My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
Offline (Batch) Reinforcement Learning: A Review of Literature and Applications
Reinforcement learning is a promising technique for learning how to perform tasks through trial and error, with an appropriate balance of exploration and exploitation. Offline Reinforcement Learning, also known as Batch Reinforcement Learning, is a variant of reinforcement learning that requires the agent to learn from a fixed batch of data without exploration. In other words, how does one maximally exploit a static dataset? The research community has grown interested in this in part because larger datasets are available that might be used to train policies for physical robots. Exploration with a physical robot may risk damage to robot hardware or surrounding objects. In addition, since offline reinforcement learning disentangles exploration from exploitation, it can help provide standardized comparisons of the exploitation capability of reinforcement learning algorithms.
Offline reinforcement learning, henceforth Offline RL, is closely related to imitation learning (IL) in that the latter also learns from a fixed dataset without exploration. However, there are several key differences.
-
Offline RL algorithms (so far) have been built on top of standard off-policy Deep Reinforcement Learning (Deep RL) algorithms, which tend to optimize some form of a Bellman equation or TD difference error.
-
Most IL problems assume an optimal, or at least a high-performing, demonstrator which provides data, whereas Offline RL may have to handle highly suboptimal data.
-
Most IL problems do not have a reward function. Offline RL considers rewards, which furthermore can be processed after-the-fact and modified.
-
Some IL problems require the data to be labeled as expert versus non-expert. Offline RL does not make this assumption.
I preface the IL descriptions with “some” and “most” because there are exceptions to every case and that the line between methods is not firm, as I emphasized in a blog post about combining IL and RL.
Offline RL is therefore about deriving the best policy possible given the data. This gives us the hope of out-performing the demonstration data, which is still often a difficult problem for imitation learning. To be clear, in tabular settings with infinite state visitation, it can be shown that algorithms such as Q-learning converge to an optimal policy despite potentially sub-optimal off-policy data. However, as some of the following papers show, even “off-policy” Deep RL algorithms such as the Deep Q-Network (DQN) algorithm require substantial amounts of “on-policy” data from the current behavioral policy in order to learn effectively, or else they risk performance collapse.
For a further introduction to Offline RL, I refer you to (Lange et al, 2012). It provides an overview of the problem, and presents Fitted Q Iteration (Ernst et al., 2005) as the “Q-Learning of Offline RL” along with a taxonomy of several other algorithms. While useful, (Lange et al., 2012) is mostly a pre-deep reinforcement learning reference which only discusses up to Neural Fitted Q-Iteration and their proposed variant, Deep Fitted Q-Iteration. The current popularity of deep learning means, to the surprise of no one, that recent Offline RL papers learn policies parameterized by deeper neural networks and are applied to harder environments. Also, perhaps unsurprisingly, at least one of the authors of (Lange et al., 2012), Martin Riedmiller, is now at DeepMind and appears to be working on … Offline RL.
In the rest of this post, I will summarize my view of the Offline RL literature. From my perspective, it can be roughly split into two categories:
-
those which try and constrain the reinforcement learning to consider actions or state-action pairs that are likely to appear in the data.
-
those which focus on the dataset, either by maximizing the data diversity or size while using strong off-policy (but not specialized to the offline setting) algorithms, or which propose new benchmark environments.
I will review the first category, followed by the second category, then end with a summary of my thoughts along with links to relevant papers.
As of May 2020, there is a recent survey from Professor Sergey Levine of UC Berkeley, whose group has done significant work in Offline RL. I began drafting this post well before the survey was released but engaged in my bad “leave the draft alone for weeks” habit. Professor Levine chooses a different set of categories, as his papers cover a wider range of topics, so hopefully this post provides an alternative yet useful perspective.
Off-Policy Deep Reinforcement Learning Without Exploration
(Fujimoto et al., 2019) was my introduction to Offline RL. I have a more extensive blog post which dissects the paper, so I’ll do my best to be concise in this post. The main takeaway is showing that most “off-policy algorithms” in deep RL will fail when solely shown off-policy data due to extrapolation error, where state-action pairs $(s,a)$ outside the data batch can have arbitrarily inaccurate values, which adversely affects algorithms that rely on propagating those values. In the online setting, exploration would be able to correct for such values because one can get ground-truth rewards, but the offline case lacks that luxury.
The proposed algorithm is Batch Constrained deep Q-learning (BCQ). The idea is to run normal Q-learning, but in the maximization step (which is normally $\max_{a’} Q(s’,a’)$), instead of considering the max over all possible actions, we want to only consider actions $a’$ such that $(s’,a’)$ actually appeared in the batch of data. Or, in more realistic cases, eliminate actions which are unlikely to be selected by the behavior policy $\pi_b$ (the policy that generated the static data).
BCQ trains a generative model — a Variational AutoEncoder — to generate actions that are likely to be from the batch, and a perturbation model which further perturbs the action. At test-time rollouts, they sample $N$ actions via the generator, perturb each, and pick the action with highest estimated Q-value.
They design experiments as follows, where in all cases there is a behavioral DDPG agent which generates the batch of data for Offline RL:
-
Final Buffer: train the behavioral agent for 1 million steps with high exploration, and pool all the logged data into a replay buffer. Train a new DDPG agent from scratch, only on that replay buffer with no exploration. Since the behavioral agent will have been learning along those 1 million steps, there should be high “state coverage.”
-
Concurrent: as the behavioral agent learns, train a new DDPG agent concurrently (hence the name) on the behavioral DDPG replay buffer data. Again, there is no exploration for the new DDPG agent. The two agents should have identical replay buffers throughout learning.
-
Imitation Learning: train the behavioral agent until it is sufficiently good, then run it for 1 million steps (potentially with more noise to increase state coverage) to get the replay buffer. The difference with “final buffer” is that the 1 million steps are all from the same policy, whereas the final buffer was throughout 1 million steps, which may have resulted in many, many gradient updates depending on the gradient-to-env-steps hyper-parameter.
The biggest surprise is that even in the concurrent setting, the new DDPG agent fails to learn well! To be clear: the agents start at the beginning with identical replay buffers, and the offline agent draws minibatches directly from the online agent’s buffer. I can only think of a handful of differences in the training process: (1) the randomness in the initial policy and (2) noise in minibatch sampling. Am I missing anything? Those factors should not be significant enough to lead to divergent performance. In contrast, BCQ is far more effective at learning offline from the given batch of DDPG data.
When reading papers, I often find myself wondering about the relationship between algorithms in batches (pun intended) of related papers. Conveniently, there is a NeurIPS 2019 workshop paper where Fujimoto benchmarks algorithms. Let’s turn to that.
Benchmarking Batch Deep Reinforcement Learning Algorithms
This solid NeurIPS 2019 workshop paper, by the same author of the BCQ paper, makes a compelling case for the need to evaluate Batch RL algorithms under unified settings. Some research, such as his own, shows that commonly-used off policy DeepRL algorithms fail to learn in an offline fashion, whereas (Agarwal et al., 2020) counter this, but with the caveat of using a much larger dataset.
One of the nice things about the paper is that it surveys some of the algorithms researchers have used for Batch RL, including Quantile Regression DQN (QR-DQN), Random Ensemble Mixture (REM), Batch Constrained Deep Q-Learning (BCQ), Bootstrapping Error Accumulation Reduction Q-Learning (BEAR-QL), KL-Control, and Safe Policy Improvement with Baseline Bootstrapping DQN (SPIBB-DQN). All these algorithms are specialized for the Batch RL setting with the exception of QR-DQN, which is a strong off-policy algorithm shown to work well in an offline setting.
Now, what’s the new algorithm that Fujimoto proposes? It’s a discrete version of BCQ. The algorithm is delightfully straightforward:

My “TL;DR”: train a behavior cloning network to predict actions of the behavior policy based on its states. For the Q-function update on iteration $k$, change the maximization over the successor state actions to only consider actions satisfying a threshold:
\[\mathcal{L}(\theta) = \ell_k \left(r + \gamma \cdot \Bigg( \max_{a' \; \mbox{s.t.} \; \frac{G_\omega(a'|s')}{\max \hat{a} \; G_\omega(\hat{a}|s')} > \tau} Q_{\theta'}(s',a') \Bigg) - Q_\theta(s,a) \right)\]When executing the policy during test-time rollouts, we can use a similar threshold:
\[\pi(s) = \operatorname*{argmax}_{a \; \mbox{s.t.} \; \frac{G_\omega(a'|s')}{\max \hat{a} \; G_\omega(\hat{a}|s')} > \tau} Q_\theta(s,a)\]Note the contrast where normally in Q-learning, we’d just do the max or argmax over the entire set of valid actions. Therefore, we will end up ignoring some actions that potentially have high Q-values, but that’s fine (and desirable!) if those actions have vastly over-estimated Q-values.
Some additional thoughts:
-
The parallels are obvious between $G_\omega$ in continuous versus discrete BCQ. In the continuous case, it is necessary to develop a generative model which may be complex to train. In the discrete case, it’s much simpler: run behavior cloning!
-
I was confused about why BCQ does the behavior cloning update of $\omega$ inside the for loop, rather than beforehand. Since the data is fixed, this seems suboptimal since the optimization for $\theta$ will rely on an inaccurate model $G_\omega$ during the first few iterations. After contacting Fujimoto, he agreed that it is probably better to move the optimization before the loop, but his results were not significantly better.
-
There is a $\tau$ parameter we can vary. What happens when $\tau = 0$? Then it’s simple: standard Q-learning, because any action should have non-zero probability from the generative model. Now, what about $\tau=1$? In practice, this is exactly behavior cloning, because when the policy selects actions it will only consider the action with highest $G_\omega$ value, regardless of its Q-value. The actual Q-learning portion of BCQ is therefore completely unnecessary since we ignore the Q-network!
-
According to the appendix, they use $\tau = 0.3$.
There are no theoretical results here; the paper is strictly experimental. The experiments are on nine Atari games. The batch of data is generated from a partially trained DQN agent over 10M steps (50M steps is standard). Note the critical design choice of whether:
- we take a single fixed snapshot (i.e., a stationary policy) and roll it out to get steps, or
- we take logged data from an agent during its training run (i.e., a non-stationary policy).
Fujimoto implements the first case, arguing that it is more realistic, but I think that claim is highly debatable. Since the policy is fixed, Fujimoto injects noise by setting $\epsilon=0.2$ 80% of the time, and setting $\epsilon=0.001$ otherwise. This must be done on a per-episode basis — it doesn’t make sense to change epsilons within an episode!
What are some conclusions from the paper?
-
Discrete BCQ seems to be the best of the “batch RL” algorithms tested. But the curves look really weird: BCQ performance shoots up to be at or slightly above the noise-free policy, but then stagnates! I should also add: exceeding the underlying noise-free policy is nice, but the caveat is that it’s from a partially trained DQN, which is a low bar.
-
For the “standard” off-policy algorithms of DQN, QR-DQN, and REM, QR-DQN is the winner, but still under-performs a noisy behavior policy, which is unsatisfactory. Regardless, trying QR-DQN in an offline setting, even though it’s not specialized for that case, might be a good idea if the dataset is large enough.
-
Results confirm some results from (Agarwal et al., 2020) in that distributional RL aids in exploitation), but that the success they were observing is highly specific to settings Agarwal used: a full 50M history of a teacher’s replay buffer, with a changing snapshot, plus noise from sticky actions.
Here’s a summary of results in their own words:
Although BCQ has the strongest performance, on most games it only matches the performance of the online DQN, which is the underlying noise-free behavioral policy. These results suggest BCQ achieves something closer to robust imitation, rather than true batch reinforcement learning when there is limited exploratory data.
This brings me to one of my questions (or aspirations, if you put it that way). Is it possible to run offline RL, and reliably exceed the noise-free behavior policy? That would be a dream scenario indeed.
Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction
This NeurIPS 2019 paper is highly related to Fujimoto’s BCQ paper covered earlier, in that it also focuses on an algorithm to constrain the distribution of actions considered when running Q-learning in a pure off-policy fashion. It identifies a concept known as bootstrapping error which is clearly described in the abstract alone:
We identify bootstrapping error as a key source of instability in current methods. Bootstrapping error is due to bootstrapping from actions that lie outside of the training data distribution, and it accumulates via the Bellman backup operator. We theoretically analyze bootstrapping error, and demonstrate how carefully constraining action selection in the backup can mitigate it.
I immediately thought: what’s the difference between bootstrapping error here versus extrapolation error from (Fujimoto et al., 2019)? Both terms can be used to refer to the same problem of propagating inaccurate Q-values during Q-learning. However, extrapolation error is a broader problem that appears in supervised learning contexts, whereas bootstrapping is specific to reinforcement learning algorithms that rely on bootstrapped estimates.
The authors have an excellent BAIR Blog post which I highly recommend because it provides great intuition on how bootstrapping error affects offline Q-learning on static datasets. For example, this figure below shows that in the second plot, we may have actions $a$ that are outside the distribution of actions (OOD is short for out-of-distribution) induced by the behavior policy $\beta(a|s)$, indicated with the dashed line. Unfortunately, if those actions have $Q(s,a)$ values that are much higher, then they are used in the bootstrapping process for Q-learning to form the targets for Q-learning updates.

Incorrectly high Q-values for OOD actions may be used for backups, leading to
accumulation of error. Figure and caption credit: Aviral Kumar.
They also have results showing that if one runs a standard off-the-shelf off-policy (not offline) RL algorithm, that simply increasing the size of the static dataset does not appear to mitigate performance issues – which suggests the need for further study.
The main contributions of their paper are: (a) theoretical analysis that carefully constraining the actions considered during Q-learning can mitigate error propagation, and (b) a resulting practical algorithm known as “Bootstrapping Error Accumulation Reduction” (BEAR). (I am pretty sure that “BEAR” is meant to be a spin on “BAIR,” which is short for Berkeley Artificial Intelligence Research.)
The BEAR algorithm is visualized below. The intuition is to ensure that the learned policy matches the support of the action distribution from the static data. In contrast, an algorithm such as BCQ focuses on distribution matching (center). This distinction is actually pretty powerful; only requiring a support match is a much weaker assumption, which enables Offline RL to more flexibly consider a wider range of actions so long as the batch of data has used those actions at some point with non-negligible probability.

Illustration of support constraint (BEAR) (right) and distribution-matching
constraint (middle). Figure and caption credit: Aviral Kumar.
To enforce this in practice, BEAR uses what’s known as the Maximum Mean Discrepancy (MMD) distance between actions from the unknown behavior policy $\beta$ and the actor $\pi$. This can be estimated directly from samples. Putting everything together, their policy improvement step for actor-critic algorithms is succinctly represented by Equation 1 from the paper:
\[\pi_\phi := \max_{\pi \in \Delta_{|S|}} \mathbb{E}_{s \sim \mathcal{D}} \mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \min_{j=1,\ldots,K} \hat{Q}_j(s, a)\right] \quad \mbox{s.t.} \quad \mathbb{E}_{s \sim \mathcal{D}} \Big[ \text{MMD}(\mathcal{D}(\cdot|s), \pi(\cdot|s)) \Big] \leq \varepsilon\]The notation is described in the paper, but just to clarify: $\mathcal{D}$ represents the static data of transitions collected by behavioral policy $\beta$, and the $j$ subscripts are from the ensemble of Q-functions used to compute a conservative estimate of Q-values. This is the less interesting aspect of the policy update as compared to the MMD constraint; in fact the BAIR Blog post doesn’t include the ensemble in the policy update. As far as I can tell, there is no ablation study that tests just using one or two Q-networks, so I wonder which of the two is more important: the ensemble of networks, or the MMD constraint?
The most closely related algorithm to BEAR is the previously-discussed BCQ (Fujimoto et al., 2019). How do they compare? The BEAR authors (Kumar et al., 2019) claim:
-
Their theory shows convergence properties under weaker assumptions, and they are able to bound the suboptimality of their approach.
-
BCQ is generally better when off-policy data is collected by an expert, but BEAR is better when data is collected by a weaker (or even random) policy. They claim this is because BCQ too aggressively constrains the distribution of actions, and this matches the interpretation of BCQ as matching the distribution of the policy of the data batch, whereas BEAR focuses on only matching the action support.
Upon reading this, I became curious to see if there’s a way to combine the strengths of both of the algorithms. I am also not entirely convinced that MuJoCo is the best way to evaluate these algorithms, so we should hopefully look at what other datasets might appear in the future so that we can perform more extensive comparisons of BEAR and BCQ.
At this point, we now consider papers that are in the second category – those which, rather than constrain actions in some way, focus on investigating what happens with a large and diverse dataset while maximizing the exploitation capacity of standard off-policy Deep RL algorithms.
An Optimistic Perspective on Offline Reinforcement Learning
Unlike the prior papers, which present algorithms to constrain the set of considered actions, this paper argues that it is not necessary to use a specialized Offline RL algorithm. Instead, use a stronger off-policy Deep RL algorithm with better exploitation capabilities. I especially enjoyed reading this paper, since it gave me insights on off-policy reinforcement learning, and the experiments are also clean and easy to understand. Surprisingly, it was rejected from ICLR 2020, and I’m a little concerned about how a paper with this many convincing experimental results can get rejected. The reviewers also asked why we should care about Offline RL, and the authors gave a rather convincing response! (Fortunately, the paper eventually found a home at ICML 2020.)
Here is a quick summary of the paper’s experiments and contributions. When discussing the paper or referring to figures, I am referencing the second version on arXiv, which corresponds to the ICLR 2020 submission and used “Batch RL” instead of “Offline RL” so we’ll use both terms interchangeably. The paper was previously titled “Striving for Simplicity in Off-Policy Deep Reinforcement Learning.”
-
To form the batch for Offline RL, they use logged data from 50M steps of standard online DQN training. In general, one step is four environment frames, so this matches the 200M frame case which is standard for Atari benchmarks. I believe the community has settled on the 1 step to 4 frame ratio. As discussed in (Machado et al., 2018), to introduce stochasticity, the agents employ sticky actions. So, given this logged data, let’s run Batch RL, where we run off-policy deep Q-learning algorithms with a 50M-sized replay buffer, and sample items uniformly.
-
They show that the off-policy, distributional-based DeepRL algorithms Categorical DQN (i.e., C51) and Quantile Regression DQN (i.e., QR-DQN), when trained solely on that logged data (i.e., in an offline setting), actually outperform online DQN!! See Figure 2 in the paper, for example. Be careful about what this claims means: C51 and QR-DQN are already known to be better than vanilla DQN, but the experiments show that even in the absence of exploration for those two methods, they still out-perform online (i.e., with exploration) DQN.
-
Incidentally, offline C51 and offline QR-DQN also out-perform offline DQN, which as expected, is usually worse than online DQN. (To be fair, Figure 2 suggests that in 10-15 out of 60 games, offline DQN can actually outperform the online variant.) Since the experiments disentangle exploration from exploitation, we can explain the difference between performance of offline DQN versus offline C51 or QR-DQN as due to exploitation capability.
-
Thus so far we have the following algorithms, from worst to best with respect to game score: offline DQN, online DQN, offline C51, and offline QR-DQN. They did not present a full result of offline C51 except for a few games in the Appendix but I’m assuming that QR-DQN would be better in both offline and online cases. In addition, I also assume that online C51 and online QR-DQN would outperform their offline variants, at least if their offline variants are trained on DQN-generated data.
-
To add further evidence that improving the base off-policy Deep RL algorithm can work well in the Batch RL setting, their results in Figure 4 suggest that using Adam as the optimizer instead of RMSprop for DQN is by itself enough to get performance gains. In that this offline DQN can even outperform online DQN on average! I’m not sure how much I can believe this result, because Adam can’t offer that much of an improvement, right?
-
They also experiment with a continuous control variant, using 1M samples from a logged training run of DDPG. They apply Batch-Constrained Q-learning from (Fujimoto et al., 2019) as discussed above, and find that it performs reasonably well. But they also find that they can simply use Twin-Delayed DDPG (i.e., TD3) from (Fujimoto et al., 2018) (yes, the same guy!) and train normally in an off-policy fashion to get better results than offline DDPG. Since TD3 is known as a stronger off-policy continuous control deep Q-learning algorithm than DDPG, this further bolsters the paper’s claims that all we need is a stronger off-policy algorithm for effective Batch RL.
-
Finally, from the above observations, they propose their Random Ensemble Mixture (REM) algorithm, which uses an ensemble of Q-networks and enforces Bellman consistency among random convex combinations. This is similar to how Dropout works. There are offline and online versions of it. In the offline setting, REM outperforms C51 and QR-DQN despite being simpler. By “simpler” the authors mainly refer to not needing to estimate a full distribution of the value function for a given state, as distributional methods do.
That’s not all they did. In an older version of the paper, they also tried experiments with logged data from a training run of QR-DQN. However, the lead author told me he removed those results since there were too many experiments which were confusing readers. In addition, for logged data from training QR-DQN, it is necessary to train an even stronger off-policy Deep RL algorithm to out-perform the online QR-DQN algorithm. I have to admit, sometimes I was also losing track of all the experiments being run in this paper.
Here is a handy visualization of some algorithms involved in the paper: DQN, QR-DQN, Ensemble-DQN (their baseline) and REM (their algorithm):
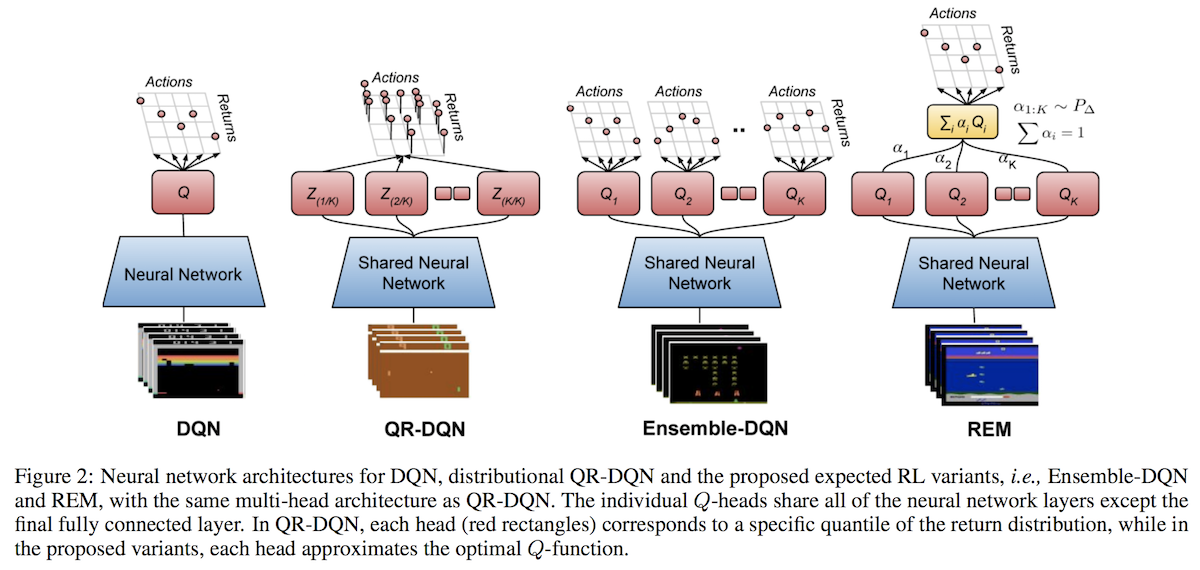
My biggest takeaway from reading this paper is that in Offline RL, the quality of the data matters significantly, and it is better to use data from many different policies rather than one fixed policy. That they get logged data from a training run means that, literally, every four steps, there was a gradient update to the policy parameters and thus a change to the policy itself. This induces great diversity in the data for Offline RL. Indeed, (Fujimoto et al., 2019) argues that the success of REM and off-policy algorithms more generally depends on the training data composition. Thus, it is not generally correct to think of these papers contradicting each other; they are more accurately thought of as different ways to achieve the same goal. Perhaps the better way going forward is simply to use larger and larger datasets with strong off-policy algorithms, while also perhaps specializing those off-policy algorithms for the batch setting.
IRIS: Implicit Reinforcement without Interaction at Scale for Learning Control from Offline Robot Manipulation Data
This paper proposes the algorithm IRIS: Implicit Reinforcement without Interaction at Scale. It is specialized for offline learning from large-scale robotics datasets, where the demonstrations may be either suboptimal or highly multi-modal. The algorithm is motivated by the same off-policy, Batch RL considerations as other papers I discuss here, and I found this paper because it cited a bunch of them. Their algorithm is visualized below:
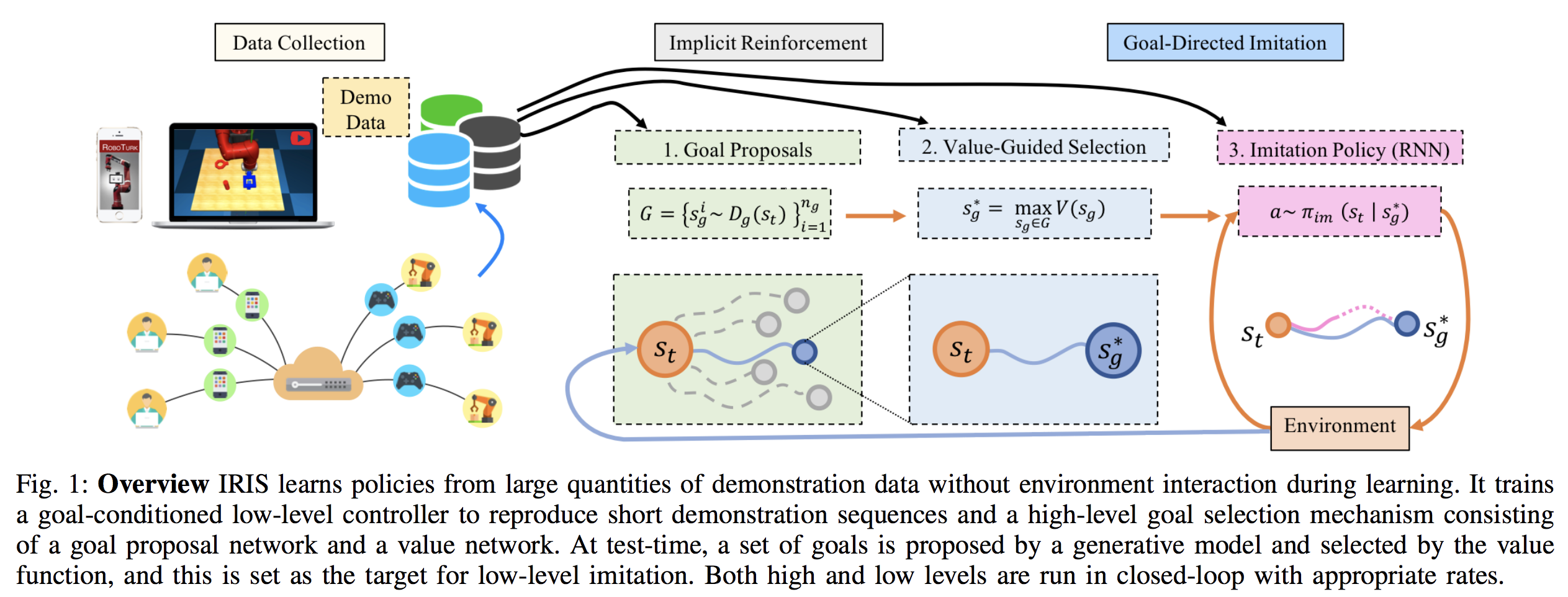
To summarize:
-
IRIS splits control into “high-level” and “low-level” controllers. The high-level mechanism, at a given state $s_t$, must pick a new goal state $s_g$. Then, the low-level mechanism is conditioned on that goal state, and produces the actual actions $a \sim \pi_{im} (s_t | s_g)$ to take.
-
The high-level policy is split in two parts. The first samples several goal proposals. The second picks the best goal proposal to pass to the low-level controller.
-
The low-level controller, given the goal $s_g$, takes $T$ actions conditioned on that goal. Then, it returns control to the high level policy, which re-samples the goal state.
-
The episode terminates when the agent gets sufficiently close to the true goal state. This is a continuous state domain, so they simply pick a distance threshold to the state. They are also in the sparse reward domain, adding another challenge.
How are the components trained?
-
The first part of the high-level controller uses a goal conditional Variational AutoEncoder (cVAE). Given a sequence of states in the data, IRIS samples pairs that are $T$ time steps apart, i.e., $(s_t, s_{t+T})$. The encoder $E(s_{t},s_{t+T})$ maps the tuple to a set of latent variables for a Gaussian, i.e., $\mu, \sigma =E(s_{t},s_{t+T})$. The decoder must construct the future state: $\hat{s}_{t+T} \sim D(s_t, z)$ where $z$ is a Gaussian sampled from $\mu$ and $\sigma$. This is for training; for test time, they sample $z$ from a standard normal $z \sim \mathcal{N}(0,1)$ (with regularization during training) and pass it to the decoder, so that it produces goal states.
-
The second part uses an action cVAE as part of their simpler variant of Batch Constrained Deep Q-learning (discussed at the beginning of this blog post) for the value function in the high-level controller. This cVAE, rather than predicting goals, will predict actions conditioned on a state. This can be trained by sampling state-action pairs $(s_t,a_t)$ and having the cVAE predict $a_t$. They can then use it in their BCQ algorithm because the cVAE will model actions that are more likely to be part of the training data.
-
The low-level controller is a recurrent neural network that, given $s_t$ and $s_g$, produces $a_t$. It is trained with behavior cloning, and therefore does not use Batch RL. But, how does one get the goal? It’s simple: since IRIS assumes the low-level controller runs for a fixed number of steps (i.e., $T$ steps) then they take consecutive state-action sequences of length $T$ and then treat the last state as the goal. Intuitively, the low-level controller trained this way will be able to figure out how to get from a start state to a “goal” state in $T$ steps, where “goal” is in quotes because it is not a true environment goal but one which we artificially set for training. This reminds me of Hindsight Experience Replay, which I have previously dissected.
Some other considerations:
-
They argue that IRIS is able to handle diverse solutions because the goal cVAE can sample different goals, to explicitly take diversity into account. Meanwhile, the low-level controller only has to model short-horizon goals at a time “resolution” that does not easily permit many solutions.
-
They argue that IRIS can handle off-policy data because their BCQ will limit actions to those likely to be generated by the data, and hence the value function (which is used to select the goal) will be more accurate.
-
They split IRIS into higher and lower level controllers because in theory this may help to handle for suboptimal demonstrations — the high-level controller can pick high value goals, and the low-level controller just has to get from point A to point B. This is also pretty much why people like hierarchies in general.
Their use of Batch RL is interesting. Rather than using it to train a policy, they are only using it to train a value function. Thus, this application can be viewed as similar to papers that are concerned with off-policy RL but only for the purpose of evaluating states. Also, why do they argue their variant of BCQ is simpler? I think it is because they eschew from training a perturbation model, which was used to optimally perturb the actions that are used for candidates. They also don’t seem to use a twin critic.
They evaluate IRIS on three datasets. Two use their prior work, RoboTurk. You can see an overview on the Stanford AI Blog here. I have not used RoboTurk before so it may be hard for me to interpret their results.
-
Graph Reach: they use a simple 2D navigation example, which is somewhat artificial but allows for easy testing of multi-modal and suboptimal examples. Navigation tasks are also present in other papers that test for suboptimal demonstrations, such as SAVED from Ken Goldberg’s lab.
-
Robosuite Lift: this involves the Robosuite Lift data, where a single human performed teleoperation (in simulation) using RoboTurk, to lift an object. The human intentionally used suboptiomal demonstrations..
-
RoboTurk Can Pick and Place: now they use a pick-and-place task, this time using RoboTurk to get a diverse set of samples due to using different human operators. You can see an overview on the Stanford AI Blog here. Again, I have not used Roboturk, but it appears that this is the most “natural” of the environments tested.
Their experiments benchmark against BCQ, which is a reasonable baseline.
Overall, I think this paper has a mix of both the “action constraining” algorithms discussed in this blog post, and the “learning from large scale datasets” papers. It was the first to show that offline RL could be used as part of the process for robot manipulation. Another project that did something similar, this time with physical robots, is from DeepMind, to which we now turn.
Scaling Data-driven Robotics with Reward Sketching and Batch Reinforcement Learning
This recent DeepMind paper is the third one I discuss which highlights the benefits of a large, massive offline dataset (which they call “NeverEnding Storage”) coupled with a strong off-policy reinforcement learning algorithm. It shows what is possible when combining ideas from reinforcement learning, human-computer interaction, and database systems. The approach consists of five major steps, as nicely indicated by the figure:
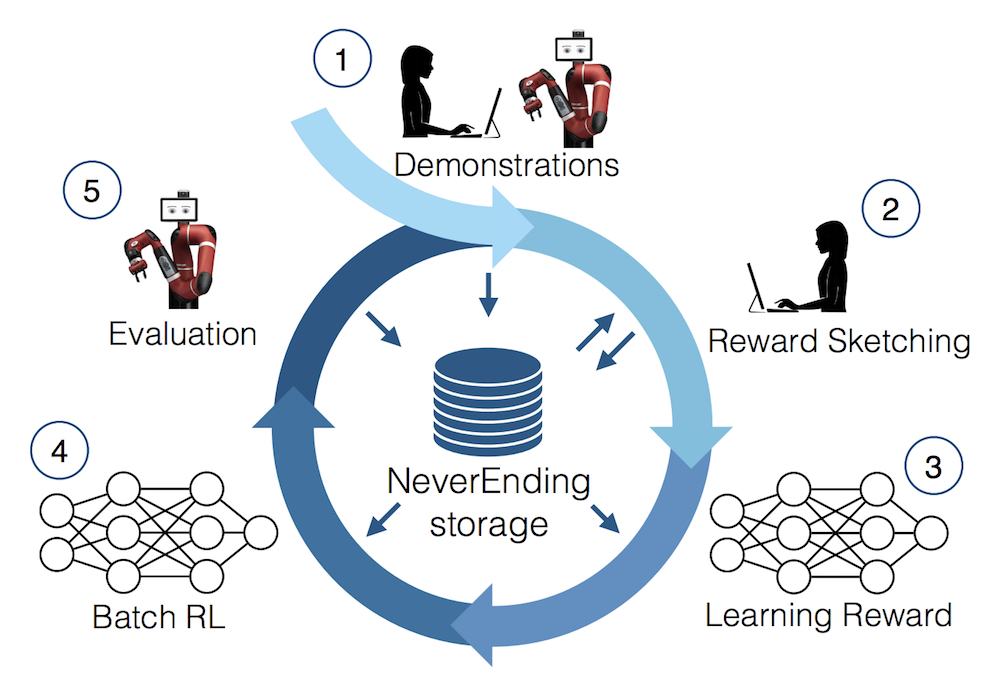
In more detail, they are:
-
Get demonstrations. This can be from a variety of sources: human teleoperation, scripted policies, or trained policies. At first, the data is from human demonstrations or scripted policies. But, as robots continue to train and perform tasks, their own trajectories are added to the NeverEnding Storage. Incidentally, this paper considers the multi-task setup, so the policies act on a variety of tasks, each of which has its own starting conditions, particular reward, etc.
-
Reward sketching. A subset of the data points are selected for humans to indicate rewards. Since it involves human intervention, and because reward design is fiendishly difficult, this part must be done with care, and certainly cannot be done by having humans slowly and manually assign a number to every frame. (I nearly vomit when simply thinking about doing that.) The authors cleverly engineered a GUI where a human can literally sketch a reward, hence the name reward sketching, to seamlessly get rewards (between 0 and 1) for each frame.
-
Learning the reward. The system trains a reward function neural network $r_\psi$ to predict task-specific (dense) rewards from frames (i.e., images). Rather than regress directly on the sketched values, the proposed approach involves taking two frames $x_t$ and $x_q$ within the same episode, and enforcing consistency conditions with the reward functions via hinge losses. Clever! When the reward function updates, this can trigger retroactive re-labeling of rewards per time step in the NES.
-
Batch RL. A specialized Batch RL algorithm is not necessary because of the massive diversity of the offline dataset, though they do seem to train task-specific policies. They use a version of D4PG, short for “Distributed Distributional Deep Deterministic Policy Gradients” which is … a really good off-policy RL algorithm! Since the NES contains data from many tasks, if they are trying to optimize the learned reward for a task, they will draw 75% of the minibatch from all of the NES, and draw the remaining 25% from task-specific episodes. I instantly made the connection to DeepMind’s “Observe and Look Further (arXiv 2018)” paper (see my blog post here) which implements a 75-25 minibatch ratio among demonstrator and agent samples.
-
Evaluation. Periodically evaluate the robot and add new demonstrations to NES. Their experiments consist of a Sawyer robot facing a 35 x 35 cm basket of objects, and the tasks generally involve grasping objects or stacking blocks.
-
Go back to step (1) and repeat, resulting in over 400 hours of video data.
There is human-in-the-loop involved, but they argue (reasonably, I would add) that reward sketching is a relatively simple way of incorporating humans. Furthermore, while human demonstrations are necessary, those are ideally drawn from existing datasets.
They say they will release their dataset so that it can facilitate development of subsequent Batch RL algorithms, though my impression is that we might as well deploy D4PG, so I am not sure if this will spur more Batch RL algorithms. On a related note, if you are like me and have trouble following all of the “D”s in the algorithm and all of DeepMind’s “state of the art” reinforcement learning algorithms, DeepMind has a March 31 blog post summarizing the progression of algorithms on Atari. I wish we had something similar for continuous control, though.
Here are some comparisons between this and the ones from (Agarwal et al., 2020) and (Mandlekar et al., 2020) previously discussed:
-
All papers deal with Batch RL from a large set of robotics-related data, though the datasets themselves differ: Atari versus RoboTurk versus this new dataset, which will hopefully be publicly available. This paper appears to be the only one capable of training Batch RL policies to perform well on new tasks. The analogue for Atari would be training a Batch RL agent on several games, and then applying it (or fine-tuning it) to a new Atari game, but I don’t think this has been done.
-
This paper agrees with the conclusions of (Agarwal et al., 2020) that having a sufficiently large and diverse dataset is critical to the success of Offline RL.
-
This paper uses D4PG as a very powerful, offline RL algorithm for learning policies, whereas (Agarwal et al., 2020) proposes a simpler version of Quantile-Regression DQN for discrete control, and (Mandlekar et al., 2020) only use Batch RL to train a value function instead of a policy.
-
This paper proposes the novel reward sketching idea, whereas (Agarwal et al., 2020) only use environments that give dense rewards, and (Mandlekar et al., 2020) use environments with sparse rewards that indicate task success.
-
This paper does not factorize policies into lower and higher level controllers, unlike (Mandkelar et al., 2020), though I assume in principle it is possible to merge the ideas.
In addition to the above comparisons, I am curious about the relationship between this paper and RoboNet from CoRL 2019. It seems like both projects are motivated by developing large datasets for robotics research, though the latter may be more specialized to visual foresight methods, but take my judgment with a grain of salt.
Overall, I have hope that, with disk space getting cheaper and cheaper, we will eventually have robots deployed in fleets that can draw upon this storage in some way.
Concluding Remarks and References
What are some of the common themes or thoughts I had when reading these and related papers? Here are a few:
-
When reading these papers, take careful note as to whether the data is generated from a non-stationary or a stationary policy. Furthermore, how diverse is the dataset?
-
The “data diversity” and “action constraining” aspects of this literature may be complementary, but I am not sure if anyone has shown how well those two mix.
-
As I mention in my blog posts, it is essential to figure out ways that an imitator can outperform the expert. While this has been demonstrated with algorithms that combine RL and IL with exploration, the Offline RL setting imposes extra constraints. If RL is indeed powerful enough, maybe it is still able to outperform the demonstrator in this setting. Thus, when developing algorithms for Offline RL, merely meeting the demonstrator behavior is not sufficient.
Happy offline reinforcement learning!
Here is a full listing of the papers covered in this blog post, in order of when I introduced the paper.
-
Sascha Lange, Thomas Gabel, Martin Riedmiller. Batch Reinforcement Learning. Book Chapter, “Reinforcement Learning: State of the Art,” 2012.
-
Sergey Levine, Aviral Kumar, George Tucker, Justin Fu. Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems, arXiv 2020.
-
Scott Fujimoto, David Meger, Doina Precup. Off-Policy Deep Reinforcement Learning without Exploration, ICML 2019.
-
Scott Fujimoto, Edoardo Conti, Mohammad Ghavamzadeh, Joelle Pineau. Benchmarking Batch Deep Reinforcement Learning Algorithms, NeurIPS 2019 workshop.
-
Aviral Kumar, Justin Fu, George Tucker, Sergey Levine. Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction, NeurIPS 2019.
-
Rishabh Agarwal, Dale Schuurmans, Mohammad Norouzi. An Optimistic Perspective on Offline Reinforcement Learning, ICML 2020.
-
Ajay Mandlekar, Fabio Ramos, Byron Boots, Silvio Savarese, Li Fei-Fei, Animesh Garg, Dieter Fox. IRIS: Implicit Reinforcement without Interaction at Scale for Learning Control from Offline Robot Manipulation Data, ICRA 2020.
-
Serkan Cabi, Sergio Gómez Colmenarejo, Alexander Novikov, Ksenia Konyushkova, Scott Reed, Rae Jeong, Konrad Zolna, Yusuf Aytar, David Budden, Mel Vecerik, Oleg Sushkov, David Barker, Jonathan Scholz, Misha Denil, Nando de Freitas, Ziyu Wang. Scaling Data-driven Robotics with Reward Sketching and Batch Reinforcement Learning, RSS 2020.
Finally, here are another set of Offline RL or related references that I didn’t have time to cover, but I will likely modify this post in the future, especially given that I already have summary notes to myself on most of these papers (but they are not yet polished enough to post on this blog).
-
Romain Laroche, Paul Trichelair, Rémi Tachet des Combes. Safe Policy Improvement with Baseline Bootstrapping, ICML 2019.
-
Natasha Jaques, Asma Ghandeharioun, Judy Hanwen Shen, Craig Ferguson, Agata Lapedriza, Noah Jones, Shixiang Gu, Rosalind Picard. Way Off-Policy Batch Deep Reinforcement Learning of Human Preferences in Dialog, arXiv 2019.
-
Xinyue Chen, Zijian Zhou, Zheng Wang, Che Wang, Yanqiu Wu, Keith Ross. BAIL: Best-Action Imitation Learning for Batch Deep Reinforcement Learning, arXiv 2019.
-
Yifan Wu, George Tucker, Ofir Nachum. Behavior Regularized Offline Reinforcement Learning, arXiv 2019.
-
Noah Y. Siegel, Jost Tobias Springenberg, Felix Berkenkamp, Abbas Abdolmaleki, Michael Neunert, Thomas Lampe, Roland Hafner, Nicolas Heess, Martin Riedmiller. Keep Doing what Worked: Behavior Modelling Priors for Offline Reinforcement Learning, ICLR 2020.
-
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, Sergey Levine. D4RL: Datasets for Deep Data-Driven Reinforcement Learning. arXiv 2020.
-
Aviral Kumar, Abhishek Gupta, Sergey Levine. DisCor: Corrective Feedback in Reinforcement Learning via Distribution Correction, arXiv 2020.
-
Aviral Kumar, Aurick Zhou, George Tucker, Sergey Levine. Conservative Q-Learning for Offline Reinforcement Learning, arXiv 2020.
-
Ashvin Nair, Murtaza Dalal, Abhishek Gupta, Sergey Levine. Accelerating Online Reinforcement Learning with Offline Datasets, arXiv 2020.
-
Tatsuya Matsushima, Hiroki Furuta, Yutaka Matsuo, Ofir Nachum, Shixiang Gu. Deployment-Efficient Reinforcement Learning via Model-Based Offline Optimization, arXiv 2020.
-
Rahul Kidambi, Aravind Rajeswaran, Praneeth Netrapalli, Thorsten Joachims. MOReL: Model-Based Offline Reinforcement Learning, arXiv 2020.
-
Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Zou, Sergey Levine, Chelsea Finn, Tengyu Ma. MOPO: Model-based Offline Policy Optimization, arXiv 2020.
-
Ziyu Wang, Alexander Novikov, Konrad Żołna, Jost Tobias Springenberg, Scott Reed, Bobak Shahriari, Noah Siegel, Josh Merel, Caglar Gulcehre, Nicolas Heess, Nando de Freitas. Critic Regularized Regression, arXiv 2020.
There is also extensive literature on off-policy evaluation, without necessarily focusing on policy optimization or deploying learned policies in practice. I did not focus on these as much since I wanted to discuss work that trains policies in this post.
I hope this post was helpful! As always, thank you for reading.
Getting Started with Blender for Robotics
Blender is a popular open-source computer graphics software toolkit. Most of its users probably use it for its animation capabilities, and it’s often compared to commercial animation software such as Autodesk Maya and Autodesk 3ds Max. Over the last one and a half years, I have used Blender’s animation capabilities for my ongoing robotics and artificial intelligence research. With Blender, I can programmatically generate many simulated images which then form the training dataset for deep neural network robotic policies. Since implementing domain randomization is simple in Blender, I can additionally perform Sim-to-Real transfer. In this blog post, and hopefully several more, I hope to demonstrate how to get started with Blender, and more broadly to make the case for Blender in AI research.
As of today’s writing, the latest version is Blender 2.83, which one can download from its website for Windows, Mac, or Linux. I use the Mac version on my laptop for local tests and the Linux version for large-scale experiments on servers. When watching older videos of Blender or borrowing related code, be aware that there was a significant jump between Blender 2.79 and Blender 2.80. By comparison, the gap between versions 2.80 to 2.83 is minor.
Installing Blender is usually straightforward. On Linux systems, I use wget
to grab the file online from the list of releases here. Suppose one wants
to use version 2.82a, which is the one I use these days. Simply scroll to the
appropriate release, right-click the desired file, and copy the link. I then
paste it after wget and run the command:
wget https://download.blender.org/release/Blender2.82/blender-2.82a-linux64.tar.xz
This should result in a *.tar.xz file, which for me was 129M. Next, run:
tar xvf blender-2.82a-linux64.tar.xz
The v is optional and is just for verbosity. To check the installation, cd
into the resulting Blender directory and type ./blender --version. In
practice, I recommend setting an alias in the ~/.bashrc like this:
export PATH=${HOME}/blender-2.82a-linux64:$PATH
which assumes I un-tarred it in my home directory. The process for installing
on a Mac is similar. This way, when typing in blender, the software will open
up and produce this viewer:

The starting cube shown above is standard in default Blender scenes. There’s a lot to process here, and there’s a temptation to check out all the icons to see all the options available. I recommend resisting this temptation because there’s way too much information. I personally got started with Blender by watching this set of official YouTube video tutorials. (The vast majority have automatic captions that work well enough, but a few strangely have captions in different languages despite how the audio is clearly in English.) I believe these are endorsed by the developers, or even provided by them, which attests to the quality of its maintainers and/or community. The quality of the videos is outstanding: they cover just enough detail, provide all the keystrokes used to help users reproduce the setup, and show common errors.
For my use case, one of the most important parts of Blender is its scripting capability. Blender is tightly intertwined with Python, in the sense that I can create a Python script and run it, and Blender will run through the steps in the script as if I had performed the equivalent manual clicks in the viewer. Let’s see a brief example of how this works in action, because over the course of my research, I often have found myself adding things manually in Blender’s viewer, then fetching the corresponding Python commands to be used for scripting later.
Let’s suppose we want to create a cloth that starts above the cube and falls on it. We can do this manually based on this excellent tutorial on cloth simulation. Inside Blender, I manually created a “plane” object, moved it above the cube, and sub-divided it by 15 to create a grid. Then, I added the cloth modifier. The result looks like this:
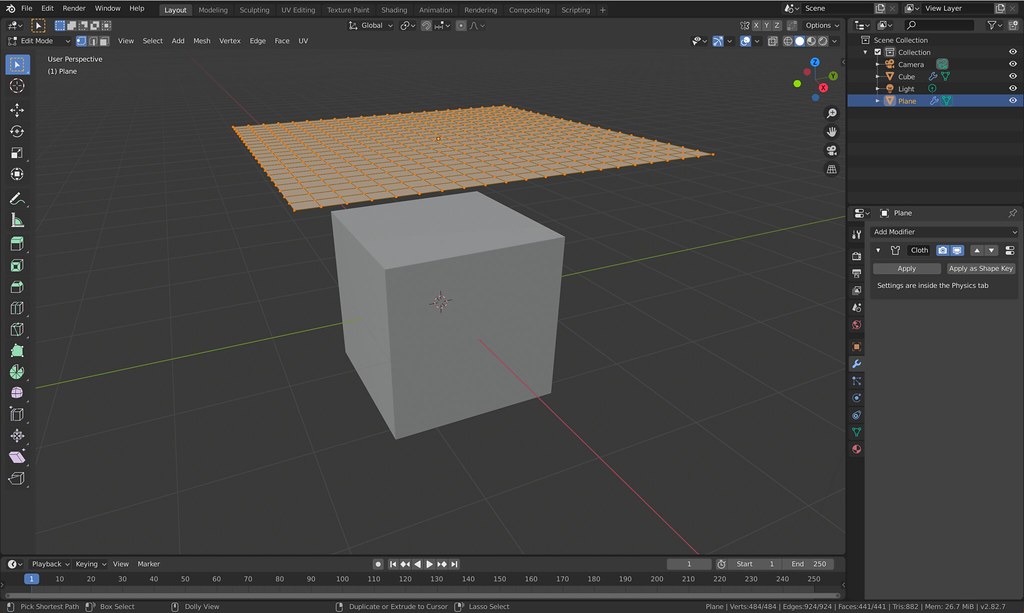
But how do we reproduce this example in a script? To do that, look at the Scripting tab, and the lower left corner window in it. This will show some of the Python commands (you’ll probably need to zoom in):
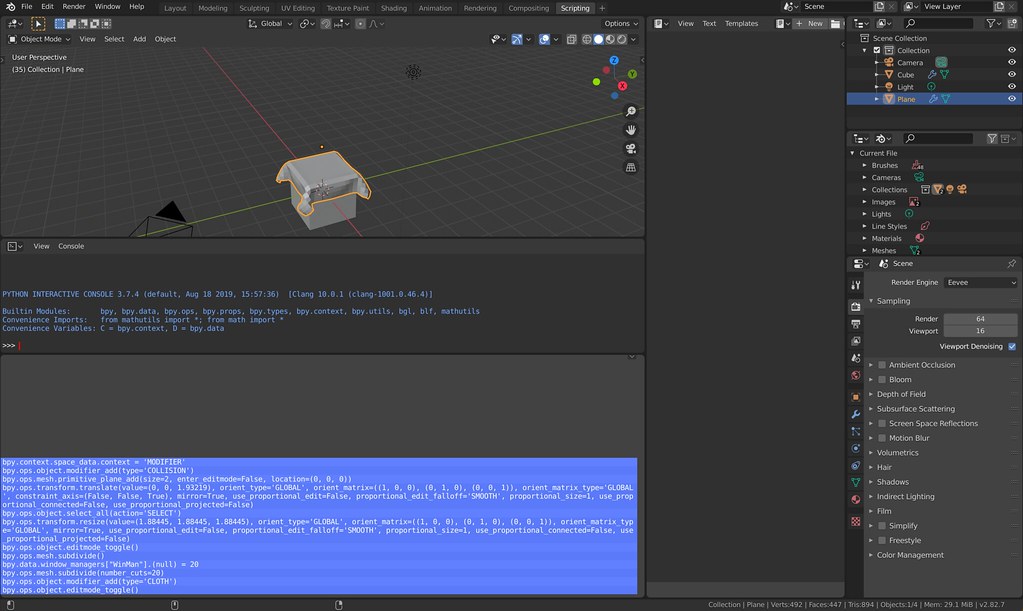
Unfortunately, there’s not always a perfect correspondence of the commands here and the commands that one has to actually put in a script to reproduce the scene. Usually there are commands missing from the Scripting tab that I need to include in my actual scripts in order to get them working properly. Conversely, some of the commands in the Scripting tab are irrelevant. I have yet to figure out a hard and fast rule, and rely on a combination of the Scripting tab, borrowing from older working scripts, and Googling stuff with “Blender Python” in my search commands.
From the above, I then created the following basic script:
# Must be imported to use much of Blender's functionality.
import bpy
# Add collision modifier to the cube (selected by default).
bpy.ops.object.modifier_add(type='COLLISION')
# Add a primitive plane (makes this the selected object). Add the translation
# method into the location to start above the cube.
bpy.ops.mesh.primitive_plane_add(size=2, enter_editmode=False, location=(0, 0, 1.932))
# Rescale the plane. (Could have alternatively adjusted the `size` above.)
# Ignore the other arguments because they are defaults.
bpy.ops.transform.resize(value=(1.884, 1.884, 1.884))
# Enter edit-mode to sub-divide the plane and to add the cloth modifier.
bpy.ops.object.editmode_toggle()
bpy.ops.mesh.subdivide(number_cuts=15)
bpy.ops.object.modifier_add(type='CLOTH')
# Go back to "object mode" by re-toggling edit mode.
bpy.ops.object.editmode_toggle()If this Python file is called test-cloth.py then running blender -P
test-cloth.py will reproduce the setup. Clicking the “play” button at the
bottom results in the following after 28 frames:
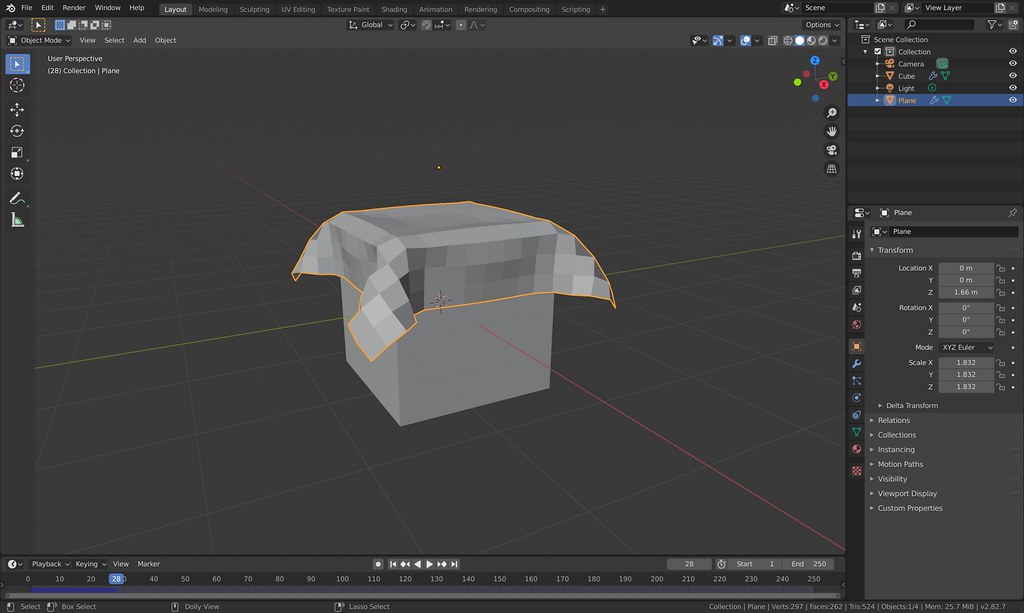
Nice, is it? The cloth is “blocky” here, but there are modifiers that can and will make it smoother.
The Python command does not need to be done in a “virtualenv” because Blender uses its own Python. Please see this Blender StackExchange post for further details.
There’s obviously far more to Blender scripting, and I am only able to scratch the surface in this post. To give an idea of its capabilities, I have used Blender for the following three papers:
- Deep Imitation Learning of Sequential Fabric Smoothing From an Algorithmic Supervisor, which is currently under review and available as a preprint on arXiv.
- Visuospatial Foresight for Multi-Step, Multi-Task Fabric Manipulation, which will appear at RSS 2020 in a few weeks.
- Learning to Smooth and Fold Real Fabric Using Dense Object Descriptors Trained on Synthetic Color Images, which is currently under review and available as a preprint on arXiv.
The first two papers used Blender 2.79, whereas the third used Blender 2.80. The first two used Blender solely for generating (domain-randomized) images from cloth meshes imported from external software, whereas the third created cloth directly in Blender and used the software’s simulator.
In subsequent posts, I hope to focus more on Python scripting and the cloth simulator in Blender. I also want to review Blender’s strengths and weaknesses. For example, there are good reasons why the first two papers above did not use Blender’s built-in cloth simulator.
I hope this served as a concise introduction to Blender. As always, thank you for reading.
Early Summer Update
Hello everyone! Here’s a quick early summer update. I had the last few days off from research since it’s the end of the semester and a few days before I begin my remote summer internship at Google Brain. During my time off, I added a new photo album on Flickr based on my trip to Vietnam for the International Symposium on Robotics Research (ISRR) in October 2019. The album has almost 200 photos from my iPhone. I also made minor updates to my older blog posts about ISRR, which you can access in the archives, to include some featured photos.
I wanted to finish the album because going to Vietnam was one of my last major trips before the COVID-19 pandemic, and it’s one that I especially cherish among my entire travel history, because it brought me to a place I knew little about beyond reading books and news about the tragic Vietnam War. That’s one of the benefits of travel. It opens our eyes to new areas and cultures.
I also updated my earlier photo albums for some of the other conferences I attended. First, I only recently realized that my photos were private. Whoops! They should be visible now judging from my tests logging out of Flickr and checking the albums. Second, I used the Flickr “Organizr” edit setting to rearrange photos from some earlier albums to get them in order based on when I actually took the photos on my iPhone. For the ISRR 2019 album, the photos are already in order since I figured out a better way to upload photos. On my laptop, I open the Photos app, group all the photos in an album within Photos (not to be confused with an album in Flickr), and then click “File –> Export –> Export Photos.” This will make a copy of the photos on the local file system in my laptop. From there, I use Flickr’s upload feature, and order the photos alphabetically, which fortunately means the photos are in order since they are named based on numbers.
I have several other actionable items on my agenda, but admittedly these may have to be pushed back by many months. One is to improve this website design. As explained here, the blog has looked like this for over five years, and I want to experiment with changes to make the website more visually appealing. The problem is backwards compatibility: I’d need the website changes to be able to retain all my LaTeX, all my code formatting, and inevitably this means re-reading over 300 posts from the last nine years. Let me know if you have any suggestions in that regard.
As always, thanks for reading this blog. In addition, I hope you are safe, and are able to stay indoors as much as possible if you have the privilege of doing so. I hope that life will return to normal in the near future.
My Third Berkeley AI Research Blog Post
Hello everyone! My silence on this blog is because I was hard at work last month writing for another blog, the Berkeley AI Research (BAIR) Blog. Today, my collaborators and I just released a new post which describes our work in robotics and deformable object manipulation. As I’ve done with my past two BAIR Blog posts (here and here), I will mention a few words about it.
Our post is unusual in that it features papers from two different labs that didn’t formally collaborate on them. We feature four research papers in the post, two from Professor Pieter Abbeel’s lab and two from Professor Ken Goldberg’s lab. In case you’re wondering, no, we were not aware that we were working independently on these projects. I vividly remember submitting my fabric smoothing paper to arXiv back in September … and then, a few days later, seeing Lerrel Pinto (soon to be on the faculty at NYU) present us with results that were essentially what I had just showed in my paper! To be clear, it was a pleasant surprise, not an unwanted one. The more people working on the topic, the better.
Despite the focus on similar robotics tasks, the machine learning techniques we used were different. In fact, there’s an elegant, hierarchical way of categorizing our collective work. At the top, we have model-free versus model-based methods. They are further sub-divided into imitation learning versus reinforcement learning (for model-free methods) and image-space versus latent-space (for model-based methods). This neat split in our work fortunately made it easy for us to not only write this blog post – in the sense that the organization was clear from the start — but also to convey to the reader that there is no one way to approach a robotics problem. In fact, I would argue that the sign of being a true expert in one’s field is understanding the tradeoffs among various techniques that could, in theory, solve a certain problem.
I hope this post is an effective high-level introduction to the many ways we can approach robot learning problems.
In sum, here are the three BAIR Blog posts that I have written (comments are welcome):
- (August 2017) Minibatch Metropolis-Hastings, written with John Canny.
- (October 2018) Drilling Down on Depth Sensing and Deep Learning, written with Jeff Mahler, Mike Danielczuk, Matthew Matl, and Ken Goldberg.
- (May 2020), Four Novel Approaches to Manipulating Fabric using Model-Free and Model-Based Deep Learning in Simulation, written with Wilson Yan and Ryan Hoque.
All my posts took significant effort to write. I know I probably spend too much time blogging compared to what I “should” be doing as a typical PhD student, but I enjoy it too much to give it up. I plan to write at least one more blog post before graduation. At that point hopefully someone will magically appear out of thin air to take over the BAIR Blog maintenance duties from me …
As an extra bit of bonus information for reading my personal blog, here are some behind-the-scenes statistics about the BAIR Blog. First, let’s look at the number of subscribers:

Here, I show the growth in subscribers from May 2019 to April 2020. (We started the blog in July 2017.) At the time I took the screenshot, we have 5,878 subscribers. Of these, for any given email to subscribers to notify them of a new BAIR Blog post, about 41.0% will open the email, and then a further 6.8% of them will actually click on the link that we provide to the blog post. Not bad! I definitely think each BAIR blog post gets more attention than the average research paper.
Oh, and we have 536 subscribers that, for whatever reason, subscribed and then unsubscribed. What gives?!?
Now let’s switch over to page views, courtesy of Google Analytics. Here’s what I see when I list the countries of origin of our visitors, from the BAIR Blog’s entire history.
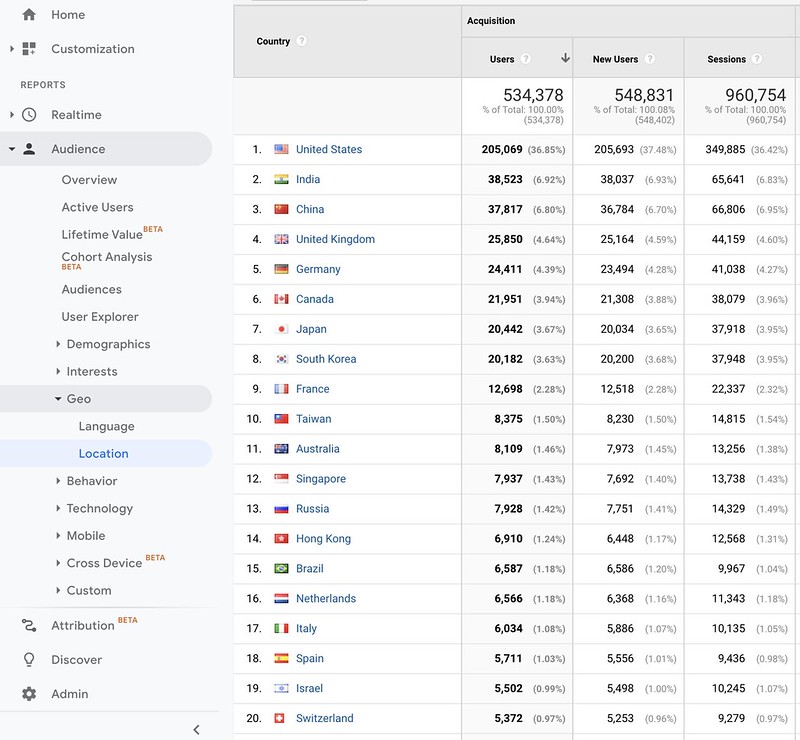
The United States is the clear leader here, with India and China the next two countries. If anything I’m surprised that the gap between the United States and India (or China) is that large. I think that Indian or Chinese citizens who access the blog while located in the United States get counted as a United States user. I’ll have to check how Google Analytics actually works here, but this seems to be the most logical conclusion.
The rest of the list also isn’t that surprising. Singapore and Hong Kong are showing, despite being the size of cities, that they have a large set of Artificial Intelligence enthusiasts.
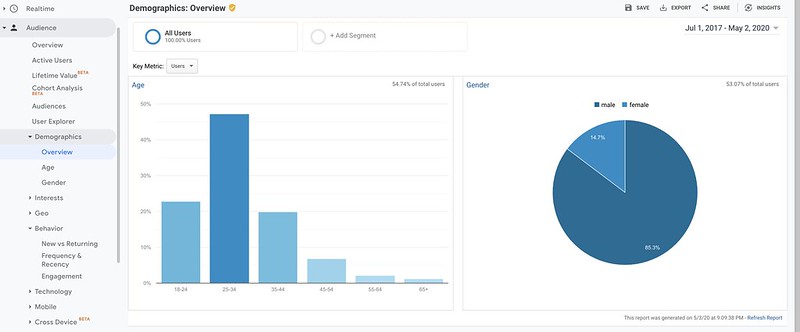
In terms of demographics, the BAIR Blog audience is estimated to be about 85% male, 15% female, as shown below. I know, we’re trying to work on this. (I frequently email BAIR students and postdocs requesting for blog posts, and I do this slightly more towards females to at least balance out the authorship.)
Here’s what happens when I look at the most popular blog posts and the page views from the beginning of the blog:
The most popular blog post by far is Chelsea Finn’s post about Model Agnostic Meta Learning (MAML), the wildly popular meta-learning algorithm for enabling deep neural networks to rapidly adapt to new tasks. Incidentally, that algorithm was a key reason why Finn landed a faculty position at Stanford. Most of the other popular posts are about (deep) reinforcement learning, which continues to be a Berkeley specialty. My first two blog posts are somewhat farther down the list, with about 10,000 page views for each. That’s still a respectable amount of views.
Well, I hope that was an interesting behind-the-scenes look at the BAIR Blog. Say, I should probably contact the maintainers of the Stanford AI Blog and the CMU Machine Learning Blog to see how much we’re dominating them in terms of subscriber count and page views …
Fully Convolutional Neural Networks for Fast and Reliable Robotic Manipulation

The figure above, from the TossingBot
paper with caption included, shows an example of how to use fully convolutional
neural networks for robotic manipulation.
Given the COVID-19 situation and the “shelter-in-place” order in the Bay Area, I have been working remotely the last few weeks. The silver lining is that, because I recently wrapped up a bunch of projects, I was already planning to use my Spring Break (which was last week) for brainstorming new research projects, which is more suitable for remote work, and I am fortunate that my job affords that opportunity. Part of the brainstorming process involves plowing through research papers on my never-ending “TODO” list. So while working at home during a pandemic has not been as good for me as it was for Sir Isaac Newton back then, it has not been terrible. I was able to read through three papers (and re-read one paper) about robotic manipulation using fully convolutional neural networks.
In particular, this blog post will discuss these four recent robotics papers, which I abbreviate as follows (see the bottom of the post for a full set of citations):
- Pick-and-Place (at ICRA 2018 and in IJRR 2019)
- Pushing and Grasping Synergies (at IROS 2018)
- Tossing Bot (at RSS 2019)
- Form2Fit (at ICRA 2020)
I already dissected Form2Fit in a prior blog post but I will revisit the paper as it is highly related to the first three. This blog post will compare and contrast the techniques used in these four papers.
The papers specialize in image-based robotic manipulation, where decisions are made on the basis of dense, per-pixel calculations. We call these “dense” operations because they compute something for every pixel in an input image. For an example of a concept that involves dense operations, see my recent blog post on dense object descriptors.
In order to efficiently perform dense per-pixel operations, the authors employ Fully Convolutional Neural Networks (FCNs). For a refresher on these, you can read the massively influential CVPR 2015 paper or perhaps look at resources such as Stanford’s CS 231n class. While FCNs were originally developed for semantic segmentation tasks, the papers I discuss here show how FCNs can be used for robotic manipulation.
Well, what are these papers about, and how do they use FCNs?
First, the Pick-and-Place paper focuses on picking out cluttered items from a bin. Their system employs several FCNs (as we’ll see, using several streams is common) to map from an image of a workspace (i.e., a bin of objects) to a value between 0 and 1, which is called an “affordance.” Numbers closer to 1 are better. Affordances should not be interpreted as a probability, even though I often think of them that way, because the training labels are not determined by measuring a probability of success, but by a relative scale labeled by human users. There are four action primitives: two for suctioning, and two for grasping, and the exact type used is not learned but hard-coded via surface normals (for suctioning) or location near a bin edge (for grasping). To handle grasp rotations, the authors simply discretize rotation into 16 groups by cleverly rotating the input RGBD images, and then passing all the images in parallel through the FCN. Interestingly, the Appendix reports other modeling architectures, such as $n$ separate FCNs, but that was sample inefficient and also challenging to load in GPU memory. While this isn’t the focus of my blog post, they interestingly do a pick first, then recognize framework, rather than the reverse which is probably more common. So, their robot picks the grasped object, and runs a separate neural network to recognize it. The predicted image class then tells the robot where to stow the object.
Second, the Pushing and Grasping Synergies paper investigates how to simultaneously learn pushing and grasping actions to pick items from a workspace and put them in an external bin. The reason for learning pushing (and not just grasping) is that they consider a workspace with objects situated next to each other, so that pushing first, then grasping, to isolate objects is often a better strategy than grasping alone. The system uses model-free deep Q-learning to train two FCNs, one for pushing and the other for grasping, and training is entirely self supervised: the authors cleverly set a system so that the robot can dump a box of objects on the workspace, and then tries pushing and grasping actions. Eventually, it trains the two Q-networks well enough that they can be deployed in scenarios with novel objects. The paper says just 5.5 hours of real-world data training is needed.
Third, the TossingBot paper investigates how to train a robot to throw arbitrary objects into target bins. Why do this, beyond generating cool videos? Throwing increases the range of the robot’s reachability and it may increase picking speed. The paper explores the synergy between grasps and throws, and jointly learns the two primitives so that the robot performs grasps that enable good throws. (It reminds me of the synergy between pushing and placing from the prior paper!) The throwing part uses the idea of residual physics. It learns a velocity magnitude conditioned on visual information, and then adds that to the output from an analytical physics model. That physics model helps to generalize to different target bins, and provides a reasonable initial velocity estimate. The estimate is then corrected from the learned model, because it is hard to model the forces of aerodynamic drag. The results and videos are truly impressive.
Fourth, the Form2Fit paper focuses on assembling kits together with robots. While my prior blog post covers this in detail, to summarize here again, robotic kit assembly is done with a sequence of picking and placing actions. The “picking” uses a suctioning action, and we need a good suctioning action as a pre-requisite to getting good placing actions. Both picking and placing are represented as FCNs. However, there is a third module, called a match network (also a FCN) which uses descriptors to indicate correspondence. Why? To associate a suction location on the object to a placing location, and to change the orientation. As I implied in my prior post, imagine we didn’t have the matching network. What would happen? Initially, given a grasped object, there are many ways we can place it successfully. But eventually we have to be able to assemble the entire kit, so each object must be inserted just at the right spot, and not just anywhere with high probability, so that subsequent actions can correctly fill up the kit.
So, to recap, here’s the desired output of the FCNs, assuming that they have been sufficiently trained:
-
Pick-and-Place: affordance (not probability) values for suctioning and grasping action primitives. Affordance values are bounded within $[0,1]$, and higher numbers are better.
-
Grasping and Pushing Synergies: $Q(s,a)$ values, or the discounted sum of future rewards at this given image $s$ and taking action primitive $a$, under the robot’s target (not behavioral) policy.
-
TossingBot: the output of the grasping network is the probability of “grasping success” when grasping at any particular pixel. Be aware that the training signal depends on the subsequent throwing success. The throwing network, interestingly, outputs the desired velocity residual which is added to an initial velocity estimate from an analytical physics model.
-
Form2Fit: the output of the suction and place networks are the probabilities of the respective actions. The output of the match network is the dense object descriptor representation, which is of the same height and width as the input image but with a higher dimension, as they used $d=64$ channels. This is used to indicate correspondence among the suction and place actions.
In order to make those FCNs output desired values, we need to train them. How does the process of collecting labels and training work for each method?
-
Pick-and-Place: skilled and experienced human users must manually label the affordances. Thus, this is the only paper among the four here that does not employ automatic data labeling via trial and error. The human manually labels pixels as positive, negative, or neither, and then pixels with neither are trained with a loss value of 0 via backpropagation. The authors had to design an interface to make this feasible, and it has to be sparsely labeled to make this practical. The training data consists of fewer than 2000 of these manually labeled images, though this is surely before data augmentation. Interestingly, 2000 is roughly on the order of how many images I had for our bed-making paper.
-
Grasping and Pushing Synergies: the labels are implicit through reinforcement learning rewards. Their reward design is simple: a $+1$ for a successful grasp and a $+0.5$ for a successful push that “meaningfully changes the scene” — the latter requires a hard-coded threshold. Through model-free reinforcement learning and backpropagation, the FCNs updates the parameters such that their output computes the learned value function.
-
TossingBot: the robot collects data through trial-and-error, and the videos show how the system is set to be self-supervised to keep human intervention at a minimum. The grasping network is trained with throwing success, not grasping success. This is critical because the whole point of grasping is to enable good throws! Therefore, when I say “grasping success probability” it really should be interpreted as “probability that this grasp will be successful for a subsequent throw.” They automatically get this label by checking if the grasped image landed in the target box. For the throw, we first get the analytical estimate \(\|\hat{v}_{x,y}\|\) from physics equations conditioned on a known target spot. Then, we get the actual landing spot from overhead cameras, which I assume are similar to the ones for detecting throwing success, and can deduce the true residual from that.
- Form2Fit: the data collection here is a bit subtle, and covered in depth in my prior blog post. It’s clever and involves reversing the task, i.e., disassembly. It is easier to disassemble than assemble, and by doing this, the robot gets data points for training the picking and placing modules, and then training the dense object net to get the match module. Once again for a grasp point or suction point, we take a single pixel (actually, a radius around it) and then backpropagate through it.
Now that we have the FCNs, what actions should the robot take at each time step? This is generally straightforward once the FCNs have done their heavy duty task in getting per-pixel image numbers:
-
Pick-and-Place: given all the possible action primitives along with all the rotations, pick the single pixel with the highest affordance value, and execute that action. This involves a maximum operation over every single image output from the FCN (including a factor of 16x for rotations), and then a second maximum over pixels in them. That’s the idea, but in practice they employed some heuristics. One is “suction first then grasp,” which led them to artificially scale the suctioning affordance values. Another one is that if the robot repeatedly tries an action but does not affect the scene — a problem I’ve experienced in several research projects — then they decrease the affordances of the relevant pixels. It’s these little things that, though somewhat hacky, help maximize performance.
-
Grasping and Pushing Synergies: the action chosen is one that maximizes the Q-values. In other words, take the maximum over all the 32 possible images (16 for grasping, 16 for pushing) over all pixels within those images. That’s a lot to consider, but the computation is parallelized.
-
TossingBot: the pixel with the highest grasp probability (from the output of the grasping module) across all orientations is chosen for the grasp point. Then, the robot will toss using the corresponding predicted velocity, which is provided in the same pixel location and same orientation in the output image of the throwing module.
-
Form2Fit: the planner first samples a set of potential actions. It then uses the descriptors to see which pick-and-place pair has the lowest L2 distance in descriptor space, and chooses that action. This “minimize distance in descriptor space” is standard for many of the robotics and descriptors papers I read nowadays. It can be expensive to sample and evaluate so many actions, so it is necessary to tune the sampling frequency.
Overall, what do these papers suggest as the advantages of the FCN-based approach?
-
The technique is object-agnostic in that it does not make any assumptions about the kind of objects the robot might grasp.
-
FCNs are efficient for per-pixel calculations, and this is helpful when we want a label for every pixel in an input image. In addition, the resulting action is often a simple function of the FCN output, such as taking an “argmax” across the pixels, as mentioned earlier. Some other alternatives for data-driven robotic grasping, as covered in an earlier blog post, require sampling a set of image patches or running the Cross Entropy Method.
-
Their specific architectural choice of rotating the input image by 16, to represent 16 different rotations, means they do not need to consider rotation as part of the action, simplifying the primitive. In addition, by keeping the different rotations in one architecture, rather than splitting into 16 different networks or 16 different trunks, they can use weight sharing to improve generalization and training efficiency.
-
Since the output is of the same dimension of the input with per-pixel properties, one can debug and/or interpret the output by looking at a heat map to see which values are higher.
There is other work that uses FCNs for efficient grasping, such as one that came right out of our own AUTOLAB and was presented at ICRA 2019. That paper, interestingly, trained a Convolutional Neural Network and then converted it to a Fully Convolutional Neural Network, to avoid the manual labeling done in the Robotic Pick-and-Place paper.
If you are interested in learning how to accelerate training of affordance-based policies with FCNs, I refer you to an ICRA 2020 paper which argues for the benefits of visual pre-training based on passive data without robotic interaction. This means the subsequent fine-tuning on active data from interaction is significantly shorter.
Overall it seems like FCNs are a powerful ingredient in the machine learning and robotics toolbox, and can be combined with techniques such as reinforcement learning, dense object descriptors, self-supervision, and other techniques.
Here are the full citations of the papers I discussed:
-
Andy Zeng, Shuran Song, Kuan-Ting Yu, Elliott Donlon, Francois R. Hogan, Maria Bauza, Daolin Ma, Orion Taylor, Melody Liu, Eudald Romo, Nima Fazeli, Ferran Alet, Nikhil Chavan Dafle, Rachel Holladay, Isabella Morona, Prem Qu Nair, Druck Green, Ian Taylor, Weber Liu, Thomas Funkhouser, Alberto Rodriguez. Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching. ICRA 2018, IJRR 2019.
-
Andy Zeng, Shuran Song, Stefan Welker, Johnny Lee, Alberto Rodriguez, Thomas Funkhouser. Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning. IROS 2018.
-
Andy Zeng, Shuran Song, Johnny Lee, Alberto Rodriguez, Thomas Funkhouser. TossingBot: Learning to Throw Arbitrary Objects with Residual Physics. RSS 2019.
-
Kevin Zakka, Andy Zeng, Johnny Lee, Shuran Song. Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly. ICRA 2020.
Thank you for reading, and stay safe.
My Interview with PyImageSearch's Sayak Paul
I’m pleased to share that my interview with Sayak Paul, who works at PyImageSearch, is now available to read over at his Medium blog. Here’s how he introduces me:
A warm welcome to Daniel Seita for today’s interview. Daniel is a computer science Ph.D. student at the University of California, Berkeley. His research interests broadly lie in areas like Artificial Intelligence, Robotics, and Deep Learning. He is deeply passionate about explaining technical insights and one such favorite insight of mine from Daniel’s archive is Understanding Generative Adversarial Networks. You can check out all of his blog pieces from here. He writes on a wide range of topics and has written more than 300 such pieces.
I was approach by Paul with a cold email, and agreed to do the interview for a number of reasons:
- I am honored that my blog posts have provided him insights.
- I was impressed by the wide range of inspiring people who Paul previously interviewed.
- I wanted to indirectly provide more support to PyImageSearch because that website has been a tremendously helpful resource for my research over the last few years.
To expand on the last point, PyImageSearch is incredible, filled with tutorial
after tutorial in such plain-spoken, clear language. I typically use it as a
reference on using OpenCV to adjust or annotate images, but PyImageSearch is
also helpful for Deep Learning more broadly. For example, literally
yesterday, I was learning how to write code using TensorFlow 2.0 with the new
eager execution (I usually use PyTorch). As part of my learning process, I
read the PyImageSearch articles on keras versus tf.keras and how to
use the new tf.GradientTape feature. I have not had to pay anything to
read these awesome resources, though I would be willing to do so.
As I mentioned earlier, I hope you enjoy the interview. Inspired by the interview, I am working hard on blog posts here, to be released in the next few months. It’s Spring Break week now, and unlike last year when I was a teaching assistant for Berkeley’s Deep Learning class and needed to use Spring Break to catch up on research and other things, this time I’m mostly taking a breather from an intense research semester thus far.
As usual, thank you for reading, and please stay safe!
Thoughts After Using rlpyt For Several Months
Over the past few months, I have frequently used the open-source reinforcement learning library rlpyt, to the point where it’s now one of the primary code bases in my research repertoire. There is a BAIR Blog post which nicely describes the rationale for rlpyt, along with its features.
Before rlpyt, my primary reinforcement learning library was OpenAI’s baselines. My switch from baselines to rlpyt was motivated by several factors. The primary one is that baselines is no longer actively maintained. I argued in an earlier blog post that it was one of OpenAI’s best resources, but I respect OpenAI’s decision to prioritize other resources, and if anything, baselines may have helped spur the development of subsequent reinforcement learning libraries. In addition, I wanted to switch to a reinforcement learning library that supported more recent algorithms such as distributional Deep Q-Networks, coupled with perhaps higher quality code with better documentation.
Aside from baselines and rlpyt, I have some experience with stable-baselines, which is a strictly superior version of baselines, but I also wanted to switch from TensorFlow to PyTorch, hence why I did not gravitate to stable-baselines. I have very limited experience with the first major open-source DeepRL library, rllab, which also came out of Berkeley, though I never used it for research as I got on the bandwagon relatively late. I also used John Schulman’s modular_rl library when I was trying to figure out how to implement Trust Region Policy Optimization. More recently, I have explored rlkit for its Twin-Delayed DDPG implementation, along with SpinningUp to see cleaner code implementations.
I know there are a slew of other DeepRL libraries, such as Intel’s NervanaSystems coach which I would like to try due to its huge variety of algorithms. There are also reinforcement learning libraries for distributed systems, but I prefer to run code on one machine to avoid complicating things.
Hence, rlpyt it is!
Installation and Quick Usage
To install rlpyt, observe that the repository already provides conda environment configuration files, which will bundle up the most important packages for you. This is not a virtualenv, though it has the same functional effect in practice. I believe conda environments and virtualenvs are the two main ways to get an isolated bundle of python packages.
On the machines I use, I find it easiest to first install miniconda. This can
be done remotely by downloading via wget and running bash on it:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
// after installing ...
. ~/.bashrc // to get conda commands to work
// to ensure (base) is not loaded by default
conda config --set auto_activate_base false
. ~/.bashrc // to remove the (base) env
In the above, I set it so that conda does not automatically activate its “base” environment for myself. I like having a clean, non-environment setup by default on Ubuntu systems. In addition, during the bash command above, the Miniconda installer will ask this:
Do you wish the installer to initialize Miniconda3
by running conda init? [yes|no]
[no] >>> yes
I answer “yes” so that it gets initialized.
After the above, I clone the repository and then install with this command:
conda env create -f linux_cuda10.ymlThis will automatically make a new conda environment, specialized for Linux with CUDA 10 for the command above. Then, finally, don’t forget:
pip install -e .to make rlpyt a package you can import within your conda environment, and
to ensure that any chances you make in rlpyt will be propagated throughout
your environment without having to do another pip install.
For quick usage, I follow the rlpyt README and use the examples directory.
There are several scripts in there that can be run easily.
Possible Workflow
There are several possible workflows one can follow when using rlpyt. For
running experiments, you can use scripts that mirror those in the examples
directory. Alternatively, for perhaps more heavy-duty experiments, you can look
at what’s in rlpyt/experiments. This contains configuration, launch, and run
scripts, which provide utility methods for testing a wide variety of
hyperparameters. Since that requires me to dive through three scripts that are
nested deep into rlpyt’s code repository, I personally don’t follow that
workflow; instead I just take a script in the examples directory and build
upon it to handle more complex cases.
Here’s another thing I find useful. As I note later, rlpyt can use more CPU
resources than expected. Therefore, particularly with machines I share with
other researchers, I limit the number of CPUs that my scripts can “see.” I do
this with taskset. For example, suppose I am using a server with 32 CPUs. I
can run a script like this:
taskset -c 21-31 python experiments/subscribe_to_my_blog.pyand this will limit the script to using CPUs indexed from 21 to 31. On htop,
this will be CPUs numbered 22 through 32, as it’s one-indexed there.
With this in mind, here is my rough workflow for heavy-duty experiments:
-
Double check the machine to ensure that there are enough resources available. For example, if
nvidia-smishows that the GPU usage is near 100% for all GPUs, then I’m either not going to run code, or I will send a Slack message to my collaborators politely inquiring when the machine will free up. -
Enter a GNU screen via typing in
screen. -
Run
conda activate rlpytto activate the conda environment. -
Set
export CUDA_VISIBLE_DEVICES=xto limit the experiment to the desired GPU. -
Run the script with
tasksetas described earlier. -
Spend a few seconds afterwards checking that the script is running correctly.
There are variations to the above, such as using tmux instead of screen,
but hopefully this general workflow makes sense for most researchers.
For plotting I don’t use the built-in plotter from rlpyt (which is really from
another code base). I keep the progress.csv file and download it in a
stand-alone python script for plotting. I also don’t use TensorBoard. In fact,
I still have never used TensorBoard to this day. Yikes!
Understanding Steps, Iterations, and Parallelism
When using rlpyt, I think one of the most important things to understand is how
the parallelism works. Due to parallelism, interpreting the number of “steps”
an algorithm runs requires some care. In rlpyt, the code frequently refers to
an itr variable. One itr should be interpreted as “one data collection AND
optimization phase”, which is repeated for however many itrs we desire. After
some number of itrs have passed, rlpyt logs the data by reporting it to the
command line and saving the textual form in a debug.log file.
The data collection phase uses parallel environments. Often in the code, a “Sampler” class (which could be Serial-, CPU-, or GPU-based) will be defined like this:
sampler = Sampler(
EnvCls=AtariEnv,
TrajInfoCls=AtariTrajInfo, # Needed for Atari game scores!
env_kwargs=dict(game=game),
eval_env_kwargs=dict(game=game),
batch_T=T,
batch_B=B,
max_decorrelation_steps=0,
eval_n_envs=10,
eval_max_steps=int(1e6),
eval_max_trajectories=50,
)(The examples folder in the code base will show how the samplers are used.)
What’s important for our purposes is batch_T and batch_B. The batch_T
defines the number of steps taken in each parallel environment, while batch_B
is the number of parallel environments. Thus, in DeepMind’s DQN Nature paper,
they set batch_B=1 (i.e., it was serial) with batch_T=4 to get 4 steps of
new data, then train, then 4 new steps of data, etc. rlpyt will enforce a
similar “replay ratio” so that if we end up with more parallel environments,
such as batch_B=10, it performs more gradient updates in the optimization
phase. For example, a single itr could consist of the following scenarios:
batch_T, batch_B = 4, 1: get 4 new samples in the replay buffer, then 1 gradient update.batch_T, batch_B = 4, 10: get 40 new samples in the replay buffer, then 10 gradient updates.
The cumulative environment steps, which is CumSteps in the logger, is thus
batch_T * batch_B, multiplied by the number of itrs thus far.
In order to define how long the algorithm runs, one needs to specify the
n_steps argument to a runner, usually MinibatchRl or MinibatchEval
(depending on whether evaluation should be online or offline), as follows:
runner = MinibatchRl(
algo=algo,
agent=agent,
sampler=sampler,
n_steps=n_steps,
log_interval_steps=1e5,
affinity=affinity,
)Then, based on n_steps, the maximum number of itrs is determined from that.
Modulo some rounding issues, this is n_steps / (batch_T * batch_B).
In addition, we use log_interval_steps to represent the itr interval when we
log data.
Current Issues
I have been very happy with rlpyt. Nonetheless, as with any major open-source code produced by a single PhD student (named Adam), there are bound to be some little issues that pop up here and there. Throughout the last few months, I have posted five issue reports:
-
CPU Usage. This describes some of the nuances regarding how rlpyt uses CPU resources on a machine. I posted it because I was seeing some discrepancies between my intended CPU allocation versus the actual CPU allocation, as judged from
htop. From this issue report, I started prefacing all my python scripts withtaskset -c x-ywherexandyrepresent CPU indices. -
Using Atari Game Scores. I was wondering why the performance of my DQN benchmarks were substantially lower than those I saw in DeepMind’s papers, and the reason was due to reporting clipped scores (i.e., bounding values within $[-1,1]$) versus the game scores. From this issue report, I added in
AtariTrajInfoas the “trajectory information” class in my Atari-related scripts, because papers usually report the game score. Fortunately, this change has since been updated to the master branch. -
Repeat Action Probability in Atari. Another nuance with the Atari environments is that they are deterministic, in the sense that taking an action will lead to only one possible next state. As this paper argues, using sticky actions helps to introduce stochasticity into the Atari environments while requiring minimal outside changes. Unfortunately, rlpyt does not enable it by default because it was benchmarking against results that did not use sticky frames. For my own usage, I keep the sticky frames on with probability $p=0.25$ and I encourage others to do the same.
-
Epsilon Greedy for CPU Sampling (bug!). This one, which is an actual bug, has to do with the epsilon schedule for epsilon greedy agents, as used in DQN. With the CPU sampler (but not the Serial or GPU variants) the epsilon was not decayed appropriately. Fortunately, this has been fixed in the latest version of rlpyt.
-
Loading a Replay Buffer. I thought this would be a nice feature. What if we want to resume training for an off-policy reinforcement learning algorithm with a replay buffer? It’s not sufficient to save the policy and optimizer parameters, as in an on-policy algorithm such as Proximal Policy Optimization, because we need to reproduce the exact contents of the replay buffer at the point when we saved the training state.
Incidentally, notice how these issue reports are designed so that they are easy for others to reproduce. I have argued previously that we need sufficiently detailed issue reports for them to be useful.
There are other issue reports that I did not create, but which I have commented on, such as this one about saving snapshots, that I hope are helpful.
Fortunately, Adam has been very responsive and proactive, which increases the usability of this code base for research. If researchers from Berkeley all gravitate to rlpyt, then it provides additional benefits for using rlpyt, since we can assist each other.
The Future
I am happy with using rlpyt for research and development. Hopefully it will be among the last major reinforcement learning libraries I need to pick up for my research. There is always some setup cost to using a code base, but I feel like that threshold has passed for me and that I am at the “frontier” of rlpyt.
Finally, thank you Adam, for all your efforts. Let’s go forth and do some great research.
More On Dense Object Nets and Descriptors: Applications to Rope Manipulation and Kit Assembly
In a prior blog post, I reviewed two papers about dense object descriptors in the context of robotic manipulation. The first paper, at CoRL (Florence et al., 2018), introduced it for object manipulation and open-loop grasping policies. The second paper, to appear at RA-Letters and ICRA (Florence et al., 2020), used descriptors and correspondence for policy optimization. In this post, I will discuss how descriptors can be used for two different robotics applications: rope manipulation and kit assembly. We can additionally combine descriptors with other tools in robotics such as imitation learning and self-supervision, which these papers demonstrate.
Before reading this post, I highly recommend going through the 30-minute PyTorch tutorial associated with the CoRL 2018 paper. I did not know anything about descriptors before reading the CoRL 2018 paper last year, and I appreciate the efforts of the authors to help us quickly learn the relevant concepts.
As a quick refresher on terminology, I refer to dense object nets as the networks which have descriptors as their output. They are “dense” because they involve predicting something at every pixel of an image. Don’t worry, this is not done by iterating through each target pixel (my brain hurts just thinking about doing that) but by passing the full image through the net and getting all the labels on each pixel in parallel.
Learning Rope Manipulation Policies Using Dense Object Descriptors Trained on Synthetic Depth Data
There is a whole sub-field of robotics that deals with rope manipulation. This paper, which recently came out of our lab at UC Berkeley, applies dense object descriptors for rope manipulation. They show, among other things, that descriptors can be applied to highly deformable objects. Previously, (Florence et al., 2018) applied it on slightly deformable objects, such as hats and shoes.
Another interesting aspect of this paper is that the authors train dense object nets in simulation. This provides perfect information of rope, so given two images of the same rope in different configurations, it should be possible to provide exact correspondences among pixels of the ropes. The paper argues that because rope is highly deformable, it is not sufficient to just change the pose of the camera to learn object descriptors, as was done in the earlier CoRL 2018 paper which used multiple camera views. I believe the CoRL paper needed to get multiple camera views for their full 3D reconstruction of the objects under consideration.
Blender is the simulator used in the paper. I know Blender reasonably well as we have recently used it for fabric manipulation (Seita et al., 2019). The below image shows a visualization of the simulator used in the work (left two columns).

The third image shows a simulated depth image of the rope, where pixels are a height value from an overhead camera. The fourth image shows that we can define an ordering of points on the rope, where points close to the ball are closer to yellow, and the colors change as one “traverses” away from the rope. A couple of pointers:
- The simulator produces depth images, which may help in sim-to-real transfer since depth is naturally invariant to colors. We have been using depth for a lot of our papers, as we show in our 2018 BAIR Blog post. In addition to standard domain randomization techniques, the authors perform several tricks on the images of rope to make it look similar to the noisier depth images we encounter in practice.
- Regarding the color ordering on the rope, the goal in training a dense object net is to generate descriptors such that if we translate the descriptor values into pixels, we get a consistent color ordering among the same rope but in different configurations. All that matters is the relative ordering of colors. We don’t care if the descriptor network happens to “decide” that points closer to the ball are blue instead of yellow, so long as that “decision” is consistent among different images.
- There is a ball attached to one end of the rope, which is needed to enforce a notion of ordering among the pixels. Otherwise, there would be two possible orderings, which might fool a descriptor net. Indeed, the ablation studies show that this ball is perhaps the most important hyperparameter decision the authors made.
That was the simulator. We have to use it to get data to train the dense object network. The authors do this by sampling to get some rope state $\xi_1$. Then, they apply a random transformation to get $\xi_2$. This is essentially a robot’s action, defined as a pick and place transform. The pair is then used as a training data, where the goal is to train the dense object net to make corresponding points in $\xi_1$ and $\xi_2$ to be close to each other, while encouraging non-corresponding points to be further apart. The training loss is done in the same manner as in the CoRL 2018 paper so please read that paper for the exact loss function, which I also dissect in my prior post.
Here is a visualization of what descriptors learn:

The first and third images show synthetic depth images of the rope in different configurations, and the second and fourth show visualizations of the corresponding dense object net outputs. Again, don’t get too caught up by the exact colors; all that matters is that they are consistent across the two images, and indeed they are! The process of generating these color images usually involves normalization techniques such as scaling the pixel values to be within $[0,255]$. In this paper, the descriptor dimension is 3, which makes it easy to visualize images.
You will also see that intersections and occlusions can be tricky with descriptors, since it may be impossible to get truly exact correlations; they would be restricted to pixels appearing at the uppermost layer of the object(s). The paper measures the uncertainty of descriptor nets and reports that, as expected, uncertainty is highest at intersections and occlusions.
The learned descriptors above are interesting, but now how do we use them in practice for robot manipulation? We need some benefit from descriptors, otherwise why we would use them? The paper reports two sets of experiments:
-
One-Shot Visual Imitation. No, don’t get confused with my post of a similar title, that was meta-learning, and here there is no meta-learning. The terminology means the robot is provided only one demonstration of a task to complete, where the demonstration is a sequence of images of rope states. The goal is to sequentially take actions to reach each of the images, or “sub-goals” if you prefer, in order. This is the same problem setting as in (Nair et al., 2017) – just think of it as requiring a demonstration at test time.
The policy is a greedy action: it uses descriptors from the current and (sub)goal images. From these, they sample paired points on the rope. They then look at the descriptor values, and find which pairing of sampled points is furthest from each other, and take a pick-and-place action to correct that. Intuitively, doing this each time gets the rope closer to the goal state because the greedy action has handled the most “distant” set of points. Assuming that actions do not cause any other descriptor pairs to increase in distance (a huge assumption!!) then eventually the rope has to look the same as in the human demonstration images.
-
Descriptor Parameterized Knot Tying. This is more specific for knot-tying, and uses a two-action sequence tuned towards a specific knot type. Thus, for another kind of knot they’d have to redefine the trajectory (and assume we already know how to do it) but there is no free lunch. They fix the actions for one rope, but here’s the clever part: they record the action vectors, but then “translate” that into descriptor space by passing it through the dense object net. This is what they mean by “defining an action in terms of descriptors.” Then, for a new goal image, since we already have the descriptors, we can use the original descriptor and map it into the corresponding pixels for the new goal image. We get the complete action by doing this for the pick and the place components. Thus, the action is generalizable across images.
For both experiments, they use a YuMi robot. For the former, they try and get the YuMi to manipulate the rope so it reaches some target, which they can measure with Intersection over Union (IoU). For the latter, they perform 50 knot-trying trials and report 66% success rates, out-performing prior work, but the caveat of course is that the experimental setup is not the same. I encourage you to visit the project website to see some videos.
There are also a set of simulated experiments that show extensive ablations over various perturbations of parameters. (If anything, I think there’s too many ablations and not enough focus on the robot experiments, but that’s probably a minor comment given the overall high quality of the paper.) The summary of the results is that descriptor quality, as measured on a held-out test set of images, is insensitive to a variety of parameters, with the exception of including a ball on one end or not. That is perfectly acceptable and reasonable.
To conclude, the advantages of the approach presented in the paper are that it uses depth and simulation to avoid the need for running real robots as in (Nair et al., 2017), and that the descriptors provide correspondence, allowing us to define interpretable, geometric actions. By that, I mean we can take a pixel location of a grasp point on a robot, and use descriptors to map that point to other rope configurations.
Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly
This paper uses descriptors for a very different application: assembling kits together. The first author, Kevin Zakka, already has a nice blog post about the paper, so my post will try and dive more into the technical details.
Kit assembly is deliberately a broad topic, and applies to basically anything that involves packaging something. By using descriptors and machine learning, they can learn picking and placing actions which generalize to assembling other kits not seen in training. They argue that in assembly lines, kits may change every few weeks, motivating learning over hard-coded rules. I can see why Google might have wanted to do this because they might work with companies that have assembly lines.
My first reaction upon understanding the kit assembly task was: great, this is cool, and a problem that I wish I had thought about earlier, but how does one get data on assembling kits? That seems much harder to do in simulation or the real world compared to rope manipulation.
The authors cleverly get data by dis-assembly from complete kits, and then repeating the process in reverse to assemble complete kits, in a manner similar to time-reversal as self-supervision. Even if actions are not truly reversible, such as with a placing operation that displaces existing objects, it seems logical that this helps get more high-quality data since it is intuitively harder to assemble than to dis-assemble. Since the paper does not use simulators, the downside is that a human would have to first provide an assembled kit and then maybe manually assemble things should something go wrong in data collection. As long as this does not need to happen too frequently, then it is acceptable. They report that they need just 500 disassembly sequences, though this is per training kit (to be fair, there are not many training kits). That’s roughly on the order of how many data points I had to physically collect for our bed-making paper from ISRR 2019.
Here is an overview of the pipeline, caption included from the paper:
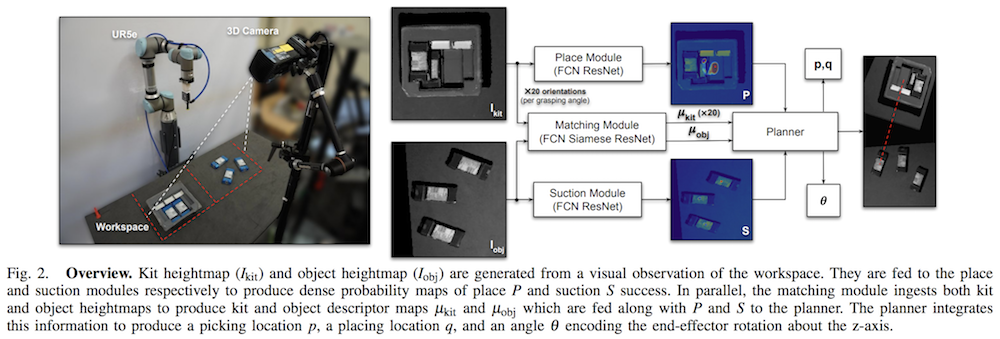
They use three fully convolutional neural networks in the pipeline. Recall that fully convolutional networks, which were introduced through a monumentally impactful paper from Trevor Darrell’s group a few years ago at Berkeley, are those that use only convolutional layers and efficiently perform dense per-pixel operations by mapping an image of size $(H\times W\times c_1)$ to another one of size $(H\times W\times c_2)$. Thus, all three networks produce per-pixel predictions of something with respect to the input image.
For kit assembly, the action space consists of a pick $p$, a place $q$, and an orientation for placement $\theta$. In addition, $p$ and $q$ are image pixels, which are then converted to a coordinate with respect to the robot’s base frame. The UR5 robot they use applies suctions, which reminds me of Jeff Mahler’s suctioning paper from ICRA 2018.
Interestingly, all three networks use depth images, like the rope manipulation paper above. However, the authors also use grayscale images and concatenate it with the depth images, producing “Grayscale-Depth” images (and not “RGB-Depth” images). I wonder why we don’t see more grayscale since that may reduce the need for heavy color-based domain randomization or additional training data?
The authors split the workspace into two images, one for showing the kit $I_{\rm kit}$ and the other for showing the objects $I_{\rm obj}$ which are initially scattered around and must be assembled in the kit.
Now let’s review the details of the three networks, which are called the suction, placing, and matching modules.
Suction module. For each pixel in $I_{\rm obj}$, this determines the success probability of grasping (i.e., suctioning) something.
- Getting labels is straightforward. The robot can measure the “airflow” of its suction gripper. For a given grasp point pixel $p$, if the airflow shows a success, then from the input image, we must encourage the suction network to assign pixel $p$ as a success. This is only one pixel out of many, so in practice the authors end up artificially increasing a radius about $p$ and labeling those a success. Notice that (a) sometimes we may get failures, so we’d do the same as earlier except assign a failure, and (b) other pixels backpropagate with zero loss. They do NOT assign other pixels as failures, because we don’t know if suctioning at other pixels far from $p$ could indeed lead to picking up something.
- The loss function uses the binary cross entropy loss, i.e., success or failure, for the pixels that were grasped, including those nearby as I mentioned earlier. Interestingly, the authors combine this with a “dice” loss. You can read the technical details in the paper but to summarize I believe it’s used to address class imbalance. For Form2Fit, I think because of the author’s setup, most of the suctions will be a success, and hence training is dominated by “pixel $p$ in a given image is a good pick point” rather than “pixel $p$ in a given image is a bad pick point.”
-
Finally, how does the data collection work from the time reversal? It’s pretty clever. First, when we disassemble, at each time we are given an image $I_{\rm kit}^{(t)}$ and apply suctioning on point $p^{(t)}$, where here I add the $t$ superscript to represent time. Notice that this is not the same as what happens during test time, where we must apply suctioning on images of objects, i.e., $I_{\rm obj}$ — but we can think of this as a clever form of data augmentation. Thus, the dis-assembly gives us a sequence of data which includes both picking from observations of the kit and placing where the objects will be during test time:
\[\{ (I_{\rm kit}^{(1)}, p^{(1)}), (I_{\rm obs}^{(1)}, q^{(1)}), (I_{\rm kit}^{(2)}, p^{(2)}), (I_{\rm obs}^{(2)}, q^{(2)}), \ldots \}\]Then, during the assembly process, we apply actions in reverse, this time looking at images $I_{\rm obj}^{(t)}$ at each time step, but with the placing action from earlier as the new suctioning action!
Place module. This network figures out a placing pixel into $I_{\rm kit}$, under the assumption that we are suctioning something from the suction network. A key design decision is that they discretize the angle into 20 groups, so there are 20 images passed through the placing network in parallel. Again, this is per-pixel, so for every pixel, there is a value that tells us the probability of placing success. Their deoderant kit example also shows how the placing module implicitly encodes ordering conditioned on the input image. The training process is similar to the suctioning network, with the exception that there isn’t a notion of getting a success signal via measuring something like suction airflow.
- The loss function also uses the cross entropy and a dice loss.
- For every pixel in $I_{\rm kit}$, we need to train the net so that it shows high success for successful places, and low success for failures. To get data, we once again use the time reversal sequence from above. Precisely, the labels are the suction location $p$ at time $t$ and the heightmap $I_{\rm kit}$ at $t+1$. Intuitively this is because if we do the sequence in reverse, we will have $I_{\rm kit}$ as the target with location $p$ as our placing point, i.e., $q$. These are the “success labels” since we assume that the suction step from the disassembly was a success, which seems reasonable since the authors can command the robot to grasp at “reasonable” coordinates on the kit.
Match module. This is the most interesting one to me because it uses descriptors. But first, why do we need this if we already have picking and placing? They argue:
While the suction and placing modules provide a list of candidate picking and placing locations, the system requires a third module to 1) associate each suction location on the object to a corresponding placing location in the kit and 2) infer the change in object orientation. This matching module serves as the core of our algorithm, which learns dense pixel-wise orientation-sensitive correspondences between the objects on the table and their placement locations in the kit.
This makes sense. What would happen if we did not have this network, and only relied on the placing network? It still has a set of 20 rotations as input, so I wonder what happens if we just take the highest probability among all pixels in all 20 images to satisfy (2)? I definitely agree, though, that we need a way to do (1) to get correspondence, because different objects should be placed at different locations.
We have $f: I \in \mathbb{R}^{H\times W\times 2} \to \mathbb{R}^{H\times W \times d}$. In this paper, the descriptor dimension is $d=64$. That is super large compared to the other paper on rope manipulation, and compared to the work from Russ Tedrake’s group. I’m surprised it is that high but I am sure the authors did extensive testing on the descriptor dimension, which they report in the supplementary material. It is a Siamese network with two fully convolutional residual streams, each sharing the same weights (since that’s what “Siamese network” means). The kit image $I_{\rm kit}$ maps to 20 separate descriptors, each of which are 64-dimensional, and one of them is selected to inform the change in rotation via:
\[\theta = \frac{360}{20} \times \arg\min_j \| \mu_{\rm kit}^{ij} - \mu_{\rm obj}^i\|_2^2 \quad {\rm for} \;\; j \in \{1,2,\ldots, 20\},\; i \in \{1,2,\ldots, H\times W\}\]The superscript of $j$ means we take one of the 20 descriptor images, so both descriptor images above, $\mu_{\rm kit}^j$ and $\mu_{\rm obj}$, are of dimension $(H\times W\times d)$. Then, we add the superscript of $i$ to represent a single pixel within those images, one of $H\times W$ candidate pixels. This way, we consider the best pixel match among all possible kit-object descriptor images. Finally, the $360/20$ fraction scales the index $j$ appropriately.
Now, how can we train the matching network to encourage similarity in both correspondence between picking and placing, and also the rotation? The loss function itself is the same as the one used in the CoRL 2018 paper, meaning that we need to sample matches and non-matches at the pixel level. The matches are taken from image pairs $(I_{\rm kit}, I_{\rm obj})$ where the kit image must be of the correct rotation (out of 20). Non-matches can be sampled from any of the 20 kit images. Within any pair of images, the pixel correspondences are labeled via object masks, which assumes that the rotation angle $\theta$ can provide us with the label of every pixel in the kit cavity and the corresponding pixel on the object, which is pulled outside the kit through data collection. This should work, particularly because the authors fix the kit to the surface; if that weren’t the case it might be harder to label correspondences.
Once the three networks are trained, the policy comes from the planner. It samples potential actions and then uses descriptors to see which pick-and-place pair (in descriptor space) have the lowest L2 distance, and that’s the action. Like with the rope manipulation paper, the policy is generally simple to describe and involves minimizing some distance in descriptors.
They conduct experiments using a physical UR5 robot, and evaluate by calculating the percentage of times when objects are placed into their target locations. I wonder if this involves some subjective interpretations, because I can imagine (and I see from the videos) that some objects might be almost but not quite inserted. As long as they are consistent with their interpretation, it is probably fine. The experiments show a number of promising results and effectiveness in assembling kits, with generalization to initial conditions of kits, and even to new kits entirely. They wrap up the results with a t-SNE visualization. Overall, I was really impressed with these results. Once again I encourage you to go to the project website for videos for a better understanding.
Conclusion
Hopefully this gives a readable overview of two different applications of dense object descriptors, showcasing the versatility of the technique. To be concrete, here are the papers I covered in this and my prior post, along with the original ICRA 2017 paper:
-
Tanner Schmidt, Richard Newcombe, Dieter Fox. Self-Supervised Visual Descriptor Learning for Dense Correspondence. ICRA 2017.
-
Peter Florence, Lucas Manuelli, Russ Tedrake. Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation. CoRL 2018.
-
Peter Florence, Lucas Manuelli, Russ Tedrake. Self-Supervised Correspondence in Visuomotor Policy Learning. RA-Letters and ICRA 2020.
-
Priya Sundaresan, Jennifer Grannen, Brijen Thananjeyan, Ashwin Balakrishna, Michael Laskey, Kevin Stone, Joseph E. Gonzalez, Ken Goldberg. Learning Rope Manipulation Policies Using Dense Object Descriptors Trained on Synthetic Depth Data. ICRA 2020.
-
Kevin Zakka, Andy Zeng, Johnny Lee, Shuran Song. Form2Fit: Learning Shape Priors for Generalizable Assembly. ICRA 2020.
Just like combining imitation learning and reinforcement learning or using simulators effectively with self-supervision, I think descriptors for correspondence belong in the toolkit we should use to develop general-purpose robots.
My PhD Qualifying Exam (Transcript)
To start off my 2020 blogging, here is the much-delayed transcript of my PhD qualifying exam. The qualifying exam is a Berkeley-wide requirement for PhD students, and varies according to the department. You can find EECS-specific details of the exam here, but to summarize, the qualifying exam (or “quals” for short) consists of a 50-60 minute talk to four faculty members who serve on a “quals committee.” They must approve of a student’s quals talk to enable the student to progress to “candidacy.” That’s the point when, contingent on completion of academic requirements, the student can graduate with approval from the PhD advisor. The quals is the second major oral exam milestone in the Berkeley EECS PhD program, the first of which is the prelims. You can find the transcript of my prelims here.
The professors on my qualifying exam committee were John Canny, Ken Goldberg, Sergey Levine, and Masayoshi Tomizuka.
I wrote this transcript right after I took this exam in April of 2018. Nonetheless, I cannot, of course, guarantee the exact accuracy of the words uttered.
Scheduling and Preparation
During a meeting with Professor Canny in late 2017, when we were discussing my research progress the past semester, I brought up the topic of the qualifying exam. Professor Canny quickly said: “this needs to happen soon.” I resolved to him that it would happen by the end of the spring 2018 semester.
Then, I talked with Professor Goldberg. While seated by our surgical robot, and soon after our ICRA 2018 paper was accepted, I brought up the topic of the quals, and inquired if he would be on my committee. “It would be weird if I wasn’t on the committee” he smiled, giving approval.1 “Will it be on this stuff?” he asked, as he pointed at the surgical robot. I said no, since I was hoping for my talk to be a bit broader than that, but as it turned out, I would spend about 30 percent of my talk on surgical robotics.
Next, I needed to find two more professors to serve on the quals committee. I decided to ask Professor Sergey Levine if he would serve as a member of the committee.
Since Berkeley faculty can be overwhelmed with email, I was advised from other students to meet professors in office hours to ask about quals. I gambled and emailed Professor Levine instead. I introduced myself with a few sentences, and described the sketch of my quals talk to him, and then politely asked if he would serve on the committee.
I got an extremely quick response from Professor Levine, who said he already knew who I was, and that he would be happy to be on the committee. He additionally said it was the “least he could do” because I am the main curator for the BAIR blog, and he was the one who originally wanted the BAIR Blog up and running.
A ha! There’s a lesson here: if you want external faculty to serve on a committee, make sure you help curate a blog they like.
Now came the really hard part: the fourth committee member. To make matters worse, there is (in my opinion) an unnecessary rule that states that one has to have a committee member outside of EECS. At the time of my exam, I barely knew any non-EECS professors with the expertise to comment on my research area.
I scrolled through a list of faculty, and decided to try asking Professor Masayoshi Tomizuka from the Mechanical Engineering department. In part, I chose him because I wanted to emphasize that I was moving in a robotics direction for my PhD thesis work. Before most of my current robotics research, I did a little theoretical machine learning research, which culminated in a UAI 2017 paper. It also helped that his lab is located next to Professor Goldberg’s lab, so I sometimes got a peek at what his students were doing.
I knew there was a zero percent chance that Professor Tomizuka would respond to a cold email, so I went hunting for his office hours.2 Unfortunately, the Mechanical Engineering website had outdated office hours from an earlier semester. In addition, his office door also had outdated office hours.
After several failed attempts at reaching him, I emailed one of his students, who provided me a list of times. I showed up at the first listed time, and saw his office door closed for the duration of the office hours.
This would be more difficult than I thought.
Several days later, I finally managed to see Professor Tomizuka while he was walking to his office with a cup of coffee. He politely allowed me to enter his office, which was overflowing with books and stacks of papers. I don’t know how it’s possible to sift through all of that material. In contrast, when I was at Professor Levine’s office, I saw almost nothing but empty shelves.
Professor Tomizuka, at the time, was a professor at Berkeley for 44 years (!!!) and was still supervising a long list of PhD students. I explained to him about my qualifying exam plan. He asked a few questions, including “what questions do you want me to ask in your exam?” to which I responded that I was hoping he would ask about robot kinematics. Eventually, he agreed to serve on the committee and wrote my name on a post-it note for him to remember.
Success!
Well, not really — I had to schedule the exam, and that’s challenging with busy professors. After several failed attempts at throwing out times, I asked if the professors could provide a full list of their constraints. Surprisingly, both Professor Levine and Professor Tomizuka were able to state their constraints on each day of the week! I’m guessing they had that somewhere on file so that they could copy and paste it easily. From there, it was straightforward to do a few more emails to schedule the exam, which I formally booked about two months in advance.
Success!
All things considered, I think my quals exam scheduling was on the easier side compared to most students. The majority of PhD students probably also have difficulty finding their fourth (or even third) committee members. For example, I know one PhD student who had some extreme difficulty scheduling the quals talk. For further discussion and thoughts, see the end of this post.
I then needed to do my preparation for the exam. I wrote up a set of slides for a talk draft, and pitched them to Professor Canny. After some harsh criticism, I read more papers, did more brainstorming, and re-did my slides, to his approval. Professor Goldberg also generally approved of my slides. I emailed Professor Levine about the general plan, and he was fine with a “40-50 minute talk on prior research and what I want to do.” I emailed Professor Tomizuka but he didn’t respond to my emails, except to one of them a week before to confirm that he would show up to the talk.
I gave two full-length practice talks in lab meetings, one to Professor Goldberg’s lab, and then to Professor Canny’s lab. The first one was hideous, and the second was less hideous. In all, I went through twelve full-length talks talks to get the average below 50 minutes, which I was told is the general upper bound for which students should aim.
Then, at long last, Judgment Day came.
The Beginning
Qualifying exam date: Tuesday April 24, 2018 at 3:00pm.
Obviously, I showed up way in advance to inspect the room that I had booked for the quals. I checked that my laptop and adapters worked with the slide system set in the room. I tucked in my dress shirt, combed my hair, cleaned my glasses for the tenth time, and stared at a wall.
Eventually, two people showed up: the sign language interpreters. One was familiar to me, since she had done many of my interpreting services in the past. The other was brand new to me. This was somewhat undesirable. Given the technical nature of the topic, I explicitly asked Berkeley’s Disabled Students’ Program to book only interpreters that had worked with me in the past. I provided a list of names more than two weeks in advance of the exam, but it was hard for them to find a second person. It seems like, just as with my prelims, it is difficult to properly schedule sign language interpreting services.
Professor Levine was the first faculty member to show up in the qualifying exam room. He carried with him a folder of my academic materials, because I had designated him as the “chair” of the quals committee (which cannot be one’s advisor). He said hello to me, took a seat, and opened my folder. I was not brave enough to peek into the files about me, and spent the time mentally rehearsing my talk.
Professor Tomizuka was the next to show up. He did not bring any supplies with him. At nearly the same time, Professor Canny showed up, with some food and drink. The three professors quickly introduced each other and shook their hands. All the professors definitely know each other, but I am not sure how well. There might be a generational gap. Professor Levine (at the time) was in his second year as a Berkeley faculty member, while Professor Tomizuka was in his 44th year. They quickly got settled in their seats.
At about 3:03pm, Professor Levine broke the painfully awkward silence: “are we on Berkeley time?”3
Professor Canny [chuckling]: “I don’t think we run those for the qualifying exam …”
Professor Levine [smiling]: “well, if any one professor is on Berkeley time then all the others have to be…”
While I pondered how professors who had served on so many qualifying exam committees in the past had not agreed on a settled rule for “Berkeley-time,” Professor Goldberg marched into the room wearing his trademark suit and tie. (He was the only one wearing a tie.)
“Hey everyone!” he smiled. Now we could start.
Professor Levine: “Well, as the chair of the committee, let’s get started. We’re going to need to talk among ourselves for a bit, so we’ll ask Daniel to step out of the room for a bit while we discuss.”
Gulp. I was already getting paranoid.
The sign language interpreters asked whether they should go out.
Professor Goldberg agreed: “Yeah, you two should probably leave as well.”
As I walked out the room, Professor Goldberg tried to mitigate my concerns. “Don’t worry, this is standard procedure. Be ready in five minutes.”
I was certainly feeling worried. I stood outside, wondering what the professors were plotting. Were they discussing how they would devour me during the talk? Would one of them lead the charge, or would they each take turns doing so?
I stared at a wall while the two sign language interpreters struck up a conversation, and commented in awe about how “Professor Goldberg looks like the typical energetic Berkeley professor.” I wasn’t interested in their conversation and politely declined to join since, well, I had the qualifying exam now!!
Finally, after what seemed like ten minutes — it definitely was not five — Professor Goldberg opened the door and welcomed us back in.
It was time.
During The Talk
“May I start?” I asked.
The professors nodded and stared at me. Professor Goldberg was smiling, and sat the closest to me, with notebook and pen in hand.
My talk was structured as follows:
- Part I: introduction and thesis proposal
- Part II: my prior work
- Part III: review of relevant robot learning research
- Part IV: potential future projects
I gave a quick overview of the above outline in a slide, trying to speak clearly. Knowing the serious nature of the talk, I had cut down on my normal humor during my talk preparation. The qualifying exam talk was not the time to gamble on humor, especially since I was not sure how Professor Tomizuka or Professor Levine would react to my jokes.
Things were going smoothly, until I came to my slide about “robot-to-robot teaching.” I was talking in the context of how to “transfer” one robot policy to another robot, a topic that I had previously brainstormed about with both Professor Goldberg and Professor Canny.
Professor Goldberg asked the first question during the talk. “When you say robot-to-robot teaching, why can’t we just copy a program from one robot to another?” he asked.
Fortunately this was a question I had explicitly prepared myself for during my practice talks.4
“Because that’s not teaching, that’s copying a program from one to another, and I’m interested in knowing what happens when we teach. If you think of how humans teach, we can’t just copy our brains and embed them into a student, nor do we write an explicit program of how we think (that would be impossible) and tell the student to follow it. We have to convey the knowledge in a different manner somehow, indirectly.”
Professor Goldberg seemed to be satisfied, so I moved on. Whew, crisis averted.
I moved on, and discussed our surgical robotics work from the ICRA 2018 paper. After rehashing some prior work in calibrating surgical robots, and just as I was about to discuss the details on our procedure, Professor Tomizuka raised his hand. “Wait can you explain why you have cheaper sensors than the prior work?”
I returned to the previous slide. “Prior work used these sophisticated sensors on the gripper which allows for better estimates of position and orientation” I said, pointing at an image which I was now thankful to have included. I provided him with more details on the differences between prior work and our work.
Professor Tomizuka seemed about half-satisfied, but motioned for me to continue with the talk.
I went through the rest of my talk, feeling at ease and making heavy eye contact with the professors, who were equally attentive.
No further interruptions happened.
When I finished the talk, which was right about 50 minutes, I had my customary concluding slide of pictures of my collaborators. “I thank all my collaborators,” I said. I then specifically pointed to the two on the lower right: pictures of Professor Canny and Professor Goldberg. “Especially the two to the lower right, thank you for being very patient with me.” In retrospect, I wish I had made my pictures of them bigger.
“And that’s it,” I said.
The professors nodded. Professor Goldberg seemed like he was trying to applaud, then stopped mid-action. No one else moved.
Immediately After The Talk
Professor Levine said it was time for additional questions. He started by asking: “I see you’ve talked about two kinds of interactive learning, one with an adversary, one with a teacher. I can see those going two different directions, do you plan to try and do both and then converge later?”
I was a little confused by this question, which seemed open-ended. I responded: “yes there are indeed two ways of thinking of interactive teaching, and I hope to pursue both.” Thinking again at my efforts at implementing code, I said “from my experience, say with Generative Adversarial Networks as an example, it can be somewhat tricky to get adversarial learning to work well, so perhaps to start I will focus on a cooperative teacher, but I do hope to try out both lines of thinking.”
I asked if Professor Levine was satisfied, since I was worried I didn’t answer well enough, and I assumed he was going to ask something more technical. In addition, GANs are fairly easy to implement, particularly with so many open-source implementations nowadays for reference. Surprisingly, Professor Levine nodded in approval. “Any other questions?”
Professor Goldberg had one. “Can you go back to one of the slides you said about student’s performance? The one that said if the student’s performance is conveyed with $P_1$ [which may represent trajectories in an environment] and from that the teacher can determine the student’s weakest skill so that the next set of data $P_2$ from the student shows improvement …””
I flipped back briefly to the appropriate slide. “This one?”
Professor Goldberg: “yes, that one. This sounds interesting, but you can think of a problem where you teach an agent to improve upon a skill, but then that results in a deterioration of another skill. Have you thought about that?”
“Yes, I have,” I said. “There’s actually an interesting parallel in the automated curriculum papers I’ve talked about, where you sample goals further and further away so you can learn how to go from point $A$ to point $B$. The agent may end up forgetting how to go from point $A$ to a point that was sampled earlier in the sequence, so you need to keep a buffer of past goals at lower difficulty levels so that you can continually retrain on those.”
Professor Goldberg: “sounds interesting, do you plan to do that?”
“I think so, of course this will be problem dependent,” I responded, “so I think more generally we just need a way to detect and diagnose these, by repeatedly evaluating the student on those other skills that were taught earlier, and perhaps do something in response. Again problem dependent but the idea of checking other skills definitely applies to these situations.”
Professor Levine asked if anyone had more questions. “John do you have a question?”
“No,” he responded, as he finished up his lunch. I was getting moderately worried.
“OK, well then …” Professor Levine said, “we’d now like Daniel to step outside the room for a second while we discuss among ourselves.”
I walked outside, and both of the interpreters followed me outside. I had two interpreters booked for the talk, but one of them (the guy who was new to me) did not need to do any interpreting at all. Overall, the professors asked substantially fewer questions than I had expected.
The Result
After what seemed like another 10 minutes of me staring at the same wall I looked at before the talk, the door opened. The professors were smiling.
Professor Levine: “congratulations, you pass!”
All four approached me and shook my hand. Professor Canny and Professor Tomizuka immediately left the room, as I could tell they had other things they wanted to do. I quickly blurted out a “thank you” to Professor Canny for his patience, and to Professor Tomizuka for simply showing up.
Professor Goldberg and Professor Levine stayed slightly longer.
While packing up, Professor Levine commended me. “You really hit upon a lot of the relevant literature in the talk. I think perhaps the only other area we’d recommend more of is the active learning literature.”
Professor Goldberg: “This sounds really interesting, and the three year time plan that you mention for your PhD sounds about right to get a lot done. In fact think of robot origami, John mentioned that. You’ve seen it, right? I show it in all the talks. You can do robot teaching on that.”
“Um, I don’t think I’ve seen it?” I asked.
Professor Goldberg quickly opened up his laptop and showed me a cool video of a surgical robot performing origami. “That’s your PhD dissertation” he pointed.
I nodded, smiling hard. The two professors, and the sign language interpreters, then left the room, and I was there by myself.
Later that day, Professor Levine sent a follow-up email, saying that my presentation reminded him of an older paper. He made some comments about causality, and wondered if there were opportunities to explore that in my research. He concluded by praising my talk and saying it was “rather thought-provoking.”
I was most concerned about what Professor Canny thought of the talk. He was almost in stone-cold silence throughout, and I knew his opinion would matter greatly in how I could construct a research agenda with him in the coming years. I nervously approached Professor Canny when I had my next one-on-one meeting with him, two days after the quals. Did he think the talk was passable?? Did he (gulp) dislike the talk and only passed me out of pity? When I asked him about the talk …
He shrugged nonchalantly. “Oh, I thought it was very good.” And he pointed out, among other things, that I had pleasantly reminded him of another colleague’s work, and that there were many things we could do together.
Wait, seriously?? He actually LIKED the talk?!?!?!?
I don’t know how that worked out. Somehow, it did.
Retrospective
I’m writing this post more than 1.5 years after I took the actual exam. Now that some time has passed here are some thoughts.
My main one pertains to why we need a non-EECS faculty member. If I have any suggestion for the EECS department, it would be to remove this requirement and to allow the fourth faculty to be in EECS. Or perhaps we can allow faculty who are “cross-listed” in EECS to count as outside members. The faculty expertise in EECS is so broad that it probably is not necessary to reach out to other departments if it does not make sense for a given talk. In addition, we also need to take an honest look as to how much expertise we can glean from someone in a 1.5-hour talk, and if it makes sense to ask for 1.5 hours of that professor’s time when that professor could be doing other, more productive things for his/her own research.
I am fortunate that scheduling was not too difficult for me, and I am thankful to Professor Tomizuka for sitting in my talk. My concern, however, is that some students may have difficulty finding that last qualifying exam member. For example, here’s one story I want to share.
I know an EECS PhD student who had three EECS faculty commit to serving on the quals committee, and needed to find a fourth non-EECS faculty. That student’s advisor suggested several names, but none of the faculty responded in the affirmative. After several months, that student searched for a list of faculty in a non-EECS department.
The student found one faculty who could be of interest, and who I knew served as an outside faculty member on one EECS quals before. After two weeks of effort (due to listed office hours that were inaccurate, just as I experienced), the student was able to confirm to get a fourth member. Unfortunately, this happened right when summer began, and the faculty on the student’s committee were traveling and never in the same place at the same time. Scheduling would have to be put off until the fall.
When summer ended and fall arrived, that student was hoping to schedule the qualifying exam, but was no longer able to contact the fourth non-EECS faculty. After several futile attempts, the student gave up and tried a second non-EECS faculty, and tentatively got confirmation. Unfortunately, once again, the student was not able to contact the faculty member again when it was time to schedule.
It took several more months before the student, with the advisor’s help, was able to find that last, elusive faculty member to serve on the committee.
In all, it took one year for that student to get a quals committee set up! That’s not counting the time that the student would then need to schedule it, which normally has to be done 1 or 2 months in advance.
Again, this is only one anecdote, and one story might not be enough to spur a change in policy, but it raises the question as to why we absolutely need an “outside” faculty member. That student’s research is in a very interesting and important area in EECS, but it’s also an area that isn’t a neat fit for any other department, and it’s understandable that faculty who are not in the student’s area would not want to spend 1.5 hours listening to a talk. There are many professors within EECS that could have served as the fourth faculty, so I would suggest we change the policy.
Moreover, while I don’t know if this is still the current policy, I read somewhere once that students can only file their dissertations at least two semesters after their qualifying exam. Thus, significant delays in getting the quals exam done could delay graduation. Again, I am not sure if this is still the official policy, so I will ask the relevant people in charge.
Let’s move on to some other thoughts. During my quals, the professors didn’t bring a lot of academic material with them, so I am guessing they probably expected me to pass. I did my usual over-preparation, but I don’t think that’s a bad thing. I was also pitching a research direction that (at the time) I had not done research in, but it looks like that is also acceptable for a quals, provided that the talk is of sufficient quality.
I was under a ridiculous amount of stress in the months of February, March, and April (until the quals itself), and I never want to have to go through months like those again. It was an incredible relief to get the quals out of the way.
Finally, let me end with some acknowledgments by thanking the professors again. Thank you very much to the professors who served on the committee. Thank you, Professors John Canny, Ken Goldberg, Sergey Levine, and Masayoshi Tomizuka, for taking the time to listen to my talk, and for your support. I only hope I can live up to your expectations.
-
At the time, I was not formally advised by him. Now, the co-advising is formalized. ↩
-
I felt really bad trying to contact Professor Tomizuka. I don’t understand why we have to ask professors we barely know to spend 1.5 hours of their valuable time on a qualifying exam talk. ↩
-
Classes at UC Berkeley operate on “Berkeley time,” meaning that they start 10 minutes after their official starting time. For example, a class that lists a starting time of 2:30pm starts at 2:40pm in practice. ↩
-
As part of my preparation for the qualifying exam, I had a list of about 50 questions that I felt the faculty would ask. ↩
Books Read in 2019
[Warning: Long Read]
There are 37 books listed here, which is similar to past years (34, 43, 35). Here is how I categorized these books:
- China (7 books)
- Popular Science (9 books)
- American History and Current Events (4 books)
- Self-Improvement (6 books)
- Dean Karnazes Books (3 books)
- Yuval Noah Harari Books (3 books)
- Miscellaneous (5 books)
For all of these I put the book’s publication date in parentheses after the title, since it’s important to know when a book was published to better understand the historical context.
This page will maintain links to all my reading list posts. In future years, I’ll try and cut down on the length of these summaries, since I know I am prone to excessive rambling. We’ll see if I am successful!
Books I especially liked have double asterisks by their name.
Group 1: China
For a variety of reasons, I resolved that in 2019, I would learn as much as I could about China’s history, economy, political structure, and current affairs. A basic knowledge of the country is a prerequisite for being able to adequately discuss China-related issues today. I successfully read several books, which I am happy about, though I wanted to read about double the number that I did. As usual, my weakness is being interested in so many subjects that it’s impossible for me to focus on just one.
-
** China in Ten Words ** (2011) is a memoir by Yu Hua, one of China’s most famous novelists. To give some context, when I discuss my book reading list with my Chinese friends, the vast majority of them know about Yu Hua. The book was translated by Pomona College professor Allan H. Barr. I found out about this book from a Forbes article on “10 Books to Understand Modern China” – and I’m glad I read it! Yu Hua was born in Zhejiang Province in 1960 and thus experienced the Cultural Revolution (1966-1976), followed by China’s massive economic growth once they moved away from centralized economic planning. Yu features the following ten words: people, leader, reading, writing, Lu Xun, revolution, disparity, grassroots, copycat, and bamboozle. Each has a chapter devoted to it. For example, the “leader” chapter is obviously about Mao Zedong, and I could anticipate what “copycat” was about because Kai-Fu Lee in AI Superpowers (a book I read just before starting this one) explicitly mentions that Chinese companies have a “copycat mentality.” But who is Lu Xun? Yu says in the chapter on “reading” that the Cultural Revolution was an era without literature, but books by Lu Xun were allowed because (surprise, surprise) Mao Zedong was a huge fan. Another word I liked was “bamboozle,” or trickery and fraud. These and related stories are brilliantly educational since I only have indirect knowledge of China via Western observers and international students from China. While Yu doesn’t go out of his way to criticize the Chinese government, there are a fair amount of critiques or anecdotes that imply healthy disagreement, so I wondered if Yu was able to get the book published in China – but a brief online search here and here showed that this did not happen. It’s unsurprising; Yu discusses the Tiananmen Square protests in the very first chapter of the book and explicitly says: “[…] it is a disturbing fact that among the younger generation in China today few know anything about the Tiananmen incident […]”. There’s no way the government would approve. Thus, Yu, who lives in Beijing, got his memoir published in Taiwan. Surprisingly, I can’t remember anything about Taiwan in this book; perhaps Yu wanted to focus on themes less clear to non-Chinese? Overall, I give the book firm praise and I thank Yu for giving me a perspective on what living in China is (and was) like.
-
On China (2011) is by the legendary former United States Secretary of State Henry Kissinger, who as National Security Advisor, made a secret visit to China in 1971 to help lay the groundwork for Richard Nixon’s historic 1972 visit to China. While I recognize that Kissinger is a controversial figure, I have no objections with Nixon’s China trip. Indeed, since it helped lead to normalizing relations with China, it may have been one of the best parts of Nixon’s presidency, which is often viewed negatively in the US due to Watergate. Kissinger’s On China is a massive 600-page book that shows the insane breadth and depth of Kissinger’s knowledge about China. The first few chapters are mostly generic history, though from the lens of security and warfare. To double check the historical accuracy, I cross-referenced this portion with other books I read this year. On China gets more interesting in the middle part of the book, where Kissinger describes meeting high-ranking Chinese officials. The book includes transcripts from Kissinger’s conversations with Mao Zedong, Zhou Enlai, and Deng Xiaoping. While the transcripts are sometimes confusing to interpret and filled with prolix comments, I enjoyed seeing what those men actually talked about decades ago. It was also interesting, from an American perspective, to see the discussion internal to US officials, who in the 1970s generally agreed that if the Soviet Union attacked China, the US would attempt to take the Chinese side. The issue of “triangular diplomacy” among the US, Soviet Union, and China is also highly relevant in On China. Later in the book, the discussion often revolves around how much the US should attempt to spread human rights, and how much room for cooperation exists between the US and China. For example, President George H.W. Bush needed to proceed with caution with the US response to the Tiananmen Square killings, since Bush understood that condemning China would seem like it was interfering with their affairs, which is a constant sore spot from the Chinese perspective. (If any Chinese are reading this, be aware that in America we frequently have passionate internal debates among whether we should intervene or not in foreign countries.) From reading this book, I am amazed at the Chinese endurance, unity, and resistance in the face of foreign pressures, and I agree with Kissinger’s conclusion that, going forward, mutually beneficial and peaceful cooperation among the US and China is a must. On China is not a page-turner, and sometimes feels like it rambles on, since Kissinger — while obviously a great writer — is not on the same level as, say, Steven Pinker or Yuval Noah Harari. That’s totally fair; his expertise is with foreign policy. It is incredible that Kissinger can write a book this grand at the age of 88. He is still alive with a sharp mind at 96 today, and who just a month ago met with Xi Jinping.
-
CEO China: The Rise of Xi Jinping (2016) by Kerry Brown of the United Kingdom is perhaps the preeminent biography available of Xi Jinping. I read CEO China because Xi Jinping is one of the two most important people in the world, with the other one being the President of the United States. CEO China was additionally recommended by Wasserstrom and Cunningham’s book China in the 21st Century: What Everyone Needs to Know, and for once I decided to follow up a book by exploring its “recommended reading” postscript. Kerry Brown is Professor of Chinese Studies and Director of the Lau China Institute at King’s College, London. Like most books I read about China (except for Yu Hua’s book), it is from the perspective of a Westerner who studies China, though interestingly enough, Brown has personally met Xi once. In addition to Xi, CEO China analyzes the Chinese Communist Party (CCP) and what “power” really means in modern China. Xi was born in 1953, and from the book we learn about Xi’s upbringing during the Great Leap Forward1 and the Cultural Revolution, about Xi’s early career in government before he became a serious candidate for being the next Chinese leader2 starting in the mid-2000s, and about Xi’s closest friends and family members. As the title suggests, the “CEO” part is because Xi has heavily focused on economics and material goods as part of his and the CCP’s legitimacy to power. What I found more interesting and novel is that Brown often compares Xi to the Pope, and the CCP to the Catholic Church. The book concludes with a discussion of what Xi wants: Brown describes a hypothetical “China in 2035” scenario with stability and prosperity. There are, of course, many things that can go wrong, and power is intoxicating. For the sake of worldwide stability and peace, I hope that Xi will recognize when his power has overstepped too much and step aside. Brown has another book, The World According to Xi, published in 2018, and presumably that is a follow-up to this one, and might discuss Xi’s lifting of term limits and retirement plans (Kerry Brown is mentioned in this late 2017 NYTimes article), the surveillance of Uighur Muslims in Xinjiang, and other similar topics that have garnered recent Western media coverage.
-
** China’s Economy: What Everyone Needs to Know ** (2016) is by Arthur R. Kroeber, a Westerner who has lived in Beijing since 2002. Describing China as “formally centralized, but in practice highly decentralized,” Kroeber drives us through a fascinating whirlwind of the world’s most populous country, discussing the Chinese Communist Party, Chinese leaders, Chinese growth relative to other Asian economies (Taiwan, South Korea, and Japan), State Owned Enterprises, the Cultural Revolution, how the political system works, how business and finance work, Chinese energy consumption, Chinese meat consumption (which, thankfully, is leveling out) demographics, the shift from rural to urban, and so forth. There’s a lot to process, and I think Kroeber admirably provides a balanced overview. Some of the economic discussion comes from Joe Studwell’s book on How Asia Works, which I read last year. The book is mostly objective and data-driven, and Kroeber only occasionally injects his opinions. American nativists would disagree with some of Kroeber’s opinions. For example, Americans often criticize China for excessive government protection of Chinese businesses, but Kroeber counters that every country has incentives to protect their businesses. Conversely, the Chinese government might not fully agree with Kroeber’s criticism of the one-child policy (but maybe not, given that the policy is no longer active), or Kroeber’s claim that it would be difficult for technological innovation and leadership to come from a country whose government does not permit free speech and heavily censors Internet usage. The book’s appendix raises the intriguing question of whether the government manipulates economic statistics. Kroeber debunks this, and one reason is the obvious: no one who has lived or visited China’s cities can deny rapid growth and improvement. Finally, Kroeber ponders about the future of China, and in particular US-China relations. He urges us (i.e., mostly Western readers) not to view China’s rise as foreboding a repeat of Nazi Germany or Communist Soviet Union, and thinks that an “accommodation can be reached under which China enjoys increased prestige and influence […], but where the US-led system remains the core of the world’s political and economic arrangements.” That is definitely better than a different scenario where war occurs between US and China.
-
** China in the 21st Century: What Everyone Needs to Know ** (editions in 2010, 2013, and 2018 — I read the 2018 one) is by UC Irvine professor Jeffrey M. Wasserstrom and historian Maura Elizabeth Cunningham. It is an excellent pairing to Arthur Kroeber’s book (see above) since it has a much broader focus than “just” China’s economy. Wasserstrom and Cunningham review historical information relevant to understanding current events (e.g., Confucius, Imperial China, World War II-related events, and so on), in many cases arguing or clarifying common misunderstandings by Westerners. In fact, there’s a full chapter dedicated to “US-China Misunderstandings.” Part of it was because they wanted to avoid us thinking along the lines of “we are good, China is Communist so therefore they are bad!!” Before reading this book, I perhaps assumed there was more intense nationalism among Chinese citizens, and that there was greater uniformity in political and cultural thought than I expected. I can see why the situation is somewhat more nuanced. There is a wide range of Chinese opinions about Mao Zedong, just like we have a variety of opinions about our own leaders. In addition, many critical thinkers operate in a “gray zone” where they can dissent just enough from the government, but not so much that they become permanently jailed. An example is the unpredictable artist Ai Weiwei who “seems to delight in provoking the Chinese government.” Another one they mention is Yu Hua (see above), an author who publishes more controversial work outside of China, which has let him live in Beijing relatively unscathed. The same cannot be said, unfortunately, for Nobel Peace Prize winner Liu Xiaobo, who tragically died in state custody. Another misunderstanding I found interesting was the one that Chinese have of Americans, and here the authors argue that it’s the way the American media is structured. In America, our media is predisposed to write about bad news, which might be the opposite case in China, in which government-run newspapers want to emphasize the positive about China. In addition, even within American newspapers, there are a wide variety of opinions on a single issue, which is less common in China. In addition to the chapter on misunderstandings, I also enjoyed learning more about the status of Hong Kong and Taiwan. I was reading this book at the same time the Hong Kong anti-extradition bill protests were happening. With regards to Taiwan, the authors state that the relationship between China and Taiwan has settled into an “agree to disagree” stalemate, and despite the Chinese rhetoric to the contrary, they predict that China and Taiwan won’t be going to war anytime soon. (I hope that’s the case!) The authors conclude with a discussion of whether Americans should refrain from all criticism of China. Their answer is no, but they hope that their book helps to explain why the Chinese government (and citizens) think about certain issues. They also wish they could recommend Chinese people to read a “What Everyone Should Know about America” book — but I wonder if such a book exists?
-
** Environmental Pollution in China: What Everyone Needs to Know ** (2018) is the third “What Everyone Needs to Know” book variant about China that I’ve read, by Daniel K. Gardner, Professor of History at Smith College. This one narrows the scope to China’s environment, which is inevitably tied to its economy and government. It is, as Gardner frequently preaches, of importance to us because China’s environment affects the world in many ways. China’s pollutants go into the atmosphere and spread to other countries. China’s purchasing power also means that if it is low on food or other resources, it may buy from other countries and push prices up, potentially adding to instability for those countries with fragile governments. Much of the discussion is about air, which makes sense due to its direct visibility (remember the “airpocalypse”?), but equally important to consider are soil and water quality, both of which look distressing due to chemicals and other heavy metals, and of course climate change. Understanding and improving China’s environment has potential to benefit China and others, and Gardner does a nice job educating us on the important issues and the relevant — but sometimes searing — statistics. I left the book impressed with how much content was packed in there, and I am thinking of ways for cooperation between the United States and China. In particular, I was encouraged by how there is an environmental movement gaining momentum in China,3 and I am also encouraged by their expanding nuclear power program, since that uses less carbon than coal, oil, or natural gas. Unfortunately, and rather surprisingly for a book published in 2018, I don’t think there’s any mention of Donald Trump, who isn’t exactly a fan of China or climate-related issues. I mean, for God’s sake, he tweeted the preposterous claim that global warming was a hoax invented by the Chinese. I can only hope that post-Trump, saner heads will soon work with China to improve its environment.
-
** AI Superpowers: China, Silicon Valley, and the New World Order (2019) ** by Kai-Fu Lee is a brilliant read, a book about Artificial Intelligence that’s more grounded in reality than a book like Life 3.0. Kai-Fu Lee was born in Taiwan, moved to the United States at a young age, and got his PhD in AI from Carnegie Mellon University (CMU) under Turing Award winner Raj Reddy at roughly the same time Ken Goldberg was at CMU. After leading Google China and co-creating Microsoft Research Asia, Lee is now a venture capitalist. As expected, AI Superpowers covers the Deep Learning revolution and its real-world impact. Lee correctly observes that many of the latest AI advances are mere refinements over Deep Learning, and more a matter of engineering and implementation rather than true breakthroughs. The United States has the lead in elite AI talent, but China has more engineers who can implement AI algorithms, which may give them the edge in certain AI domains. Lee predicts that in perception and autonomous AI, the balance of power will shift slightly in China’s favor in the next 5-10 years, but that both the United States and China will be far ahead of other countries with respect to AI. In addition, China’s lax data privacy laws compared to the United States and Europe means it can more easily obtain larger datasets to train Deep Neural Networks. Finally, Lee provides a blueprint for AI and human coexistence in a world where AI eliminates a large number of jobs. Lee views Silicon Valley’s go-to solution, a Universal Basic Income, as a painkiller at best; his blueprint would be to augment it with market forces that encourage and reward “human touch”. When reading this, I was reminded of Thomas L. Friedman’s “STEMpathy” claims. Lee’s ideas are inspired in part by his cancer diagnosis at the age of 53, which made him realize he was spending too much time working. Lee’s story is touching, and I agree with Lee’s critique of himself. But, Lee had tremendous career success. What if I and many others want that kind of experience and lifestyle? Why should we not work excessively hard, then? Even with some of my skepticism, I think Lee’s ideas have slightly more merit than a vanilla Universal Basic Income, but we’ll see how the details work out if, or when, it beckons. I will refer back to AI Superpowers frequently in the near future to see how some of his short-term predictions pan out.
Group 2: Popular Science
This includes books with a psychology bent, such as those from Steven Pinker.
-
** The Blank Slate: The Modern Denial of Human Nature ** (2002) by famous psychology Professor Steven Pinker, is a wonderful take on a topic which I had previously been unaware about: The Blank Slate, the idea that humans start off as a “blank slate” and can be “molded” to fit particular personality traits. Two other similar concepts are The Noble Savage, the idea that humans are by nature peaceful, and The Ghost in the Machine, that humans have souls distinct from the physical world we recognize today. The book is mostly about the first item, The Blank Slate, but occasionally Pinker reflects on the other two. What was new to me is that in the late 20th century, social scientists and psychologists had essentially agreed that The Blank Slate was correct. Part of this was due to the moral appeal. That people are blank slates inherently means they are equal and thus discrimination (e.g., by gender, race, or religion) is not only morally wrong, but also wrong in a scientific sense. Unfortunately, Pinker systematically debunks the claims of The Blank Slate so badly that if I were a Blank Slate supporter, I would be thoroughly embarrassed. He cites examples from Marxist regimes on how they subscribed to The Blank Slate … which then played a key role in their industrial-scale killing, making what the Nazis did seem almost moderate by comparison. (For example, The Blank Slate implies people can be manipulated and controlled with enough force.) Pinker also makes the strong case that our morals, such as being against discrimination, should be due to moral reasons and not hinged directly upon scientific advances, which indeed are showing strong evidence for innate human characteristics. Pinker delves into controversial areas, such as innate gender differences, though for his own sake, he probably avoided racial differences out of fear of further retaliation. Reading this book nearly two decades later in 2019, I don’t find the book’s claims controversial at all. It has always seemed obvious to me that there are inherent differences in human ability which affects human achievement, in addition to, of course, nurture. The last few years have provided more evidence for Pinker’s book. In fact, Pinker often cites Robert Plomin, a name I recognize due to reading his recent book Blueprint: How DNA Makes Us Who We Are this year. It is clear that DNA and inherent nature makes a lot of what humans are. Obviously, this is in addition to the importance of ensuring that we increase opportunity to a variety of people in our society.
-
** The Better Angels of Our Nature: Why Violence has Declined ** (2011) needs no introduction. The Bill Gates-endorsed, 700+ page magnus opus by Pinker, and which I managed to read in bits and pieces over the course of two busy months, describes how humans have grown steadily less and less violent over the course of our several million year history. This is in contrast to many commentators nowadays, who like to highlight every bit of violence happening in the modern world while longing for a more “romantic” or “peaceful” past. Pinker thoroughly and embarrassingly demolishes such arguments by providing compelling quantitative and qualitative evidence that violence was much, much more prevalent before the modern era. In years past, life expectancy was lower, a far greater percentage of people died due to homicide and war, and practices such as torture and unusual punishment were more common and accepted by society. This is just a fraction of what’s in the book. I recommend it to everyone I know. Since I read Pinker’s Enlightenment Now last year, which can be thought of as a successor to this book, I was already somewhat familiar with the themes here, but the book still managed to blow my mind about how much violence there was before my time. It also raises some interesting moral dilemmas, because while World War II did kill a lot of people, what might matter more is the number of deaths relative to the world or country population at that time, and by that metric there are many other incidents throughout history that merit our attention. Probably the only downside of Better Angels from a reader’s perspective is that the later parts of the book can be a bit dry since it presents some of the inner workings of the brain because Pinker wanted to discuss the science of why current circumstances might be more favorable to reducing violence. That is a tricky subject to describe to a non-technical audience. I view myself as technically-minded, though not in the sense that I know much about how the brain works internally,4 and even I found this section somewhat tough going. The overall lesson that I learned, though, is that I believe Pinker is right about humans and violence. He is also right that we must understand the causes of violence and how to encourage trends that have shown to reduce it. I remain optimistic.
-
Artificial Intelligence: What Everyone Needs to Know (2016) is by entrepreneur Jerry Kaplan, who got his PhD in computer science (focusing on NLP) from the University of Pennsylvania in 1979. It is in the “What Everyone Needs to Know” series. Kaplan presents the history and research frontiers of AI, and then wades into AI philosophy, AI and the law, the effect of AI on jobs and society, and the risks of superintelligence. I knew most of the book’s material due to my technical background in AI and my reading of popular science books which cover such topics. Thus, I did not learn as much from this book as I do with others, but that doesn’t mean it’s bad for a general audience. I do think the discussion of free well and consciousness could be reduced a bit in favor of extra focus on imitation and reinforcement learning, which are among the hottest research fields in AI. While this book isn’t entirely about the research frontiers, the omission of those is a bit surprising even when considering the 2016 date. The book is on the shorter side at 200 pages so perhaps a revised edition could add 10-20 more pages to the research frontiers of AI? There are also some other surprising omissions — for example, the famous AlexNet paper is not mentioned. In general, I might recommend more focus on current frontiers in AI and not on speculation of the future.
-
Astrophysics for People in a Hurry (2017) by scientist and science popularizer Neil deGrasse Tyson, is a slim book5 where each chapter is on a major theme in astrophysics. Example include exoplanets, dark energy, dark matter, and what’s “between” planets and galaxies. I am familiar with some concepts at a high-level, most of which can be attributed to Lisa Randall’s two recent books that I read, and Tyson’s book served as a helpful refresher. Tyson boasts that Astrophysics for People in a Hurry is short, so there are necessarily going to be limitations in what he can present, but I think there is a niche audience that this book will reach. In addition, it is written in Tyson’s standard wit and humor, such as “I don’t know about you, but the planet Saturn pops into my mind with every bite of a hamburger” and “The system is called the Sagittarius Dwarf but should probably have been named Lunch”, since dwarf planets can get consumed by larger planets, i.e., “planet cannibalism”, get it?? The main benefit is probably to pique the reader’s curiosity about learning more, which could be said for any book, really. In addition, I will give a shout-out to Tyson for mentioning in the final chapter that we must never cease our scientific curiosity, for if we do, we risk regressive thinking that the world revolves around us. (Please read the final chapter to fully understand.)
-
** Life 3.0: Being Human in the Age of Artificial Intelligence ** (2017) by MIT theoretical physicist — and a welcome recent entrant to AI — Max Tegmark, clicked on all the right cylinders. Think of it as a more accessible and mainstream version of Nick Bostrom’s Superintelligence, which itself wasn’t too shabby! The “Life 3.0” part refers to Tegmark’s classification of life as three tiers: Life 1.0 is simple life such as bacteria that can evolve but cannot change its hardware or software, and thus will not be able to change its behavior beyond what evolution has endowed it with. Life 2.0 represents humans: we can change our software by changing our behavior based on past experience, but we are limited by our “hardware” of being human, beyond basic stuff like hearing aids (that I wear), which can be argued as a “hardware upgrade”, but are minor in the grand scheme of a human design. In contrast, Life 3.0 not only can learn like humans, but can also physically upgrade its own hardware. The possibilities for Life 3.0 are endless, and Tegmark takes us on wonderful thought experiments: what kind of world do we want from a superintelligent agent? How can it use the resources in the cosmos (i.e., all the universe)? These are relevant to the question of how we design AI now, because by driving the agenda, we can increase the chances of attaining the kind of future we want. He gave a captivating keynote talk about some of this material at IJCAI 2018 in his home country of Sweden, which you can see from my earlier blog post. Having been a committed AI researcher for the past five years, I recognized many of the well-known names from Tegmark in his commentary and the pictures from the two conferences he features in the book.6 I am inspired by Tegmark’s body of work, both in the traditional academic sense of research papers but also in the sense of “mainstreaming” AI safety and getting the top researchers together to support AI safety research.7 The book manages to make the reader ponder about the future of life. That’s the name of an organization that Tegmark helped co-found. I will heed the advice from his epilogue about being optimistic for the future of life, and how I can help drive the agenda for the better. Overall, Life 3.0 is one of my favorites, just like it is for former President Barack Obama, and might have been my favorite this year.
-
** Why We Sleep: Unlocking the Power of Sleep and Dreams ** (2017) is probably the top popular-science book on sleep out there. It’s by UC Berkeley neuroscience Professor Matthew Walker, whose lab is in the same building as the AI group! I had to buy Why We Sleep after Scott Young recommended it. I badly want to improve my sleep habits. I don’t normally have a problem allocating my eight hours of sleep a night … the problem is that I might be physically in bed at the right time, but not fall asleep until an hour later, which means eight hours in bed corresponds to seven hours of actual sleep. I wanted to know if I could fix that. I am also curious about sleep in general: about the role of screens, alcohol, caffeine, and sleeping pills, and if there are truly people who can get away with six hours of sleep a night without performance degradation. I quickly devoured this book8 since it gave crisp and clear answers to most of my questions. Yes, some people can get away with about six hours of sleep, but those odds are roughly 1 in 2000 (and I know I am not one of them). Walker is also firm that sleeping pills and alcohol are not helpful for sleeping. Please, don’t say that wine helps you to sleep! Walker additionally describes the different sleeping stages of REM and NREM sleep (REM = Rapid Eye Movement). He backs up these claims and/or facts with scientific studies. These might involve bringing participants to his sleeping lab where he can monitor their sleep and probe them experimentally by waking them up in the middle of the night and asking them to perform cognitive tasks. I was pleased by how much “causality” was mentioned in the book, particularly because I was reading this in parallel with some of Judea Pearl’s The Book of Why (which I haven’t finished yet). Walker writes with the usual academic refrain that for some hypotheses, “causation has yet to be determined,” but there are other cases where controlled trials have shown that lack of sleep often happens before debilitating health effects. I believe it! The one thing I wasn’t quite sure about after reading this was on how fast people can fall asleep at night. I’ve had people tell me that they fall asleep within six or seven minutes (!!!!!) of getting into bed, and I was hoping Walker would discuss how that is physically possible. Nonetheless, it’s still a great book, and I am now using my FitBit to track my sleep, and may upgrade more sophisticated sleep measurement systems to cross-verify for accuracy. I read a lot of books so by now it’s hard for a new one to really change my thinking or way of life, but this one somehow managed to do it. It’s a top 2-3 book I read this year.
Update 01/04/2020: yikes! A reader informed me of this blog post which claims that Why We Sleep is filled with scientific errors. That post has gotten a fair amount of attention. I’m … honestly not sure what to think of this. I will have to go through it in more detail. I also urge Professor Walker to respond to the claims in that blog post.
-
Blueprint: How DNA Makes Us Who We Are (2018) by behavioral geneticist Robert Plomin of King’s College London is about DNA and its ability to predict psychological traits. This is what Plomin means by “makes us who we are” in the subtitle, which he repeats throughout the book. The first part summarizes the literature and research results on how DNA can be used to predict traits, including those that seem environmental, such as educational attainment. The presence of identical twins has been a boon to genetics research, as they are the rare cases of when two people are 100 percent similar genetically. The second part discusses how “polygenic scores”9 computed from DNA samples can be used for “fortune-telling” or predicting traits. This is not my field, and I trust Plomin when he says that the science is essentially settled on whether heritability exists. Nonetheless, this book will be controversial; right on cue, there’s a negative review of the book which brings up precisely the points I am worried about: eugenics, designer babies, and so on. To his credit, Plomin keeps emphasizing that all DNA can do is make probabilistic (and not actual) predictions, and that there are an enormous spread of outcomes. Plomin is also right to say that: “The genome genie is out of the bottle and, even if we tried, we cannot stuff it back in” near the end of the book. Trying to hide science that’s already been made public is virtually impossible, as the Soviets demonstrated back in the early days of the Cold War when they stole nuclear weapons technology from the United States. But I worry that Plomin still did not sufficient assuage the concerns of readers, particularly those of (a) parents and potential parents, and (b) policy makers concerned about consequences for inequality and meritocracy. Though, to be clear, I am fine with these results and trust the science, and it’s also blindingly obvious that if we end up equalizing opportunity and education among an entire population, we will end up increasing the relative impact of genetics on final performance. Blueprint is a necessary book to read to understand the implications of the current genomics and DNA revolution.
-
The Deep Learning Revolution: Artificial Intelligence Meets Human Intelligence (2018) was an instant-read for me the moment I saw the book at the MIT Press Booth at ICRA 2019. It is written by Distinguished UC San Diego Professor Terence Sejnowski, who also holds a chaired position at the Salk Institute and is President of the Neural Information Processing Systems foundation. That’s a lot of titles! I recognized Sejnowski’s name by looking at various NIPS (now NeurIPS) conference websites and seeing him as the president. From a technical sense, I remember he was among the team that refined Independent Component Analysis. I have a very old blog post about the algorithm, dating back to the beginning of my Berkeley era. He also worked with neural networks at a time when it was thought not to be a fruitful path. That the 2018 Turing Award went to Hinton, Bengio, and LeCun shows how much things have changed. The book talks about Sejnowski’s experience, including times when others said they “hated his work” – I was familiar with some of the history of Deep Learning, but Senjowski brings a uniquely personal experience to the reader. He’s also knowledgeable about other famous scientists, and mentions the pioneers in Deep Learning, Reinforcement Learning, and Hardware. He concludes by marveling about the growth of NeurIPS. The main downside is that the book can sometimes seem like a hodgepodge of things together without much connection among the topics, and there are some typos which hopefully will be corrected in future editions. There is, of course, the usual adage that it’s hard to know a topic that Sejnowski talks about without already knowing it beforehand, but every popular science book would suffer from that problem. I would later attend NeurIPS 2019, as I wrote here, where I saw him and a few others featured in his book. I wish I could attain a fraction of Sejnowski’s academic success.
-
** Taming the Sun: Innovations to Harness Solar Energy and Power the Planet ** (2018) is by Varun Sivaram, who was then a Fellow at the Council on Foreign Relations, one of the main “think tanks” I generally trust. The book, recommended by distinguished politicians such as John Kerry, provides the scientific and economic facts to know about solar energy. We should care about solar energy, the book argues, due not only to climate change and the need to reduce carbon emissions (this one obvious), but also due to how the sun powers enough energy to literally power the planet, yet we do not have the technology to utilize it effectively. The second point was less obvious but shows the vast potential of solar energy! I wanted to understand how much solar energy can realistically take care of our energy needs, both now and many decades in the future. While the cost of solar has come down, as I am aware, that is not a panacea. Large Chinese firms have pumped cheap solar cells into the economy, but the extra value added by a solar panel can actually be negative due to the panels absorbing too much power during the sunny days of the year, forcing electric utilities to sell solar power and reducing the economic basis of adding more solar panels. In addition, Sivaram explains that the focus on cost cutting and economies of scale with current products means it is harder for newer technologies that could, eventually, be superior to the current panels used today. He describes how academic labs throughout the world are tweaking with their designs for more efficient solar cells, but it could be many years before these become economically viable. In the meantime, we need more technological, innovation, and we also need systemic innovation, which refers to adjusting our power grids and infrastructure to take advantage of solar energy. There are a number of challenges, but like many readers, I came away deeply impressed with Sivaram’s optimism and technological expertise. I hope we get more exciting talent and results from this field. According to his website, Sivaram is currently Chief Technology Officer of ReNew Power Limited and lives in India. I hope he succeeds there, for India is an emerging economy and it is where climate change will be at the forefront.
Group 3: American History and Current Events
-
Washinton at Work: Back Rooms and Clean Air (second edition, 1995) by Richard E. Cohen, a Congressional reporter, details what happened “behind the scenes” to make the 1990 Clean Air Act pass into law. I found this seemingly obscure book at a coffee shop in Berkeley. I decided to read it because … Washington is “at work?” Seriously? It’s working?!? YAY!!!!!! More seriously, the broader impact of Washington at Work is to provide context on how complex bills become law in America. Cohen wrote the book a few years after the act was passed, and “reconstructed” the dialogue and political dynamics. Cohen introduces the 1970 Clean Air Act, the predecessor to the 1990 one, and follows up with the Reagan years in the 1980s, where little could be done on environmental legislation due to deregulation.10 Fortunately, Reagan’s vice president, the late George H.W. Bush, was interested in being known as an environmental president. (Disappointingly, Bush had to move further to the political right after the law was passed to appease conservative critics, and paradoxically was unable to fully take credit for the Clean Air Act.) What follows in Washington at Work are stories of how the House and Senate were able to resolve their differences and create their own versions of an updated clean air act. Key players were the legendary representative John Dingell and Henry Waxman, along with George Mitchell in the Senate. One observation from reading the book is that political partisanship and deadlock were serious roadblocks back in the 1980s and 1990s, so I wonder if those who say that things are “much worse nowadays” have a quantitative metric to evaluate deadlock. Another observation, which might partially answer the first, is the large amount of partisan infighting over the bill, with coal-state Democrats opposing the bill (e.g., Robert Byrd) and several Republicans supporting the bill. I’m not sure we would see the same today. Finally, it’s interesting to see that back then, acid rain was one of the most pressing environmental topics of the day, but we barely talk about it nowadays. Instead the focus has shifted to global warming and climate change.
-
** Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians who Helped Win the Space Race ** is the 2016 bestselling book which inspired the movie of the same name. I’m not a movie person — since December 2015 I have watched a total of one movie in four years — but I am a book person, so I read the book, by Margot Lee Shetterly. I started right after making my Apollo 11 post, because I figured there was never going to be a better time for me to read it, and I’m glad I did. It chronicles the lives of Dorothy Vaughn, Katherine Coleman (still alive at the age of 101!), Mary Jackson, Christine Darden, and a few others, who were female African American mathematicians working at Langley and then NASA, helping America win the Space Race over the Soviet Union in the 1960s. Hidden Figures compellingly describes what life must have been like for them in the 1960s; when reading the book, I often got distracted due to fantasizing different 1960s-era scenarios in mind. The book discusses the career trajectories of the women, assigned as “mathematicians,” and concrete scenarios such as how Katherine Johnson’s work helped John Glenn orbit the Earth. If there’s one thing I was slightly disappointed about, it was that there wasn’t a whole lot about the actual Apollo 11 mission to land on the moon, except for a bit in the final chapter, but perhaps it was hard to find documentation or evidence for the women’s contributions to that project, as compared to Glenn’s orbit. I agree with Shetterly in that these stories are inspiring but not well known prior to this book, and that clearly justifies the need for Hidden Figures. I was reading this at a time when I was laboring heavy hours in a workweek to meet some research deadlines, and one thing that helps drive me is knowing that I have plenty of opportunity here at Berkeley, and I can’t waste it.
-
** American Dialogue: The Founders and Us ** (2018) by Joseph J. Ellis, Professor Emeritus at Mount Holyoke College, considers the question: What would the founders think? The book features four of them. Each has one major theme presented in a historical context and then a modern context. In order of discussion: Thomas Jefferson on race, John Adams on equality, James Madison on law, and George Washington on foreign policy. Ellis presents the history and circumstances of these four men in a concise yet informative and fascinating manner. My biggest takeaway are all the contradictions inherent in our founders. Thomas Jefferson opposed a biracial America and, while he wanted to free slaves, he also made it clear that the goal was to deport them to some undetermined location to keep America “pure.” At the same time he said that, he had a biracial slave mistress, and an extended family of slaves at home. Hypocritical is too kind of a word. This is also relevant to the famous “all men are created equal” phrase in the constitution … whatever happened to Native Americans or African Americans? Or, of course, women. (Hey, founders, I’m very impressed with your ability to ignore half of the population!) Meanwhile, in law, we have the whole “originalist” vs “living Constitution” debate … yet Ellis makes a convincing case that Justice Scalia’s District of Columbia v Heller opinion was highly political whereas Justice Steven’s dissent was originalist. (How often do we hear about the “well regulated militia” in the debates about the second amendment?) As Ellis keeps reminding us, we live in an America that is far different from what the founders lived in, so rather than view the founders as mythological creatures with the brilliance to write a Constitution that should last forever, we should instead view them as highly fallible men who debated and argued while drafting the Constitution, and could not have foretold what the future would hold. Argument, debate, and dialogue is their ultimate legacy.
-
** Identity: the Demand for Dignity and the Politics of Resentment ** (2018) explores the topic of identity. It’s by Francis Fukuyama, better known for writing The End of History and the Last Man and The Origins of Political Order; I read the latter last year. Fukuyama admits from the first sentence that “This book would not have been written had Donald J Trump not been elected president […]”. Fukuyama also addresses whether event X or event Y in the world invalidates his thesis from The End of History and the Last Man. Fukuyama appears to still hold faith in liberal democracies, but he admits that such societies are not able to fully satisfy what’s known as “thymos,” the part of the soul that craves dignity. (Two related terms that frequently appear in the book are “isothymia” and “megalothymia.”) The rise of liberal democracies gives more freedom to citizens, but also means they have to consider the questions of “Who am I” and “What group am I in?” These questions would not have made sense in earlier, peasant-oriented societies. Unfortunately, these aren’t issues that the free market and capitalism can entirely address, meaning that some people resort to potentially dangerous strains of nationalism and religion. Fukuyama additionally discusses the identity politics of modern-day America, from both the left and right. While he admits that there are some positives (for example, he is concerned over police brutality to blacks and sexual assault from powerful men) he makes it clear that there are advantages to having shared citizenship, and at some point we must put aside our differences. From reading Identity, I gleaned several insights that in retrospect I should have known beforehand. In addition, the solutions that Fukuyama proposes in his last chapter appear reasonable, such as those about promoting immigration. If I had political power, I would try to implement these.
Group 4: Self-Improvement
-
** Mindset: The New Psychology of Success ** (2007) is by Carol Dweck, Professor of Psychology at Stanford since 2004. Mindset has been a huge success, with at least 1.8 million copies sold, and is advertised as telling us “how we can achieve our potential.” Professor Jason Mars recommend it when I personally asked him about his favorite books. The key contribution of Mindset to the public sphere is the notion of a growth mindset, in contrast to a fixed mindset. A growth mindset is about believing you can change your skills. Those with a fixed mindset think their skills are stagnant, and that if they have to put in effort for some task, they’re not skilled. Obviously, these are oversimplifications, and Dweck clarifies that everyone lies on some spectrum of fixed-to-growth, which is furthermore task-dependent. Some have a growth mindset for business but have a fixed mindset for their personal lives. Dweck presents examples in sports (UCLA coach John Wooden), parenting, relationships, and business. I am puzzled about her praise of former GE Jack Welch as CEO, but at least she — and Adam Grant in Give and Take — agree that Kenneth Lay of Enron isn’t someone to be admired. I conclude from Mindset that I need to have a growth mindset. I view the book favorably; it has a similar flavor to Grit by Angela Duckworth. Both books are subject to the same sets of criticisms, such as from the limitations of psychology-based research and the “blaming the victim” mentality when things don’t go well. Professor Dweck explicitly mentions she does not want to play this game, and admits that in CEOs and business, most of her examples are men, and she wishes she could feature more women. Perhaps the biggest weakness of the book is that I’m not sure where the line is drawn between blaming the victim (e.g., “it is women’s fault they don’t have the growth mindset!!”) versus attacking structural discrimination (e.g., “women don’t even have the opportunity to get these kind of careers!!”). Regardless of whether discrimination is present or not, it’s still better to have a growth mindset than a fixed one, and that counts for something.
-
Infinite Possibilities: The Art of Living Your Dreams (2009) is by Michael Dooley, a former tax accountant who now spends his time discussing daily “notes on the universe” and other things as explained on his website. Dooley’s chief claim from the start is that thoughts become things. Dooley argues we have to believe in and think about our goals, before we can attain them. Inifinite Possibilities is written in a motivational style, trying to urge the reader to do stuff, think positively, and follow your dreams. There are some good points in this book, and I appreciate Dooley revealing that even a deeply spiritual man like him suffers from similar things I do, like feeling guilty when relaxing and vacationing. The downside is that I disagree with the rationale for his beliefs in Infinite Possibilities. Dooley argues, for instance, that space and time operate via thoughts turning into things; but they actually operate by the laws of physics, and someone thinking about something can’t guarantee that the event will actually happen! Dooley counters this by claiming that we think about so many things that not all can be true, but that is cherry-picking. I am a vocal advocate of rigorous, empirical, controlled experiments, over high-level motivational comments. Unfortunately, this book doesn’t cite any studies or even a cursory glance at the literature in neuroscience, cognitive science, psychology, and other fields that could bolster some of Dooley’s claims. There is certainly an audience for Dooley’s book, as evident by his hundreds of thousands of email subscribers, but it is not my style.
-
Getting to Yes: Negotiating Agreement without Giving In (editions in 1983, 1991, and 2011 – I read the 2011 one).11 The three authors are Roger Fisher, a former Harvard law professor, William Ury, a distinguished fellow of “the Harvard Negotiation Project” (surprisingly, that’s a thing), and in later editions, Bruce Patton (also a distinguished fellow of the Harvard Negotiation Project). Getting to Yes is a classic book on negotiation skills, which has become increasingly important with flatter hierarchies in work environments, which induces more discussions among people of equal status. The book starts off by warning us not to bargain over positions. That would be the classic “he said $X$, she said $Y$, so we’ll split the difference and do $\frac{X+Y}{2}$”, which is bad for a number of reasons. Here’s an obvious one: someone clever could just start with a more extreme position to get a desired quantity! Instead, the authors give us a four point method: (1) separate — or more politely, disentangle — the people from the problem, (2) focus on interests, not positions, (3) invent options for mutual gain, and (4) insist on objective criteria. Then they tell us what to do with people who won’t play nice (e.g., “best alternative to a negotiated agreement”) and then answer common questions from readers. Their advice seems sound! I can see why it works in theory. That said, the book has several weaknesses, but some are inherent to this kind of genre. First, I do not think the examples are fully fleshed through. Perhaps fewer examples would be better, and maybe it would be feasible to contrast those with failed negotiations? The book sounds scholarly, but it doesn’t cite much research except for some of the authors’ other books. Also, I don’t think this will appease people nowadays who talk about marginalized people and say that “the moderate stance is taking an extreme political position…” Fortunately, I think the book does a fine job in the delicate case of dealing with a more powerful negotiator.
-
** Atomic Habits: An Easy & Proven Way to Build Good Habits & Break Bad Habits ** (2018), is written by James Clear and came recommended by Scott Young. The book’s central claim is to focus on making small improvements, because over time these add up. Making a 1% improvement for a few days doesn’t seem like much, but it makes a huge difference over a year, as compared to someone who might experience a 1% deterioration. I was initially skeptical at the start of reading Atomic Habits, but I gradually grew to like it. Clear provides clear (pun intended) tips on how to build good habits. For example, it makes more sense to fix your environment rather than to motivate yourself. If I’m trying to eat healthy, then why surround myself with a bunch of sugary snacks and hope that my “willpower” will make me avoid eating that stuff? The logical thing is to only buy healthy food. That’s essentially what I strive to do, so it was good to see my habits coinciding with Clear’s recommendations. I additionally use variants of Clear’s advice (e.g., “show up on bad days”) to help me with running. I am seeing results: in the last two years, my half-marathon time has dramatically improved from 1:54 to 1:35. Clear references some books I’ve read, such as the authors of the Harvard Negotiation Project who wrote the Getting to Yes book. Clear also references Robert Plomin, who wrote Blueprint, when discussing how certain skills are hereditary, most notably in sports contexts. The footnotes also mention Cal Newport’s Deep Work. From the perspective of my PhD research, I was also pleased to see a lot of discussions about rewards, which go hand-in-hand with reinforcement learning. Finally, it was nice to see in the last chapter (titled “The Downside of Creating Good Habits”) that Clear performs annual reviews of himself. You can find them here. It is quite similar to what I have with my New Year’s Resolution documents, though I do not make mine public. In fact, as I’m typing these words, I am simultaneously reviewing my 2019 document and polishing my 2020 plan.
-
** Digital Minimalism: Choosing a Focused Life in a Noisy World ** (2019) is yet another book written by computer science professor Cal Newport. I’ve read all of his books12, and knew I was going to devour Digital Minimalism upon its release. I did so through iBooks and mostly read the book on my iPhone during morning bus rides to campus. The point of Digital Minimalism is to offer a better philosophy of utilizing social media and other “digital technologies” to lead a more fulfilling life. Newport backs his claims with research on how humans are hard-wired for both socialization but also periodic forms of isolation; the latter is increasingly difficult nowadays in our constantly-connected lives. Newport particularly laments that social media companies have figured out ways to keep more users on social media longer to get more advertisement revenue, such as by using red as the color for notifications, and that key to the rise of social media is the smartphone and how it enabled constant social media access. Newport is a critic of these, which is what I would expect from someone who often boasts on his blog that he’s never had a social media account. But he brought up something thought-provoking and new to me: Steve Jobs did not anticipate us using smartphones the way we do today with constant connection; he mostly wanted to merge a phone with an iPod. In addition to discussing some history and current events, Newport provides recommendations for properly integrating social media for a more fulfilling life, such as deleting apps on smartphones that give access to social media and doing leisure activities that involve physical, non-digital activity. I feel strongly that the book is useful to the vast majority of people who utilize social media. For me, it probably isn’t going to change my life too much, given that I already follow plenty of Newport’s advice. It’s not as good as Deep Work, but it’s definitely worth reading.
-
** 24/6: The Power of Unplugging One Day a Week ** (2019) is a new book by famous film-maker and Internet pioneer Tiffany Shlain, who I know because she is married to one of my PhD advisors. Needless to say, 24/6 was an instant read for me when it was published. Fortunately, Ken Goldberg brought a copy to the lab. When I opened it, I found a hand-written note from Ms. Shlain addressed to me, saying that I was “the most prolific reader in Ken’s lab”.13 Thank you! The book resonated with me because, Like Ms. Shlain, I am deeply connected to the world and rely heavily on the Internet for my day-to-day duties. I also have this long-running blog, which probably makes me even more closely attached to the Internet compared to other computer scientists in my generation. This book discusses how she and her family takes 24 hours off a week, from Friday night to Saturday night, and unplug. This means no electronics. For calls, they use their landline phone, and for writing stuff, it’s paper and pen. This is inspired by the Jewish “sabbath” but as Shalin repeatedly emphasizes, it’s not a Jewish thing but one that can apply to a variety of religions, including the church I go to (atheism). 24/6 has many examples of Shalin’s activities during her sabbaths, some of which were known to me beforehand. She also proposes practical tips on making a 24/6 life happen in today’s world, with testimonials from her readers. The easiest way for me to follow this is, like her, to have a 24/6 break from Friday night to Saturday night, and use that time for, well, reading physical books instead of e-books, long-distance running, and cooking the next salad dish. I hope I can keep it up!
Group 5: Dean Karnazes Books
All three of these books are by ultramarathoner Dean Karnazes. He is perhaps the ultramarathoner best known to the general public. While Karnazes is not the best ultramarathoner, he’s a very good one. (This article shows some context on the “controversy” surrounding Karnzes.) I first saw the name “Dean Karnazes” in an email advertisement for a running race in the Bay Area. It showed a picture of him shirtless (no surprise) and quickly recapped some of his eye-popping achievements: that he’s run in conditions ranging from 120 degree temperatures in Death Valley to freezing temperatures in Antarctica, that he once ran 350 miles continuously, and that he once ran 50 marathons in 50 days in 50 states. One Google search led to another, and I found myself reading his books.
-
** Ultramarathon Man: Confessions of an All-Night Runner ** is the 2005 biography of ultramarathoner Dean Karnazes, and the one that catapulted him to fame. In Ultramarathon Man, Karnazes describes how he had an epiphany when he turned 30 to start running for the first time since high school, to give him satisfaction and meaning that he wasn’t getting from his corporate job. The book describes four main running races: the Western States 100, Badwater, a run at the South Pole, and then a 200-mile race. The Western States 100 run was his first 100-mile ultramarathon and describes all the setbacks, pitfalls, and dangers that he and other runners faced, such as disfigured feet, bad urine, and dehydration. But Western States 100 probably pales in difficulty compared to Badwater, a 135 mile run in 120 degree weather in Death Valley in July. Ouch! Karnazes actually dropped out in his first attempt, came back to finish and eventually won the 2004 race outright. His race in Antartica was equally dangerous, for obvious reasons: there was frostbite, and he nearly got lost. The last one was a 200-mile “relay” race that he ran solo, whereas other teams had 12 alternating runners. Karnazes’ purpose was to raise some money for a young girl’s health condition. It’s very touching that he is inspired to run “to give the gift of life,” especially considering how his sister died in a tragic car accident while a teenager. The main feeling I had after finishing this book was: inspiration. As of December 2019, I have run seven half-marathons, and I will add some marathons in the coming years. Health permitting, I will be a runner for life. If there’s any ultramarathon I’d run, it would be the San Francisco one, which gives a break of a few hours between two consecutive 26.2 mile runs. Perhaps I’ll see Karnazes there, as I think he still lives in San Francisco.
-
50/50: Secrets I Learned Running 50 Marathons in 50 Days — and How You Too Can Achieve Super Endurance! (2008), written by Dean Karnazes and Matt Fitzgerald, describes Dean Karnazes’ well publicized 50 marathons in 50 states in 50 days quest.14 This is the best reference for it. I think there was other information online at some point, but that was back in 2006. NorthFace sponsored Karnazes — in part due to the publication of Ultramarathon Man — and provided him with a support team for travel to races and to monitor his health. Karnazes’ target pace was 4 hours for each marathon, and he kept remarkably well at it. The average time of his 50 marathons was 3:53:14. Most of the 50 races were not actual “live marathons” since those usually happen on weekends. The weekday races were simulated like a normal marathon and run on the same course, but with only minimal police protection and a smaller group of volunteer runners that signed up to run with Karnazes. There are many great stories here, such as a Japanese man who signed up on a whim to impress his new lover, and how former Arkansas Governor Michael Huckabee joined him for the races in Arkansas and in New York City. Incidentally, the last race was the live 2006 New York City marathon, which he ran in 3:00:30, a very respectable time! After the celebration, the next day Karnazes said he felt lousy. So … he went for a run. He said he spent forty days almost entirely outside, running from New York City back to the starting line of the Lewis and Clark marathon in Missouri?!? How is that possible? Sorry, I don’t believe this one iota. Finally, the book is scattered with running tips from Karnazes, though most are generic “marathon advice” that can be easily found outside of this book. Three pieces of advice I remember are: (a) tips on how to avoid getting sick during a race, (b) stop heel-striking, and (c) don’t drink water for the last hour before a race.
-
Run! 26.2 Stories of Blisters and Bliss (2011) is yet another Dean Karnazes book, consisting of “26.2 chapters” on various short stories throughout Karnazes’ running career, not including those in his prior books. For example, he recalls the Badwater races he ran after his first, failed attempt (covered in Ultramarathon Man), including one where he ran naked after he found out his father needed heart surgery. Strangely, he never mentions the 2004 edition of Badwater, which is the one he actually won. He also never mentions his continuous 350 mile run done over three nights without sleep, though he does refer to run of the same length in Australia over six days. Karnazes also mentions his two failures at Leadville, the first due to altitude, and the second due to a torn meniscus. He then ignored his doctor’s instructions to stop running! I disagree. I like running but I am not willing to do lasting damage to myself. Run! is a reasonably nice supplement to better understand the highly unusual nature of Karnazes’ life. Some stories seem a bit fragmented, with only a few pages to digest them before moving on to the next. The book is on the short side so I’m in favor of adding rather than removing content. I believe Karnaes’ first book, Ultramarathon Man, is the best, followed by 50/50, and then this one. I am fine reading all of them, but for those who aren’t running fanatics, I recommend sticking with Ultramarathon Man and leaving this one aside. The book’s cover is a picture of him shirtless which I found to be a bit self-centered, though to be fair Karnazes doesn’t write like a someone trying to inflate his ego — he explicitly states in his book that he runs for personal goals, not to brag to others.
Group 6: Yuval Noah Harari Books
I’m glad I finally read Yuval Noah Harari’s books. Somehow, he takes us through mind-blowing journeys across history, current events, and the future, and delivers highly thought-provoking perspectives. All of his books are about 400 pages, but for “academic-style” books, they honestly don’t feel like slogs at all. His English writing is also beautiful, and reminds me of Steven Pinker’s writing style. All of this is from someone who works less than me and spends 1-2 hours each day meditating.
-
** Sapiens: A Brief History of Humankind ** (2011, US Edition 2015) is a lovely book that somehow covers the entire history of humanity, from our Neanderthal ancestors to modern-day humans. Thus, Sapiens must necessarily sacrifice depth in favor of breadth. That’s fine with me, as I can pick other books from my reading list that can go into more depth on a subset of topics. Harari does a great job describing our ancestors in such vivid and sometimes quirky language. I especially enjoyed his descriptions on what life was like as a forager, where wild, “natural” food was available — provided you could find it — and infectious diseases were nonexistent. Consider the contrast, Harari argues, with agriculture, which forced us to settle into fixed communities with animals. Not only did disease spread, but domesticated animals themselves became an evolutionary tragedy: they are technically “successful” in reproducing themselves, but they live such miserable lives. (Harari also discusses our treatment of animals in his other books, and due to his research, he now strives to avoid anything to do with the meat industry.) I was also delighted to see that Sapiens covers happiness and the decline of violence. These are similar themes present in Steven Pinker’s books of Better Angels and Enlightenment Now. The Hebrew edition of Sapiens was published in 2011, the same year Better Angels came out, so perhaps Harari and Pinker independently synthesized the research literature on the decline of violence? They seem to have a fair amount of common interests (and common readers, like me), so perhaps they collaborate in their academic lives? Collaboration, after all, is an example of human communication and cooperation, which Harari states as perhaps the definitive advantage of our species over others.
-
** Homno Deus: A Brief History of Tomorrow ** (2015, US Edition 2017). I was initially puzzled: how can someone, even a great mind like Harari, write 400 pages of what the future will be like? I can see how to write Sapiens (in theory), since there’s so much history to write and the difficulty would be with condensing it, but predicting the future seems too speculative, and might rely heavily on subjects such as climate change and artificial intelligence (AI), and he is not an expert in those areas. Yet, Harari once again managed to surpass my expectations with Homo Deus. Yes, climate change and AI certainly made their expected appearances, but they are not as prevalent as I expected. Harari begins by presenting the “new human agenda,” stating that many advances of the prior centuries were about reducing premature deaths (e.g., infant mortality), but this is not the same as the more exciting but frightening concept of upgrading the human experience. Why is this problematic? Reducing premature deaths is fine if we think of the “baseline human experience” as living in good health until age 90 or so, and societies have incentives to increase health and prosperity among (most of) their people, not just a tiny elite. But what will happen if the super rich can upgrade themselves to live to 150, and where technological forces and globalization mean that there is little to no incentive to improve the well being of the non-elite, working class, who suffer from irrelevance? Homo Deus then explores these themes in more detail, in three main parts: (1) on how we treat animals, because upgraded humans could treat ordinary humans like we treat animals, (2) how “Humanism” won over Communism, Nazism, and Fascism, and (3) the future of Humanism. Even if, say, Humanism dies out, this might not be a bad thing. “Dataism,” for example, could take the place of Humanism, where data and algorithms make our decisions. I’m pretty pro-data myself — though not a “fanatic” — and it was scary to ponder about the danger the future could hold. Harari concludes with the obvious disclaimer that no one can predict the future, and nowadays, there is so much information that we actually need to cultivate skill in filtering nonsense. I strongly endorse Harai’s books and I think they are worth our time to read. This was a top 2-3 book that I read this year.
-
21 Lessons for the 21st Century (2018) is the third book by Yuval Noah Harari, and once again, somehow Harari manages to blend complex concepts and “how did I not realize that earlier?” ideas into wonderfully simple language. Harari divides his third book into 21 chapters, each with a particular “lesson” or “theme” for us to ponder. This is about the present, whereas his prior books talk about the past and future, but this book has quite some overlap with Homo Deus, such as with the “fly and the bull” metaphor about terrorism. Nonetheless, there is certainly enough new material to be worthy of its own book. Chapters include those on terrorism, as suggested earlier, along with those such as war (never underestimate human stupidity!), liberty, equality, work, ignorance, education, and so forth. Harari concludes with two interesting chapters, on (a) how to find meaning in life, which includes discussions on suffering and has persuaded me that meaning can be found in reducing suffering, and (b) his own solution to facing information overload in the 21st century: meditation. Perhaps I should get around to practicing meditation, since it would be good for me to figure out how to keep my mind concentrated on one topic (or no topic!), rather than the present state where my mind repeatedly jumps around from subject to subject. Now for the bad news: it seems like, at least if the Wikipedia page is right, that for the Russian translation, Harari authorized the removal of some passages critical of the Russian government. I will call it out like it is: hypocrisy. I don’t know why he did that; if I were in his position, I would get all the Russian experts I know to confirm that the Russian translation actually contains the criticism of Russia, and I would refuse to authorize the translation if it removed them. Putin is the kind of person who would be happy to create the kind of heavy surveillance state that Harari criticizes in the book when discussing the loss of liberty. To sum it up: an excellent book, and one which will probably persuade me to try out meditating, but poor hypocrisy.
Group 7: Miscellaneous
I put a few books here that didn’t fit nicely in any of the earlier categories.
-
** The New Geography of Jobs ** (2012) by Berkeley Economics Professor Enrico Moretti can be thought of as a counter view to claims made by those such as Thomas Friedman of The World is Flat fame that new long-distance communication technology means geography is less important for jobs and the economy. Moretti argues that, in fact, geography matters now more than ever. Why, out of all places in the world, do the high-tech computer software industries continue to cluster in Silicon Valley? Similarly, why have other major metropolitan areas in the United States and in other countries become hubs and magnets for particular high-innovation activities? One would think that companies want to move to areas with lower costs of living. That has happened, but mostly for lower-skilled manufacturing tasks. Higher-skilled research and development remains in pricey US cities. Moretti provides compelling evidence of the advantages these cities possess: they have “thicker markets” with a plethora of highly skilled workers and jobs that match them well. In addition, simply being around talented people can breed greater success and innovation, as many academics can attest (myself included). Critically, this book is not just about the high-tech industry. Moretti’s research suggests that these innovation hubs also provide jobs and wealth to lower-skilled workers. Highly skilled workers have more disposable income and can afford the hairstylists, barbers, yoga instructors, plumbers, carpenters, and other services that still require the same human labor as compared to decades earlier. These advantages, though, only apply in areas that already have high innovation activities, and most cities lack the proper “ecosystem” and thus we see a huge divergence in the fortunes of people based on geography. This book was written in 2012, and Moretti frequently cited the city of Flint as an example of a city whose fortunes have been trending in the wrong direction due to these forces. He turned out to be horribly right. I learned about Flint, like many of us did, when lead was found in its water, forcing then-Governor Rick Snyder to apologize and leading the Democratic political party to host a debate there. So what do we do? Moretti’s main policy proposal is to increase levels of investment in education. Right now, US students are about average in math and science compared to other advanced countries, but fortunately, we are still a magnet for talented citizens of other countries to study and work here. This is the key advantage that we have over other countries, particularly China and Japan, and the US must never relinquish it. Yet, I worry that Trump’s anti-immigration rhetoric, though mostly aimed at lower-skilled immigrants, has the additional effect of making it harder for high-skilled immigrants to come here. To make matters worse, we continue to see lower levels of funding and investment in domestic education and higher levels of student debt. Addressing this must remain a high political priority going forward.
-
It’s Not Yet Dark: A Memoir (2017) is a short and sweet memoir of Irish Filmmaker Simon Fitzmaurice, about his life as a filmmaker living with Amyotrophic Lateral Sclerosis (i.e., Lou Gehrig’s disease). He was diagnosed in 2008, and given four years to live. Despite this, he made it to late 2017 before passing away, and in that time he and his wife gave birth to more children, for five in all. In addition, he wrote the film My Name is Emily using eye-gaze technology. It’s Not Yet Dark poignantly describes how Fitzmaurice’s muscles and body motions progressively broke down, and how he needed a ventilator to breathe. There was some pushback, he recalls, from some people in his Irish hospital about whether it makes sense to “ventilate” someone with ALS, but Fitzmaurice convinced them that he wanted to live. The book describes in succinct yet surprising detail what it’s like to live with ALS, and also how to appreciate life. I’m regularly terrified that I’ll be in good health until I turn, say, 35, and then am suddenly stricken with ALS, which is why I will always try to cherish the present.
-
** Educated: A Memoir ** is a lovely, best-selling 2018 memoir by Tara Westover. The Bill Gates-endorsed book shows how Tara, born to “survivalists” (her wording) in Idaho, grew up without going to school. While technically she was “home schooled,” her family was ultra religious and tried avoiding other activities most of us do in the modern era without much questioning, such as going to the doctor and buying insurance. After some inspiration from an older brother, Westover studied hard for the ACT to get into Brigham Young. Despite being Mormon15 herself, she could not fit in with other students, who viewed her as strange and too devout. In class, Westover didn’t know what the word “Holocaust” meant, and asked that question aloud, to bewildering reactions. (“That’s not a joke” she was told.) I’m amazed she managed to actually get decent grades. In fact, she won a Gates Cambridge scholar and would get a PhD in history from Cambridge. The journey was not easy. Whenever she came back home, she faced a violent brother who would attack and cut her, and her parents would take her brother’s side. Her parents also tried to get her out of the PhD program, insulting those “socialists.” Eventually, Westover started to be open with her friends and collaborators about her background. At the end of the book, she reveals that she could not abide to what her parents were asking her to do, and her family bisected into two, with the PhDs (including her) on one end, and the others (including her parents) on the other. They are not on speaking terms, and I think that’s fine. I would never want to socialize with people like her parents. I did some Googling and found that a lawyer defending her parents said “42% of the children have PhDs.” While that is true, it is in spite of what her parents did, or because her parents starved their children of education — not because they were “better” at preparing their children for PhDs! Educated is the epitome of the memoir I like reading: one which appreciates the power of education and gives me a perspective on someone who has lived a vastly different life than I would ever want to live.
-
India in the 21st Century: What Everyone Needs to Know (2018) by Mira Kamdar is another “What Everyone Needs to Know” book, structured as a list of question-and-answer sections. Kamdar was a member of the Editorial Board of the New York Times from 2013-2017, and currently is an author and provides expert commentary on India. The book reviews the history of the Indian territory, its early religions and ethnic groups, and the British control that lasted until India’s independence in 1947. While some of the history felt a bit dry, it still seems valuable to know, particularly when Kamdar describes famous and powerful people of India, such as Prime Ministers Jawaharlal Nehru and Indira Gandhi, and the famous Mahatma Gandhi. I’m embarrassed to say this, but before reading Kamdar’s book, I thought Indira was related to Mahatma. Oops! Indira was actually the daughter of Nehru and married someone with a last name of “Gandhi.” Anyway, the most interesting portions of the book to me were those that listed the challenges that India faces today. India will soon be the most populous country in the world,16 which will strain its water, food, and energy needs. Unlike China, which has a rapidly aging population, India has a far larger group of younger people, which means it doesn’t need to provide as much elderly care, but it does need to find jobs, jobs, and jobs. If the government fails to do so, it may face protests and anarchy. In addition, India (despite once having a female Prime Minister) still has quite retrograde views on women. I want India to be known for a great place for women to visit, rather than a place where women get gang-raped when they board buses. To make matters worse, sex preferences have resulted in more young men than women, just as in China. The current leader, Narendra Modi, faces these and other challenges, such as dealing with a rapidly-growing China and a hostile Pakistan. I am not a fan of Modi’s “Hindu nationalism”17 that Kamdar mentions; I think unchecked nationalism is one of the biggest dangers to world peace. Kamdar’s last question is a bit strange: Will India’s Bengal tiger become extinct? But, I see her reason: India was able to make progress in rescuing the tiger from the brink of extinction. This gives hope that India will rise to the occasion for bigger challenges in this century. I sure hope so.
-
** North Korea: What Everyone Needs to Know ** (2019) is yet another book in the “What Everyone Needs to Know” series. The author is Patrick McEachern, who spent time at the Wilson Center as a Council on Foreign Relations International Affairs Fellow.18 I wanted to read this because (a) I do not like Kim Jong Un,19, (b) I am concerned about their nuclear weapons program, and (c) I want to know more about North Korea understand the history and politics that have influenced present-day events; a similar rationale motivates my reading of books about China this year. Fortunately, McEachern does an effective job addressing (c). The book, though certainly about North Korea, is probably more accurately described as “two-thirds North Korea” (i.e., the DPRK) and “one-third South Korea” (i.e., the ROK). It starts by discussing the history of Korea and its annexation by Japan, which explains much of the current Korea-Japan animosity across both halves of Korea.20 The book discusses what we Americans view as the Korean War; I have a relative who served in that war. It also makes it clear why so many in North Korea hate America, and why most South Koreans support America. I learned about the history of Korea’s leadership. In the North, we have Kim Il Sung, Kim Jong Il, and Kim Jong Un. In the South, we have leaders from Syngman Rhee to current President Moon Jae-in. McEachern discusses how China is reluctantly an ally of North Korea, for a variety of diplomatic reasons. Interestingly, McEachern believes that North Korea has not yet developed the capability to strike the US with ICMBs, at least as of early 2019 when the book went to print. It was interesting to see that South Korean politics is often a back-and-forth between Conservatives and Liberals, mirroring what’s happening in the United States today. That said, I was surprised by a few of McEachern’s points. For example, his description of the status of women in North Korea is surprisingly neutral, or at least not as negative as I would have thought. I want to see more details on the status of North Korean women in the next edition of the book. I also liked his thought-provoking question at the end. Who will lead North Korea after Kim Jong Un? McEachern proposes that, if Kim Jong Un dies sooner than expected, then his trusted younger sister could lead North Korea. Could North Korea, of all places, have a female leader before the United States?
Whew, 2019 was a good year for reading. Now, onto 2020 and a new decade!
-
Or more accurately, The Great Leap Backwards. The Great Leap Forward was one of the biggest tragedies in the history of the human race. ↩
-
We should be clear on what the “leader of China” means. There have been five major “eras” of leadership in Chinese history since the founding of the People’s Republic in 1949: the Mao Zedong era (1949 to 1976), the Deng Xiaoping era (1978 to 1992), the Jiang Zemin era (1992 to 2002), the Hu Jintao era (2002 to 2012), and finally the Xi Jinping era (2012 to present). The years that I’ve put here are only approximations, because there are three main positions to have to be considered the “ultimate” (my informal term, for lack of a better option) leader in China and these men sometimes did not have control of all positions simultaneously. In addition, they can often play a huge role after their formal retirement. Incidentally, the three positions are: General Secretary of the Communist Party, Chairman of the Central Military Commission (which controls the army) and State President (to control the government). In practice, the first two are more important than the third for the purpose of ruling power. As of this writing in late 2019, Xi Jinping holds all three positions. ↩
-
In China, it is safer to protest about environmental-related issues because protestors can align their objectives with the Chinese Communist Party and frame it as improving the country. It is far different from protesting over more politically sensitive issues, such as asking for democracy in China. Yeah, don’t do that! ↩
-
No, understanding neural networks does not mean we understand how the human brain works. ↩
-
Hence the “People in a Hurry” in the title. My hardcover copy is a little over 200 pages, but the margins are super-thin, so it’s probably equivalent to a “120-page book.” It’s definitely the second-shortest book that I have read this year, with the book It’s Not Yet Dark having the honor of the shortest of them all. Pinker’s Better Angels is, of course, the longest in this list, followed by (I think) Henry Kissinger’s book about China. ↩
-
Thankfully, Tegmark put the names of the conference attendees in the picture caption. It’s definitely a veritable who’s who in Artificial Intelligence! I only wish I could join them one day. ↩
-
Probably the chief downside of Life 3.0, and one which might be a target of criticism from AI researchers, is the heavy discussion on what a superintelligent agent can do is vastly premature; it’s basically the same argument against Nick Bostrom’s work. Still, I argue that there are many pressing AI safety issues right now that the subject of “AI safety” must be a current research agenda. ↩
-
I probably should have expected this, but at the beginning of Why We Sleep, there is a disclaimer which states that the book is not meant to be used for professional medical advice. ↩
-
When reading the book, I was struck by similarities between polygenic scores and Deep Learning. Polygenic scores rely on large-scale studies and the results can only be interpreted by the end outcome from the human’s experience. That is, to my knowledge, we can’t look at a gene and interpret its actual effects on the bloodstream, muscle movements, brain cells, and other body parts of humans. We can only look at a person’s years of education or height to see which set of genes can explain the variance in these qualities. Thus, it’s not as interpretable as we would like. Interpretability is a huge issue in Deep Learning, which has (as we all know) also benefited from the Big Data era. ↩
-
Cohen mentions Anne Gorsuch, who was the Environmental Protection Agency administrator during Reagan’s presidency. I recognized her name instantly, because in 2017, her son Neil Gorsuch, was successfully nominated to the United States Supreme Court. Remember, Cohen’s book was published in 1995. ↩
-
The first edition of the book had some “sexist language” according to the authors. Uh oh. I suspect the “sexist language” has to do with the negotiations about divorce settlements. Earlier editions might have assumed that the (former) wife was relying on the (former) husband for income. Or more generally, the book may have assumed that the men were always the breadwinners of the family. ↩
-
With one exception: I have not read his book on how to be a high school superstar. ↩
-
If you are a member of Ken Goldberg’s lab and would like to dispute this “most read” label, send me your reading list. I don’t mean to say this in a competitive manner; I am legitimately curious to see what books you read so that I can jump start my 2020 book reading list. ↩
-
I’m a bit confused why the title isn’t 50/50/50, as that would be more accurate, and the fact that Karnazes ran in 50 states matters since all the travel eats up potential recovery and sleep time. ↩
-
At the start of the book, Westover mentions that this is not a book about Mormonism and she “disputes connections” between Mormonism and the actions of people in this book. My guess is that she did not want to offend Mormons who are far less extreme as her parents. But we can run an experiment to see if there’s a connection between religion and the activities of certain people. We need a random sample of Mormons, and a random sample of non-Mormons, and measure whatever we are considering (I know this is not easy but science isn’t easy). I don’t know what would be the outcome of a study if such exists, but the point is we can’t unilaterally dispute connections without rigorous, scientific testing. It is disappointing to see this phrase at the beginning of the book. ↩
-
Kamdar explicitly says in the book that sometime in 2017, India surpassed China to be the world’s most populous country. Most online sources, however, seem to still have China slightly ahead. Either way, India is clearly going to be the most populous country for much of the 21st century. ↩
-
Since the book was published, Modi has presided over power and Internet outages in Kashmir, and a controversial Indian citizenship law that arguably discriminates against Muslims. The prospects of peace between India and Pakistan, and within India as well among those of different religions, appears, sadly, remote. ↩
-
Yes, that’s another CFR fellow! I read a lot of their books — and no, it’s not on purposes — I usually don’t find out until I buy the book and then read the author biographies. It’s probably that the genre of books I read includes those which require specialized expertise in an area that relates to foreign affairs. ↩
-
I read this book on the return flight from the ISRR 2019 conference. In one of my blog posts on the conference, I stated that “I will never tire of telling people how much I disapprove of Kim Jong Un.” ↩
-
If I were President of the United States, one of my first foreign policy priorities would be to turn South Korea and Japan into strong allies, while also reassuring both countries that they are under our nuclear umbrella. ↩
Thoughts After Attending the Neural Information Processing Systems (NeurIPS) 2019
At long last. It took forever, but for the first time, I attended the largest and most prestigious machine learning conference, Neural Information Processing Systems (NeurIPS), held in Vancouver, Canada, from December 8-14. According to the opening video, last year in Montreal — the same place that hosted ICRA 2019 — NeurIPS had over 10,000 attendees. Tickets for NeurIPS 2018 sold out in 12 minutes, so for this year, NeurIPS actually used a lottery system for people who wanted to come. (The lottery was not for those contributing to the conference, who received a set of reserved tickets.) About 15,000 entered the lottery, and the total number of attendees was somewhere between 12,500 and 13,000.
I was only there from December 11 through 14, because the first few days were for industry-only events or tutorial talks. While those might be interesting, I also had to finish up a paper submission for a medical robotics conference. I finally submitted our paper on the night of December 10, and then the next morning, I had an early flight from San Francisco to Vancouver. My FitBit reported just 3 hours and 32 minutes of sleep, admonishing me to “Put Sleep First.” I know, I apologize. In addition, I did not have a full conference paper at NeurIPS, alas; if I did, I probably would have attended more of the conference. I had a workshop paper, which is the main reason why I attended. I am still trying to get my first full NeurIPS conference paper … believe me, it is very difficult, despite what some may say. It’s additionally tricky because my work is usually better suited for robotics conferences like ICRA.
The flight from San Francisco to Vancouver is only about 2.5 hours, and Vancouver has a halfway-decent public transportation system (BART, are you paying attention?). Thus, I was able to get to the conference convention center while it was still morning. The conference also had a luggage check, which meant I didn’t have to keep dragging my suitcase with me. Thank you!
NeurIPS 2019 was organized so that December 10-12 were the “real” (for lack of a better word) conference, with presentations and poster sessions from researchers with full, accepted conference papers. The last two days, December 13 and 14, were for the workshops, which also have papers, though those do not go through as intensive a peer-review process.
By the time I was ready to explore NeurIPS, the first of two poster sessions was happening that day. The poster sessions were, well, crowded. I don’t know if it was just me, but I was bumping into people constantly and kept having to mutter “sorry” and “excuse me.” In fact, at some point, the poster sessions had to be closed to new entrants, prompting attendees to post pictures of the “Closed” sign on Twitter, musing stuff like “Oh baby, only at NeurIPS would this happen…“.
For the 1-1.5 hours that I was at each poster session, which are formally for 2 hours each but in practice lasted about 3 hours, I probably was able to talk to only 4-5 people in each session. Am I the only one who’s struggling to talk to researchers during poster sessions?
Given the difficulty of talking to presenters at the poster session, I decided to spend some time at the industry booths. It was slightly less crowded, but not that much. Here’s a picture:

The industry and sponsors session, happening in parallel with the poster
session, on December 11.
You can’t see it in the above photo, but the National Security Agency (!!) had a booth in that room. I have a little connection with the NSA: they are funding my fellowship, and I used to work there. I later would meet a former collaborator of mine from the NSA, who I hadn’t seen in many years but instantly recognized when I saw that collaborator roaming around. However, I have had no connection with the NSA for a long time and know pretty much nothing about what they are doing now, so please don’t ask me for details. While I was there I also spoke with researchers from DeepMind and a few other companies. At least for DeepMind, I have a better idea of what they are doing.
I had a pre-planned lunch with a group, and then we attended Bengio’s keynote. Yes, that Bengio who also spoke at ICRA 2019. He is constantly asked to give talks. Needless to say, the large room was packed. Bengio gave a talk about “System I and System II” in Deep Learning. Once again, I felt fortunate to have digested Thinking, Fast and Slow earlier, as you can see in my 2017 book reading list. You can find the SlidesLive recording of his talk online. There was another poster session after the talk (yes, more bumping into people and apologizing) and then I got some food at a cocktail-style dinner event that evening.
The second day was similar to the first, but with two notable differences. First, I attended a town hall meeting, where NeurIPS attendees were able to voice their concerns to the conference organizers. Second, in the evening, there was a Disability in AI event, which is a newer affinity group like the Queer in AI and Black in AI groups. At those two events, I met some of the people who I had been emailing earlier to ask about and arrange closed captioning on videos and sign language interpreting services. The Disability in AI panel talked about how to make the conference more accessible to those with disabilities. The panel members spoke about their experiences with disabilities — either personal or from a friend/relative — some of which were more severe than others. There’s some delicacy needed when describing one’s disability, such as to avoid insulting others who might have a more severe form of the disability and to avoid revealing disabilities that are hidden (if that’s important, for me it’s the opposite), but I think things proceeded OK.
I used a mix of captioning and sign language interpreting services at NeurIPS. You can find videos of NeurIPS talks on SlidesLive, complete with (some) closed captioning, but it’s not the best. The interface for the captions seems pretty unusable — it strangely was better during live recordings, when the captioning was automated. Scrolling through the myriad of workshop and conference videos on SlidesLive is also annoying. This week, I plan to write some feedback to SlidesLive and the NeurIPS conference organizers offering some advice.
I requested the interpreting for specific events where I would be walking around a lot, such as in the poster sessions, and it worked pretty well considering the stifling crowds. There was also another student at the conference who brought a team of two interpreters, so on occasion we shared the services if we were in the same events or talks. The panel discussed the idea of having a permanent sign language interpreting service from NeurIPS, which would certainly make some of my conference preparation easier! One person at the Disability in AI panel noted that “this conference is so large that we actually have two people using sign language interpreters” which is pretty much unheard of for an academic conference that doesn’t specialize in access technology or HCI more broadly.
It was nice to talk with some of the organizers, such as NeurIPS treasurer Marian Stewart Bartlett of Apple, who knew me before I had introduced myself. I also knew a little about Bartlett since she was featured in NeurIPS President Terrence Sejnowski’s Deep Learning book. Sejnowski was also briefly at the Disability in AI reception.
For the last two days of NeurIPS (December 13 and 14), we had workshops. The workshops might be the best part of NeurIPS; there are so many of them covering a wide variety of topics. This is in contrast to some other conferences I’ve attended, where workshops have been some of the least interesting or sparsely-attended portions of the conference. I don’t mean to say this negatively, it’s just my experience at various conferences. You can find the full list of workshops on the conference website, and here are the ones that seemed most interesting to me:
- Learning with Rich Experience
- Retrospectives: A Venue for Self-Reflection in ML Research
- Machine Learning for Autonomous Driving
- Bayesian Deep Learning
- Robot Learning: Control and Interaction in the Real World
- Tackling Climate Change with Machine Learning
- Fair ML in Health Care
- Deep Reinforcement Learning
I attended portions of two workshops on December 13: “Learning with Rich Experience” and “Retrospectives.” The former featured talks by Raia Hadsell of DeepMind and Pieter Abbeel of UC Berkeley. By “rich experience,” I think the workshop focuses on learning not just from images, but also videos and language. Indeed, that seems to have been featured in Hadsell and Abbeel’s talks. I would also add that John Canny has a few ongoing projects that incorporate language in the context of explainable AI for autonomous driving.
The retrospectives workshop was quite a thrill. I was there for three main reasons: (a) to understand the perspective of leaders in the ML community, (b) because many of the presenters are famous and highly accomplished, and (c) the automated captioning system would likely work better for these talks than those with more dense, technical terms. Some of the talks were by:
- Emily Denton, a research scientist at Google, who has done a lot of ground-breaking work in Generative Adversarial Networks (GANs). Her talk was largely a wake-up call to the machine learning community in that we can’t ignore the societal effects of our research. For example, she called out a full conference paper at NeurIPS 2019 which performed facial reconstruction (not recognition, reconstruction) from voice.
- Zachary Lipton, a professor at CMU and well-known among the “debunking AI hype” community. I’m embarrassed that my only interaction with him is commenting on his book reading list here. I’m probably the only person in the world who engages in that kind of conversation.
- David Duvenaud, a professor at the University of Toronto whose paper on Neural Ordinary Differential Equations (ODEs) won the best paper award at NeurIPS 2018 and has racked up over 200 citations as of today. Naturally, his talk was on all the terrible things people have said about his work, including himself but also some journalists. Seriously, did a journalist really say that Duvenaud invented the concept of an ODE?!?!? They date back to the 1600s if not earlier.
Jürgen Schmidhuber also gave a talk in this workshop.

Jürgen Schmidhuber giving a talk about Predictability Minimization and
Generative Adversarial Networks at the "Retrospectives in Machine Learning"
workshop. Sorry for the terrible quality of the photo above. I tried to do a
panorama which failed badly, and I don't have another photo.
I don’t know why this workshop was assigned to be in a such a small room; I’m sitting in the back row in that photo. I think those who got actual chairs to sit on were in the minority. A few minutes after I took the photo above, Yoshua Bengio came and sat in front of me on the table, next to my iPad which was spitting out the SlidesLive captions. If Bengio was fuming when Schmidhuber dismissed GANs as a “simple application” of his 90s-era idea, he didn’t show it, and politely applauded with the rest of us after Schmidhuber’s talk.
In case you are new to this history, please see this NYTimes article and this Quora post for some context on the “Schmidhuber vs Hinton/LeCun/Bengio/Goodfellow” situation regarding GANs and other machine learning concepts, particularly because GANs are mentioned as one of Bengio’s technical contributions in his Turing Award citation.
Sometime in the middle of the workshop, there was a panel where Bengio, along with a few other researchers, talked about steps that could be done to improve the overall process of how research and science gets done today. Some of the topics that came up were: removing best paper awards, eliminating paper reviews (!!), and understanding how to reduce stress for younger researchers. It was refreshing to see Bengio talk about the latter topic about the pressure graduate students face, and Bengio also acknowledged that paper citations can be problematic. To put this in perspective, Bengio had the most Google Scholar citations in all of 2018, among all computer scientists, and I’m sure he was also the most cited across any field. As of today (December 22, 2019) Google Scholar shows that Bengio has 62,293 citations in 2018 and then 73,947 in 2019. Within 10 years, I would not be surprised if he is the most cited person of all time. There are a few online rankings of the most cited scholars, but most are a few years old and need updating. Joelle Pineau of McGill University brought up some good points in that while we may have high stress in our field, we are still far more fortunate than many other groups of people today, prompting applause.
Finally on the last day of the conference, the Deep Reinforcement Learning (DeepRL) workshop happened. This was one of the most, if not the most, popular NeurIPS workshop. It featured more than 100 papers, and unlike most workshop papers which are 2-4 pages, the DeepRL papers were full 8-page length papers, like normal conference papers. The workshop has a program committee size rivaling that of many full conferences! The highlights of the DeepRL workshop included, of course, AlphaStar from DeepMind and Dota2 from OpenAI. For the latter, OpenAI finally released their monstrous 66-page paper describing the system. Additionally, OpenAI gave a presentation about their Rubik’s cube robot.
NeurIPS 2019 concluded with a closing reception. The food and drinks were great, and amounted to a full dinner. During the closing reception, while music was playing nearby, Andrew Ng in his famous blue shirt attire was politely taking pictures with people who were lining up to meet him. I was tempted to take a picture of him with my phone but decided against it — I don’t want to be that kind of person who takes pictures of famous people. For his sake, I hope Ng wasn’t standing there for the entire four-hour reception!
Overall, after my four-day NeurIPS experience, here are my thoughts about networking:
- I think I was better than usual at it. NeurIPS is so large, and Berkeley is so well-represented, that there’s a good chance I’ll see someone I know when roaming around somewhere. I usually try to approach these people if I see them alone. I spoke with people who I had not seen in many years (sometimes as high as six years!), most of who were at Berkeley at some point.
- In a handful of cases, I made an appointment to see someone “at this coffee break” or “at this poster session”. Those require lots of preparation, and are subject to last-minute cancellations. I probably could have done a better job setting pre-arranged meetings, but the paper deadline I had just before coming meant I was preoccupied with other things.
- I tried to talk to anyone who was willing to talk with me, but the quality of my conversations depended on the person. I was approached by someone who is doing an online master’s program at a different university. While we had a nice conversation, there is simply no way that I would ever be collaborating with that person in the future. In contrast, it is much easier for me to talk at length with robotics PhD students from Stanford, CMU, or MIT.
In the morning of December 15, I explored Vancouver. Given my limited time, I decided to go for a run. (Yes, what a big surprise.) I hope I can come back here next year, and do more extensive running in Stanley Park. NeurIPS 2020 will return to this same exact place. My guess is that by booking two years in a row, NeurIPS could save money.

A morning run in Stanley Park, in chilly Vancouver weather.
NeurIPS 2019 did not have any extracurricular highlights like the visits to Skansen or City Hall that we had at IJCAI 2019, or like the dinner reception at ICRA 2018, but the real advantage of NeurIPS is that I think the caliber of science is higher compared to other conferences.
The convention center seemed fine. However, I didn’t see a lot of extra space, so I don’t know how much more NeurIPS can absorb when it returns to Vancouver in 2020.
Remember how I wanted to come back to Sydney? NeurIPS 2021 is going to be held there, so perhaps I can return to Sydney. Additionally, according to some discussion at the town hall meeting mentioned earlier, NeurIPS will be held in New Orleans in 2022 and 2023, and then it will be in San Diego in 2024. I am wondering if anyone knows how to find statistics on the sizes and capacities of convention centers? A cursory search online didn’t yield easily digestible numbers.
In terms of “trends,” there are too many to list. I’m not going to go through a detailed list of trends, or summaries of the most interesting papers that I have seen, because I will do that in future blog posts. Here are higher-level trends and observations:
- Deep reinforcement learning remains hugely popular, though still highly concentrated within institutions such as Google, DeepMind, OpenAI, Stanford, and Berkeley.
- Meta-learning remains popular and is fast-growing.
- Fairness and privacy are fast-growing and becoming extremely popular, especially with (a) reducing societal biases of machine learning systems, and (b) health care in all aspects. In addition, it is no longer an excuse to say “we are just scientists” or “we were not aware of machine learning’s unintended consequences”. This must be part of the conversation from the beginning.
- Climate change is another fast-growing topic, though here I don’t know what the trend is like, since I don’t read papers about climate change and machine learning. I didn’t attend the climate change workshop since it conflicted with the DeepRL workshop, but I hope there was least some work that combines machine learning with nuclear energy. Nuclear energy is one of the most critical and readily usable “carbon-free” technologies we have available.
- Industry investment in machine learning continues to be strong. No signs of an “AI Winter” to me … yet.
- Diversity and inclusion, transparency, and fairness are critical. To get some insights, I encourage you to read the NeurIPS medium blog posts.
It’s great to see all this activity. I’m also enjoying reading other people’s perspectives on NeurIPS 2019, such as those from Chip Huyen. Let me know if I’m missing any interesting blog posts!
You can find some of the pictures I took at NeurIPS in my NeurIPS 2019 Flickr album. They are arranged in roughly chronological order. In the meantime, there are still several other NeurIPS-related topics that I hope to discuss. Please stay tuned for some follow-up posts.
As always, thanks for reading!
Dense Object Nets and Descriptors for Robotic Manipulation
Machine learning for robotic manipulation is a popular research area, driven by the combination of larger datasets for robot grasping and the ability of deep neural networks to learn grasping policies from complex, image-based input, as I described in an earlier blog post. In this post, I review two papers from the same set of authors at MIT’s Robot Locomotion Group that deal with robotic manipulation. These papers use a concept that I was not originally familiar with: dense object descriptors. I’m glad I read these papers, because the application of dense object descriptors for robotic manipulation seems promising, and I suspect we will see a myriad of follow-up works in the coming years.
Paper 1: Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation (CoRL 2018)
This paper, by Florence, Manuelli, and Tedrake, introduced the use of dense descriptors in objects for robotic manipulation. It was honored with the best paper award at CoRL 2018 and got some popular, high-level press coverage.
The authors start the paper by wondering about the “right object representation for manipulation.” What does that mean? I view “representation” as the way that we encode data which we then pass as input to a machine learning (which means deep learning) algorithm. In addition, it would be ideal if this representation could be learned or formed in a “self supervised” manner. Self supervision is ideal for scaling up datasets, since it means manual labeling of the data is unnecessary. I’m a huge fan of self supervision, as evident by my earlier post on “self supervision” in machine learning and robotics.
The paper uses a dense object net to map a raw, full-resolution RGB image to a “descriptor image.” (Alternatively, we can call this network a dense descriptor mapping.) Concretely, say that function $f(\cdot)$ is the learned dense descriptor mapping. For an RGB image $I$, we have:
\[f(I) : \mathbb{R}^{H\times W\times 3} \to \mathbb{R}^{H\times W\times D}\]for some dimension $D$, which in this paper is usually $D=3$, but they test with some larger values, and occasionally with $D=2$.
I originally thought the definition of $f(I)$ must have had a typo. If we are trying to map a full resolution RGB image $I$ to some other “space” for machine learning, then surely we would want to decrease the size of the data, right? Ah, but after reading the paper carefully, I now understand that they need to keep the same height and width of the image to get pixel correspondences.
The function $f(I)$ maps each pixel in the original, three-channel image $I$, to a $D$-dimensional vector. The authors generally use $D=3$, and compared to larger values of $D$, using $D=3$ has the advantage in that descriptors can be visualized easily; it means the image is effectively another $H\times W\times 3$-dimensional image, so upon some normalization (such as to convert values into $[0,255]$) it can be visualized as a normal color image. This is explained in the accompanying video, and I will show a figure later from the paper.
What does the data and then the loss formulation look like for training $f$? The data consists of tuples with four elements: two images $I_a$ and $I_b$, then two pixels on the images, $u_a$ and $u_b$, respectively. Each pixel is therefore a 2-D vector in $\mathbb{R}^2$; in practice, each value in $u_a$ or $u_b$ can be rounded to the nearest pixel integer. We write $f(I_a)(u_a)$ for the channel values at pixel location $u_a$ in descriptor image $f(I_a)$. For example, if $f$ is the identity function and $I_a$ a pure white image, then $f(I_a)(u_a) = [255,255,255]$ for all possible values of $u_a$, because a white pixel value corresponds to 255 in all three channels.
There are two loss functions that add up to one loss function for the given image pair:
\[\mathcal{L}_{\rm matches}(I_a, I_b) = \frac{1}{N_{\rm matches}} \sum_{N_{\rm matches}} \| f(I_a)(u_a) - f(I_b)(u_b)\|_2^2\]and
\[\mathcal{L}_{\rm non-matches}(I_a, I_b) = \frac{1}{N_{\rm non-matches}} \sum_{N_{\rm non-matches}} \max\{0, M - \|f(I_a)(u_a) - f(I_b)(u_b)\|_2^2\}\]The final loss for $(I_a,I_b)$ is simply the sum of the two above:
\[\mathcal{L}(I_a, I_b) = \mathcal{L}_{\rm matches}(I_a, I_b) + \mathcal{L}_{\rm non-matches}(I_a, I_b)\]Let’s deconstruct this loss function. Minimizing this loss will encourage $f$ to map pixels such that they are close in descriptor space with respect to Euclidean distance if they are matches, and far away — by at least some target margin $M$ — if they are non-matches. (We will discuss what we mean by matches and non-matches shortly.) The target margin was likely borrowed by the famous hinge loss (or “max margin” loss) that is used for training Support Vector Machine classifiers.
Here are two immediate, related thoughts:
-
This is only for one image pair $(I_a,I_b)$. Surely we want more data, so while it isn’t explicitly stated in the paper, there must be an extra loop that samples for the image pair, and then samples the pixels in them.
-
But how many pixels should we sample for a pair of images? The authors say they generate about one million pixel pairs! So, if we want to split our matches and non-matches roughly evenly, this just means $N_{\rm matches} \approx 500,000$ and $N_{\rm non-matches} \approx 500,000$. Thus, any two images provide a huge training data, since the data has to include pixels, and thus we can literally randomly draw the pixels from the two images.
To be clear on the credit assignment, the above math is not due to their paper, but actually from prior work (Schmidt et al., ICRA 2017). The authors of the CoRL 2018 paper use this formalism to apply it to robotic manipulation, and provide some protocols that accelerate training, to which we now turn.

The image above concisely represents several of the paper’s contributions with respect to improving the training process of descriptors, and particularly in the realm of robotic manipulation. Here, we are concerned with grasping various objects, so we want descriptors to be consistent among objects.
A match for images $I_a$ and $I_b$ at pixels $u_a$ and $u_b$ therefore means that the pixels located at $u_a$ and $u_b$ point to the same part of the object. A non-match is, well, basically everything else. In the image above, matching pairs of pixels are in green, and non-matching pairs are in red.
Mandatory “rant-like” side comment: I really wish the colors were different. Seriously, almost ANY other color pairing is better than red-green. I wish conference organizers could ban pairings of red-green in papers and presentations.
There are several problems with simply randomly drawing pixels $u_a$ and $u_b$. First, in all likelihood we will get a non-match (unless we have a really weird pair of images), and thus the training data is heavily skewed. Second, how do we ensure that matches are actually matches? We can’t have humans label manually, as that would be horrendously difficult and time-consuming.
Some of the related points and contributions they made were:
-
By using prior work on 3D reconstruction and 3D change detection, the authors are able to isolate the pixels that correspond to the actual object. These pixels, whether or not they are matches (and it’s important to sample both matches and non-matches!), are usually more interesting than background pixels.
-
It is beneficial to use domain randomization, but it should be done on the background so that the learned descriptors are not dependent on background to figure out locations and characteristics of objects. Note how the previous point about masking the object in the image enables background domain randomization.
-
There are several strategies to enforce that the same function $f$ can apply to different object classes. An easy one is if images $I_a$ and $I_b$ have only one object each, and those objects are of different classes. Thus, every pair of sampled pixels among those two images is a non-match (as I believe all background pixels are considered non-matches).
There are a variety of additional contributions they make to the training process. I encourage you to read the paper to check out the details.

The majority of the experiments in the paper are for validating that the resulting descriptors make sense. By that, I mean that the descriptors are consistent across objects. For example, the same shoe, when seen from different camera perspectives, should have descriptors that are able to match the different components of the shoe.
The above image is illuminating. They use descriptors with $D=3$ and are able to visualize the descriptor images, shown in the second and fourth rows. Note that the colors in the descriptor images should not be interpreted in any way other than the fact that they indicate correspondence. That is, it would be equally appealing and satisfying to see the same descriptor images above, except with all the yellows replaced with greens, all the purples replaced with blue, and so on. What matters is that, among different images of the same object, we see the same color pattern for the objects (and ideally the background).
In addition, other ablation experiments show that their proposed improvements to the training process actually help. This is great stuff!
Their last experiment shows a real-world robot grasping objects. They are not learning a policy; given a target to grasp, they execute an open loop trajectory. What’s interesting from their experiment is that they can use descriptors to grasp the same part of an object (e.g., a shoe) even if the shoe is seen at different camera angles or from different positions. It even works when they use different shoes, since those still have the same general structure of a “shoe class” and thus descriptors can be consistent even among different class attributes.
Paper 2: Self-Supervised Correspondence in Visuomotor Policy Learning (arXiv 2019)
This paper can be viewed as a follow-up to the CoRL 2018 paper; unsurprisingly, it is by the same set of authors. Here, the focus is on using dense descriptors for training a visuomotor policy. (By “visuomotor” we mean a robot which sets “motor torques” based on image-based data.) The CoRL 2018 paper, in contrast, focused on simply getting accurate correspondences set up among objects in different images. You can find the arXiv version here and the accompanying project website here.
I immediately found something I liked in the paper. In the figure above, to the left, you see the most common way of designing a visuomotor policy. It involves passing the image through a CNN, and then getting a feature vector $\mathbf{z} \in \mathbb{R}^Z$. Then, it is concatenated with other non-image based information, such as end-effector information and relevant object poses. I believe this convention started with the paper by (Levine, Finn, et al., JMLR 2016), and indeed, it is very commonly used. For example, the Sim-to-Real cloth manipulation paper (Matas et al., CoRL 2018) used this convention. It’s nice when researchers think outside of the box to find a viable alternative.
Concretely, we get the action from the policy and the past set of observations via \(\mathbf{a}_t = \pi_\theta (\mathbf{o}_{0:t})\), and we have
\[\mathcal{O}_{\rm robot} \times \mathcal{O}_{\rm image} = \mathcal{O}\]representing the observation space. The usual factorization is:
\[\mathbf{z} = f_{\theta_v}(\mathbf{o}_{\rm image}) \; : \; \mathbf{z} \in \mathbb{R}^Z\] \[\mathbf{a} = \pi_{\theta_p}(\mathbf{z}, \mathbf{o}_{\rm robot}) \; :\; \mathbf{a} \in \mathcal{A}\]where $Z$ is of much smaller dimensionality than the size of the full image $\mathbf{o}_{\rm image}$ (height times width times channels). This is a logical factorization that has become standard in the Deep Learning and Robotics literature.
Now, what is the main drawback of this approach? (There better be one, otherwise there would be no need to modify the architecture!) Florence and Manuelli argue that we should try and use correspondence information when training policies. Right now, doing end-to-end learning is popular, as are autoencoding methods, but why not explicitly enforce correspondence information? One can do this by enforcing $\mathbf{z}$ to encode pose information via setting an appropriate loss function with a target vector that has actual poses.
I was initially worried. Why not automatically learn $\mathbf{z}$ end-to-end? It seems risky to try and force $\mathbf{z}$ to have some representation. Poses, to be sure, are intuitively ideal, but if there’s anything machine learning has taught us over the past decade, it is probably that we should favor letting the data automatically determine latent features. The argument in the paper seems to be that learning intermediate representations (i.e., the descriptors) with surrogate objectives is better with less data, and that’s a fair point.
Prior work has not done this because:
-
Prior work generally focuses on rigid objects, and pose estimation does not apply to deformable objects. I think “pose estimation” relies on assuming rigid objects. Knowing the 6 DoF pose of any point on the object means we know the full object configuration, assuming its shape is known beforehand.
-
While other prior work interprets $\mathbf{z}$ as encoding spatial information, it is not trained directly for correspondence.
The authors propose directly using dense correspondence models in the learning process. They suggest four options, showing that a lot is up to discretion of the designer (but I don’t see any extensive comparisons among their four methods). Let there be a dense descriptor pre-trained model $f_{\theta_v}^{\rm dense}(\cdot)$ that was trained as in their CoRL 2018 paper. We have:
\[\mathbf{z} = f^C(f_{\theta_v}^{\rm dense}(\mathbf{o}_{\rm image}), \{\mathbf{d}_i\}_{i=1}^{P})\]which provides the predicted location of descriptors and is used in three of their four proposed ways of incorporating correspondence with descriptors. We have $\mathbf{z} \in \mathbb{R}^{P \times D}$ where $P$ is the number of descriptors and $D$ is the descriptor dimension, usually two or three. Descriptors can be directly interpreted as 2D pixels or 3D coordinates, making $\mathbf{z}$ highly interpretable — a good thing as “interpretability” of feature vectors is something that everyone gets frustrated about in Deep Learning.
This raises an interesting question: how do we actually get \(\{d_1, \ldots, d_P\}\)? We can get a fixed reference image, say of the same object we’re considering, except in a different pose (that’s the whole point of using correspondences). Descriptors can also be optimized by backpropagation. Given the number of descriptors, which is a hyperparameter, the descriptors are combined with the image input to get $\mathbf{z}$. This “combination” is done with a “spatial softmax” operation. Like the normal softmax, the spatial softmax operation has no parameters but is differentiable. Hence, the objective used in the overall, outer loss function (which is behavior cloning, as the authors later describe) is used to pass though gradients via backpropagation, and then the spatial softmax is the local operation passing gradients back to the descriptors, which are directly adjusted via gradients. The spatial softmax operation is denoted with $f^C$, and the reference for it is attributed to (Levine, Finn, et al., JMLR 2016).
They combine correspondence with imitation learning, by using behavior cloning with a weighted average of $L_1$ and $L_2$ losses — pretty standard stuff. Remember again that for merging their work with descriptors, they don’t need to use behavior cloning, or imitation learning for that matter. It was probably just easiest for them to get interesting robotics results that way.
Their action space is
\[\mathbf{a} = (T_{\Delta, \rm cmd}, w_{\rm gripper}) \in \mathcal{A}\]where \(\mathcal{A} = SE(3) \times \mathbb{R}^+\). For more details, see the paper.
Some of their other contributions have to do with the training process, such as proposing a novel data augmentation technique to prevent cascading errors, and a new technique for multi-camera time synchronized dense spatial correspondence learning. The latter is used to help train in dynamic environments, whereas the CoRL 2018 paper was limited to static environments.
They perform a set of simulated and then real experiments:
-
Simulated Experiments: these involve using the DRAKE simulator. I haven’t used it before, but I want to learn about it. If it is not proprietary like MuJoCo, then perhaps the research community can migrate to it? They benchmark a variety of methods. (Strangely, some numbers are missing from Table I. I can understand why some are not tested, but not all of them.) They have many methods, with the differences arising from how each acquires $\mathbf{z}$. That’s the point of their experiments! Due to the simulated environments, they can encode ground truth positions and poses in $\mathbf{z}$ as an upper-bound baseline.
The experiments show that their methods are better than prior work, and are nearly as good as the ones with ground truth in $\mathbf{z}$. There is also some nice analysis involving the convex hull of the training data (which is applicable because of the 2D nature of the table). If data is outside of that convex hull, then effectively we see an “out of distribution” data point, and hence policies have to generalize. Policies with 3D information seem to be better able to extrapolate outside the training distribution than those with only 2D information.
-
Real-World Experiments: for these, they use a Kuka IIWA LBR robot with a parallel jaw gripper. As shown in the images below, they are able to get highly accurate descriptors. Essentially, one point on one object should be consistently labeled as the corresponding point on the object if it is in a different location, or if we use similar objects in the same class, such as using a different shoe type for descriptors trained on shoe-like objects.

They argue their method is better because they use correspondence — fair enough. For the experiment setup, their method is already near the limit of what can be achieved, since results are close to those of baselines with ground truth information in $\mathbf{z}$.
Closing Thoughts
Some thoughts and takeaways I have from reading these two papers above:
-
Correspondence is a fundamental concept for computer vision. Because we want robots to learn things from raw images, it therefore seems logical that correspondence is also important for robotic manipulation. Correspondence will help us figure out how to manipulate objects in a similar way when they are oriented at different poses and perspectives.
-
Self supervision is more scalable for large datasets than asking humans to manually label. Figuring out ways to automate labeling must be an important component of any proposed descriptor-based technique.
-
I am still confused about how exactly we can get pixel correspondences via depth images, camera poses, and camera intrinsics, as described in the paper. It makes sense to me with some vague intuition, but I need to code and experience the full pipeline myself to actually understand.
International Symposium on Robotics Research (ISRR) 2019, Day 5 of 5

A photo I took of our trip to Halong Bay. This was after our bus ride and
cruise, which brought us to a cave. The Halong Bay resort is in the background.
On October 10, the last official day of ISRR 2019, we had a day-long excursion to Halong Bay. I did not request remote captioning for this day because I do not know how it could possibly work for an outdoor drive and cruise with no WiFi, and I would rather be taking pictures with my phone than reading my iPad in detail.
We had a two-hour bus ride from the hotel in Hanoi to Halong Bay. I sat near the front and was able to understand the words our tour guide was saying. He was an amusing and engaging local who spoke fluent English. He gave a 15-minute history of Vietnam and commented on the wars with France (1946 to 1954) and America (1964 to 1975).
After his historical account, our tour guide said we were free to ask him questions. I immediately asked him how Vietnamese think of United States President Donald Trump.
He replied with a mix of both amusement and puzzlement: “Donald Trump is very … uh … strange. He’s like … uh … an actor. He’s … very different from other leaders.”
I do not disagree with his assessment! He said that when Trump and Kim visited the hotel we were at for their nuclear “summit,” local Vietnamese were all clamoring to get a view of the two leaders. He then concluded his answer to my question by saying that Vietnamese are not very political. Uh oh, I thought, though I did not press him on the issue. (I did not bring this up to avoid being a distraction, but my main concern over lack of political interest is if people will not fight to maintain the rights of themselves or their fellow citizens.)
Near the end of the bus ride, we had a quick stop at a jewelry store, where some conference attendees bought jewelry for their spouses. The quality of the jewelry looked great, but I’m obviously not an expert. The prices varied considerably, and I think the most expensive single piece of jewelry I saw on sale was 14,500 USD. Wow!
Shortly after our stop at the jewelry store, we finally arrived at the Halong Bay report. The area we went to seemed like a tourist destination, with lots of tall and nice-looking buildings compared to downtown Hanoi. I also noticed upon a closer look, however, that while the outsides of the buildings looked great, the insides looked like they were run down or under construction — it honestly felt slightly creepy. I also didn’t see a lot of tourists other than our group. I am not sure what the plan is regarding Halong Bay, but I hope these buildings are under construction rather than abandoned.
The tour guides split us into several groups, and each group went on a small cruise ship. On the ship, we ate a Vietnamese lunch, which included some similar dishes we had earlier at the conference, such as prawns and squid. Those two dishes are really popular in Vietnam! It is a lot different from my seafood diet in America, which I associate with “Salmon” or “Halibut.” We took a 30-minute tour of a cave, and then went back on our boats to return to the buses to Hanoi.
At Hanoi, I joined a few other students for dinner at the same place Barack Obama famously ate when he visited Vietnam. Unsurprisingly, the restaurant is filled with pictures of Obama and even has a menu item named “Combo Obama,” representing what he ate. I imagine that most people in Vietnam can recognize Obama in photos and know about him.
On the following day, October 11, I performed some final sight-seeing of Hanoi, and finally got to try out their famous coconut coffee, which blends coconut and black coffee. It was delicious, and I sipped it while sitting down in a tiny chair at the cafe where I purchased it, and used my Google Translate app to thank the employees there.
I also toured the Vietnamese Museum of National History. Most of the exhibits concerned Vietnam’s fights against foreign invaders, most notably the French and then (obviously) the Americans. After I spent an hour walking through the museum, I thought in awe about Vietnam’s transformation from war-torn territory to a rapidly developing country. Given all the diplomatic difficulties the United States has with countries such as Russia, China, North Korea, Iran, and Syria, the improved US-Vietnam relations give me hope that one day we can consider these countries allies, rather than adversaries.
On my trip back, I had a long layover at Incheon, so I first napped for a few hours in the “nap area” and then went to the Skydeck lounge to catch up on email, administrative work, and obviously writing these blog posts. It cost me 48 USD to stay in the Skydeck Lounge for six hours, but I think it was mostly worth the price, and essentially anyone with a boarding pass (even economy passengers like me) can access it. It is not as good as the Asiana Business Class lounge, but it is good enough for me.
Once the time came, I boarded my flight back to San Francisco, to return to normal life.
If you’re interested, I have a photo album of my trip on Flickr, with almost 200 photos taken. As always, thanks for reading.
International Symposium on Robotics Research (ISRR) 2019, Day 4 of 5

After the last batch of technical talks, the ISRR 2019 attendees gathered around in the Sofitel to take a group photo. It's now visible on the ISRR website!
The third full conference day was much easier on me, because I did not have to think about rehearsing my talk.
For today, I also did something I wish I had done earlier: taking pictures of students giving talks, and then emailing them the pictures. I sent all emails by the end of the day, and eventually heard back from all the recipients with appreciation. I hope they post them on their websites. I am not sure why I did not do this for all the student presenters, because this seems like an obviously easy way to “network” with them. I might be seeing these students in future conferences or employment settings.
The captioners struggled to understand some of the faculty speakers. They also told me two new issues: that there was an echo from the room, and that every time I type something into my iPad (e.g., when switching tabs) they hear it and it overrides the microphone’s sound. I am at a loss on why there was an echo in the room, and I was wondering why I did not know about the “iPad typing issues” beforehand. Once again, having some kind of checklist where I can go through common issues would be great.
Fortunately, the captioners were able to understand Peter Corke’s talk today, and his was among the most relevant to my research area. (Incidentally, Peter Corke was the chair for ICRA 2018 in Brisbane, which I wrote about in several blog posts here.) Hence, I enjoyed Corke’s talk; he contrasted the computer vision and robotics fields by describing the style of papers in each field, and proposed several “assertions” about how the robotics community can make more research progress, similar to how the computer vision community made substantial progress with ImageNet competitions.
Before the talks concluded, Oussama Khatib made a few announcements. He presented a few slides about the history of ISRR and the closely related conference on experimental robotics, ISER. He then made the grand reveal for where ISRR 2021 would be located. (Remember, this conference only happens once every two years.)
And … drum roll please: ISRR 2021 will be located in Zurich, Switzerland, from July 19 to 23! It will also be co-located with a few other robotics conferences at that time, along with a “Joint Robotics Congress” which I hope means we can talk with some policy makers from certain countries. I hope I can submit to, and attend, ISRR 2021!
We wrapped up the day with the farewell reception, which was a full dinner at the conference hotel (the Sofitel Legend Metropole). This was a fixed set menu of Vietnamese food, and included:
-
Crab soup, with the usual broth that’s standard in Vietnamese cuisine. Again, I suspect it is some kind of fish sauce.
-
Chicken salad with onions, sprouts, and herbs.
-
Fried prawns with passion fruit sauce and vegetable fried rice. These prawns were huge!
-
Sticky rice and lotus desserts.
-
Unlimited refills for beer and wine.
The seating situation was ideal for me, because I was sitting at a table in the corner, and only had one person, another student, next to me. A second person next to me would hypothetically increase the sound nearby by nearly a factor of two. The student was nice and I was able to communicate reasonably well. During the dinner, the captioners did a great job recording the conversations happening at my table. I applaud them for their performance that night. Discussions ranged from food in Vietnam, aspects of various robotics conferences, how to get in PhD programs, how to read research papers, details about Berkeley itself, and a bunch of other things I can’t remember.
After these great meals, I conclude that ISRR, though it may be a small conference, is leaving a strong impression for high quality food.
International Symposium on Robotics Research (ISRR) 2019, Day 3 of 5
Video of my talk at ISRR 2019. The YouTube version is
here.
Courtesy of Masayuki Inaba.
The second conference day proceeded in a similar manner as the first day, with a set of alternating faculty and then paper talks. Some issues that came up were self-driving cars (e.g., in Henrik Christensen’s talk), climate change (with the obligatory criticism of Donald Trump) and faculty taking leaves to work in industry (which has hurt academia). I also enjoyed Frank Park’s talk on model-based physics, which cited some of the domain randomization work that is essential to what I am doing lately.
In a shameless plug, the highlight of the day was me. OK, only joking, only joking.
Like the other paper presenters, I gave a rapid 5 minute presentation on my ISRR 2019 paper about robot bed-making. It’s really hard to discuss anything substantive in 5 minutes but I hope I did a reasonable job. I cut down my humor compared to my UAI 2017 talk, so there was not as much lauging from the audience. In my talk slides, I referenced a few papers by other conference attendees, which hopefully they appreciated. I will keep this strategy in mind for future talks, in case I know who is attending the talk.
The good news is that I have my talk on video, and you can see it at the top of this post. The video is courtesy of Professor Masayuki Inaba of the University of Tokyo. He was sitting next to me in the front row, and I saw that he was recording all the presentations with his phone. He graciously gave me the video of my talk. It is dark, but that’s due to the lighting situation in the room; it was also wreaking havoc on my attempts to get high quality pictures of presenters.
In the rare cases when I have a video of one of my talks, I always get nervous when watching it, because I see countless things that make me feel embarrassed. Fortunately, from looking at the video above, I don’t think I made a fool out of myself. What I like are the following:
-
My talk was five minutes flat, exactly the time limit. No, I am not good enough to normally hit the allotted time limit exactly. (I know the video is 5:04 but if you get rid of the 0.5 seconds at the start and the 3.5 seconds at the end, that’s the span of my actual talk.) Before giving this talk, I performed an estimated 20 practice talks total, about 8 of which involved this exact talk after several improvements and iterations, and my average time was 5:10.
-
I did a reasonably good job looking at the audience, and in addition, I looked at a variety of different directions (and not just to one person, for example). Spending an entire talk looking at one’s laptop is a sure way to make a talk boring and dis-engaging.
-
My speaking volume seems to be at roughly the right level. It is tricky because I was also wearing a microphone, but I don’t think people in the audience missed stuff I was saying.
-
I did not project many “uhm”s or other sounds that are indicative of not knowing what to say.
Here are some things I think I could do better:
-
I am not sure if my body movement is ideal. I normally have so much energy when I’m giving a talk that I can’t help but move around a lot. (I get slightly nervous in the minutes before my talk begins, but I think this is natural.) I think I did a reasonable job not moving side-to-side too much, which is a huge bad habit of mine. But I feel a bit embarrassed by my hand movement, since it seems like I perform an endless sequence of “stop sign like” movements.
-
Finally, I am not sure if this is just the way I talk or due to the microphone or video recording issues, but the automated captions did not perform as well as I would have hoped. True, it was correct in some areas, but I think if I had not given this talk, I would have a hard time understanding what I was saying!
I think that’s how I would assess myself. I will keep this for future reference when giving talks in the future.
Before coming to ISRR, I did not know each paper talk would have an additional minute left over for questions. Hopefully this can be clarified in future ISRR. We had questions after this, and one thing bears comment. I had spoken to the person managing the “robot learning” talks (the one my paper was in) that I was deaf and asked him to come next to me to repeat any questions from the audience. When the first person asked a question, I asked him to repeat it to me. But before he could do that, Ken instead came bursting forward and effectively took his spot, and repeated the question. He would do that for the other two questions. I appreciate Ken’s prompt response. Audience questions are a vanishingly small fraction of my conference experience, but they present the greatest difficulty when there is not an extra person around for assistance.
Later in my session, there was also another paper from Ken Goldberg’s lab about cloud robotics, with Nan Tian as the lead author.
We then had the interactive sessions, and here Ken stuck around by our station, helping to communicate with some of the other people. The first person who came to our station immediately rebuked me and vigorously pointed at my video. He said: That is not a bed! That is a table! That is not a bed! That is a TABLE! True, our “bed” is from a table, so I guess he was technically right?
After the interactive session, we had the banquet. This was in a reasonably nice looking building, with air conditioning machines rather than the fans that are ubiquitous in street restaurants of Hanoi. The conference chair asked that faculty and students try to sit next to each other, rather than split off into faculty-only or student-only groups.
I courageously tried most of the fixed set menu even if the food was not visually appealing to me. The food appeared to be, in order, crab soup (with fish sauce?), Vietnamese pomelo, squids with celery, prawns, and some chicken soup. I was struck by how much more “experienced” some of the other conference attendees were at eating the food. For example, I don’t eat prawns very much, so I was intently watching how others took apart the prawns and removed the meat with their utensils.
The restaurant was near the top of a building with different restaurants on each row, so I was able to take some nice pictures of Hanoi’s evening scene and all the pedestrians and motorcycles moving around. It was beautiful.