My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
Review of Statistical Learning Theory (CS 281A) at Berkeley
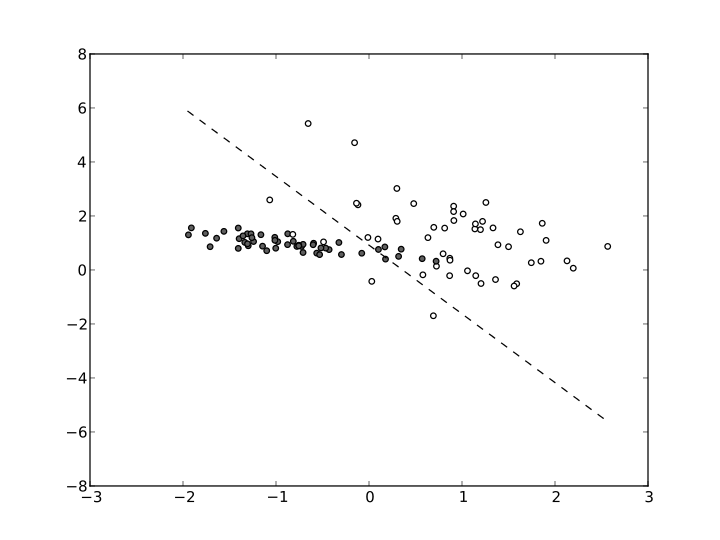
Now that I’ve finished my first semester at Berkeley, I think it’s time for me to review how I felt about the two classes I took: Statistical Learning Theory (CS 281A) and Natural Language Processing (CS 288). In this post, I’ll discuss CS 281a, a class that I’m extremely happy I took even if it was a bit stressful to be in lecture (more on that later).
First of all, what is statistical learning theory? I view the subject as one that principally deals with the problem of finding a predictive function of data that minimizes a loss function (e.g., squared loss) on training data, and analyzes this problem in a framework that conflates machine learning and probability methods. Whereas a standard machine learning course might primarily describe various learning algorithms, statistical learning theory focuses on the subset of these that are most well-suited to statistical analysis. For instance, regression is a common learning algorithm, and regularization is a common (statistical?) technique we use to improve our predictors.
At Berkeley, statistical learning theory is a popular course that attracts an unusually diverse audience of students (by graduate-course standards), not just machine learning theorists. It attracts students from all computer science and statistics research areas, as well as students from mathematics, psychology, and various engineering disciplines. For some reason, this year it was even more popular than usual — we had over 100 at the start (overflowing the largest room in the electrical engineering building). I would have thought that since the popular Professor Michael I. Jordan taught it last spring, that would have pulled away some of the students in this year’s cycle, but I guess not.
In past years, I think CS 281A focused almost exclusively on graphical models. My class seemed different: I had Professor Ben Recht, who was teaching it for the first time, and he changed the material so that we only discussed graphical models for about four lectures, giving us time to go over detection theory, hypothesis testing, and other fields. He told me personally that he dislikes graphical models (and also the EM-algorithm!) so I’m assuming that’s the reason why. We didn’t even get to talk about the junction tree algorithm.
We had five problem sets, which were each challenging but not impossible, and the workload got easier as the class went on. I probably spent an average of 15-20 hours on each problem set, including the “LaTeX-ing” process, but not including general mathematical review, of which I had to do a lot because of some shocking gaps in my linear algebra and probability intuition.
Digression: this semester gave me my first experience with Piazza, a private online forum where students can ask and answer questions related to the class material. (Students can be anonymous to other classmates if desired.) Even though it has some obvious shortcomings, I enjoyed it because it gave me a chance to discuss some of the homework problems “virtually.” Combined with a few in-person collaborations, CS 281a gave me a collaboration experience that I never had at Williams in my math courses. Having Piazza would have made some of those classes much easier!
Back to CS 281A: somewhat unexpectedly, we had a midterm! It was a 25.5-hour take-home midterm, open note, and open internet (!). At first, I was disappointed about having to take a midterm because I think I have proven my ability to understand concepts and describe them under timed exam constraints, but I ended up enjoying the test and benefited from it. I didn’t check, but I’m pretty sure none of these questions could be found online. 24-hour take home exams are the norm at Williams so I had tons of experience with this exam format. In lieu of a final exam, we had a final project, which I described in a previous post.
In terms of the lectures themselves, Professor Recht would alternate between discussing a concept at a high level and then writing some math on the blackboard. Unfortunately, the technical terms in this class made the captioning difficult, as I discussed earlier this semester. (Here’s a sample: Gaussians, Kullback-Liebler Divergence, Baum-Welch, Neyman-Pearson, and Lagrangians. Pretend you don’t know any math beyond calculus and try to spell these correctly.) And also, I didn’t mention this earlier, but for a large lecture course, we had a surprisingly high number of question-answer exchanges, which made it tougher on the captioner, I think, because of the need to listen to multiple people talking. The result was that the screen I looked at, which was supposed to contain the captions, had a lot of gibberish instead, and I bet the students sitting behind me were wondering what was going on. (I sat in the front row.)
I was still able to learn a lot of the material in part because I did a lot of reading — both from the assigned list and from random online sources — to really understand some of this material. I probably need to rely on out-of-class reading more than most (Berkeley computer science graduate) students, so I don’t mind that, and it’s something that graduate students are supposed to do: if you don’t understand something, then learn about it yourself (at first).
Overall verdict: I’m happy I took it. It’s a good introduction to what graduate courses are like, and I will probably take the sequel, CS 281B, the next time it’s offered.
The Advantages of Recitations in Large Lecture Courses

At Williams, the largest mathematics or computer science course I took had probably 55 students. The normal size was 20 to 35 students. This meant I had many opportunities to talk to the professors without too much competition among the students.
The upper limit of 55 students pales in comparison to one of my courses at Berkeley. Last semester, the Statistical Learning Theory course (CS 281a or STAT 241a) initially had over 100 students after the first few lectures. Eventually, the number of students dropped to roughly 80 by the time the course concluded, but that’s still a considerable amount, especially considering that this was a graduate-level course, so shouldn’t there only be a handful of people who are interested in the subject? Of course, even that enrollment pales in comparison to the enrollment in Berkeley’s introductory computer science courses. Here, computer science majors (technically “EECS” majors) are “supposed” to start with the CS 61A, 61B, and 61C series, which are basically “intro to CS,” data structures, and computer organization/architecture. I was told that the enrollment in those three courses last semester after add/drop were (brace yourselves) 1243, 752, and 411 students, respectively! I’m not sure if there’s a single room on the Williams campus that can hold 411 people!
It’s no surprise, therefore, that at CS-intensive universities like Berkeley, MIT, and Washington, large lecture courses like 61{A,B,C} split up students into smaller recitation sessions. These can be thought of an extra lecture session, but led by a graduate student or an advanced undergraduate. The reduced number of students in these sessions makes it easier to ask questions and to go over confusing concepts.
One understandable reaction to this kind of situation is … why would anyone prefer Berkeley-style lectures compared to Williams-style lectures, where no recitations with (presumably less-talented) instructors are needed? Certainly this would have been my thought as a high school student, because it seems like I would much rather prefer the advantage of having a more personal relationship with the brilliant professors and being able to ask real questions during lectures. But on the flip side, there are several advantages to the recitation style.
- The recitation instructors are also incredibly brilliant! By making the most out of recitations, students can obtain valuable advice, insights, and strategies, from the recitation instructor that might be tailored more towards the student’s needs. HUGE disclaimer: I go to Berkeley, where people in CS are expected to be geniuses or crazy hard-workers. I’m aware that many universities have bad TAs.
- Sometimes, when it directly concerns specific class assignments, the recitation instructors can be better than the professors at answering questions! This is not the same thing, of course, as saying that the recitation instructors know more about the subject than the professor (or the class lecturer). Professors have clear views on how their field is moving and a broad knowledge base, but a graduate student might have had more time to look specifically at the code for one of the projects and can answer very specific questions, such as whether a line of code is functioning correctly. I often find that when I get past the initial hurdle of understanding an assignment at a high-level, it’s the tiny details that remain before I can confidently turn in my work.
- I also believe that due to the reduction of question-answering in large lectures, and because of an “extra” lecture/class session due to recitation, computer science courses in a school like Berkeley are able to cover more material than the corresponding Williams courses. At Williams, I remember some lectures that ended up in a back-and-forth question-answering session among the students and the professor. While this does mean we get to answer students’ questions, it also means we don’t make that much ground on material as compared to a standard lecture style course. For instance, after reviewing lectures and syllabi, I think that Berkeley’s data structures course (CS 61B) covers more material than Williams’ data structures course (CS 136), even when ignoring the last two weeks of Berkeley’s class. (Berkeley semesters are two weeks longer than Williams semesters due to the lack of a Winter Study.)
I wish I had better understood the tradeoffs between lectures in large universities and small liberal arts colleges back in high school when I was considering which college to attend. Then again, since I got rejected from almost everywhere I applied despite high GPA and SAT scores, perhaps it wouldn’t have mattered in the end, but I might have considered expanding the pool of my college applications to include more universities.
Detection Theory Adventures (a.k.a. a Final Project)
Whew! I just spent the past week in a mad dash to finish up my Statistical Learning Theory final project (CS 281a at Berkeley). My write-up is online, in case you want to check it out. The overall goal of my project was to explore the area of detection theory, an important mathematical field that does have practical implications. I know every field likes to say that (and in a sense, maybe it’s true for all fields anyway) but seriously — detection theory is about trying to distinguish the signal from the noise. Suppose we see a bunch of data points that are generated from some underlying process. This goes on for a while, but then at some point, the chart we see spikes up. That could indicate that something’s wrong. There are tons of examples that match this kind of situation. The example I used in my report was monitoring a patient’s body temperature. If I’m taking my temperature every 12 hours, for instance, and I see the following numbers: 98.6, 98.6, … (a long time) …, 98.6, 99.1, 99.5, 99.7, 100.2, 100.0, 101.1, by the time I’m getting even past 99.5 I should be a little suspicious and think that the underlying process for my body temperature indicates that I have a fever.
I learned a lot from my final project, since I read about 15 academic papers (which are not easy to read) and skimmed over many others. Despite this, I am not that happy with how it ended up, because my experiments were not extensive or groundbreaking. On the other hand, perhaps this kind of work is what I should expect if I’ve got only four weeks for a class project. It wouldn’t be the first time that I’ve been excessively harsh on myself.
By the way, my report is written in the style and formatting of the Neural Information Processing Systems (NIPS) conference. NIPS is one of the top two academic machine learning research conferences, with the other one being the Internal Conference on Machine Learning (ICML). Their papers have a nine-page limit, with the ninth one reserved for references only, but I’ve noticed that in practice a lot of researchers end up putting a ton of proofs and other information in appendices or supplementary material after the first nine pages. I have seen supplementary material sections that were 30 pages long! This is allowed, because NIPS guidelines say that extra material after nine pages is fine with the understanding that reviewers are not obligated to read them. I found the eight page limit to be easy to reach with this simple project, which is funny because I’ve long viewed eight page papers/reports to be long for a high school or college class. Furthermore, many of my previous class papers had to be double-spaced in 12-point font, whereas in NIPS they cram everything down with single-spaced, 10-point font. I had to fiddle around with a lot of the text to get everything to squish into eight pages, and as my last step, I used the LaTeX command vskip -10pt to condense the “Acknowledgments” subsection heading with its text. I guess that’s what academic writing is like?
Brain Dump: Successfully Installing and Running the Moses Statistical Machine Translation System
I’m using Moses again. It’s an open-source statistical machine translation system. I first used it when I was at Bard in 2012, and I remember being clueless about the installation process and being overwhelmed by all the Linux/Unix commands I had to know. I think it took me more than a week before I had installed Moses and successfully completed the suggested baseline test. At that time, I was doing nothing but that … so I was pretty frustrated. Even at the end of my REU, the commands to run Moses felt like black magic.
But I’m back at it again. Armed with several more years of hacking and Linux/Unix experience, as well as a statistical natural language processing class for background material, I managed to install Moses and complete the baseline test on my laptop, which is a Macbook that I got last January. It still took me almost a week (Friday night, 9-5 Saturday, 9-5 Sunday, all day Monday and Tuesday…) to do that since I ran into some unexpected problems. To prevent me from getting this kind of headache again, I’ll be listing the steps I conducted to install and run the baseline, which hopefully will be applicable for anyone trying to use Moses right now. If you find this article useful, please let me know. (Keep in mind, however, that it will probably be obsolete in a few months.) You will need some Linux/Unix experience to follow this article.
At a high level, I had problems with installing boost, installing mgiza, and training the baseline system.
To start, I git cloned the moses code. The installation instructions say that I need g++ and
boost installed. Actually, I don’t think g++ is necessary because in Mavericks (i.e., OS X
10.9), Apple changed the default compiler for C++ to be clang, so we really need that on our
computers to run Moses, but clang should be built-in or be part of Xcode so it should definitely be
there as long as I have Xcode. Speaking of boost, I did have boost 1.56 installed; I got it via the
command brew install boost, which will install boost 1.56 in /usr/local/Cellar/boost/,
because that’s the default place where homebrew installs things. For example, I also have
the widely-used numpy package located in /usr/local/Cellar/numpy.
So, thinking that I had things taken care of, I went into my mosesdecoder directory, and followed
the instructions by running ./bjam -j8. Unfortunately, I ran into the dreaded “clang:
error: linker command failed with exit code 1.”
$ ./bjam -j8
Tip: install tcmalloc for faster threading. See BUILD-INSTRUCTIONS.txt for more information.
mkdir: bin: File exists
...patience...
...patience...
...found 4469 targets...
...updating 155 targets...
darwin.link lm/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/query
ld: library not found for -lboost_thread
clang: error: linker command failed with exit code 1 (use -v to see invocation)
// Additional error messages...
...failed darwin.link mert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/util_test...
...skipped <pmert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi>util_test.passed for
lack of <pmert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi>util_test...
darwin.link mert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/vocabulary_test
ld: library not found for -lboost_thread
clang: error: linker command failed with exit code 1 (use -v to see invocation)
"g++" -o "mert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/vocabulary_test"
"mert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/VocabularyTest.o"
"mert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/libmert_lib.a"
-lboost_unit_test_framework -llzma -lbz2 -ldl -lboost_system -lz -lboost_thread -lm -liconv -g
-Wl,-dead_strip -no_dead_strip_inits_and_terms
...failed darwin.link
mert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/vocabulary_test...
...skipped <pmert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi>vocabulary_test.passed
for lack of <pmert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi>vocabulary_test...
...failed updating 72 targets…
...skipped 83 targets…
The build failed. If you need support, run:
./jam-files/bjam -j8 –debug-configuration -d2 |gzip >build.log.gz
then attach build.log.gz to your e-mail.
You MUST do 3 things before sending to the mailing list:
1. Subscribe to the mailing list at http://mailman.mit.edu/mailman/listinfo/moses-support
2. Attach build.log.gz to your e-mail
3. Say what is the EXACT command you executed when you got the error
Huh. I can’t even do a simple installation?!? Note: in the above terminal output, I included my
original command (after the dollar sign $), and the error message was much longer than what’s
displayed; I got rid of some if it with // Additional error messages for the sake of clarity.
What’s the problem? Apparently, moses couldn’t find the lboost_thread library.
After some extensive research on Google and asking on the Moses mailing list, I think the issue
comes down to the layout being layout=tagged versus layout=system. To give an example,
the library file that I think lboost_thread refers to is libboost_thread-mt.a, which is
a tagged version due to having mt; the untagged file version would be
libboost_thread.a. I think this was the problem I was getting, but I couldn’t figure
it out despite making moses look at the directory where boost was installed. On the instructions,
they say to do ./bjam -with-boost=~/workspace/temp/boost_1_55_0 -j8 where the
workspace/temp folder is just where they’ve put boost in. On my system, it’s
obviously in a different location, so I ran ./bjam -with-boost=/usr/local/Cellar/boost -j8.
Unfortunately, that also didn’t work. Note: the tilda option indicates the path to the home
directory, so on my computer, ~/workspace would be equivalent to
/Users/danielseita/workspace. The /Users/danielseita equals the $HOME path variable.
I asked on the mailing list, and their advice was to do some clean installations because it’s
obvious something was broken here, especially with boost. All right, then, the first step to do that
is to uninstall boost: brew uninstall boost -force.
I went through several more trials of installing boost via homebrew before I decided to avoid using
it at all; I went to the boost website directly, downloaded the .tar.gz file for version 1.57 (the
latest version at the time of this writing), and untarred it: tar -zxvf boost_1_57_0.tar.gz.
That pastes the boost files in the current directory, but now we have to compile it for Moses. At the time of this writing, the Moses installation instructions say to execute the following two commands in the boost directory:
./bootstrap.sh;
./b2 -j8 -prefix=$PWD -libdir=$PWD/lib64 -layout=system link=static install || echo FAILURE
Unfortunately, running those commands never helped, and I consistently got the same amount of
errors/warnings each time. After a series of uninstallations/installations, I decided to just try
following the instructions directly from the boost website, specifically from their “Getting
Started” section. I attempted the following set of commands from a clean download folder
boost_1_57_0:
cp -r boost_1_57_0/ /usr/local
cd /usr/local/boost_1_57_0
./bootstrap.sh
./b2 install
And in addition to that … I went into Apple’s Finder window, double-clicked on the Xcode application (just to check if I had clang installed) … and upon doing so, I received a pop-up message saying that there was some external software I needed to install! I wish I had gotten a screenshot of that, but it showed up as soon as I double clicked on the application, and in a few seconds it had installed what it needed. It looked like I did have clang installed, but I have no idea about how much that initial pop-up must have helped me.
I then tried to compile moses again with a simple ./bjam -j8 command. Aaaaaand … it worked!
See some of the output (again, the dollar sign indicates lines that I typed):
$ cd ~/mosesdecoder/
$ ./bjam -j8
Tip: install tcmalloc for faster threading. See BUILD-INSTRUCTIONS.txt for more information.
mkdir: bin: File exists
...patience...
...patience...
...found 4470 targets...
...updating 63 targets...
common.copy /Users/danielseita/mosesdecoder/bin/lmplz
darwin.link util/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/bit_packing_test
darwin.link util/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/multi_intersection_test
darwin.link util/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/joint_sort_test
darwin.link util/bin/file_piece_test.test/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/file_piece_test
darwin.link lm/bin/partial_test.test/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/partial_test
darwin.link lm/bin/left_test.test/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/left_test
darwin.link lm/bin/model_test.test/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/model_test
testing.unit-test util/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/joint_sort_test.passed
Running 4 test cases...
*** No errors detected
testing.unit-test util/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/multi_intersection_test.passed
Running 4 test cases...
// Additional cases not shown
*** No errors detected
testing.unit-test mert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/util_test.passed
Running 3 test cases...
*** No errors detected
testing.unit-test mert/bin/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/vocabulary_test.passed
Running 2 test cases...
*** No errors detected
testing.capture-output moses/LM/bin/BackwardTest.test/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/BackwardTest.run
**passed** moses/LM/bin/BackwardTest.test/darwin-4.2.1/release/debug-symbols-on/link-static/threading-multi/BackwardTest.test
...updated 63 targets...
SUCCESS
What’s the lesson here? I guess the point is that deleting stuff and just starting an installation process all over again while trying out new ways of doing things is one of the most effective techniques to tackling complicated software problems. Yeah, it’s kind of lame, but I guess trial-and-error is the nature of Linux/Unix.
All right, now let’s discuss the second main problem I had with installing Moses, this time related to mgiza. I initially ran into the problems that I will describe below, but the fix above (uninstalling boost, taking it from the website, and compiling it according to the boost website’s instructions) seemed to resolve them. But I will describe the problem I had with mgiza just for completeness.
On the Moses website, they now recommend avoiding GIZA++ (which is a popular word-alignment software) and instead using mgiza, which is a multi-threaded version of GIZA++. As with moses, I git cloned it into a directory. The installation instructions are really simple, since mgiza comes with makefiles (the cmake command will generate a Makefile). There are three commands to execute:
cmake .
make
make install
Notice that cmake has a period after it, which indicates that we’re assuming the installation happens in the current directory.
Of course, despite the simplicity of these instructions, I still got errors. The cmake step seemed to work fine, but not make:
1 warning generated.
Linking CXX executable ../bin/d4norm
Undefined symbols for architecture x86_64:
"std::string::_Rep::_M_destroy(std::allocator<char> const&)", referenced from:
boost::system::(anonymous namespace)::generic_error_category::message(int) const in libboost_system-mt.a(error_code.o)
"std::string::_Rep::_S_empty_rep_storage", referenced from:
boost::system::(anonymous namespace)::generic_error_category::message(int) const in libboost_system-mt.a(error_code.o)
"std::string::assign(char const*, unsigned long)", referenced from:
boost::system::(anonymous namespace)::generic_error_category::message(int) const in libboost_system-mt.a(error_code.o)
"std::basic_string<char, std::char_traits<char>, std::allocator<char> >::basic_string(char const*, std::allocator<char> const&)", referenced from:
boost::system::(anonymous namespace)::generic_error_category::message(int) const in libboost_system-mt.a(error_code.o)
"std::basic_string<char, std::char_traits<char>, std::allocator<char> >::basic_string(std::string const&)", referenced from:
boost::system::(anonymous namespace)::generic_error_category::message(int) const in libboost_system-mt.a(error_code.o)
"std::basic_string<char, std::char_traits<char>, std::allocator<char> >::~basic_string()", referenced from:
boost::system::(anonymous namespace)::generic_error_category::message(int) const in libboost_system-mt.a(error_code.o)
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
Yikes … another problem with boost! And this time, the “ld: symbols(s) not found for architecture x86_64” error occurred. Again, as I mentioned earlier, the solution lies not with mgiza itself but with boost (where it’s installed, etc.), so consider a clean installation and compilation of boost from the official website (not homebrew). When I did that, I deleted the mgiza directory, cloned it again from git, and the three subsequent commands worked. I got a ton of warning messages, but no errors, which is the important part.
Whew! With moses and mgiza successfully compiled, I could finally start the baseline! Most of the time, copying and pasting the instructions from the Moses website and modifying them according to your directory structure should work, but there are some important things to be aware of:
(1) Installing irstlm is a little different because now it’s version 5.80.06 rather than the
5.80.03 that’s currently listed on the website. (In fact, irstlm 5.80.03 does not even compile
on my laptop.) With this new version, irstlm moved the directory structure so now the installation
won’t work if you copy the baseline. There’s a README in the trunk directory inside
irstlm so I followed that and didn’t seem to have many issues. Make sure you modify the rest
of the baseline’s commands accordingly, since the documentation assumes that we use
~/irstlm/bin as the place where the binaries are located.
(2) One thing I had trouble with was the “–text yes” option for the compile-lm. That created a “DEBUG: warning: too many parameters” output, as described here. The key is to use “–text=yes” so put in the equals sign. I can’t believe that fix took so long for me to figure out! I described this on the mailing list and the people maintaining the Moses website have (as of this writing) changed the instructions to conform to “–text=yes”.
(3) With training, the current instructions assume we’re using GIZA++, but since it’s mgiza, we’ve got to change that. Oh, that reminds me — I also tried out these training steps with normal GIZA++, but I could never get it work because after training went on for a few hours, something wrong happened with the lexical reordering score, because extract.o.sorted.gz never got generated. Here’s the error I got in the log file training.out:
libc++abi.dylib: terminating with uncaught exception of type
util::ErrnoException: util/file.cc:68 in int util::OpenReadOrThrow(const char *)
threw ErrnoException because '-1 == (ret = open(name, 0x0000))'.
No such file or directory while opening
/Users/danielseita/working/train/model/extract.o.sorted.gz
ERROR: Execution of:
/Users/danielseita/mosesdecoder/scripts/../bin/lexical-reordering-score
/Users/danielseita/working/train/model/extract.o.sorted.gz 0.5
/Users/danielseita/working/train/model/reordering-table.
-model "wbe msd wbe-msd-bidirectional-fe"
died with signal 6, without coredump
The error above prevented a moses.ini file from even forming. To work around this issue, it’s
possible to run the training while removing the -reordering argument, but when I did that, tuning
fails. If you know of a fix, please let me know!
Now back to training with mgiza. The instructions are listed on the external software page. We
need to specify the -mgiza flag, and we also need to make sure that -external-bin-dir is set
correctly. This should be a directory where the mgiza binary files are located, as well as the
merge_align.py script (all of these must be in one directory together!). In the current version of
mgiza, they seem to be in /mgiza/mgizapp/bin. I decided to move everything over to a directory
called word_align_tools; inside the mosesdecoder directory. I also specified the number of CPUs
for mgiza to be four. The following code shows the list of commands I used to prepare my file
system for training:
cd ~/mosesdecoder/
mkdir word_align_tools
cp ~/mgiza/mgizapp/bin/* word_align_tools/
cp ~/mgiza/mgizapp/scripts/merge_alignment.py word_align_tools/
And this does the actual training:
/Users/danielseita/mosesdecoder/scripts/training/train-model.perl
-root-dir /Users/danielseita/working/train
-corpus /Users/danielseita/corpus/news-commentary-v8.fr-en.clean
-f fr -e en -alignment grow-diag-final-and -reordering msd-bidirectional-fe
-lm 0:3:/Users/danielseita/lm/news-commentary-v8.fr-en.blm.en
-mgiza -mgiza-cpus 4
-external-bin-dir /Users/danielseita/mosesdecoder/mgiza_tools/ >&training.out
I put in some backward slashes there just so the code wouldn’t require so much scrolling to
understand, but I didn’t include them when I ran it in Terminal. Also notice that I’m
using absolute paths, rather than relative paths. This means we want a full path like
/Users/danielseita/mosesdecoder instead of ~/mosesdecoder. I saw some errors online that were
resolved with using full paths, so I decided to use full paths for everything, though it’s
probably worth it only for the -root-dir argument above. Finally, I’m not adding in a
“:8″ to the language model argument, because I don’t know what that does (to do:
find out!).
Update 11/29/14: Apparently, that extra :8 argument forces the use of KenLM instead of SRILM … so yes, include an extra :8 after the language model file name. The above command, while still correct I believe, should not be used.
That command above took five or six hours to complete on my laptop, which is surprising because the baseline currently claims it should be 1.5 hours, and I’ve got a pretty powerful laptop. Perhaps the data I downloaded got updated and is larger than the baseline claims? Or maybe it’s an mgiza issue?
Once training is done, here’s a very important piece of advice: change the resulting moses.ini file to say KENLM instead of SRILM. This means my moses.ini file had a line that looked like this:
KENLM name=LM0 factor=0 path=/Users/danielseita/lm/newscommentary-v8.fr-en.blm.en order=3
I’m not sure why this isn’t emphasized that much on the baseline webpage, because it’s pretty darn important! The tuning will fail if we don’t get the language model set correctly.
(4) I ran into many problems with tuning, but most of them were “carried over” from the training step, such as if I made an error in the command for training. Once I finally got mgiza working, tuning was fine, and the following command (for tuning) ran in the normal time range, which is about four hours.
/Users/danielseita/mosesdecoder/scripts/training/mert-moses.pl
/Users/danielseita/corpus/news-test2008.true.fr
/Users/danielseita/corpus/news-test2008.true.en
/Users/danielseita/mosesdecoder/bin/moses
/Users/danielseita/working/train/model/moses.ini -decoder-flags="-threads 4"
-mertdir /Users/danielseita/mosesdecoder/bin/ >& mert.out
(5) Testing should proceed as normal. My BLEU score is 23.58, which is what they expect (they say they got 23.5).
$ ~/mosesdecoder/scripts/generic/multi-bleu.perl -lc
~/corpus/newstest2011.true.en < newstest2011.translated.en
BLEU = 23.58, 60.3/29.9/16.9/10.1 (BP=1.000, ratio=1.017, hyp_len=76035, ref_len=74753)
Looking back at this, while Moses is no doubt a great software system, it does take a lot of effort to get it working correctly. Sometime in the next few weeks, I’ll try to post a real, organized guide here. UPDATE May 16, 2015: I doubt I’ll ever get a real guide up here, since Moses isn’t really an integral part of my research now. Sorry about that!
Steve Ballmer’s (Subtle) Jab at UC Berkeley
Well, the news is out. Former Microsoft CEO and current Los Angeles Clippers owner Steve Ballmer just donated enough money to the Harvard computer science department to fund twelve professorships. Twelve! To put that in perspective, that’s 50% more than the total number of computer science professors at Williams College, and about half of the current size of Harvard’s CS faculty.
While it’s no doubt thrilling to see the attention that computer science is getting nowadays, I couldn’t help but notice this little segment from The Crimson:
“Right now I think everybody would agree that MIT, Stanford, and Carnegie Mellon are the top places [for computer science],” Ballmer said, adding that some would also include the University of California at Berkeley. “I want Harvard on that list.”
Wait a second, did Ballmer just exclude Berkeley from the Stanford, CMU, and MIT group? Last I checked, they were all clustered together at rank one … perhaps the exclusion is related to how Berkeley’s a public university? I can’t really think of any other reason. And while he did mention the school, don’t you think that if he viewed the top schools as a group of four, he would have said “I think everyone would agree that MIT, Stanford, Carnegie Mellon, and Berkeley are the top places […]” instead?
Anyway, I hope Berkeley can maintain its reputation for the next few years. This is mainly so that people will be willing to take me seriously at a first glance/conversation when discussing research; beyond that, of course, they’ll care more about your actual record than the school you go to. But it helps to go to a highly-ranked school. And I’m sure that some of Harvard’s new faculty members will have gotten their Ph.D.s from Berkeley. Incidentally, the fourth and fifth year students at Berkeley who have strong publication records must be feeling ecstatic.
The Berkeley Vision and Learning Center’s Fall 2014 Retreat

On November 5, I attended part of the Fall 2014 Retreat for the Berkeley Vision and Learning Center (BVLC). The BVLC is a new group of faculty, students, and industry partners in EECS that focuses on research in vision (from computer vision to visualization) and machine learning. The retreat was held in the Faculty Club, a nice, country-style building enclosed by trees near the center of the UC Berkeley campus. While there were events going on all morning (and the day before, actually), I only attended the poster session from 5:00pm to 7:00pm and the dinner after that.
The poster session wasn’t as enormous as I thought it would be, but there were still quite a few people crowded in such a small area. I think there were around 15 to 20 posters from various research groups. I brought one about the BID Data project, whose principal investigator is John Canny. I’m hoping to become a part of that project within the next few weeks.
As far as the people who actually attended, there were a good number of faculty, postdocs, senior graduate students, and even industry people (from Microsoft, NVIDIA, Sony, etc.). For faculty, I saw Pieter Abbeel, Trevor Darrell, Alexei (Alyosha) Efros, Michael I. Jordan, and Jitendra Malik at various times throughout the evening. (Trevor is the head of the group so he was guaranteed to be there.) I had two interpreters for the poster session, which was probably overkill, but they were able to help me describe what a few people were saying when I went to see two specific posters that were interesting to me.
I didn’t have anyone there for dinner, though, which meant it was a struggle for me to communicate. Also, during dinner, we listened to guest speaker Andy Walshe of Red Bull Stratos. His talk was titled Leveraging Crossmodal Data from High Performance Athletes at Red Bull. Andy mostly talked about the limits of human performance, and as far as I can tell, his talk was not an advertisement for the actual drink known as Red Bull, which as everyone knows is dangerous to consume. Even so, I was often wondering why this kind of talk was being given, because I would have expected a “traditional” machine learning talk — but maybe I missed something at the start when Trevor Darrell was introducing Andy. (This is one of the things one should realize about me; dinners and talks are some of the most difficult situations for me to be in, while they may be quite easy to get involved in for other people.)
I could tell that the talk was not overly technical, which meant that there was a lot of discussion and questions once the talk was over. In particular, Michael Jordan and Alexei Efros asked consecutive questions that made everyone in the room (except me) roar with laughter. I’ll have to find someone who can explain what they said….
(Note: the image at the top — taken from the Faculty Club website — shows the location where we had dinner and where Andy gave his 30-minute multimedia presentation.)
Richard Ladner’s Path from Theoretical Computer Science to Accessibility Technology
Richard Ladner showed me a link to the September 2014 SIGACCESS newsletter, which contains a personal essay on why he made a career transition from being a computer science theorist to an accessibility researcher. (Frequent readers of my blog will know that I met Richard Ladner as part of the Summer Academy.) As usual, I’m a bit late with posting news here on this blog — this one is a few months old — but here it is and hopefully you enjoy his essay. Some highlights:
- Richard: “Although I am not disabled, disability is in my fabric as one of four children of deaf parents. Both my parents were highly educated and were teachers at the California School for the Deaf, then in Berkeley, California. They both used American Sign Language (ASL) and speech for communication, although not simultaneously.”
- Richard: “When I started at the University of Washington in 1971 I had no intention of doing anything in the area of technology for people with disabilities. I worked exclusively in theoretical science where I had some modest success. Nonetheless, some where in the back of my mind the transformative nature of the TTY helped me realize the power of technology to improve people’s lives.”
- Richard: “A light bulb went off in my head when I realized that innovation in technology benefits greatly when people with disabilities are involved in the research, not just as testers, but as an integral part of the design and development team.”
- Richard: “In 2002, with the arrival of Sangyun Hahn, a new graduate student from Korea who happens to be blind, I began my transition from theoretical computer scientist to accessibility researcher. By 2008 the transition was complete.”
- Richard: “One activity that I am particularly proud of is the Summer Academy for Advancing Deaf and Hard of Hearing in Computing that I developed with the help of Robert Roth who is deaf. […] Eighty-three students completed the program over its 7-year run from 2007-13. About half of these students became computer science or information technology majors.”
- Richard: “For students who want to become accessibility researchers I also have one piece of advice. Get involved at a personal level with people with disabilities. With this direct knowledge you are more likely to create a solution to an accessibility problem that will be adopted, not one that will sit on the shelf in some journal or conference proceedings.”
On a related note, Richard isn’t the only scientist who has made a late-stage research transition. I personally know several scientists/professors (though none as well as Richard) who have substantially changed their research agenda. One interesting trend is that people who do make transitions tend to move towards more applied research. It’s almost never the other way around, and I suspect that it’s due to a combination of two factors. First, theory-oriented research requires a lot of mathematical background to make progress, which can be a deterring factor. And second, I think many theorists wish their work could have more of a real world impact.
Any Social Advice for Mingling Sessions?

Lately, I’ve been disappointed at my lack of ability to effectively socialize in various mingling sessions. Examples of these include the Berkeley graduate student social events, the Williams College math and computer science “snack/social” gatherings, research-style poster sessions (see this Williams math post for some sample images), and basically any kind of party. Typically, if I attend these events, I end up saying hi to a few people, stand around awkwardly by myself for a while, and then leave long before the event concludes, feeling somewhat dejected. This has been an issue throughout my entire life.
I don’t normally have anyone with me (such as an ASL interpreter) to help me out with communication, so I know that I’m already disadvantaged to start with, but I would like to think that I can manage social events better. I’ve tried various tactics, such as coming early to events, or going with someone else. Even when I arrive early, though, when the event starts to gather some steam and more people arrive, they tend to immediately conglomerate into groups of two or more, and I am often left out of any conversation. Furthermore, there’s no easy way for me to convince a group of five laughing students to include me in their conversation, and to also ask them to move to a corner of the room to decrease background noise.
Also, in my past experience, when I’ve attended an event with at least one other person, I can briefly remain in a conversation with the group I went with, but we end up splitting at some point. This usually means they’ve found someone else to talk with, but I haven’t.
The worst case scenario, of course, is if I arrive alone and late to a loud social event. By that time, everyone’s found a group to stick with and I don’t know what else to do but watch a bunch of people chat about some mysterious topics … or leave.
So what should I do then? I’m not someone who can just walk in a room and command the attention of everyone else here, and as evident from past experience, I’m going to need to work to get involved in a non-trivial conversation.
Unfortunately, I can’t (and shouldn’t) avoid social events all together, and the reason has to do with academic conferences. Especially in a field like computer science, where top-tier conference publications are what “count” for a Ph.D. student’s job application, it’s crucial for Ph.D. students to attend conferences and network with other people in the field. Even though I’ve already started graduate school, I have still (!) not attended a single academic conference, though I hope to do so in the future, and I worry about how I will handle the various social events they offer. I wrote a little bit on the topic of academic conferences before, but I’m more concerned with the social aspect here, not about the process of obtaining accommodations, which hopefully won’t be too bad with the resources that Berkeley has at its disposal.
I don’t have any answers to this right now, so I would appreciate any advice if you have them. In the meantime, I’ll continue brainstorming different strategies to improve my social situation in events that involve mingling, because I’m attending a poster session in three days.
The Value of Standing Up
My office is in the fifth floor of Soda Hall, and is part of a larger laboratory that consists of several open cubicles in the center, surrounded by shared offices (for graduate students and postdocs) and personal offices (for professors). Thus, I can peek into other offices to see what people are doing. And the graduate students I observe are almost always ensconced in their chairs.
I know that even Berkeley students take breaks now and then, but I still think that many us end up sitting down for five to six hours daily. (That’s assuming graduate students work for only eight hours a day … definitely an underestimate!)
I don’t like sitting down all day. In fact, I think that’s dangerous, and lately, I’ve joined the crowd of people who alternate between sitting and standing while at work. My original plan when I arrived in Berkeley was to ask my temporary advisor to buy a computer station that has the capability to move up and down as needed. Fortunately, I haven’t had to do that, because I somehow lucked into an “office” that looks like this:

Heck, I don’t even know what those metal-like objects are to the left. Fortunately, they’re set at the perfect height for a person like me, and they’re really heavy, so it’s provides a firm foundation for me to put my laptop there and stand while working. My current work flow is to default by standing up, and then sit down only when my feet start getting sore. Then I stand up once I start feeling stiff. Seriously, it doesn’t get any easier than that. You don’t need a fancy treadmill desk, though it’s an option — one faculty member at Cornell has this in her office. All you need is a nice stack of sturdy objects to put on top of something. And especially if you only plan to use your laptop, I can’t believe anyone (e.g., a boss) would complain if you built a simple station yourself. For more tips, you can also check out this excellent Mark’s Daily Apple article about standing at work.
There are other ways of avoiding the curse of a sitting-only job. For instance, some people might benefit from long walks during work, a thought that came to me due to a New York Times article that appears to have turned some heads. Personally, I find walking overrated. Every time I go for a walk, I can’t focus on my work — my mind always switches to whatever random thought happens to be flowing around. So I prefer to just sit and stand as needed during a pure work day, and I hope that other students (and faculty!) consider doing that.
Rain, Berkeley Weather, and Hearing Aids
I’m sure that most long-time hearing aid users such as myself have gone through this scenario: you’re outside, wearing your hearing aids, and the weather (sunny, 75 degrees) is great. Perhaps you’re taking a walk around your neighborhood, or you and a friend are having lunch outside. But then all of a sudden, the weather takes a nasty turn and it’s pouring rain. Since you don’t have an umbrella or a rain jacket, you scramble to find shelter. While you are doing so, you also wonder if you should take off your hearing aids, as they are (sadly) not waterproof. You consider a few important questions. Is it raining hard enough? Can you reach shelter quickly? Is it safe to take off your hearing aids?
All this is due to one rather unfortunate feature of hearing aids: they are not (generally) waterproof. Even a waterproof label might be misleading because that means a hearing aid passed a specific test, not that you can throw it in your backyard pool and expect it to work when you pick it up a month later. I’m actually planning on writing a more extensive post on the issue of hearing aids and moisture, as I’ve only briefly mentioned that topic in this blog (e.g., in this article, where I talked about touch-screen hearing aids). But I can say from my own experience that I get disappointed every time I get what is advertised as “the latest water resistant hearing aid” only to see it break down midway through a game of Ultimate Frisbee. I don’t typically have problems with rain anymore, because I’m usually prepared with an umbrella — or I just stay indoors.
Anyway, I’m happy to report that hearing aid wearers in the San Francisco Bay Area need not worry about rain. I moved in Berkeley on August 13, so it’s been almost two months. And I only remember one day when it rained. That was a few weeks ago, and it was a light drizzle at that. I brought two umbrellas and a rain jacket when I moved in, and they’re just collecting dust in my room, waiting for the next rainy day to occur. As indicated by my screenshot of the current forecast, that may not come for a while. It’s not as if the weather is scorching hot either, which might induce unusual amounts of sweat (another threat to hearing aids). It’s usually around 60 to 85 degrees here.
There was a newspaper article a few weeks ago that touched on the topic of rain in the Bay Area, so from what I can tell, I should expect more rain once it’s winter, but probably not that much. (I’m also aware that California’s in a historic drought, so I do feel guilty for being happy about the lack of rain.) Needless to say, the weather here is vastly different from the weather in Williamstown, MA. I remember when it would rain for days in September, thus ruining the Ultimate Frisbee fields. So far, the weather in Berkeley has been terrific, which is probably one of many reasons why graduate students come here from all over the world.
After a Few Weeks of CART, Why do I Feel Dissatisfied?

As I said in a recent post, I’ve been using a mixture of captioning (also known as CART) and interpreting services for various Berkeley-related events. For my two classes, I decided to forgo interpreting services in favor of captioning. Part of this was out of a desire to try something new, but I think most of it was because when I was at Williams, I experienced enormous frustration with my inability to sufficiently understand and follow technical lectures with interpreting services. (I had to rely on hours of independent reading before or after the talks for the material to make sense.)
This isn’t a knock on the interpreters, or a criticism of Williams. I’ve said before and will gladly continue to say that I was very happy with the accommodations Williams was able to provide me, and how my interpreters have put up with me for four years as I consistently enrolled in the classes that they hated the most.
The problem is the technical term dilemma that continues to plague my experience in the classroom.
In the best case scenario, using captioning services would let me focus primarily on the professor talking, and if there was something I missed, I could fall back on the captions to catch up on a few sentences. To make it clear, the way CART usually works is that the captioner will type on a laptop with the text small enough so that I can quickly look at the screen to see what was being said 10 seconds ago. With interpreting services, one can’t go “back in time.”
The other advantage I was hoping to gain from CART pertained to preserving the spelling of technical terms. An interpreter can’t really sign the word Gaussian, but a captioner can at least type out that word correctly once the professor has said it often enough (or has written it on the board).
To top it all off, I was told during my first meeting with the Disabled Students’ Program (DSP) that CART would be able to capture content with 99 percent accuracy.
Unfortunately, theory hasn’t matched with reality and, if anything, my experience in Berkeley classes so far has been more frustrating than with my Williams classes.
I’m not trying to criticize Berkeley as a school, which so far looks like they’re excellent with regards to accommodations (no issues that have shown up in other schools so far!). This article is more of a holistic frustration at the whole education system.
Let me be a little more specific about what has happened so far. This semester, I’m taking two graduate-level computer science classes, natural language processing (NLP) and statistical learning theory (SLT). The former is an Artificial Intelligence course that’s heavy on programming, and the latter is a math course with problem sets. At the time of this writing, I have sat through eleven lectures for each class.
Natural Language Processing
One interesting wrinkle is that I have remote captioning for my NLP class. This means for each lecture I bring a microphone hooked up to my laptop, and a captioner in a different area (perhaps at her own house) will connect to my computer through Skype or Google Hangout and type what’s being said. I see the captions via another program that lets me see the captioner’s computer screen on my laptop. It’s pretty cool, actually. (One student in the class thought it was a sophisticated automatic speech recognition system.)
Berkeley had to provide remote captioning because there were too many requests for CART during the class time slot. I was fine with it because, well, why not?
Unfortunately, I didn’t anticipate there being multiple factors that would result in a tiring and frustrating classroom experience.
First, my NLP class moves at a very fast pace. (Since it is a graduate level computer science course, I expected that it would move quickly, though perhaps not as fast as it has so far.) As a consequence, my captioner has had a hard time keeping up with the conversational pace. It’s common for her to type in all the sentences for about thirty seconds, then to take a five second break, and then to come back to captioning. I can’t blame her — it’s impossible to type nonstop for the eighty-minute lecture, but it does throw a wrench in my plan to try and understand everything from the transcript, because there’s so much that could be missing.
To be fair to the professor, we do have a lot to discuss, and the students here are skilled enough so that most can absorb plenty of knowledge even when it’s coming at a fast pace. So while I do feel like the lecture rate is a bit too high, I know it’s not something that can be addressed easily without causing some additional problems. I’ve already talked to the professor about possibly slowing down the lecture rate, and he was happy I brought it to his attention and would see what he could do without reducing the material we cover.
My other frustrations in the class stem from the remote connection. The microphone that Berkeley’s DSP gave me is powerful, but when other students ask questions in the class, their voices are often too quiet for the captioner to pick up. As a result, most of the time when students ask questions, the captioner has been forced to write down “(Inaudible)” which is the standard way of marking down unknown comments, so I don’t understand the flow of conversation between the students and the professor. And knowing what the other students are saying was one of the major benefits of having interpreting services! In a classroom setting, the professors are much easier for me to hear than the other students, even if those students are physically closer to me. I haven’t been asking the professor to repeat what the students have said, which is my fault — I need to start doing that!
My other, and perhaps most significant frustration with the remote captioning service, pertains to the logistic and technical difficulties we have experienced. The first lecture was fine, but the second was not. I had an on-campus captioner act as a substitute for the remote captioner, but the substitute didn’t get the right room assignment because the professor had to change the room (due to over-enrollment), and I didn’t update it with DSP because, well, a remote captioner doesn’t need to have a room number.
After emailing the substitute about the new room, she was able to find it thirty minutes into lecture, and by that time I was lost since I spent more time worrying about the captioner rather than the lecture material. And even when she was there, it’s hard to catch up on the last fifty minutes when you’ve missed the first thirty.
The third lecture was much better, even if the captioner had trouble typing in some of the technical terms — I sent her spellings some of the terms to make things easier. For the fourth lecture, though, I had a substitute remote captioner who needed to use Google Hangout to connect to me (I had used Skype earlier, as was the default). And we ran into a problem: even after connecting ourselves with Google Hangout, she couldn’t hear anything that was going on in the class.
We finally resolve the issue thirty minutes later — she installed Skype, and I removed the microphone I had been provided with and relied on my laptop’s internal microphone, and suddenly that worked. I have no idea why. But that class was a disaster. For the first thirty minutes, I was constantly on Google Chat with my remote captioner, trying to fiddle around with settings on my laptop to get her to hear what was going on in the class (I bet the students sitting near me were wondering what I was doing). And again, when you miss the first thirty minutes of a lecture, it’s hard to catch up on the last fifty.
Fortunately, I don’t think I will have connection issues in the future. I had a meeting with the primary remote captioner and we spent an evening trying to resolve our technical difficulties. Berkeley’s DSP also provided me with a more powerful microphone.
The fifth, sixth, and seventh lectures were okay, but technical problems continued during lectures eight and nine. In both cases, the captioner ran into problem with her own computer, so I wasn’t able to get captioning shown on my laptop until 28 and 12 minutes after lecture started (respectively). And while the tenth and eleventh lectures were free of notable problems, I’ll still be carefully monitoring any future technical difficulties (as I have been doing so far) and will send Berkeley’s DSP a report on it at the end of the semester, when I will re-evaluate whether I want captioning services at all (and if so, whether they should be remote).
So I guess the point is, while remote services sound pretty cool, be wary of technical difficulties that could happen, along with heightened difficulty of knowing what other students are saying.
Now let’s talk about my other class.
Statistical Learning Theory
As I mentioned earlier, SLT is a standard mathematics and statistics course. The professor lectures by writing on a chalkboard (we have no slides) and assigns us biweekly problem sets. I sit next to my captioner in the front of the classroom.
It might be hard to believe, given my description of NLP earlier, but captioning for SLT has been perhaps even less effective, thought this time it’s largely due to the material we cover in class.
Consider how captioners do their job. When captioners type, they type based on sound cues, and their special machines combine those cues together to form common English words. Captioners do not type word by word on a QWERTY keyboard like most of us do, because that would be too slow and introduce numerous typographical errors.
By now, you might see the problem: their machines are designed to recognize and auto-complete common English words. By typing in several sound cues, a captioner can quickly print phrases or long words on the screen that are automatically spelled correctly. With a technical class, however, these phrases or words suddenly aren’t that common, so the screen doesn’t auto-fill their text because advanced statistics terminology isn’t in its dictionary. The way to get around this is to pre-assign words to sound cues in the machine. For instance, my captioner has assigned the word Gaussian to the spell-checker so that it will print it out according to the appropriate sound cues, rather than print text like “GAU SAY EN” on screen. (Note to anyone who’s taking CS 281a: you’ll be playing around with Gaussians a lot.) But it’s still a problem in my class because new and old advanced terms are thrown around every lecture.
And to make matters a little worse, not everyone in the class has great articulation (according to my captioner).
Putting it All Together
There’s a common factor to both of my classes that might be a reason why I’m not getting the most out of the lectures: I’m not used to CART. So maybe there’s a bit of an adjustment period as I determine the optimal combination of looking at the professor and looking at the computer screen.
But I don’t think adjustment can explain all the difficulty I’m having in my classes. At the start of the semester, I sat through one of Maneesh Agrawala’s lectures on visualization, and my captioner had no problem at all (and I understood what was going on). In fact, I think that she did obtain around 99 percent accuracy in that lecture. Maneesh has a remarkable ability to speak at a reasonable pace and he throws out pauses in judicious locations. It shows that one’s experience with captioning can vary considerably depending on the speaker and other factors.
That doesn’t change the fact that, so far, I feel disappointed that I haven’t gotten more out of class lectures. I do make this up by spending a lot of my own time reviewing. Every few days, I will spend a full workday, 9:00am to 5:00pm, just reviewing lecture material. I don’t mind doing a lot of this work on my own, but I’m worried that if I have to keep doing this, it will take away time from my research. I don’t want to be consumed with classes, but I also have minimum GPA requirements, so I can’t slack off either. The better thing would be to do a lot of reading before the class, which admittedly I’ve been slacking off on due to giving priority on research and homework, but if I’m not getting much out of my classes, I’ve got to change my strategy.
Overall, being in my classes has been an incredibly frustrating experience for me, as I’ve had to spend several full days reading my textbooks about concepts that I think most other students got right out of lecture. This has been a major factor in what was an unusually brutal September for me, though again, to be fair to Berkeley, last September was arguably less stressful for me than September of 2013.
Nonetheless, I do feel like I am learning a lot, and I do feel like things will improve as the semester progresses. But in the meantime, I know there’s only one thing that can make this easier: doing a ridiculous amount of self-study. Do the readings, find online tutorials, do whatever it takes to learn the stuff discussed in lecture, ideally before the lecture occurs. Doing a ton of reading before lectures has proven to be a rock-solid learning strategy for me.
On Data Wrangling

Last month, the New York Times published an interesting article that connected with my experience working as a computer scientist. The idea is that there’s so much data out there — in case you’ve been living under a rock, it’s the age of Big Data — but it’s becoming increasingly harder for us to make sense of it so that we can actually use the data well. Here’s a relevant passage:
But if the value comes from combining different data sets, so does the headache. Data from sensors, documents, the web and conventional databases all come in different formats. Before a software algorithm can go looking for answers, the data must be cleaned up and converted into a unified form that the algorithm can understand.
So why does this article connect to me? Every major computer science project I’ve worked on has involved a nontrivial amount of data “wrangling” (for lack of a better word), such as the one I worked on at the Bard REU. I also had a brief internship last summer where my job was to implement Latent Dirichlet Allocation, and it took me a substantial amount of time to convert a variety of documents (plain text, .doc, .docx, .pdf, and others) into a format that the algorithm could easily use.
Fortunately, many researchers are trying to help us out, such as professors Jeff Heer at the University of Washington and Joe Hellerstein at the University of California, Berkeley. I met Jeff when I was visiting the school a few months ago, and he gave me an update on the amazing work he and his group have done.
Meanwhile, as I finished reading the article, I was also thinking about how our computer science classes should prepare us for the inevitable amount of data wrangling we’ll be doing in our jobs. The standard machine learning computer science project, for instance, will tell us to implement an algorithm and run it on some data. That data, though, is often formatted and “pre-packaged,” which makes it easier for students but typically doesn’t provide the experience of having to deal with a haphazard collection of data.
So I would suggest that in a data-heavy computer science class, at least one of the projects should involve some data wrangling. These might be open-ended projects, where the student is given little to no starter code and must implement an algorithm while at the same time figuring out how to deal with the data.
On a related note, I should also add that students should appreciate it when their data comes nicely formatted. Someone had to assemble the data, after all. In addition, for many computer science projects, such as the Berkeley Pacman assignments, much of the complicated, external code has already been written and tested, making our jobs much easier. So to anyone who is complaining about how hard their latest programming project is, just remember, someone probably had to work twice as hard as you did to prepare the project and its data in the first place.
Good News: Accommodations for Berkeley Events are Quick and Easy to Obtain

I’ve only been a Berkeley student for about three weeks, but I’m already appreciating how quick and easy it has been to get accommodations for various events. To do so, one just needs to go to the Disability Access Services website, fill out a two-page online form, and submit. I’ve filed about half a dozen requests already, an indication of how many meetings I’ll need to be attending to during my time in Berkeley. (Though I’m probably better off than the tenured professors here in that regard.)
The services one can request fall in two categories: communication and mobility. I’m only familiar with the communications aspect, which includes sign language interpreting and real-time captioning. Since this is the first time I’ve really been able to take advantage of captioning availability, I’m trying out a mix — some events with captioning, some with interpreting.
Not only is it easy to obtain these services, it’s also quite reliable. I’ve never had a request denied or forgotten. In fact, I even got a captioner for a new graduate student meeting despite giving only 36 hours of advance notice. (I had forgotten that it was happening … won’t do that again!) I’ve met a few of the people who work at the access services group, and they’re all really friendly. They are closely related to the Disabled Students’ Program at Berkeley, which is designed to help accommodate students for class-related purposes.
I think even people who aren’t affiliated with Berkeley in some way can request accommodations for events, though they might need to pay a small fee. Berkeley students can get them for free.
Berkeley Orientation

My life has been busy in the past few weeks as I’ve gotten adjusted to life in Berkeley. Part of this process has been going through orientation. I sat through a new EECS graduate student orientation and a general graduate student orientation.
For the most part, what we discussed during the orientations wasn’t too surprising. Here are a few highlights from the EECS-specific one.
- There were 1,615 applicants to the computer science doctoral program. Berkeley accepted 83, for an acceptance rate of 5.1%. The yield was 43, not including five extra students coming in from last year’s cycle. Interestingly enough, this information doesn’t seem to be available anywhere and I’ve heard acceptance rates range from as high as 9% to as low as 2%, so it was nice to see these values come directly from the department chair. There were even more applicants for the electrical engineering program (at least 1,800). Coming from a school that has no engineering courses, I would have thought that computer science would have been more popular than electrical engineering. All together, we have 98 entering EECS Ph.D. students.
- The orientation made it clear that the department is passionate about supporting the well-being of its graduate students. The chair emphasized the need to be inclusive of people from all backgrounds. We also had a psychologist and a member from the Berkeley Disabled Students Program speak to us. Finally, there were representatives from the Computer Science Graduate Student Association (CSGSA), an organization designed by the students to support each other school (there’s also an EE version). I really did come out of this orientation feeling like Berkeley cares about their EECS graduate students.
- The end of the orientation was mostly about working and getting funding. There was too much information to absorb in one day, but fortunately the handouts we got contained the relevant information.
The general graduate student orientation, held the following day, was less useful than the department-specific one, and I could tell by the size of the crowd that most of the EECS students probably didn’t go. Some highlights:
- The most important one for me was learning about residency, residency, and residency. As a public school, Berkeley charges out-of-state students non-resident tuition, including graduate students. The EECS department pays for this during the first year, but from the second year onwards, we pay an extra $8,000 unless we’ve established California residency.
- I also attended workshops relating to student health services and “surviving and thriving” in Berkeley.
- And for any graduate student who expects to be hungry often, there was free breakfast and lunch.
In addition to orientation, I’ve had a few classes and research group meetings. I’ll talk about the research later — stay tuned.
Reading the Oticon Sensei Hearing Aid Manual
I’m 22 years old and have been wearing hearing aids for most of my life. But for some reason, I’ve never read a hearing aid instructions manual. Now that I live in California, far away from my audiologist in New York, I’m going to need to be a bit more independent about managing my hearing aids. So I read the manual for my new Oticon Sensei hearing aids. Here are some of its important messages and the comments I have about them, which probably apply to many other types of hearing aids.
- “The Sensei BTE [Behind the Ear] 13 is a powerful hearing instrument. If you have been fitted with BTE 13, you should never allow others to wear your hearing instrument as incorrect usage could cause permanent damage to their hearing.” My comment: I already knew this, and I think it’s a point worth emphasizing again. Your hearing aids are for you and not for anyone else!
- “The hearing instrument hasn’t been tested for compliance with international standards concerning explosive atmospheres, so it is recommended not to us the hearing aids in areas where there is a danger of explosions.” My comment: again, this is straightforward, because generally anything with batteries can have a risk of explosion, but I think the better strategy is to not go near those places at all. (And if you’re a construction worker, I’d ask for a different work location.)
- “The otherwise non-allergenic materials used in hearing instruments may in rare cases cause a skin irritation or any other unusual condition.” My comment: I had the misfortune of experiencing skin irritation a few months ago. Some new earmolds I had were designed differently from what I was used to, causing skin in my inner ear to harden. I had to dig into an old reserve of earmolds and fit those to my hearing aids to comfortably wear them.
- “[When turning off hearing aids] Open the battery door fully to allow air to circulate whenever you are not using your hearing instrument, especially at night or for longer periods of time.” My comment: I sort of knew this, but now it’s concrete. From now on, I’ll keep the battery doors open when I put them in the dryer each night. Unfortunately, the manual didn’t specify whether the battery should stay in the compartment or not.
- “Hearing instruments are fitted to the uniqueness of each ear […] it is important to distinguish between the left hearing instrument and the right.” My comment: For someone like me, who relies more on one ear for hearing than the other, keeping track of what goes left and what goes right is crucial. I’ve gotten confused several times about this when I replaced earmolds for various hearing aids.
- “Although your hearing instrument has achieved an IP57 classification, it is referred to as being water resistant, not waterproof. […] Do not wear your hearing instrument while showering, swimming, snorkeling or diving.” My comment: as usual, one needs to be careful about the distinction between water **resistant versus being *waterproof. *From my own experience, the Oticon Sensei does an excellent job resisting sweat, and I can only remember a handful of times when they stopped working normally during or after a gym session. (As I mentioned before, the same isn’t true for some types of hearing aids.)
I emphasize the importance of reading these manuals because if one is going to be using a hearing aid often, it’s important to know as much about them as possible, and I think this aspect gets glossed over in today’s busy lives. Similarly, don’t forget to learn more about your cars, houses, phones, laptops, and other expensive items — you might learn something useful.