humanities where class discussion and participation play vital roles in helping a student better understand the course material.
But they are also disadvantageous to deaf students, and it’s fairly easy to see why. With class discussion, students can quickly take turns talking, and very often those who manage to raise their hands first will get the chance to participate. If a topic is particularly popular or heated, a deaf student may find it very difficult to participate as he or she will have to wait until understanding what the fellow students have said, and that gets delayed by the natural lag of sign language interpreters and CART as compared to normal hearing. Also, one of the more embarrassing things that can happen in seminars is if one makes a compelling and passionate argument, only to find that a student had previously provided those insights to the class. Of course, if that happens, a deaf student can explain that the misunderstanding came from the urge to quickly participate in the seminar format. But why be in a class that can offer that kind of risk?
It’s no coincidence that I enjoy lectures far more than seminars. But the good news for computer science majors? You (hopefully) won’t have seminars. My college has no seminars in computer science, and I’m sure many other schools are similar in that regard. It’s a different story if you’re one of the small fraction of students entering a Ph.D program and sign up to take a research seminar, but how many students do that?
Growing Support Groups
Recently, there’s been a pleasant surge in the number of groups, mailing lists, organizations, and other entities designed to help support deaf students in STEM fields. I can personally vouch for the Summer Academy as a strong example of this. Briefly, the program was founded in 2007 by Richard Ladner and allows about ten deaf and hard-of-hearing students to attend a nine-week, residential program at the University of Washington in Seattle where they take one computer science class, one special animation class, have talks, and participate in field trips. The program is free for students.
Not surprisingly, diamonds like these don’t come around very often. The Summer Academy concludes with a community premiere, where students present their work and outline their post-graduate plans in front of an audience of about 100. Just by observing the audience, I could tell that many were middle-aged deaf residents of Seattle who were pleasantly surprised with what the program had to offer. A common theme in their sign language conversations was: “This kind of program never existed when I was younger!”
This network of support is assuredly a product of how today’s world has become unquestionably more accessible year by year. Sign language interpreters began to regularly populate schools with deaf students in the late 1900s, with more arising when The Americans with Disabilities Act was passed in 1990. Then again, it still took until 2007 and a well-known professor before the program got funding.
Aside from the previously mentioned Summer Academy, another possible resource for deaf computer science students is DO-IT (also related to the University of Wshington). I’m on their mailing list, and I regularly receive emails about technical internships where employers are targeting students with disabilities.
Ability to Easily Conduct, Perform, or Verify Tedious Tasks
This is one of the benefits that can apply to anyone, not just a deaf person, but I will include it here as it can potentially be extremely useful. As a computer science major, you are required to know how to program. Even if you never have to program outside the class, having the ability to do so can help you in a variety of circumstances. You might, for instance, have a probability class that assigns questions such as “how many ways can we form a group of blue and red marbles if…,” and a simple Python program can verify your answer. At work, you might be casually wondering to yourself: if we can get about X new customers a day while keeping the same prices and retaining all previous customers, how much will we benefit? Again, just fire up a script on your terminal or text editor and do this. Obviously, this would mostly apply towards casual thoughts, but I find that having that kind of intuition helps me better understand the scope of a topic.
It is true that this previous advice is more useful as a reason to why you should take one computer programming class, rather than major in computer science. But inevitably, the more computer science classes you take, the more programming becomes an inveterate activity, and therefore, these “casual” programs are easier to write and can be applied to a wider variety of circumstances.
Being Computer-Literate in a Technological World
From the printing press to the scientific method to today, data and technology have been expanding exponentially. Thus, it is crucial that people understand what is out there and how it works. As an example, deaf people should be aware of the latest advances in cochlear implant and hearing aid technology. Just recently, a hearing aid was now upgraded to be completely waterproof. And by “just recently,” notice that the linked blog post is dated as January 21, 2013.
I claim that part of the responsibility as a computer science major is keeping up with the news on any latest advances in their field. Furthermore, especially if you understand electronics, you might be able to better understand the detailed description of a device, how it works, and its usefulness compared to other competing goods, all excellent qualities for the prescient buyer. And of course, you get to explain this to all your friends!
Strong Accessibility at Work
One of the biggest concerns deaf students may have is job accessibility. Sure, we can bank on the Americans with Disabilities Act to help us in a pinch. But why not avoid this trouble in the first place, and aim for companies that clearly have no issues in hiring qualified deaf employees? The good news is that there are plenty of these in the computer science industry, such as Microsoft. A deaf employee there personally told me this: Microsoft is one of the most accessible companies out there. You can ask for an accommodation and you will get it. Also, as I said earlier, I am regularly informed of internship opportunities for deaf students in computing, so there are places reaching out. Perhaps computer science firms, a relatively new phenomenon in today’s world, are up to date on all the latest laws related to accessibility. For this, I commend them.
Closing Thoughts
Hopefully this was an explanation that elucidates most of the reason why I decided to major in computer science. It’s not the entire reason, but then I would be going on and on about how theory is so scintillating, and that doesn’t quite help to spread the word about computer science. Part of my aim in this blog, for instance, was to explore connections between computer science and deafness. I hope this was a small step.
Deaf Computer Science Ph.D.s
As any regular reader of this blog knows, I’m almost certainly heading to computer science graduate school directly after college. This got me thinking about an obvious question: how many deaf people have computer science Ph.D.s? I’ll limit the answer to those who earned them from American institutions, though if anyone has information about other countries, please let me know either via comments here or by email (see the “About” page).
A simple Google search and some outside information led to these people:
- Karen Alkoby (Ph.D., DePaul University, 2008)
- Raja Kushalnagar (Ph.D., University of Houston, 2010)
- Christian Vogler (Ph.D., University of Pennsylvania, 2003)
One thing that struck me was their Ph.D. dates: 2003, 2008, 2010. That’s awfully recent, and that’s a sign that there may be some other deaf students currently enrolled in Ph.D. programs. I don’t know of any.
Another thing that was interesting is that, while all are professors, none of them are actually computer science professors! Dr. Kushalnagar is in Information and Computing Studies at RIT, Dr. Vogler is in Communication Studies at Gallaudet, and Dr. Alkoby is in Gallaudet’s Business department. Of course, the lack of a Computer Science department at Gallaudet is likely a factor.
I’ve never met nor talked with Dr. Alkoby, but I met Dr. Kushalnagar a few years ago and recently had a video chat with Dr. Vogler, so I can say a bit more about them.
Dr. Kushalnagar and I met at the 2011 Summer Academy. He was raised in India and took a heavy math and science curriculum in high school. Due to his family’s strong educational values, he not only got a B.S. from Angelo State University, but he also has the uncommon combination of a computer science Ph.D. and a law degree. His research interests deal with deaf education, and he acts as a primary tutor to deaf computer science students.
Dr. Vogler and I both think that Dr. Vogler was the first deaf person to earn a computer science Ph.D. — at least in the United States — and we also believe there are three deaf computer science Ph.D.s. He and I appear to possess similar hearing loss levels and communication ability. Dr. Vogler used “ASL” accommodations while he was in conferences and taking classes at the University of Pennsylvania. (By the way, Williams College currently has three alumni at Penn’s computer and information sciences Ph.D. program, and I may be applying there.) His key suggestion was that, when faced with a technical term dilemma, “ASL” interpreters need to abolish the standard grammar of the language and focus more on a direct English translation. Yes, it will involve a lot of finger spelling and some confusion, but trying to comprehend such technicalities on top of ASL’s grammar is not convenient for effective communication.
The PhD Grind — Philip Guo’s E-book

Today, I read Philip Guo’s e-book The Ph.D. Grind. It’s completely free (just visit the link and download) and it’s fairly easy reading, so one should be able to finish in about an hour or two. After reading it, I was both enlightened and impressed. The book seemed to accomplish its goals: provide a clear — but not overly detailed — account of a computer science graduate student’s journey to obtain a Ph.D. (Philip Guo was a Ph.D. student at Stanford University.) One of the reasons why I like it is that the author included many examples of how he struggled during his first three years of his Ph.D. program, and more importantly, why those struggles occurred. By the end of the book, I was pondering to myself: can I avoid the pitfalls he encountered, and intelligently grind away at a publishable project? As you can tell, some amount of “grinding” is necessary; otherwise, you’ll never make any progress. But if you go entirely on the wrong track — that is, if you’re working hours and hours by yourself on a famous professor’s project without any direction — that’s not a good idea.
Possibly more than anything else, The Ph.D. Grind taught me the value of (at least initially) working with assistant professors and postdoctoral researchers. The reason is quite simple.
They are the ones under the most pressure to publish.
The assistant professor needs to publish for tenure; the postdoc needs to publish to get an assistant professorship. Now, that’s not to say a Ph.D. student should never pick a tenured professor to be an advisor … it’s just that the student might want to be part of a research group that’s composed of at least one non-tenured faculty.
Some of my quick thoughts after reading this book include:
- I absolutely, positively want to get a graduate fellowship.
- I should talk with all assistant professors at whatever university I’m at (for graduate school) and offer my services.
- I cannot, unless circumstances are extremely unexceptional, work all day on a project
- Aim for top-tier conference publications earlier; it makes the process of actually writing the thesis a formality.
To wrap things up, I recommend The Ph.D. Grind especially to undergraduates who are considering pursuing a Ph.D. in computer science. Again, it’s free and easy to read.
RIT’s Computer Science REU
Just as I did last summer, I browsed through the list of computer science REUs listed here to figure out possible research sites for this summer. While I was reading through Rochester Institute of Technology’s computer science REU, I noticed something unique about their award abstract:
[…] With specific recruiting efforts that target underrepresented groups such as women, minorities, and persons with disabilities, especially deaf and hard-of-hearing students, this REU program also aims to increase the size and diversity of the scientific workforce.
Most of these REUs embody the NSF’s commitment to increasing diversity among the next generation of scientists. In almost all cases, however, these award abstracts do this by encouraging women and minorities to apply. There are a handful that mention disabilities, though, but only RIT’s site specifically mentions deaf and hard-of-hearing students.
While it is a bit frustrating to me, it does make sense for convenience. In the United States, according to this and this,
- Women compose roughly 50 percent of the population.
- African Americans, Latin Americans, and Native Americans compose roughly 30 percent of the population.
- People with disabilities in the late teens and young adult group compose roughly 5-8 percent of the same aged population.
I had to approximate a bit with #3, but it’s clear that it’s a minority even compared to #2. And then there an extraordinary number of subdivisions of disabled people, and even then a range of severity for each kind. It is best to conflate these into one general category, but I do wish that institutions trying to promote diversity would add on the category of disabled people to women and minorities.
By the way, I didn’t apply to the linked REU at RIT. Their grant money apparently ran out in 2012 and the NSF didn’t renew it. Perhaps they will reconsider this year.
A Surprising YouTube Tutorial on Weka

My new research project is underway. It involves the use of a web crawler that can reach the computer science home pages for colleges and universities across the country. That web crawler can then try and derive data from web pages belonging to individual computer scientists. Given that data, is it possible for us to determine a set of features that will indicate whether the web crawler has found the homepage of a female computer scientist? If so, then it might be possible to reach out to those people by adding them to mailing lists, such as the one belonging to the CRA-W. I hope to learn a lot during this project, and I’ll probably discuss it later on Seita’s Place.
Since this is a machine learning project, I’m using the Weka software to help me run experiments and determine what features in the data are most useful in indicating whether a homepage belongs to a female computer scientist. An example of a feature I think would be very indicative is the number of times the pronoun “she” appears. Another one might be how often a name appears in an index of common American female first names.
Because I’ve never used Weka before, I looked at this tutorial on YouTube. I wasn’t planning to watch the whole thing, since I just wanted to see what the user’s settings were, where he clicked, and other small things. But I was surprised to see that there were complete and correct subtitles for the entire 23-minute video! This wasn’t the Google captioning that you can just click on for most videos. This guy, Brandon Weinberg, actually inserted a full transcript of his spiel. Major kudos goes to him.
Don’t you wish that every YouTube video could be like this? That would be a nice Christmas present for me in 2030.
How Should the Deaf Manage to Understand Foreign Accents?
According to the National Science Foundation, the fields with the highest proportion of international students in American Ph.D programs are computer science, engineering, and mathematics. The majority of these students are from China, India, or South Korea. These statistics worry me, but not because of the increased competition for precious few spots in respected doctoral programs. From what I can tell, it’s generally easier for American students to get in Ph.D programs as compared to foreign students. I won’t get into the exact reasons, as that’s enough for an entirely different blog post.
But what I am worried about is how I will communicate with those foreign students. Many have accents that make it difficult for me to understand their speech. I encounter this problem frequently at Williams College, where about eight percent of the student body is international. Even the most simple conversation might require me to ask my conversationalist to repeat sentences multiple times before I understand it, and can leave both of us feeling awkward.
So how can a deaf person fix this problem? If you have enough hearing to easily converse with most Americans, one thing I strongly recommend is to actively continue to talk with people whose accents are difficult to understand. If you see those people alone, start a conversation! The worst thing you can do is avoid them or, failing that, gently nod at whatever they say. Rebuff any of those actions! The logic is quite simple; the more you talk with someone, the more you get used to his or her style of speech. And eventually, though it might take a while, conversations will require fewer and fewer “Pardon?”s and “What?”s that are an all too common occurrence in my life. As a case in point, my ASL interpreters have told me that I can understand the voices of certain international students at Williams College better than they can. Not coincidentally, they’re among the students who I’ve talked with the most.
This is important to me because I’m going to have to manage this in graduate school. The strength of a Ph.D program depends in part on the quality of its students. In strong computer science programs, I’m sure many foreign students have enough background (i.e. at a Master’s level) to pass the qualification examination on day 1. Clearly, these students are valuable resources for me. Almost all current research is the product of collaboration of at least two people, so I’m going to have to communicate with my peers if I participate in a project with them. They are the ones who I can learn the most from, so let’s start talking.
CS Theory Part 4 of 8: Introduction to the Turing Machine

And here we are with what I think is the most important “new” concept in this course: the Turing Machine. Roughly speaking, these are automata that are equivalent in power to what we think of normal computers today. Therefore, any problems that are unsolvable by Turing Machines are beyond the limit of current computation. Let’s briefly go over the automata we’ve seen thus far:
- Finite Automata (DFAs and NFAs)
- Pushdown Automata (PDAs and NPDAs)
- Turing Machines (TMs, NTMs)
The N’s denote the nondeterministic versions. In other words, they allow multiple branches of computation to proceed simultaneously, rather than having one strictly defined path for each input string as would be the case with deterministic automata.
Here, the automata are listed in order of increasing power. Finite automata recognize the class of regular languages. Pushdown automata recognize the class of context-free languages. All context-free languages are regular, but not all regular languages are context-free. This is why pushdown automata are considered more “powerful” than finite automata, with respect to computability. Their infinite stack gives them more memory that can be useful to solve certain non-regular languages.
But Turing Machines (abbreviated as TMs), which recognize the class of decidable and recognizable languages (to be explained in a future blog entry), take things a step further. Like finite automata and pushdown automata, TMs have states and use transition functions to determine the correct path through states to take upon reading in an input string. But they have an additional feature called an infinite tape that is depicted in the picture above. There is also a tape head that reads in one symbol from a TM. This is a fairly abstract concept, and it’s often surprising to first realize that this simple addition to an automata allows it to recognize the class of all computable functions.
For instance, if we wanted to compute the value of a function, such as a function that returns a value twice as much as its input \(f(x) = 2x\), then assuming our alphabet consists of 0s and 1s, the infinite tape starts with the binary symbol for the input, and then once the computation is over, contains the binary symbol for the output. Thus, the infinite tape can be the medium for which input/output occurs. Obviously, a TM must have some way of modifying the tape, and there are two ways of doing so.
- The function \(\delta(q, a, L) = (q', b)\) means that, if at state \(q\) and the head reading in an \(a\), the TM will replace the \(a\) with a \(b\) on the tape, move to state \(q\), and move the tape head left.
- The function \(\delta(q, a, R) = (q', b)\) means that, if at state \(q\) and the head reading in an \(a\), the TM will replace the \(a\) with a \(b\) on the tape, move to state \(q\), and move the tape head right.
That’s literally all we need to know about a TM’s transition function. That the tape head can move along the infinite tape and replace symbols on the tape from anything in the TM’s pre-defined “tape alphabet” is what allows a TM to go through a computation. There’s a small caveat: we obviously need a place for the tape head to start out on the tape! So when we say the TM’s tape is infinite, we really mean it’s infinite in the rightward direction. That is, there is a “bumper” that indicates the start of the tape, and the rest of the tape extends to the right. Therefore, if the TM’s tape head is on the first symbol of the tape, it can’t move left since the bumper prevents it from doing so. Thus, having a transition function that causes the tape head to move left while at the leftmost symbol of the tape will just leave the tape head where it is.
Another important thing to know about the tape is that, since it’s infinite, we need to have a symbol on each component. The input string takes up the first few segments of the tape, but beyond that, the tape is composed of what’s known as the blank symbol. These are part of the tape alphabet, so it’s legal to put them on the tape, as well as replace them if necessary.
The infinite tape is not the only feature that makes TMs different from finite automata (for instance, TM’s have only one accept and one reject state, and their effects take place immediately), but it’s by far the most important one. To understand a TM, it is necessary to have a “good feel” of how the tape works in your head. I can’t emphasize this enough. Don’t waste time trying to get the technical details of the Turing Machine. Use a high-level view of them. Make sure you get an intuitive understanding of how they work. I like to do this by imagining arbitrary computation paths and moving the tape head around the infinite tape.
Let’s do a quick example question that highlights the importance of understanding how a TM works over the nitty gritty details.
Example Question and Answer
Question: Say that a write-once Turing Machine is a single-tape TM that can alter each tape square at most once, including the input portion of the tape. Show that this variant TM model is equivalent to the ordinary TM model.
Answer: We first show how we can use a write-twice TM to simulate an ordinary TM, and then build a write-once TM out of the write-twice TM.
The write-twice TM simulates one step of the original machine by copying the entire tape over to a fresh portion of the tape to the right of the portion used to hold the input. The copying procedure marks each character as it gets copied, so this procedure alters each tape square twice, once to write the character for the first time, and again to mark that it has been copied, which happens on the following step when the tape is re-copied. When copying the cells at or adjacent to the marked position, the tape content is updated according to the rules of the original TM, which allows this copying procedure to simulate one step of an ordinary TM. (Minor technical detail: we also need to know the location of the original TM’s tape head on the corresponding copied symbol.)
To carry out the simulation with a write-once machine, operate exactly as before, except that each cell of the previous tape is now represented by two cells. The first of these contains the original machine’s tape symbol, and the second is for the mark used in the copying procedure. The input is not presented to the machine in the format with two cells per symbol, so the very first time the tape is copied, the copying marks are put directly over the input symbol.
Quite nice, isn’t it?
Deaf-Friendly Tactic: The Power of Two
I’m someone who tends to do a lot of work solo, but once in a while, I see myself working in groups. This typically arises during academic settings, but is a broad enough concept to be applied to any areas of life. There have been advantages and disadvantages of working in groups, but one thing is clear: there’s a clear correspondence between the number of people in the group and my level of enlightenment, productivity, and satisfaction. I imagine that many deaf people will agree with this simple tactic that I call the Power of Two rule:
Divide people into groups of two.
If that’s not possible, then try three people, then four, and so on … but always be sure to use the minimum amount of people in each group possible. Why do I consider this a deaf-friendly tactic? Because it’s much easier to communicate in a one-on-one setting as compared to a many-on-one setting.
Let’s compare the two situations. Suppose a professor of a college computer programming class assigns students to work together in groups of three on some major project. (Furthermore, suppose there’s one deaf student in the class.) Assuming all three students are roughly at the same skill level, I can see three situations arising.
- One student dominates the decision-making of the project, and acts as the de facto leader, while the other two essentially obey orders. The workload may or may not be equal, but what stands out here are the social dynamics between the leading student and the two others.
- Two students become closer to each other, while the third is more or less isolated, relegated to following the lead of the other two. Again, I’m intentionally ignoring the workload here — maybe the isolated student works more, less, or just as much as the other two.
- The three students are equally close to each other. In other words, if we were to assign a measure of how friendly two students were to each other, the score would be roughly equal for all three of the possible pairings of the three students.
From my experience, #3 rarely happens, unless the professor was lucky enough to assign to a group three students who knew each other equally well. And I believe #2 probably happens more often than #1. The more I think about it, the more I believe a deaf student mingling with hearing students is likely to be the unfortunate third ring in the social group. From a hearing person’s perspective, he or she basically has the choice between interacting with someone who can talk and hear just as well versus someone in which communication tends to be more difficult and may require third party assistance. Given the convenience, why wouldn’t that person opt to talk with the hearing person more often? Obviously, I’m ignoring tons of extraneous factors, but I consider them irrelevant to my main argument.
But if there’s only two people in a group … isn’t that much more helpful to a deaf person? Now, there’s really no choice for either member of the group not to communicate with his or her partner. Moreover, I believe that in a group of two, members become more comfortable having personal discussions without the third person. So the benefit of two people is that, as they hash through ways to complete a project, the collaboration among the two is on a closer level than with three people. Both members also have a larger say in the decision-making process as compared to if they were in a group of three. Thus, it becomes easier for the members to know exactly what’s going on in their project.
So to anyone thinking about dividing up people, I suggest keeping the “Power of Two” rule in mind.
[This post is part of a series that I started here.]
The One-Year Warning for NSF Graduate Fellowships
After talking with someone who was toiling away at his physics National Science Foundation (NSF) Graduate Fellowship application, I checked the NSF website and saw that November 13 is the deadline for 2013 GRFP applications in computer science. As it’s the beginning of November, I’m aware that I probably have more important things to worry about than an application deadline that won’t affect me for at least another year. (Hey, I heard the Presidential election results will be out in a few days….)
But in the back of my mind, I know it’s almost certain that I will be applying for a computer science NSF Graduate Fellowship next fall. I’m not sure how I’ll handle that along with four courses (one of which will be a thesis), graduate school applications, and likely some teaching assistant duties, but I’ll manage.
One thing that caught my eye from the NSF website was this text:
The NSF welcomes applications from all qualified students and strongly encourages under-represented populations, including women, under-represented racial and ethnic minorities, and persons with disabilities, to apply for this fellowship.
So does that mean that a deaf person, like me, has a slight advantage in receiving a fellowship, as compared to similarly qualified students? It sounds like it, which can only be good news for me. I’m not sure how many deaf computer science Ph.D students have received NSF Fellowships. (A quick search online gave me no results.) I’m obviously hoping to be one of the few to get this ultra-competitive fellowship. I am curious, though, as to how much of my application should focus on being deaf. Should it be the main topic of my application essays? Should I make it one of many points as to why I would be a nice candidate for a fellowship? My college application essays focused almost entirely about my being deaf; given my lackluster acceptance results, perhaps I shouldn’t talk about being deaf that much? But then again, the application fellowship has several required essays encompassing a variety of topics; I should probably avoid talking about deafness on, for instance, the previous research essay, since my previous research hasn’t had anything to do with being deaf.
Obviously, this is just pure speculation as I ponder about the NSF Graduate Fellowship program. The next few years for me have the potential to give me an enormous head-start on my future career. I’m crossing my fingers that everything will proceed as planned. But for now, I thought I’d post this up here to remind myself of an important date to keep in mind for the next year.
CS Theory Part 3 of 8: Context-Free Grammars
(Note: I’m aware that I’ve been a bit computer science heavy in the past month; I’m working on getting additional topics up here, but time is scarce, and I may end up revising these posts a bit in the winter.)
We’re moving on to the next unit of Theory of Computation, which deals with context-free languages. These are a special class of languages that contain the regular languages, but a few other non-regular ones. (See CS Theory Part 2 for ways in which I prove certain languages are not regular.) What makes them different as compared with regular languages is that languages are context-free if we can derive a context-free grammar that describes it. A grammar is simply a way of constructing strings using a set of terminals and variables. Consider the example below.
\[S \longrightarrow T1T \\ T \longrightarrow TT \mid 0T1 \mid 1T0 \mid 1 \mid \varepsilon\]This grammar will generate the language containing all strings that have more 1s than 0s, assuming the entire alphabet is composed of just 0 and 1.
Clearly, using grammars to generate languages is more powerful than regular expressions, because of the ability to generate non-regular languages. To derive any string from the language, we start with the variable \(S\), which generates a required 1; this is necessary because in order for a string to have more 1s than 0s, we must have at least one 1 as the string “1” is clearly in the language. But \(S\) generates another variable with that 1, which we call \(T\). This \(T\) can recursively expand to generate an infinite number of strings. For each derivation, we substitute the \(T\) with a randomly chosen derivation, such as \(0T1\). The derivation process ends when we have all non-terminals (i.e. 0s and 1s), and the resulting string formed will be a member of the language. The language described above is non-regular because any DFA recognizing it would have to keep track of how many 0s and 1s there were, and there could be infinitely many of them.
I now want to introduce a new finite automaton called pushdown automata, These are analogous to NFAs in that constructing a pushdown automata (PDA) that recognizes a given language is the same as showing that the language is context-free. Thus, to show a language is context-free, either (1) construct a context-free grammar generating it, or (2) construct a PDA recognizing it.
The main difference between NFAs and PDAs is the stack component of the PDA, which is empty at the start of an input string but can have alphabet symbols (e.g. a 0 or a 1) or arbitrary symbols added as the input string is read. This is the heart of why context-free languages are a super set of the regular languages; an NFA is a PDA, but a PDA provides additional counting and memory capabilities, which allows languages, such as the canonical non-regular language of \(\{0^n1^n \mid n \ge 0\}\), to be considered context-free. Like NFAs, we can easily draw PDAs to recognize languages using states and transition arrows. This time, when making a transition arrow, we use symbols of the form \(a, b \longrightarrow c\). This is saying “if we read in \(a\) as input, we may pop \(b\) off the top of the stack and add on \(c\)”. Note: if the symbol on the top of the stack doesn’t match the transition function, that computational path dies. Furthermore, \(\varepsilon\) can be used anywhere in the transition function, as we’ll see in the always-necessary example later.
Example PDA
What language do you think this PDA recognizes? Note: the dollar sign is added on the stack before the first character is read; it’s used solely to indicate the bottom of the stack.
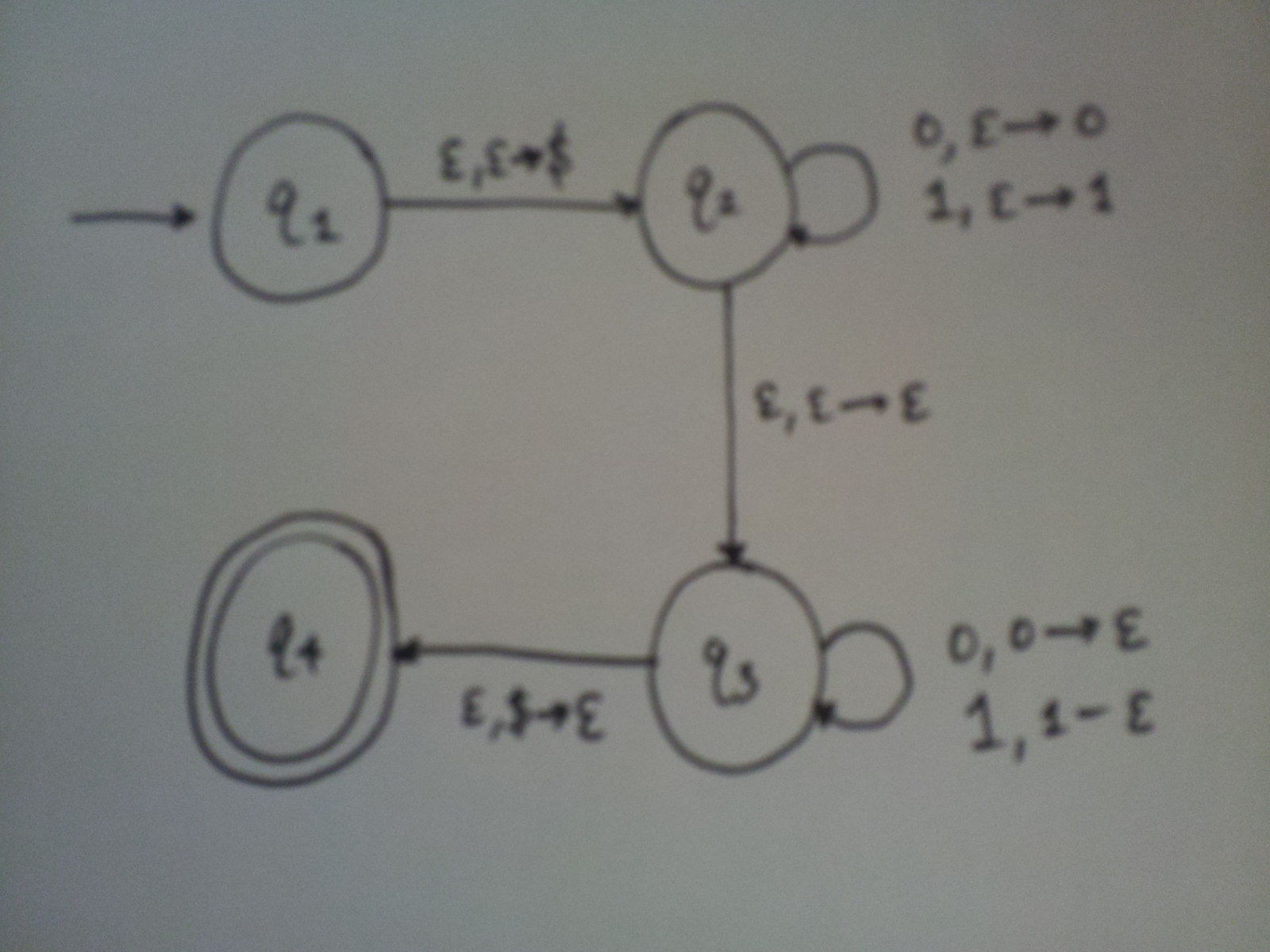
The above PDA will accept all strings that recognize the language \(\{ww^R \mid w \in \{0,1\}^* \}\). It nondeterministically guesses where the middle of the input string will be, and tries to pop off stuff from the stack from that point on. Since we have nondeterminism here, we are guaranteed that if a string is in the language previously described, then it will be recognized by this PDA. Pretty impressive! Notice that this language is non-regular, which we can justify with a simple pumping lemma proof.
Up next for me is arguably the most important concept of the course: the Turing Machine.
CS Theory Part 2 of 8: Proving Languages are not Regular
After a little bit of a delay, I’m back to writing a little bit more about theory of computation. (Be warned that this post will assume more prior knowledge about automata than the previous entry.) So far, we’ve been learning a lot about languages, which are a set of strings formed from some alphabet (e.g. 0 and 1 for binary numbers) that obey certain guidelines. Languages can be classified as either regular or non-regular. Regular languages are those that can be recognized by some DFA, and I made some examples of that in the first Theory post. But not all languages are regular. And so far, I believe there’s three main ways to prove a language is not regular.
- Closure properties of regular languages (unions, intersections, concatenations, “star” operation, etc.)
- The Pumping Lemma
- The Myhill-Nerode Theorem and Fooling Sets
The usefulness of these three depends on the language. For some, the closure properties are the easiest to prove non-regularity; for others, it might be the Myhill-Nerode theorem. In fact, there are some languages that are not regular, yet are satisfied by the Pumping Lemma! That lemma is not a sufficient condition on non-regularity, so if a language satisfies it, all bets are off as to whether it’s regular or not. But if a language “passes” the requirements of Myhill-Nerode, it must be regular. Clearly, languages require multiple strategies to prove regularity or non-regularity.
I thought I’d present an example of a non-regular language and see how all three methods could be applied. First, before we begin, the canonical non-regular language (meaning, the one language that often introduces students into the world of linguistic non-regularity) is the following:
\[A = \{0^n1^n \mid n \ge 0\}\]It’s the language consisting of all strings with an equal amount of zeroes and ones, with the ones following the zeroes. Intuitively, it’s fairly simple to see that it’s non-regular. If a DFA were to recognize this language, it would have to compute the total amount of zeroes, followed by the ones. Consequently, since there would be an infinite amount of states needed, we can’t make a DFA since they are meant to be finite automata. That is, they have finitely many states. We will use this knowledge in hand, combined with the three common ways to prove non-regularity, when we consider this similar language:
\[B = \{0^m1^n \mid m \ne n\}\]It’s similar, but we just have to make sure that there are a different amount of zeroes and ones, and again, that the ones all come after the zeroes.
So let’s consider the different ways we could prove that this language is not regular.
Closure Properties
First, we look at closure properties of regular languages. A theorem of regular languages is that they are equivalent to the class of regular expressions. We know that \(0^*\) and \(1^*\) are both regular expressions. Furthermore, a theorem states that the class of expressions is closed under concatenation, so the following regular expression (i.e. regular language) \(0^*1^*\) is regular! Notice the key difference between this language and the previous two; the fact that we don’t have restrictions on the amount of 0s and 1s makes it possible to construct a DFA for this! Such a DFA would be fairly simple to construct — it would only require three states, one to start and represent the initial zeroes, one to represent the ones, and another to represent the death state, which is when, at any point, we see a 0 following a 1.
Why is knowing \(0^*1^*\) important? The class of regular languages is closed under intersection, so consider the language
\[\overline{B} \cap 0^*1^* = \{0^k1^k \mid k \ge 0\}\]Where \(\overline{B}\) represents the complement of \(B\). Yet another theorem is that regular languages are closed under complements. That is, if \(B\) is regular, then \(\overline{B}\) is regular. But notice that if we assume \(B\) is regular, then the intersection \(\overline{B} \cap 0^*1^*\) must be regular by intersection closure. But we know that the intersection is equal to the canonical non-regular language! Hence, \(B\) must be non-regular.
The Pumping Lemma
That wasn’t too bad, but things will get slightly more complex when we use the pumping lemma. We assume, by way of contradiction, that \(B\) is regular. Then by the pumping lemma, there exists some string length \(p\) such that any string in this language that is at least this long can be partitioned into components \(x, y, z\). Consider the string \(s = 0^p1^{p! + p} \in B\), which clearly satisfies the minimum length requirement, so it can be pumped. We set \(x = 0^a, y = 0^b, \mbox{ and } z = 0^{c}1^{p!+p}\), where \(b \ge 1 \mbox{ and } a+b+c = p\). Let us pump the \(y\) component \(i +1 = p!/b + 1\) times in \(s' = xy^{i+1}z\), which must be in the language by the pumping lemma. But pumping this string turns out to be \(s' = 0^{a+b+c+p!}1^{p!+p} = 0^{p!+p}1^{p!+p} \not \in B\), a contradiction. Any language that fails the pumping lemma is not regular, so \(B\) is non-regular.
The Myhill-Nerode Theorem
Knowing how to use the pumping lemma after reading the solution seems simple, but the hard part is actually coming up with the \(p! + p\) component. We wrap up by using the often easier Myhill-Nerode method to prove that this language is not regular. Let’s use the fooling set \(F = \{0^i \mid i \ge 0\}\). Then for any distinct \(x, y \in F\), we know that the have a different amount of zeroes in them. Let \(x = 0^j \mbox{ and } y = 0^k\) Then take \(z = 1^j\). We know that \(xz \not \in B\), but we also have \(yz \in B\) … so these strings are distinguishable from each other! And since our fooling set is infinite, and any pairs of distinct strings in it are distinguishable, any DFA would have to have an infinite amount of states, which is impossible. Hence, this language is not regular.
(Personally, I prefer the fooling set method to solving problems … it’s often very simple, and the same fooling sets can be used to prove non-regularity for multiple languages.)
Up next in my studies are context-free grammars. Stay tuned!
(On a side note, this is my 50th blog entry.)
CS Theory Part 1 of 8: Finite Automata
As I mentioned before, I am writing a series of blog posts on my Theory of Computation class. This particular post will be somewhat image-heavy due to complete lack of experience on how to use LaTeX in accordance with state machine diagrams. Even the LaTeX I embed in these posts doesn’t look too great with this background, so I’ll have to do some more experiments. UPDATE May 16, 2015: I think the Jekyll + MathJax combination looks great now!
But anyway, in this class, I’m trying to understand three central areas: automata, computability, and complexity, and they are all linked by the following question:
What are the fundamental capabilities and limitations of computers?
Computability and complexity will come later in the course. Right now we’re focusing on automata.
To start off, let’s look at some basic computers, called finite automata. To put things formally, a finite automaton is a 5-tuple \((Q, \sum, \delta, q_{1}, F)\), where1
- \(Q\) is a finite set of states
- \(\sigma\) is a finite set known as the alphabet
- \(\delta: Q \times \sigma \longrightarrow Q\) is the transition function
- \(q_{1} \in Q\) is the start state
- \(F \subset Q\) is the set of accept states
But this is very abstract. Let’s get more specific by talking about the alphabet, and I’ll then return to discuss the other four points. An alphabet is defined to be any nonempty, finite set of symbols. For instance, \(\sum = \{0,1\}\) is a valid alphabet. And so is the alphabet composed of the 26 letters of the English language.
Related to alphabets, we have strings and languages. A string is just a finite sequence of characters derived from our alphabet. All the English words I type in this blog entry are strings of the alphabet composed of the 26 letters of the English language. The sequence of symbols in 11001100 is a valid string of the alphabet \(\sum = \{0,1\}\). Any binary number is a string that can be formed by the alphabet. And a language is a set of these strings.
Here is the key relation between languages and finite automata.
A language is called a regular language if some finite automaton recognizes it.
By definition, a finite automaton will recognize a language if all strings the automaton accepts are members of the language. That’s the key. And to indicate what I mean, let’s look at a state diagram. Many finite automata can be written using these diagrams, and it’s highly advantageous to do so given how intuitive it is. The following is a state diagram of a finite automata that recognizes some language.
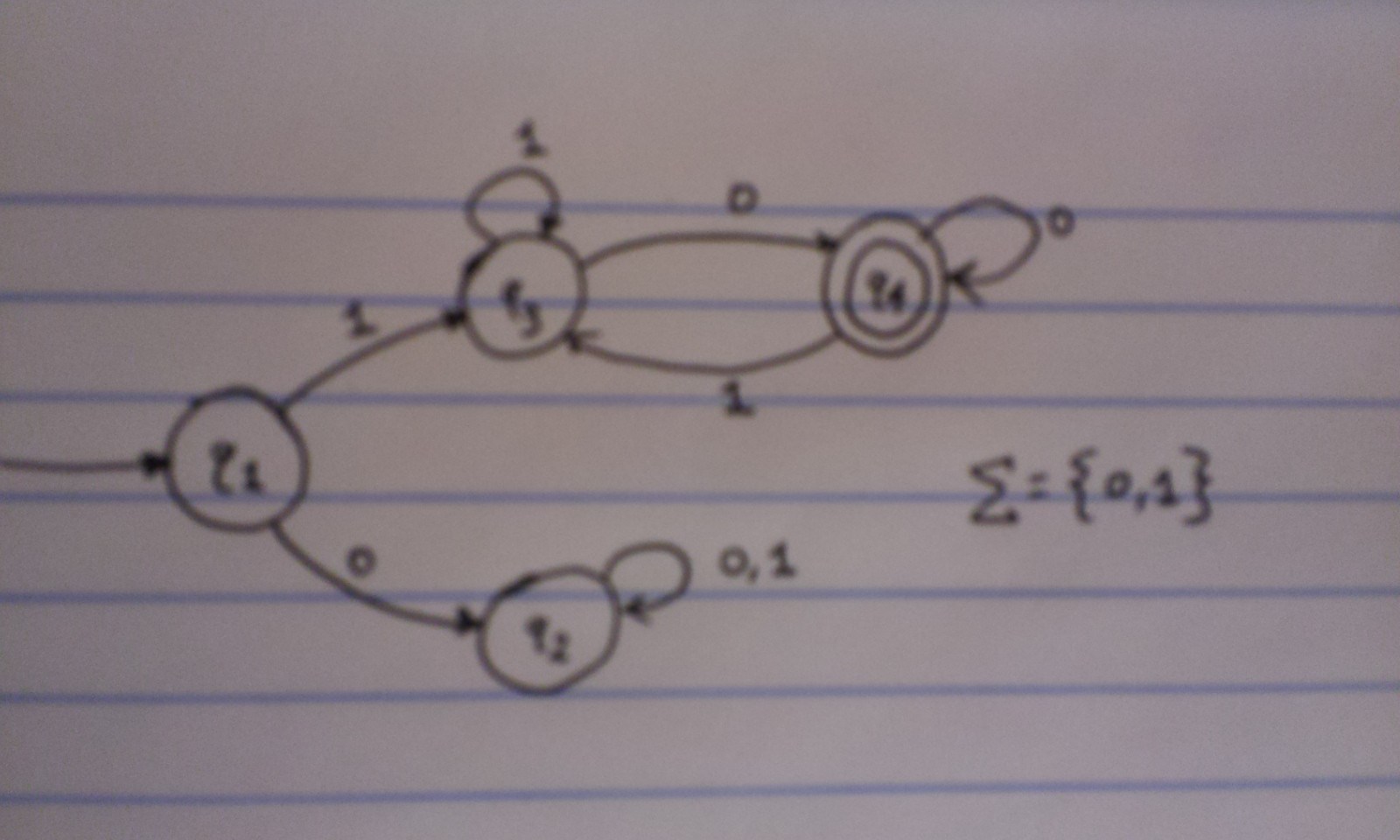
It’s a little blurry (future images will be better), but I hope you can still see the interesting symbols. First, there are four large circles, with one having a circle within it. Each of these four circles represents a state. Hence, \(\{q_{1}, q_{2}, q_{3}, q_{4}\} = Q\), the set of states (#1 on my list above). These are used to represent some situation that we encounter as we progress through a given string.
We have \(q_{1}\) forming our *start state *(#4 on my list above). This means when we progress through a given string, this is where we start before we make any “moves.” And \(q_{4}\) represents the lone accept state, indicated by the double circle outline. We can have multiple — or zero — accept states; this particular diagram only has one. If a string ends on one of these states, it’s “accepted” by the language. Otherwise, it’s rejected.
When I say “progress through a given string,” I refer to the process of determining whether a machine will recognize a certain string, and here is where we use the transition function (#3 on my list above), indicated by arrows in the diagram. Our alphabet in the above example is composed of just 0 and 1, so the machine only works with strings of that form. Let’s see what happens when we “input” a few strings into this machine.
- \(\varepsilon\) — This is the empty string. We start by going to \(q_{1}\) and we stop there, since we have no characters left. The finish state is the same as the start state, but this means the empty string is not accepted by the language since it did not finish in state \(q_{4}\).
- “1” — Here, we again start at the empty state. From this point forth, always assume we start at the start state. Since we have a “1” this means we go to state \(q_{3}\) as dictated by the transition function (i.e. arrows). We stop here, because we’re out of characters. But unfortunately, “1” did not end in the accept state so, like \(\varepsilon\), it is not accepted by the machine.
- “0” — We go from the start state to \(q_{2}\). Again, we stop, and just as in the previous two examples, the machine doesn’t accept the string.
- By now it should be clearer what should be accepted by the machine. Let’s go with “10” and see what happens. We start at \(q_{1}\) as usual. We proceed to \(q_{3}\) since we started with a 1. Our next character is a 0, so we go to \(q_{4}\) and stop there. At last! We have a string that is recognized by the language! So whatever the language is here, it better include “10” but exclude “1”, “0”, and the empty string.
- Let’s try “010”. We start by going to \(q_{2}\) due to the leading zero. Then we have “10” left, so we follow the arrow for the “1” which loops back to the same state. Then our final task is to go where the “0” arrow points to, but again, that goes back to the same \(q_{2}\) state! Thus, “010” is not accepted by this machine.
We can go on and on, but at some point, we have to come up with the rules for this language the machine accepts. Notice that state \(q_{2}\) is a “death” or “trap” state, because as soon as a string enters that state, it must end there. All strings are finite, and no matter what, any symbol we get (which is only a 0 or a 1 here) will lead us back to the same state. In other words, it is impossible for a string to be accepted (i.e. finish at \(q_{4}\)) if it ever enters \(q_{2}\). This means that if a string has a leading zero, it will never be accepted by the language/machine.
So now we know the language this machine recognizes must have all strings starting with a 1. But are there further restrictions? The answer is yes. If we have a string that consists of all 1s, then we will always end at \(q_{3}\) due to the 1 that loops back to that state. This is not an accept state, so we need to consider having a 0 in some string. Notice that the accept state has a 0 that loops back to it. So if a given string ever reaches \(q_{4}\), as long as it ends in a 0, it will remain in that state and be accepted. It doesn’t matter if we have one, five, or a hundred zeroes. The only way a string can leave an accept state is by having a 1, which means that string goes back to \(q_{3}\). But notice that this is not a death state! It is possible to come back to the accept state if a string is in \(q_{3}\).
Now we can formalize things. This state machine recognizes the following language \(L\):
\[L = \{x \mid x \mbox{ is a binary number that begins with a 1 and ends with a 0.} \}\]And we know that this language is regular. (To show a language is regular, it suffices to make a state diagram of a finite automaton.)
It’s also worth pointing out that the diagram I have above should represent the simplest possible state machine that accepts this language. There are infinitely many other diagrams that would also accept this language.
Now that was a simple example. I want to bring up a more complicated question that uses these same concepts.
Interesting Question
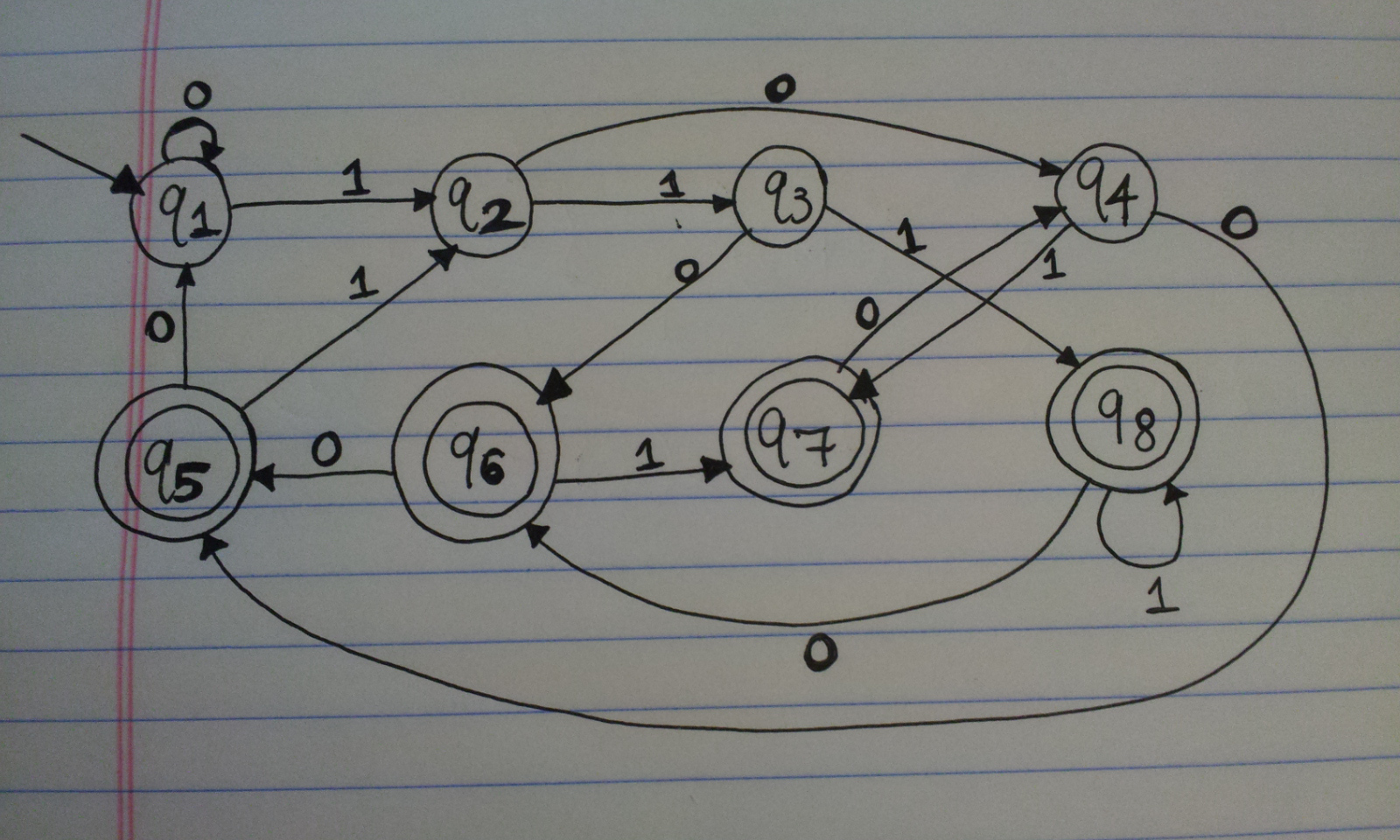
Let \(A\) be the language consisting of all strings over \(\{0,1\}\) containing a 1 in the third position from the end.
Designing a finite automata that accepts some language is arguably harder than the reverse process, determining what language is accepted by a given machine. I have my solution to the above question below. The diagram only needs to keep track of the last three digits. There are four accept states that correspond to the last three digits being 100, 101, 110, or 111, which are the four possibilities we could have for the last three symbols of accepted strings. Naturally, the four other non-accept states correspond to the last three symbols being 000, 001, 010, or 011.
Up to now, I assumed that my finite automaton were deterministic, so it was always possible to know what was happening. But soon I’ll be moving on to non-deterministic finite automaton …
-
From my textbook, Introduction to the Theory of Computation, Third Edition, by Michael Sipser. ↩
Why you Should Always Speak as if you’re in an Interview
A few days ago, I said that I was on the hunt for simple, yet effective deaf-friendly strategies that most people would be able to apply in life.
Here’s a basic one.
As much as you can, articulate as if you’re in an interview.
To be more specific, suppose you’re on the job market with a freshly minted Ph.D. In today’s situation, you may be competing with 300 other qualified candidates for one tenure-track faculty position at your dream school. If you manage to get an interview, you should feel proud, but it’s not a job guarantee. A competent interview means you remain in the applicant pool, and a terrible one … well, you get the idea.
So during that interview, what are the odds that you’ll mumble, slur or fail to fully project your voice as your interviewer stands across you? If you’re serious about getting the job, I think you’ll articulate very clearly.
But do most people extend this kind of voice in informal conversations?
I don’t believe that’s the case. Certainly for me, I pay much more attention to my speech when I’m giving a lecture or talking to a prominent person. But I need to work on extending that mentality to all conversations. I want to always make a good impression on my conversationalist by speaking as well as I can. If everyone else tried to do the same thing, we would all benefit.
That’s why getting into a habit like this is useful.
So please, as much as possible, do the following:
- Project your voice and articulate by moving your lips. This is similar to not mumbling.
- Focus on pronouncing the ends of your phrases to avoid sound tailing off.
- Don’t talk in a rushed manner; relax and know that, for the most part, everything will be okay.
- Don’t talk abnormally loud so that hearing people would wonder if there’s something wrong.
In my case, the first point I listed is the most helpful for me when I hear. But for those who may lack more “raw” hearing even with the help of assisted listening devices, the fourth may be more effective. But the first one, in my opinion, should take priority.