My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
RRE: A Game-Theoretic Intrusion Response and Recovery Engine
During the past two months, I have been reading more research papers after not doing so for much of the spring 2016 semester. One paper I recently read is RRE: A Game-Theoretic Intrusion Response and Recovery Engine, a February 2014 IEEE Transactions on Parallel and Distributed Systems paper written by four computer engineering researchers. As suggested by the publication venue, it’s a systems and networking paper, but there’s an interesting connection to Artificial Intelligence. It also looks like it has had a noticeable impact, with 106 Google Scholar citations today, which is good for a 2014 paper. In this post, I’ll provide a brief summary of the RRE paper.
The paper considers the scenario of defending a computer network system from outside intrusions, which for many reasons is very common and very important nowadays. The traditional way to do this is to have some administrators and IT staff inspect the system and respond to attacks. Unfortunately, this is slow and hard to scale, and attackers are becoming increasingly sophisticated, meaning that we need automated responses to preserve the availability and integrity of computer systems. Hence, we have the Response and Recovery Engine (RRE) as a possible solution.
Their proposed RRE uses a two-tiered design for handling local and global situations. At the local level, individual computers have their own RREs, which take as input Intrusion Detection System (IDS) alerts and Attack Response Trees (ARTs). IDS alerts are a well-known computer networking concept, but ARTs are part of their new research contribution. ARTs analyze possible combinations of attack consequences that lead to some intrusion of system assets (e.g., SQL servers) and are designed offline by experts. ARTs allow RREs to (a) understand the cause and effects of different system problems and (b) decide on appropriate security responses. Another important aspect of ARTs is that its root node, denoted \(\delta_g\), represents the probability that the overall security property it represents has been compromised. The value of \(\delta_g\) can be computed using straightforward probability recurrence rules, so long as nodes in the ARTs are assumed independent. The recurrence starts at the leaves of the ART, which each take as input a set of IDS alerts and use a Naive Bayes binary classifier to determine the probability that the leaf node property has happened or not.
Using these ARTs, the authors nicely transform the security problem into a Partially Observed Markov Decision Process (POMDP), which they technically call a Partially Observed Competitive Markov Decision Process (POCMDP). First, an ART with \(n\) leaf nodes is automatically converted to a standard (i.e., fully observed) Markov Decision Process. The states \(s\) are \(n\)-dimensional binary vectors, with one element for each leaf, and the value matching whatever the leaf node has in the ART. The set of actions \(A\) for this MDP is split into sets \(A_r\) and \(A_a\), representing the set of actions for the RRE and the attacker, respectively. These actions have the effect of changing the values in the ART leaves; responses generally result in more zeros, and attacks typically result in more ones. (ARTs are designed so that nodes tend to represent negative events, hence we want more zeros.) The transition probabilities are determined from prior data, and the reward function \(r(s,a,s')\) is customized so that it takes into account the probability difference in the security property (i.e., \((\delta_g(s) - \delta_g(s'))^{\tau_1}\) for \(0\le \tau_1 \le 1\)), as well as the cost of executing the action. Here’s a brief exercise left to the reader: why is \(\delta_g(s') \le \delta_g(s)\)?
After formulating the MDP, the paper suddenly reminds us that we don’t actually have full knowledge of our states \(s\) (which makes sense in reality). Thus, we are in the partially observed case. According to their formulation, the probability of being in a state \(s\), denoted as \(b(s)\), is
\[b(s) = \prod_{l \in \mathcal{L}}(1_{[s_l = 1]}\delta(l) + 1_{[s_l=0]}(1-\delta(l)))\]This makes sense and is consistent with the paper’s notation; I will leave it to the reader to review the paper if he or she wishes to verify this formula. They then outline how to solve the POMDP (based on their MDP formulation) using standard value iteration techniques. Note that they call their formulation a POCMDP (as stated earlier) because they add the “Competitive” word to the name, but I don’t think that is necessary. As I discussed near the end of this blog post on reinforcement learning, one can formulate a standard MDP in terms of a two-player adversarial game. They are simply making the distinction between action sets clearer here, perhaps for the benefit of the reader who is not familiar with Artificial Intelligence.
Another interesting note about their POCMDP formulation is that we do not actually need ARTs — the POCMDPs are all that is necessary, but they are harder to design and they have an exponential state space compared to the ARTs, so it is best to let experts design ARTs and automatically build the POCMDPs from it. This certainly makes sense from a practical perspective.
The process above is similar for the global case. The global RRE takes as input the recursively computed \(\delta_g\) values for each local RRE, the probability that the security property of the local assets have been compromised. It then uses these to automatically formulate a CMDP to help guide overall network priorities. To add finer-grained control over the states, the authors augment the system with fuzzy logic, allowing partial memberships. (See the Fuzzy Sets Wikipedia page for background on fuzzy sets.) This means they can combine information from local engines to determine a probability for a global security property. Their canonical example of the latter: is the network secure? Overall, this section of the paper is not as clear as the one describing local RREs, and while I understood the basics on how they used fuzzy logic, I wish there was enough space in the paper for a clearer explanation of how they form the global CMDP.
After their global RRE description, the authors present some brief experimental results on how long it takes to form the MDP models and on the runtime for RREs to compute an optimal response action. In general, their experiments are short and not that informative since they rely on randomly generated networks. To be fair, it is probably harder to run benchmarks in networking papers as compared to machine learning papers. In the latter case, we have standard datasets on which to test our algorithms.
The disappointing experiments notwithstanding, I enjoyed this paper. I fortunately did not need much networking or systems background to understand it, and it is nice to see different ways of how MDPs get formulated. It certainly falls prey to lots of simplifying assumptions, but I don’t see how that can be avoided for a research paper.
The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World
I recently finished The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World, by acclaimed computer science professor Pedro Domingos of the University of Washington. The Master Algorithm is aimed at a broad but well-educated audience and attempts to serve as an intermediate between dense, technical textbooks and simple, overly-hyped 800-word “AI IS GOING TO DESTROY PEOPLE” newspaper articles. The main hypothesis is that there exists a universal algorithm for solving general machine learning problems: the master algorithm. Or, as Domingos humorously puts it, one algorithm to rule them all. For background information, Domingos provides a historical overview of five “tribes” of machine learning that we must unify and understand to have a chance at unlocking the master algorithm. In general, I think his master algorithm idea has merit, and his explanation of the five areas of machine learning are the most important and valuable parts of the book. Nonetheless, as there are fundamental limitations on learning a technical subject like machine learning in a book with just 300 (non-mathematical) pages, this book is bound to disappoint a few readers. The explanation of the hypothetical master algorithm is also limited since it relies almost entirely on Domingos’ decade-old research. In addition, some of the implications on society seem far fetched.
I was familiar with most of the material in this book beforehand, but as stated earlier, I still found Domingos’ organization of machine learning into five tribes to be immensely useful for understanding the field. His five tribes are: symbolists, connectionists, evolutionaries, Bayesians, and analogizers. I would never have thought about organizing machine learning this way, because I have limited experience with evolutionaries (i.e., people who use genetic programming) and because whenever I try to study logic and reasoning (i.e., what the symbolists do) I struggle to avoid falling asleep. I have been able to study logic, though, as shown in this long blog post.
I am most familiar with the other three areas Domingos lists. The connectionists are dominating machine learning nowadays because they use neural networks. (Ever heard of “deep learning,” anyone?) The Bayesians used to dominate; these are the people who use graphical models. The analogizers use the nearest neighbor and support vector machine algorithms. For all three of these tribes, I have covered corresponding topics in previous blog entries (e.g., see this post for a discussion on SVMs).
Given the constraints of 30 pages per tribe, Domingos explains each of them remarkably well. Having studied these in mathematical detail, I find it enjoyable to just relax, avoid the math, and understand the history: who invented which algorithm, what were competing trends, and similar stories. In addition to the five tribes, Domingos goes over other important concepts in machine learning and artificial intelligence, including Expectation-Maximization and reinforcement learning. Domingos then describes his thoughts on a universal algorithm, invoking his own research (Markov logic networks) in the progress. Finally, he discusses the implications of improved machine learning on our lives.
For the sake of a general audience, Domingos avoids mathematical details and relies on examples and analogies. This is fine, and both Domingos and I agree that it is possible to understand some machine learning without math. I probably do not agree with that statement as much as Domingos does, though; I really need to go over all the math details for me to understand an algorithm, and other readers with my mindset can get disappointed.
I also think his attempts at explaining the master algorithm at the end fall prey to excessive storytelling. After his long, adventure-related metaphor, I was (and still am) confused about how to effectively build upon his Markov logic network work to get a real master algorithm. Regarding the implications of the master algorithm on human life, that chapter felt more fantasty than reality to me, and I can’t see the kind of stuff Domingos says happening in the near future. For instance, Domingos says that since AI might take over human labor, we will need to use a “universal basic income,” but that would not necessarily be the best thing to do and I can’t see how this will be politically viable (it’s possible, though, but I’m probably thinking on a longer time horizon than Domingos).
I don’t mean for the last two paragraphs to sound overly critical. I think The Master Algorithm is interesting and I would recommend it to those who would like to learn more about computer science. I would not, however, say it is among my top-tier favorite books. It’s a decent, solid, but not once-in-a-generation, and I think that’s a fair characterization.
Thoughts on Isolation: Three Difficult Years
I have now had depression for almost three years. It started in August 2013, when I became more conscious of all the isolation I was experiencing in college. A difficult senior year that followed means that I have some contradictory feelings about my alma matter.
I assumed it would be easier for me to socialize in graduate school since the other students would be more like me. But after two years in Berkeley, my depression has worsened and it has been enormously challenging for me to focus on work. I never realized that, during their first summer, graduate students were supposed to spend days alone without talking to anyone. Does anyone remember that line from The Martian movie when one man, wondering about how the astronaut survives on Mars alone, ponders: “What does that do to a man?” Every day, I need to decide: if people are going to ask me how I feel, do I lie and say “fine”, do I say “no” and change the subject, or do I take an intermediate stance like “I’m feeling a 6 out of 10 today” and adding in some jokes. Since it’s funnier, I default to the third. Perhaps I should start using Donald Trump jokes — I can usually think of a way to incorporate him in conversations.
This isn’t completely new to me. Technically my depression began in seventh grade, but it was more sporadic back then. During seventh grade, I became conscious of my bottom-of-the-pack social standing by seeing seemingly all other students having their own group of friends. At that time, there were only two other deaf students in my cohort, and both were far more popular than me (but they also had better hearing). I tried to fight my way up the hierarchy by studying what the other students did: their clothing styles, their facial expressions, their style of jokes, or anything that I thought would help me advance socially. Unfortunately, I was not successful, and eleven years later, I am still trying to figure out the secrets.
I thought that new graduate students would be able to find a group and be supervised by more experienced students or postdocs to get a fast start on research. At the very least, they would have some cohort of students of the same year (or plus/minus one year) with matching research interests, where if not outright working together, they could talk and bounce off ideas. Given how hard it has been for me to be involved in that, though, I wonder how students get that in the first place. It’s true that it has gotten noticeably better this semester, so hopefully I have stuff to look up to. Even so, I do not know why I was admitted to the PhD program at all, and I also believe it was a mistake for me to attend Berkeley (just like it was a mistake to attend Williams).
There’s a lot of stuff that people say about the Berkeley graduate school experience, whether it’s in person during visit days or on a Berkeley website. I know some of it is for advertising (e.g., to exaggerate, “graduate students love Berkeley!”) which is fine with me. Any school would need to do that. From personal experience, however, some of the material online is misleading if not completely wrong.
I know depressed graduate students aren’t exactly a scarce resource. I’m trying to fight my way out of it, but it’s not that easy. Some people may disagree with this, but I think it’s harder to do good, research-quality work while depressed. The faculty may not have had this experience since they were the stars in graduate school and, presumably, non-depressed, but not everyone is like that. I know there are people who enjoy graduate school. Yet it feels weird for me to be physically nearby but feel so distant simultaneously. How are they enjoying their experience so much?
I get a lot of emails that relate to trying to improve the graduate school experience. Examples include graduate student surveys for enhancing the well-being of students and invitations to student events/parties. The main thing I want to do, however, is get good research done in a research group. That’s going to help me more than going to a random student event. In addition, attending these events usually means I need to ask a sign language interpreter to come with me, and I feel very awkward trying to socialize with the interpreter.
I have thought about temporarily leaving graduate school to recover, but this would not be a guaranteed solution. I obviously don’t have a group of friends to start a company, so it’s probably best to work at a large, well-established company. Then again, the same concern arises: what if I can’t figure out how to mesh with my group there (people do work in groups, right?). The same concern arises, and the people in industry might also be older and have more diverging interests. If I come back to graduate school, I’ll continue to feel like I am behind in research for taking time off.
I am well aware that I could come under criticism for this blog post. I read more foreign policy books and there are lots of people in this world suffering. Just look at the horrible, gut-wrenching crisis in Syria, where people are under assault by the government, young men feel compelled to join gangs, and young women have to resort to prostitution for money. Even in the United States, there are so many people struggling financially, and as Berkeley can attest, there are too many homeless people in this country. Why do I have the right to feel depressed, especially when so many people would like to be a Berkeley graduate student?
By that logic, though, anyone who has a job in the United States can’t complain, because there’s always someone in the world who would want that position. I also do not think my desires are that out of line. If other students worked alone, then I would not necessarily feel as bad as I do now. Just to be clear, I know I could have done some stuff better over the past few years, such as working even harder. Some of the blame is always going to lie with me. Though there is some business incentive to only prioritize a few students, however, I would like to think that the department wants to put its students in positions where they are most likely to succeed.
It is a good thing I won’t be in Berkeley this summer. Given how much I detested last summer, I don’t want to think about how much worse I’d feel if I stayed in Berkeley. Fortunately, things improved for me last semester, and so my goal for the summer is to continue that trend, and hopefully, to prevent the depression from dragging on for a fourth year.
Review of Applications of Parallel Computing (CS 267) at Berkeley
Last semester, I took Applications of Parallel Computing (CS 267), taught by Jim Demmel. This is one of those graduate courses that we can expect will be offered every year for the near future. In fact, CS 267 has been offered almost every year since 1994, and strangely enough, it seems to have always been in the spring semester. Amazingly, the website for the 1994 class is still active!
The reason why CS 267 continues to be offered is because parallel programming has become more important recently. I can provide two quick, broad reasons why: because virtually all computers nowadays are parallel (i.e., have parallel processors), and because Moore’s Law1 has started to slow down, so that future speed-ups will not “come for free” as it did with Moore’s Law, but will come with parallelism. But parallelizing existing code is hard. Hence why this class exists.
CS 267 is aimed at a broad audience, so the student body is very diverse. There are computer scientists of course, but also mechanical engineers, environmental engineers, bioengineers, political scientists, etc. The slides on the first day of class said that we had 116 (yes, 116, you can tell how popular things are getting) students enrolled, including 16 undergrads and 64 EECS students. Computer scientists, especially those in graphics/AI/theory like to take this course to fulfill prelim breadth requirements. See the following screenshot for why:

We have to take at least one course in three out of the six areas above, with one “above the line” and one “below the line.” CS 267 is in the “Programming” category and “below the line,” making it a good match for AI people, which is why you see a lot of those in the class. Incidentally, our “Homework 0” was to write a short summary about ourselves, and these were posted on the website. I wish more classes did this.
Due to its popularity, CS 267 has video lectures. I talked about this earlier when I explained why I didn’t show up to lectures. (Actually, I’m still catching up on watching the video lectures … sorry.) Fortunately, the captioners did a better job than I expected with getting captions on the videos.
Regarding the workload in the class, there were four main things: three homeworks and a final project.
Homework 1: Optimize Matrix Multiplication. We had to implement matrix multiplication. We were judged by the speed of \(C = AB\) for dense, random matrices \(A\) and \(B\), on a nearby supercomputer. The naive \(O(n^3)\) algorithm is easy to describe and implement, but is unacceptably slow. To speed it up, we had to use low-level techniques such as compiler intrinsics, loop unrolling, blocking, etc. The thing I probably learned the most out of this assignment is how to use these operations to make better use of the cache. I also credit this assignment for giving me a glimpse into how real, professional-grade matrix libraries work. We had assigned teams on this homework; the course staff paired us up based on a course survey. It’s probably best to say you’re a bad C programmer in the survey so you can get paired up with an “expert”.
Homework 2: Parallelize Particle Simulation. It’s helpful to look at the GIF of the particle simulation:

This is implemented by having an array of particles (which themselves are C structs). During each
iteration, the particle positions are updated based on simple forces that cause particles to repel.
We were provided an \(O(n^2)\) serial (i.e., not parallel) implementation, where \(n\) is the number
of particles. This assignment involved four parts: implementing (1) an \(O(n)\) serial version, (2)
an \(O(n)\) OpenMP version (i.e., shared memory), (3) an \(O(n)\) MPI version (i.e., distributed
memory), and (4) an \(O(n)\) GPU-accelerated version. For this assignment, obviously do (1) first,
since the others are based on that. But don’t use linked lists, which I tried in my first version.
For (2), OpenMP isn’t as hard as I thought, and most of it involves adding various pragma omp
statements before for loops. For (3), MPI can be challenging, so do yourself a favor and read these
excellent blog posts. For (4) … unfortunately, one of my partners did that, not me. I did
(1), (2), and (3), but I wish I had done some GPU coding.
Homework 3: Parallelize Graph Algorithms. We needed to parallelize de Novo Gene Assembly. No biology background is needed, because the assignment description is self-contained. Our job was to parallelize their provided serial algorithm, which constructs and traverses over something called a De Brujin graph. We had to use an extension of the C language called UPC, developed by researchers here in Berkeley, but fortunately, it’s not that much more complicated than MPI, and there are some guides and long presentation slides online that you can read and digest. UPC tries to provide both shared and distributed memory, which can be a little hard to think about, so you really want to make sure you know exactly what kind of data is being transferred when you write UPC statements. Don’t assume things work as you expect!
For all three assignments, a write-up is needed, so be sure to have time before the deadline to
write it. In terms of debugging, my best advice is to keep running the code with a bunch of
printf(...) statements. Sorry for lack of better ideas. But a fair warning — there’s a
limit to how often we can use the supercomputer’s resources! This is something I wish the course
staff had clarified early in the semester, rather than waiting until a few people had exceeded
their quotas.
Final Projects. As usual, we had final projects. Our format was somewhat unusual, though: we gathered in the Wozniak Lounge from 8:10AM to 11:00AM (early for some people, but not for me). The first half of this time slot consisted of a series of 1.5-minute presentations. For my talk, I discussed an ongoing research project about parallel Gibbs sampling, but my slide probably had too much stuff in it for a 1.5-minute talk. (I also didn’t realize how low the screen resolution would be until the presentation date.) I was tempted to add some humor by starting out with one separate slide that said “MAKE GIBBS SAMPLING GREAT AGAIN”, but for some reason I decided against it. Perhaps that was mistaken, since I think the presentations could have been a little funnier. After this, we had the usual poster session.
Overall, I wouldn’t say that CS 267 is among the more challenging CS courses2, but it can be difficult for those with limited C programming experience. Some students, especially undergrads, might be somewhat annoyed at the lack of grading information, because we didn’t get grades on our final project, and I don’t even know what grade I got on the third homework. The grading is lenient as usual, though, so I wouldn’t worry much about it. Also, during the homeworks, it can be easy to not do much work if you rely on your partners; don’t do that! You get more out of the class if you take the lead on the homeworks and do as much as you can.
-
Roughly speaking, Moore’s Law states that the number of transistors in an integrated circuit increases at a fixed rate, usually stated as doubling every 1.5 years. ↩
-
I’m talking about the assignments here, not the lectures. The assignments are generally doable, but the lectures are impossible to follow. ↩
The Obligatory "Can You Read Lips?" Question
It’s often one of the first things people ask when they meet me, whether it’s at some orientation event, a new doctor appointment, or some other setting:
“Can You Read Lips?”
These people know that I’m deaf. Perhaps I told them immediately (rather than dragging it out), perhaps they found out from someone else, or perhaps they saw my hearing aids and drew the logical conclusion. But they know in some way. In addition, my guess is that the people asking me that question also don’t have much experience communicating with other deaf and hard of hearing people.
Taking that last assumption into account, I’m often surprised at how many have defaulted to this as their first nontrivial statement to me (or more generally, when meeting their first deaf person). I don’t know where this phenomenon comes from. Was there some notable event or movement that popularized this notion? I can’t figure out anything matching this after a brief round of Googling.
After thinking for a while, it probably comes down to this: hearing people, when they think about deaf people, might first and foremost think about sign language. After all, it’s highly visible, as anyone who’s had a class with me can attest. If I were hearing, I imagine I would be fascinated during my first encounter with sign language.
But then a hearing person might wonder: how do deaf people communicate with hearing people without interpreters present? This must be where the myth (as I’ll explain shortly) of lip reading appeared.
To get back to the initial question of this post, and in part to relieve any reader of this blog post who might need to meet me for the first time later of asking me this question: yes, I can lip read. Now let’s go over the caveats. Here’s a very incomplete list:
- Is the person who I’m communicating with trying to move his or her lips carefully? That makes it easy to lip read. At Williams, I was once part of a little lip reading exercise to see if we could read lips. But that fails to generalize to real conversations, because we tried hard to move our lips. Most people do not have that in mind when talking, especially because it’s usually not needed. And many people slur or speak in a way that inhibits lip movement.
- Am I face-to-face with that person, in clear lighting? For obvious reasons, it’s easiest to lip read in those situations, and much harder when, for instance, we’re in a haunted house (sorry, I couldn’t think of a better example). From personal experience, it is also harder to lip read with someone when that person is talking over a screen, e.g., in Skype, even assuming excellent Internet connections.
- Is the person a foreigner? On top of the already challenging task of understanding accents, part of the difficulty in communicating with them is that they may lack intuitive knowledge of certain frequencies when uttering words (as one of my statistics professors put it when we discussed this once). For instance, my grandmother is a Japanese-American and I have no hope of reading her lips at all.
- Am I trying to lip read in a group conversation? On the one hand, lip-reading theoretically should easier than trying to listen normally because it “only” involves looking at one person’s mouth. In reality, group conversations often have sudden shifts in who does the talking, or people can talk simultaneously. Finally, most people will not be face-to-face with me.
Having said all that, under the best of circumstances, I can do some lip reading. I do not, however, think my lip reading abilities are multiple standard deviations better than those of the average hearing person, especially because I haven’t had any formal lip reading training.
But more training might not matter. Even if my skills were as good as humanly possible, the above list of caveats should make a convincing case that lip reading as a panacea for deaf people’s communication difficulties is a myth.
Ava, the company I introduced in last week’s blog post, has their own blog, and mentions lip reading in a post titled “Let’s Talk About Tom, Your Colleague You Haven’t Heard About” (or as I like to think of it, “Daniel”). They mention:
Actually reading lips is really, really hard. Despite year-long trainings for that, you only can hope to get 20–30% better. What’s even worse? In English, only 30% can be distinguished with lipreading.
These numbers are almost certainly arbitrary and wildly inaccurate, but their general point is correct: lip reading just cannot convey all the information someone says. It is much less effective than just hearing someone say something. If, given the choice between no lip reading skills and wearing my current hearing aids, or having lots of lip reading skills but no hearing aids at all, I would prefer the former scenario. My hearing aids, while an imperfect remedy, are far more helpful than lip reading can and will be.
In the future, if anyone emails me to ask the obligatory “Can I Lip Read?” question, I will send them the link to this blog post. If it’s in person … I’ll provide a 20-second version of this post. This doesn’t mean I dislike it when people ask these questions. To the contrary, I actually take a slightly positive stance towards it. Yes, it gets tiring, but at least it seems like people are curious and genuinely want to be helpful, and in some cases we can get the conversation going to other, more interesting topics.
Review of Convex Optimization and Approximation (EE 227C) at Berkeley
This past semester, I took Convex Optimization and Approximation (EE 227C). The name of the course is slightly misleading, because it’s not clear why there should be the extra “and approximation” text in the course title. Furthermore, EE 227C is not really a continuation of EE 227B1 since 227B material is not a prerequisite. Those two classes are generally orthogonal, and I would almost recommend taking then in the reverse order (EE 227C, then EE 227B) if one of the midterm questions hadn’t depended on EE 227B material. More on that later.
Here’s the course website. The professor was Ben Recht, who amusingly enough, calls the course a different name: “Optimization for Modern Data Analysis”. That’s probably more accurate than “Convex Optimization and Approximation”, if only because “Convex Optimization” implies that researchers and practitioners are dealing with convex functions. With neural network optimization being the go-to method for machine learning today, however, the loss functions in reality are non-convex. EE 227C takes a broader view than just neural network optimization, of course, and this is reflected in the main focus of the course: descent algorithms.
Given a convex function \(f : \mathbb{R}^n \to \mathbb{R}\), how can we find the \(x \in \mathbb{R}^n\) that minimizes it? The first thing one should think of is the gradient descent method: \(x_{k+1} = x_{k} - \alpha \nabla f(x_k)\) where \(\alpha\) is the step size. This is the most basic of all the descent methods, and there are tons of variations of it, as well as similar algorithms and/or problem frameworks that use gradient methods. More generally, the idea behind descent methods is to iteratively update our “point of interest”, \(x\), with respect to some function, and stop once we feel close enough to the optimal point. Perhaps the “approximation” part of the course title is because we can’t usually get to the optimal point of our problem. On the other hand, in many practical cases, it’s not clear that we do want to get the absolute optimal point. In the real world, \(x\) is usually a parameter of a machine learning model (often written as \(\theta\)) and the function to minimize is a loss function, showing how “bad” our current model is on a given training data. Minimizing the loss function perfectly usually leads to overfitting on the test data.
Here are some of the most important concepts covered in class that reflect the enormous breadth of descent methods, listed roughly in order of when we discussed them:
-
Line search. Use these for tuning the step size of the gradient method. There are two main ones to know: exact (but impractical) and backtracking (“stupid,” according to Stephen Boyd, but practical).
-
Momentum and accelerated gradients. These add in extra terms in the gradient update to preserve “momentum”, the intuition being that if we go in a direction, we’ll want to “keep the momentum going” rather than throwing away information from previous iterations, as is the case with the standard gradient method. The most well-known of these is Nesterov’s method: \(x_{k+1} = x_k + \beta_k(x_k - x_{k-1}) - \alpha_k \nabla f(x_k + \beta_k(x_k - x_{k-1}))\).
-
Stochastic gradients. These are when we use approximations of the gradient that match in expectation. Usually, we deal with them when our loss function is of the form \(f(x) = \frac{1}{n}\sum_{i=1}^nf_i(x)\), where each \(f_i\) is a specific training data example. The gradient of \(f\) is the gradient of the individual terms, but we can use a random subset each iteration and our performance is just as good and much, much faster.
-
Projected gradient. Use these for constrained optimization problems, where we want to find a “good” point \(x\), but we have to make sure it satisfies the constraint \(x \in \Omega\) for some space \(\Omega\). The easiest case is when we have component-wise linear constraints of the form \(a \le x_i \le b\). Those are easy because the projection is as follows: if \(x_i\) exceeds the range, either decrease it to \(b\), or increase it to \(a\), depending on which case applies.
-
Subgradient method. This is like the gradient method, except this time we use a subgradient rather than a gradient. It is not a descent direction, so perhaps this shouldn’t be in the list. Nonetheless, the performance in practice can still be good and, theoretically, it’s not much worse than regular stochastic gradient.
-
Proximal point. To me, these are non-intuitive. These methods combine a gradient step with a proximal method. They also perform a projection.
Then later, we had special topics, such as Newton’s method and zero-order derivatives (a.k.a., finite differences). For the former, quadratic convergence is nice, but the method is almost useless in practice. For the latter, we can use it, but avoid if possible.
As mentioned earlier, Ben Recht was the professor for the class, and this is the second class he’s taught for me (the first being CS 281A) so by now I know his style well. I generally had an easier time with this course than CS 281A, and one reason was that we had typed-up lecture notes released beforehand, and I could read them in great detail. Each lecture’s material was contained in a 5-10 page handout with the main ideas and math details, though in class we didn’t have time to cover most proofs. The notes had a substantial amount of typos (which is understandable) so Ben offered extra credit for those who could catch typos. Since “catching typos” is one of my areas of specialty (along with “reading lecture notes before class”) I soon began highlighting and posting on Piazza all the typos I found, though perhaps I went overkill on that. Since I don’t post anonymously on Piazza, the other students in the class also probably thought it was overkill2.
The class had four homework assignments, all of which were sufficiently challenging but certainly doable. I reached out to a handful of other students in the class to work together, which helped. A fair warning: the homeworks also contain typos, so be sure to check Piazza. One of the students in class told me he didn’t know we had a Piazza until after the second homework assignment was due, and that assignment had a notable typo; the way it was originally written meant it was unsolvable.
Just to be clear: I’m not here to criticize Ben for the typos. I think it’s actually a good thing, because he has to start writing these lecture notes and assignments from scratch. This isn’t one of those courses that’s been taught every year for 20 years and where Ben can reuse the material. The homework problems are also brand new questions; one student who took EE 227C last spring showed me his assignments which were vastly different.
In addition to the homeworks, we had one midterm just before spring break. It was a 25.5-hour take home midterm, but Ben said students should be able to finish the midterm in two hours. To state my opinion: while I agree that there are students in the class who can finish the midterm in less than two hours, I don’t think that’s the case for the majority of students. At least, it wasn’t for me — I needed about six hours — and I got a good score. The day we got our midterms back, Ben said that if we got above an 80 on the midterm, we shouldn’t talk to him to “complain about our grades.”
Incidentally, the midterm had four questions. One question wasn’t even related to the material that much (it was about critical points) and another was about duality and Lagrange multipliers, so that probably gave people like me who took EE 227B an advantage (these concepts were not covered much in class). The other two questions were based more on stuff directly from lecture.
The other major work component of EE 227C was the usual final project for graduate-level EE and CS courses. I worked on “optimization for robot grasping”, which is one of my ongoing research projects, so that was nice. Ben expects students to have final projects that coincide with their research. We had a poster session rather than presentations, but I managed to survive it as well as I could.
My overall thought about the class difficulty is that EE 227C is slightly easier than EE 227B, slightly more challenging than CS 280 and CS 287, and around the same difficulty as CS 281A.
To collect some of my thoughts together, here are a few positive aspects of the course:
- The material is interesting both theoretically and practically. It is heavily related to machine learning and AI research.
- Homework assignments are solid and sufficiently challenging without going overboard.
- Lecture notes make it easy to review material before (and after!) class.
- The student body is a mix of EE, CS, STAT, and IEOR graduate students, so it’s possible to meet people from different departments.
Here are the possibly negative aspects of EE 227C:
- We had little grading transparency and feedback on assignments/midterms/projects, in part because of the relatively large class (around 50 students?) and only one GSI. But it’s a graduate-level course and my GPA almost doesn’t matter anymore so it was not a big deal to me.
- We started in Etcheverry Hall, but had to move to a bigger room in Donner Lab (uh … where is that?!?) when more students stayed in the class than expected. This move meant we had to sit in cramped, auditorium-style seats, and I had to constantly work to make sure my legs didn’t bump into whoever was sitting next to me. Am I the only one who runs into this issue?
- For some reason, we also ended class early a lot. The class was listed as being from 3:30-5:00PM, which means in Berkeley, it goes from 3:40-5:00PM. But we actually ran from 3:40-4:50PM, especially near the end of the semester. Super Berkeley time, maybe?
To end this review on a more personal note, convex optimization was one of those topics that I struggled with in undergrad. At Williams, there’s no course like this (or EE 227B … or even EE 227A!!3) so when I was working on my undergraduate thesis, I never deeply understood all of the optimization material that I needed to know for my topic, which was about the properties of a specific probabilistic graphical model architecture. I spent much of my “learning” time on Wikipedia and reading other class websites. After two years in Berkeley, with courses such as CS 281A, CS 287, EE 227B, and of course, this one, I finally have formal optimization education, and my understanding of related material and research topics has vastly improved. On our last lecture, I asked Ben what to take after this. He mentioned that this was a terminal course, but the closest would be a Convex Analysis course, as taught in the math department. I checked, and Bernd Sturmfels’s Gemoetry of Convex Optimization class would probably be the closest, though it looks like that’s not going to be taught for a while, if at all. In the absence of a course like that, I’m probably going to shift gears and take classes in different topics, but optimization was great to learn. I honestly felt like I enjoyed this course more than any other in my time at Berkeley.
Thanks for a great class, Ben!
-
For some reason, Convex Optimization is still called EE 227BT instead of EE 227B. Are Berkeley’s course naming rules really that bad that we can’t get rid of the “T” there? ↩
-
I’m not even sure if I got extra credit for those. ↩
-
One of the odd benefits of graduate school is that I can easily rebel against my liberal arts education. ↩
Ava: Communication Beyond Barriers
On January 21, 2015, I saw an email in my inbox about an issue of Berkeley Engineering, which must be some magazine published by the university every few months. I wasn’t planning on reading it in detail, but one of the articles caught my eye. It was about a former Berkeley graduate student, Thibault Duchemin, who had just co-founded a company called Transcense (now named Ava) to break the communication barrier that plagues hearing impaired people when we attempt to talk with hearing people. Their main product is an app that can perform automatic speech recognition, so a hearing impaired person can look at his/her phone during a conversation and (hopefully) read the text to understand what’s going on.
Why did Thibault start the company? In part, it was because of his experience as a hearing person in a deaf family. (That’s rather unusual, since it’s typically the case that there’s a single deaf person in a hearing family1.)
When I was reading this article, I kept thinking about the continued importance of automatic speech recognition. Today, it is widely used in practice (as any avid Googler can tell) and is also a popular research subfield in computer science. I wish I could do research in that area, but unfortunately, I don’t think people who do that kind of research would be interested in working with me.
Needless to say, I wanted to know more, so I sent Thibault an email, and was pleasantly surprised to get a fast response. We decided to meet in person at one of my favorite cafes, Nefeli’s Cafe, located on the edge of the Berkeley campus. We chatted for about an hour in sign language. I was probably a little rusty, and there may have been some French versus English signing confusion, but we understood what we were saying to each other.
I later met a few more people from Ava since I asked to stay in touch with them. Since my meeting with Thibault, they’ve made enough progress on their product that it’s currently in beta stage and released to a specific audience. I recently tested it out with one of their other co-founders, Pieter, and they’ve definitely made progress, though they need to hone out some of the bugs we found during my session. They only have about nine people working for them so hopefully they will be able to work hard to get the app in a useful stage. By the way, here’s the link their new website.
One might wonder how their product works. I don’t know the details, but I think they use some of Google’s speech recognition software. It’s possible to design your own automatic speech recognition software (I did one for CS 288 using Hidden Markov Models) but it’s definitely far easier to use one that’s already existing, rather than build a huge one from scratch, which would require a ridiculous amount of data, and probably lots of neural network tweaking.
As I continue to fight daily doses of isolation, it’s nice to think in the back of my mind that there are people out there willing to work and help me.
-
That doesn’t apply to me, however. ↩
A Nice Running Route Through the Berkeley Marina and Cesar Chavez Park
This morning, I went running through the perimeter of the Berkeley Marina area, including Cesar Chavez Park. This is only the second time I’ve done this route, but I can already tell that I’ll be coming back here every weekend.
I highlighted the running route in the following Google Maps image:
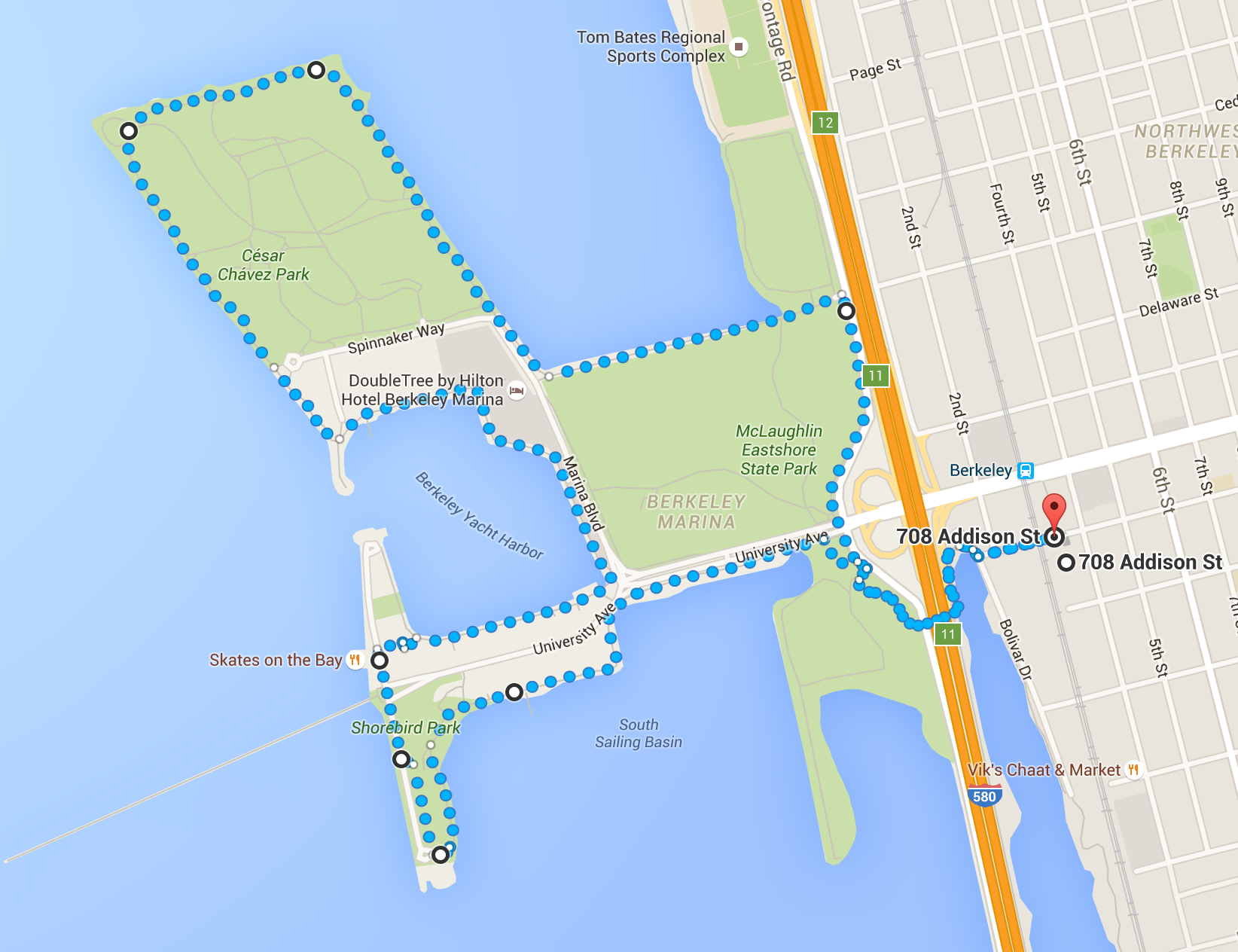
Google Maps said this was 5.3 miles, which matches what my iPhone reported me running this morning. I ran while holding my phone in my left hand and my keychain – with a lanyard – in my right. Update May 27, 2016: It’s also easy to extend this route to increase the distance. There’s a pond to the bottom right of the image above (partially obscured), and running around the pond once before proceeding with the rest of the route results in an 8.3 mile run.
In terms of footwear, I used my Vibram FiveFingers. I hadn’t used these shoes for more than a year, but I’m glad I had them. There’s something oddly appealing about running outdoors with minimalist style shoes. Fair warning, though: a day after my first time running this route, I had really sore calves! This is probably because running with Vibrams means we run “on our toes,” so we rely more on the calves.
Here’s how to start the route as I’ve highlighted it. The first thing to do is find a way to walk past the Amtrak. At 708 Addison Street, there is a walkway and road that intersects with the Amtrak track. Here’s an image of the railroad crossing:

Obviously, look both ways before you run across it! The Amtrak train actually appeared this morning as I was running towards it. Fortunately, the train isn’t that long (at least, the one I saw) so you won’t be waiting too much.
Once you run through that, you’ll find yourself in a small park, as shown in the following image:

You can easily see the pedestrian bridge that goes over the highway. It’s a safe bridge that also has separate lanes for walkers and bikers. (A funny side note: during my first stab at this route, in typical Berkeley fashion, a few people wearing “Democratic Socialists” t-shirts were holding up several “Bernie!” banners so that drivers on the highway could see them.) Once you’re past the bridge, just continue running the route as I highlighted above. I went south first to Shorebird Park, and then north through Cesar Chavez Park, but you could easily run it in the opposite direction.
One reason why I like this route so much is that it’s really safe. Almost all of it is on a sidewalk or a bike lane that’s separate from the roads cars use. In addition, when I ran (on Saturday morning) there were a number of people there walking, jogging, or just hanging out, but it wasn’t super-crowded. I’m much more comfortable if I see a few other joggers there, since it means I know this is a place where people run.
On top of all that, there are some nice views of the bay. The upside of clutching one’s phone when running is the ability to stop and take pictures as desired. I took pictures along some of the route. Here’s the trail that you’ll see soon after you pass that pedestrian bridge.

Looks pretty simple, right?
Here’s one I took that’s close to a favorite restaurant of mine, Skates on the Bay:

You can also see San Francisco and the Golden Gate Bridge in the background.
When I was running through Cesar Chavez Park, I noticed a few nice-looking hotels and restaurants, such as the following:

Perhaps these are worth checking out.
On the way back, you’ll see the Berkeley area across the water and parts of the McLaughlin Eastshore State Park. This area has more dirt than the other parts of the route.

This route is definitely a keeper.
The BVLC (BAIR) Retreat: Disaster Averted!
A few weeks ago, I attended the Spring 2016 BVLC retreat, which was a three-day event (Sunday, Monday, Tuesday) held in Sonoma, CA, in the Wine Country. There was a similar event last year, but I did not attend that one. BVLC stands for “Berkeley Vision and Learning Center,” but the organization recently re-branded itself as BAIR (“Berkeley Artificial Intelligence Research”). I’m a student member of the group. Check out the new BAIR website.
This post is split in two parts. The first will be a recap of my experience at the BVLC retreat. The second will explain why the BVLC retreat was nearly a disaster.
The BVLC Retreat
I took the BVLC-sponsored bus ride from Berkeley to Sonoma with other students, postdocs, and (a few) faculty. After going through typical sign-in procedures and checking into our rooms, the first major event was the bike ride (though I think only two of the faculty actually rode with us, and both are new assistant professors).
We were divided into three groups and, led by a few experienced bikers, rode across a park and a few roads to reach the lunch destination at the Bartholomew Park Winery. I was a tiny bit nervous about embarrassing myself since I hadn’t biked for a few years, but everything went well and I enjoyed the ride. I observed that other bikers were able to maintain conversations while biking; it’s hard for me to do that since I don’t want to lose focus on the bike path, so I didn’t do much talking along the way. Once we were at the winery, a humorous host instructed us on the finer points of wine-tasting and provided us with six different wines to drink. Among other things, I learned that to drink wine correctly, you need to spin/twirl your glass. Then we had a surprisingly-delicious lunch outside. I sat next to two other students I knew, and while it was tough at times to understand their voices, they were willing to repeat when needed.
After that, we biked over to an ice cream place near the hotel. I ventured into new territory by trying a bowl of cappuccino and almonds ice cream. (Why does that combination exist? I don’t know.) I tried that only because I really like almonds and cappuccinos.
Once we finished the bike ride, we (faculty included, of course) gathered in a ballroom at 4:30PM so that Angie Abbatecola and Trevor Darrell could provide some opening remarks. Fortunately, there were two sign-language interpreters, so I sat in the front left corner of the room. Sadly, most of the other students sat in the back of the ballroom, so I was surrounded by faculty and industry sponsors. (Members from companies sponsoring BVLC were invited to the retreat, such as employees of Facebook and – more surprisingly – a few guys from Yahoo! Japan.) After the opening remarks, we had brief 15-minute faculty talks about their group’s ongoing research. There was some interesting stuff here. In particular, I liked the robotics research from Ken Goldberg and Pieter Abbeel. The former’s research can be succinctly described as “cloud robotics”; the latter’s research can probably be called “deep reinforcement learning.”
Following that, we had a poster session with roughly 25 posters. I did not interact with students much, preferring to instead read the posters carefully. Halfway through the 1-1.5 hour poster session, I had memorized the high-level concepts of all the posters, and I described all of them to Ken Goldberg when he asked me to prove that I knew them.
In the evening, we had a large group dinner at the hotel. Everyone was invited: students, postdocs, faculty, and industry sponsors. I had salmon with spinach and mushrooms, and it was a good meal despite my general distaste for mushrooms.
The dinner bears some further discussion. Large group dinners have historically been some of the most difficult events for me to go through because, without any outside assistance, I cannot follow conversations at my table and feel depressed afterwards. But this time, I was smart enough to request sign language interpreting services not only for the talks, but for the dinner, so the same two guys were there. And it’s a good thing they were there; I spent half of my dinner talking to one person, a sponsor from Samsung, who seemed fascinated by my deafness. He asked me the obligatory “can I lip read?” question, and later asked how I could speak so well since he thought my speech was better than his. (Even though I’ve gone through this subject countless times, I don’t mind the attention.) Then we had some more substantive discussion on technology issues such as automatic speech recognition.
But despite how he was sitting right next to me, I had a hard time understanding his voice and looked at the interpreters more than I looked at him.
Incidentally, the dinners were “structured” in the sense that Angie and Trevor wanted (a) people to sit next to new people and (b) for all tables to discuss a common topic. Each of the attendees had name tags with a small colored dot, and we were supposed to sit next to people with different colors. (Side note: I hope next year’s event will actually write the color names rather than have a tiny dot, since we color blind people cannot tell what color we have.) But it didn’t really matter since so many students (and even faculty!) broke the rule; I saw members from the same research group sitting next to each other. Oh well.
The topic for tonight’s dinner was the impact and ethics of AI on jobs. This is an important topic because in the future, AI may rapidly displace jobs in the same way that the assembly line and industrialism replaced unskilled labor. In addition, as anyone who has read science fiction will know, there is a fear that AI can eventually become “unstoppable” and sprawl out of human control. Clearly, we have to reassure people that this will not happen. The discussion at my table was interesting, with most of it centered on how technological displacement has been happening all the time, and this is just “the next step.” In addition, my table (and others!) even mentioned that Bernie Sanders was the only “AI-friendly” presidential candidate. I do not agree with that statement for a variety for reasons, but it wasn’t surprising to see many people support that since academics tend to be liberal.
The dinner went far beyond scheduled, and I finally decided to call it a night after the interpreters stayed 30 minutes past the assigned time. (They were really nice to stay, and I was the one who had to convince them to finish up!)
I got very little sleep that night – it took me three hours to fall asleep – but I didn’t want to miss out on the 7:00AM morning hike. I woke up on time, ate some stale breakfast (no coffee, though) and boarded the bus for the hike. The hike was through Jack London State Park. We split up into a “moderate” group and an “intermediate” group; the guides said the intermediate group would have to go on a somewhat hilly route. Unfortunately for the guides, far more people wanted to be on the “intermediate” hike, so we had to split up further. (I was obviously part of the intermediate group, since I didn’t want to give the impression that I was in poor physical shape.)
The hike itself was much easier than “intermediate,” but that was fine with me. It was nice to be outdoors and to forget about academics. I didn’t talk much, but it would have been hard to have a consistent conversation with someone while avoiding the animal droppings on the trail, since I have to look at the person to understand them well.
Upon arriving back to the hotel, we had another set of five faculty talks and a poster session. For this one, I brought an old poster describing a project from last fall, but it sadly didn’t seem to be that popular among the attendees. Following the poster session, we had all (or most) of the industry sponsors give brief talks about their company, but some were just advertising their job openings. I thought the most interesting presentation came from Facebook’s employees, who described an app that helps the blind “see” through photos. Notice the date of that article!
After the sponsor talks, we had three “breakout” sessions where we gathered in smaller groups to discuss a more specific subset of AI. There were three sessions: (1) natural language & vision, (2) deep reinforcement learning, and (3) CAFFE. I sat in the natural language & vision session, and we talked about the usual object recognition issues, but there was also some interesting stuff about automatic image captioning. I’m aware that there’s research going on in that area (especially in Trevor Darrell’s group) but I haven’t read any of the papers in detail.
Then, we had one of the more unusual events in the afternoon: a wine-blending competition!
The rules were simple. Each group was given the same set of four red wines: Cabernet Sauvignon, Merlot, Franc, and … something else I can’t remember. We had to choose a blend of the four wines to form a new wine, with the constraint that we could not have more than 50 percent of the blend come from one of the wines. Each group would nominate their “best” wine, which our hosts would then shuffle in private and distribute into glasses for three groups of four (since we had twelve groups total). Then, each group nominated a wine-taster, who would match up with three others in the first round (with their three wines) to taste all four wines and rank them from best (1) to worst (4). This meant that every wine taster was guaranteed that his/her group’s wine would appear in his/her group of four, so groups had to make wines that both were really good, but ideally would also be easily detected by their group’s wine-taster, so he or she could rank it as (1).
My group nominated Alexei (Alyosha) Efros as our wine-taster, and we won the first round! In our group of four, Alexei correctly picked our wine first, and the three other wine-tasters from the three competing teams each picked our wine as (2), so our total was 1+2+2+2 = 7 points. It’s hard to get better than that! We advanced to the second (and final) round along with the two other winners from their first round groups, and a fourth “wild-card” team which had the best score of any of the non-first place teams.
Sadly, our victory was not to be. Alexei picked our wine last, so that added four awful points to our score. In fact, the three other wine-tasters really liked our wine, so much that we came in second place, I think with nine points (4+2+2+1). Yeah, I should have volunteered to wine taste.
One of the more amusing aspects of the competition was coming up with our team names, and seeing everyone’s reaction when our host read them aloud. Many of the names (predictably) had some form of “deep” in them – my team name was “Deep Drink,” courtesy of Anca Dragan. Our host was immediately suspicious, and thought there had to be some deeper meaning of the word “deep.”
We then had our second dinner, but this time it was at a golf course, and it was preceded by a one-hour reception. As my interpreters would not show up until after the reception, I knew it would be difficult for me socially, so I asked a few students I knew to stay with me. Though those students were foreigners, I could understand them since I led us away from the crowd. The subject of the night? American politics! Obviously, I was the one who initiated the conversation. The funny thing about this was that an international student told me I was the first American to talk to him about politics despite how he has been at Berkeley for three years.
The dinner after the reception was surprisingly similar to last night’s dinner. We split up into similar-sized tables, I ate fish again, I had two sign language interpreters there, and rules were broken: in my table, five people who knew each other well sat next to each other, and we didn’t talk about the “designated topic” for the night, which was about working in academia versus industry. Once again, both interpreters were very nice and stayed past their assigned time (9:00PM) without me asking them.
The Tuesday morning was more of the same – breakfast, followed by faculty talks, followed by a poster session, then some closing statements, then lunch. A lot of people who drove here went away Tuesday morning before the closing events. During lunch, I did not have interpreters, but it was only for one meal and I can manage (like how I’ve been “managing it” my whole life). I sat next to a man from Yahoo! Japan, and with him being Japanese, it was tough to understand him, but we got some basic conversation going.
Then, at last, I boarded the bus back to Berkeley.
What are my thoughts on the retreat? It went much better than I expected, but this is in part because I have such low expectations that it doesn’t take much to make me happy. (I wasn’t happy all the time, though.)
I think the key for my positive experience was the two dinners. I told this to one of the students who had attended the retreat, and he told me his experience was the opposite: he did not enjoy the dinners, because he could only consistently understand the people who were sitting next to him. And yes, he is hearing, and a few other people I spoke to also confirmed that the noise was an issue for them.
In contrast, I had six pairs of ears that night. The weakest two – but still better than nothing – belonged to me. The other four belonged to the two other interpreters, one of whom sat across from me and thus was able to follow conversations at the opposite end of the table. For one of the few times in my life, I was actually better off during a crowded dinner setting compared to hearing people. I felt ridiculously happy being with my sign language interpreters and could forget about my past frustrations with these dinner experiences.
And yet … the sign language interpreters almost never made it there.
What Almost Happened
On February 22, Angie Abbatecola sent a joint email to members of BVLC asking them to sign up for the retreat. I looked at the agenda and was excited. I did an informal cost-benefit analysis and thought that, particularly because I didn’t attend last year, I better go this time. I RSVP-ed and sent an email to Angie and to Berkeley’s Disabled Students’ Program (DSP) to inquire about accommodations.
DSP’s initial response was that they were unable to pay for interpreting services since it was not directly related to my coursework, but they would investigate their options and contact me later. I was puzzled at this assertion, because I had gotten services before for research-oriented events, and this (even though it is a social event) definitely qualifies as a research event. I immediately followed-up with an email reply saying that this was for a research group and that I wanted to go primarily because I needed to be more involved with the research community and reduce my isolation. I also asked if BVLC would have to pay for the services.
I didn’t get a response.
A week went by, and I sent two more emails asking for an update and/or clarification. For one of the emails, I was told that DSP was still searching for interpreters. Fine, I assumed. There’s plenty of time.
But then another week went by without an update. I sent an email asking for an update, and got no response.
Then Spring Break (March 21 - 25) arrived. I had sent a sixth email (counting from the original email replying to Angie) just before the break started, but I then realized that the staff would probably not work over the break. Uh oh.
The day I returned from Spring Break, which was a week before the retreat would start, I decided I could not wait any longer and marched over to DSP’s offices in person, demanding to know why they had not been able to arrange the interpreting services after four weeks. The staff member there apologized for the delay, and said that it was because the agency DSP uses, Partners In Communication, does not arrange for interpreters to venture beyond San Francisco, Berkeley, and San Jose. Sonoma is roughly an hour and a half’s drive north of Berkeley.
Fortunately, DSP just found another agency that they could use to arrange for interpreting services. I gave them another copy of the retreat agenda, and highlighted the specific sections for which I was requesting accommodations. I didn’t request services for everything, of course, since it didn’t make sense for some of the events (e.g., the bike ride). In addition, since this was happening on short notice, I figured if I requested fewer hours, the likelihood of the requests being fulfilled was greater.
The following Tuesday, DSP formally submitted the request. But at this time, I was really worried that we would not be able to find any interpreters. I discussed this with my parents and they were enraged that Berkeley’s DSP hadn’t moved fast enough despite me giving them more than a month’s notification. They also questioned the claim that the company DSP negotiates with was not willing to arrange for interpreters to drive an hour and a half north, due to my experience at Williams with interpreters traveling long distances. We discussed my options. One of them was that I could search for an agency and pay for interpreters, and have DSP or BVLC/BAIR reimburse me later.
Needless to say, this concern over interpreting services wasn’t helping me in my ability to focus on research and homework. As it turned out, the third CS 267 homework was due around this time.
On the evening of Thursday, March 31, my frustration and stress had crossed a line. With still no word on any interpreters getting hired, I sent a joint email to Berkeley’s DSP and a few other people (Angie, some faculty), with some rather harsh words, but with the goal of trying to explain why I was feeling stressed. Here are some segments of the email:
I wanted to bring up something that’s been causing me a lot of stress lately. The Berkeley Vision and Learning Center (BVLC, though now known as BAIR) retreat is coming up soon, on April 3, 4, and
- Unfortunately, as of right now, I still have not received any confirmation that I will have any sign language interpreting accommodations for that event. If the agency who provides the interpreting services is unable to assign anyone tomorrow, then I am not sure if they will be able to assign anyone at all, since their staff may not work on Saturdays. Angie, the contact person for BVLC, sent an email on February 22 announcing the date of the BVLC retreat. A few days later, on February 27, I sent a joint email to Angie and to [Berkeley’s DSP] outlining my general request for interpreting services for the event.
Then, after outlining my frequent reminders, I explained why I was getting stressed:
What I’m trying to explain in this email is partly that not knowing whether I have accommodations is going to affect how I feel during this event. For instance, if I know that I won’t have accommodations, then I have to carefully plan out every detailed minute and ask a variety of people to stick with me during certain events so that they can explain what people are talking about. The worst part, judging from the agenda, will probably be the dinners. I am unable to follow conversation during noisy dinner settings, so I usually end up taking turns watching one person for a minute, then switching my gaze towards another person, then I repeat the cycle.
The best case scenario is that tomorrow, all the requests are fulfilled. Still, this means I have to constantly think and worry about what will happen for this event and need to refresh my email constantly. This comes at the cost of getting real work done, and I also don’t think that most graduate students have to worry about this stuff. I have been suffering from soaring isolation and stress levels since I arrived in Berkeley, and while it’s gotten better this semester, I just don’t want (in the worst case) this event to revert them back to their fall 2015 levels.
This email was the spark that led to action. I finally saw some evidence that we were moving forward to getting interpreters. Angie and the DSP staff began a lengthy email exchange with each other to search for, arrange for, and pay for interpreters. I was copied to those emails, which was an enormous sense of relief.
My best guess, judging from these emails, is that the new company DSP found (shortly after Spring Break) was unable to provide interpreters, so we had to search for a third agency. We finally found one that was willing to hire on short notice, and filed in a request on Friday, April 1. Unfortunately, since this was so close to the retreat (and remember, many people don’t work on Saturdays and Sundays), the agency charged more for a late-day notice. Fortunately, Angie was willing to arrange the extra payment because she wanted me to enjoy my experience. Incidentally, BVLC was the organization that had to make the payment.
Even though we filed in a request and BVLC was willing to pay, there was no guarantee for interpreter availability. Surprisingly, on Saturday, I received a notice saying that the agency had found a few interpreters for some of the events. By the time I arrived in Sonoma on Sunday morning, half of the hours I requested had been arranged. Excellent! But that still left the other half unassigned …
Also on Sunday, I discovered a bewildering fact. When I entered the ballroom at 4:30PM for the opening remarks, I recognized one of the two interpreters, because he was a “substitute for the substitute” for me in CS 287 during last semester’s infamous “interpreter substitution” phenomenon.
I was curious about how this new agency was able to arrange for him to come to Sonoma. I assumed he lived somewhere near here, or at least equidistant between Sonoma and Berkeley. I asked him where he lived.
His response? Berkeley.
I couldn’t believe it. After all this time, from Berkeley’s DSP not being able to get their usual company to arrange for someone to drive north an hour and a half to Sonoma, what we finally settled on … was an interpreter who lived in Berkeley! Yes, I’m serious! Indeed, he confirmed to me that he had to drive all the way for the job. Wow.
In the end, things worked out in the nick of time, and all of the unfilled hours were filled by Sunday evening (the Sunday events were booked first, but most of Monday was unassigned when I arrived to the retreat on Sunday). I got lucky – one of the interpreters for a Monday morning event was originally scheduled to interpret somewhere else, but his assignment got canceled, so he was available.
In fact, I had interpreting services for all the hours I requested and for a few times that I didn’t request! I think this was due to two reasons. One was that there may have been some miscommunication and that Angle or DSP accidentally filed in more hours than I requested. But the second was a true surprise: the interpreters I had (as mentioned earlier) were kind enough to stay beyond their assigned hours. All the interpreters for the two dinners stayed after 9:00PM, and one Monday afternoon interpreter stayed with me for the wine-blending competition, despite how I hadn’t requested services for that. (I was going to, but since it was short notice, I thought the event was lower on my priority list.) I thanked all the interpreters who stayed beyond their hours, and I wish I could thank them again right now.
What is the lesson I learned from this? Requesting accommodations takes time, and some prodding. I lied in that blog post I wrote last month. I didn’t write it because of Teresa Burke’s essay. I wrote it during the midst of this interpreting request (note the date of the post: March 23) and I only found out about Teresa’s lengthier blog post after I remembered reading one of her older emails. Requesting accommodations takes time in part because there is lots of bureaucracy involved. There are rules that get in the way, from company policies to dealing with DSP versus BVLC payment.
But probably the worst part about these episodes is the impact on how I feel. I constantly, constantly feel like I inconvenience people. I think about that all the time, and arranging for the retreat made these feelings worse. BVLC had to pay extra money for the interpreters because of our last-minute request. The company that arranged the interpreters sent us an email describing their pricing, and the charges took a noticeable hike for a request on three days’ notification.
I didn’t compute the final cost, but my rough estimate is that BVLC had to spend a few thousand dollars for this event (perhaps one thousand for a “normal” request, and an extra thousand for the late notification). Do you think I want to be responsible for all that money shelled out? Angie reassured me that it wasn’t my fault, because I sent in the request far in advance and DSP should have acted earlier, which helped to mitigate some of my concerns.
It’s not just the money that’s involved. There are my usual concerns over whether other people get annoyed or distracted in the presence of interpreters. I’m not exactly at the top of the field, and I don’t know what I would do if a famous professor demanded that the interpreters be removed.
My concerns extend to other events in the future. As a worrisome example, what happens if I attend an academic conference? It was hard enough to get accommodations for an event located in Sonoma, CA, which is an hour and a half drive from Berkeley, CA. Imagine what would happen if I requested an interpreter for a conference in China? There can’t be too many (American/English) interpreters in China, and international flights aren’t cheap.
I’m very, very anxious and concerned about having to plan this out.
Hopefully this explains why I thought the retreat was a “Disaster Averted” moment for me. It was shaping to be awful, but somehow, someway, things ended up better than expected. Moreover, I even finished that CS 267 homework in time. Whew. But why do I need to go these experiences?
My hope is that, one of these days, I’ll be able to enjoy going to gatherings and similar events without having to constantly worry about accommodations, payment, inconveniencing people, and socialization.
Gradient Descent Converges to Minimizers
The title of this blog post is the name of a preprint recently uploaded to arXiv by several researchers at Berkeley, including Ben Recht, who has taught two of my classes (so far). Judging by the arXiv comments, this paper is in submission to COLT 2016, so we won’t know about its acceptance until April 25. But it looks like quite a number of Berkeley people have skimmed this paper; there was some brief discussion about this on a robotics email list. Furthermore, there’s also been some related work about gradient descent, local minima, and saddle points in the context of neural networks. I’ve read two such papers: The Loss Surfaces of Multilayer Networks and Identifying and Attacking the Saddle Point Problem in High-Dimensional Non-convex Optimization. Consequently, I thought it would be interesting to take a look at the highlights of this paper.
Their main contribution is conveniently outlined in a single obvious paragraph (thank you for clear writing!!):
If \(f: \mathbb{R}^d \to \mathbb{R}\) is twice continuously differentiable and satisfies the strict saddle property, then gradient descent with a random initialization and sufficiently small constant step size converges to a local minimizer or negative infinity almost surely.
Let’s make it clear what this contribution means:
-
We’re dealing with the gradient method, \(x_{k+1} = x_k - \alpha\nabla f(x_k)\). It’s nothing too fancy, and the constant step size makes the analysis easier.
-
The sufficiently small step size means we want \(0 < \alpha < 1/L\) where \(L\) is the Lipschitz constant. In other words, it satisfies the well-known inequality \(\|\nabla f(x) - \nabla f(y)\|_2 \le L \|x-y\|_2\) for all \(x\) and \(y\). I have used this inequality a lot in EE 227C.
-
The strict saddle property restricts \(f\) so that every critical point (i.e., those points \(x\) such that \(\nabla f(x) = 0\)) is either (a) a local minimizer, or (b) has \(\lambda_{\min}(\nabla^2f(x)) < 0\). It serves to restrict \(f\) because other functions could have critical points where all the eigenvalues are zero. Note that since the Hessian is a symmetric matrix, all the eigenvalues are real numbers. In addition, a local minimizing point \(x\) means the eigenvalues of \(\nabla^2f(x)\) are all strictly positive.
-
They claim that the gradient method will go to a local minimizer. But where else could it go to? There are two other options: saddle points, and local maxima. Gradient descent, however, cannot go to local maxima because it is by definition a descent procedure, unless (I think) for some reason we’ve initialized \(x_0\) as a point that is already a global maxima, so \(\nabla f(x_0) = 0\) and we get nowhere. So the only thing we worry about are saddle points. Thus, if “saddle points are not a problem” as suggested in the paper, then that therefore means gradient descent converges to local minimizers, as desired.
It’s worth discussing saddle points in more detail. The paper “Identifying and Attacking…” uses the following diagrams to provide intuition:
Image (a) is a saddle point of a 1-D (i.e., scalar) function. Images (b) and (c) represent saddle points in higher dimensions. They are characterized by the eigenvalues of the Hessian at those critical points. If all eigenvalues are non-zero and either strictly positive or strictly negative, then we get the shape of (b) with a min-max structure. If there exists a zero eigenvalue, then we get (c) with a degenerate Hessian. (Recall that a matrix is invertible if and only if all its eigenvalues are non-zero.) Image (d) is a weird “gutter shape” which also results from at least one zero eigenvalue. I’m not completely sure I buy their explanation – I’d need a little more explanation for why this happens. But I suppose the point is that the authors of “Gradient Descent Converges to Minimizers” don’t want to consider degenerate cases with zero eigenvalues. It must make the analysis easier.
Section 3 of “Gradient Descent Converges to Minimizers” provides two examples for intuition. The first example is \(f(x) = \frac{1}{2}x^THx\), where \(H={\rm diag}(\lambda_1, \lambda_2, \ldots, \lambda_n)\) and has no zero components (and hence no zero eigenvalues) but it must have at least one positive and at least one negative component. Otherwise, we wouldn’t have any saddle points! By the way, the only critical point for this function is \(x=0\), as \(\nabla f(x) = Hx=0\) if and only if \(x=0\).
The gradient update is \(x_{k+1} = (I-\alpha H)x_k\). Applying this recursively, we get \(x_{k+1} = (I-\alpha H)^{k+1}x_0\). More specifically, the iterates take on the following form:
\[x_{k+1} = \begin{bmatrix} (1-\alpha \lambda_1)^{k+1} & 0 & \cdots & 0 \\ 0 & (1-\alpha \lambda_2)^{k+1} & 0 & 0 \\ \vdots & \ddots & \ddots & 0 \\ 0 & \cdots & 0 & (1-\alpha \lambda_n)^{k+1} \end{bmatrix} x_0\]Indeed, an analysis of gradient descent with \(0 < \alpha < 1/L\) shows that gradient descent will only converge to \(x=0\) if the initial point \(x_0\) is in the span of \(\{e_1, \ldots, e_k\}\) where \(k\) represents the number of strictly positive eigenvalues (so \(k < n\)). Remember: we don’t actually want to converge to that point, since it is a saddle point! But fortunately, as \(k < n\), if we randomly initialize \(x_0\) appropriately, the only way our iterates converge to the zero vector is if all components from \(k+1\) to \(n\) were exactly zero, and the probability of that happening is zero. Great! We don’t converge to the (bad) critical point! We converge to … a better point, I hope. (The paper uses the term “diverge” but I get uneasy reading that.)
The second example is \(f(x,y) = \frac{1}{2}x^2 + \frac{1}{4}y^4 - \frac{1}{2}y^2\). Finding the explicit gradient update is straightforward, and is provided in the paper. They also explicitly state the three critical points of \(f\). Their argument is similar to the previous example in that they can reduce the cases of converging to an undesirable saddle point to a case which would require initializing a certain component of the starting 2-D point \((x_0,y_0)\) to zero, which cannot happen with random initialization (well, the technical way to say that is “zero measure” …).
I still have a few burning questions on these (plus some of the other stuff mentioned in Section 3) but I’ll hold off on writing about those once I have time to get to the meat of this paper, Section
- In the meantime, it will be interesting to see what kind of work gets built off of this one.
Requesting Accommodations Takes Time
One of the things that I’ve been a little frustrated about lately is the time it takes to arrange and obtain academic accommodations, such as sign language interpreting or captioning services. I can’t just show up to a lecture or an event and expect a sign language interpreter to be there. I have to explicitly request the service, and there are many reasons why this process might get delayed.
-
Before agencies or institutions provide the service, I have to prove that I need the service. This means, at minimum, I need to provide them my audiogram, and they might need some additional background information about my education. Sometimes an interview is required; I had a remote interview with a Berkeley DSP employee before I had arrived for my first classes.
-
After the initial registration hurdle, I can start formally requesting accommodations. To schedule an accommodation for a campus-related event, I have to fill out an online form with information about the time, the location, and other stuff. Berkeley’s gotten better with the forms, as they’ve implemented extra features that help to counter my earlier criticism. On the other hand, there can still be a noticeable delay between when I submit the form and when I get responses, and I have to keep reminding myself that weekends and vacations do not count as “real days” when counting how many days in advance to submit a request.
-
In some cases, it can be extremely annoying to schedule accommodations for one-time events. If it is the first time that I am participating in an event, then I usually don’t have much information on the setting or environment, and it is not always clear if there will be one speaker (which is easier for an interpreter) or a debate with people shouting simultaneously. In addition, I often need to have a detailed schedule of the event, and it’s common to have people wait until the last minute to finalize schedules. I’ve had to send lots of emails to remind others that I need a detailed schedule ASAP, and people hate to see “ASAP.”
-
Finally, it’s not clear how much accommodations can help in practice. I’m not counting cases when there’s some kind of mistake in the scheduling (they do happen sometimes, as in my prelims). I’m considering cases when they work normally, but they simply do not produce any benefit. For instance, when I took CS 288, I had captioning services. In general, they worked as intended (well, not always) but it was extremely hard for me to follow and understand concepts based on real-time, imperfect captions.
I should note, of course, that I’m not the only one who has mentioned this. In fact, I was actually inspired to write this short piece after reading a longer essay by Teresa Blankmeyer Burke, an Associate Professor of Philosophy at Gallaudet University who is deaf. Her blog post covers on some of the themes regarding the time it takes to schedule accommodations. I think her experience is similar to mine: lots and lots of emails to write and forms to fill.
Nonetheless, despite the annoyance of scheduling accommodations, it is important for me to look at the big picture. First, I usually get the accommodations, which is something that not every deaf person in the world can say. In addition, even when accommodations do not work that well, I know that the people providing them are trying their best to help me, and I appreciate that.
Looking Back: Some of my Lifelong Regrets
I often think about some of my lifelong regrets, probably because I’m in a stressful period of my life.
What could I have done different? Would I be a much better person today if I had done this instead of that? Why didn’t I think about doing such obvious acts earlier?
Hopefully if I list them here, I can look back at this blog post periodically and ask myself if I’m making progress towards mitigating my constant guilt over these regrets.
Here are ten of my major lifelong regrets:
-
(1) I did not do enough math, statistics, and computer programming, both during college and (especially) before college. To be clear, I have been a good student my entire life, getting mostly top grades in the hardest courses available to me. But gradually, it became clear to me that I was just an “average good student”, and at Berkeley, there are a lot of “better than good students” who boast ridiculously long lists of math/programming accomplishments, and long lists of graduate-level courses taken.
I am constantly thinking about how I have to study a certain concept many times or take an extra class because I need to “catch up” to far more experienced students (in my year). Looking back, I wish I had taken all of my high school classes two years earlier than when I actually took them, which would have given me a bigger head-start in college. And programming? Upon graduating from high school, I couldn’t make a simple “Hello World” program, whereas other Berkeley students (and this is especially common among international students) were busy winning programming competitions in high school.
In Outliers (more on that later) Malcolm Gladwell describes how hockey players who were born near January 1, and thus had the size edge during youth leagues, are more likely to reach the highest level of the sport than other guys born at different times of the year. This is because being good early leads to snowballing advantages. This “snowballing” is what I wish could be an advantage for me, not a disadvantage. It’s also partly why I don’t think that just taking courses makes it easy to catch up, as (to take an example) professors would rather work with students who have already taken graduate courses in their research area over “riskier” students who have to take those courses and who may not like them or may not do well in them. It’s really hard to catch up.
-
(2) I often did not make it clear to others that I was deaf, in part because I was embarrassed by it. I discussed my uneasiness in telling people that I was deaf in a blog post a few months ago, but here, my focus is on my pre-college life. Starting from middle school, which is when I first became conscious of my dreadful social hierarchy position, I constantly tried to hide my deafness by not signing in public and by focusing on my teachers instead of my sign language interpreters during classes. In high school, I expressed little enthusiasm in discussing “deafness” with anyone. In my senior year, it was awkward for me to write my college essays, since my parents were adamant that I should write about being deaf. (My difficulties in expressing my thoughts probably explains why I didn’t get into many colleges: lackluster essays plus lack of impressive extracurricular activities.) Fortunately, by the time I got to college, I had learned to watch the interpreters more often, but I still don’t generally tell people I’m deaf when we meet for the first time. It’s still a little awkward.
-
(3) I spent too much of my life emphasizing sports, either playing sports or following sports-related news. I have spent many hours doing organized soccer, baseball, basketball, skiing, and to a lesser extent, ultimate frisbee and track & field. In addition, during down-time, I would often read popular sports websites such as ESPN and NBA.com. But I think I could have put that time to better use, because sports haven’t exactly been the greatest thing for me. Some people join sports to get to know other people, but I don’t think I made a single friend out of being on a sports team. In addition, sports were often a source of stress in my life. I was usually not among the top players on my sports teams, and I constantly worried about screwing up and embarrassing myself. Finally, and probably most importantly, I’m not sure I genuinely enjoyed sports. When my high school soccer teams won important games (or scored game-winning goals), I was one of the least enthusiastic players on the team during the celebrations. While other players might hoot and holler and pile up upon the player who scored a winning goal, I would quietly do a few token jumps.
-
(4) On a related regret, I did not do enough to improve my physical fitness. This is not the same as playing a sport; it’s about the work of weight lifting to get stronger and running to improve stamina. Speaking as someone who’s played a lot of sports, I can definitely vouch for the importance of physical fitness and conditioning. Consider this: if someone doesn’t have the foot skills to handle a soccer ball well, but has incredible speed and strength, that player could be a solid defender on a good soccer team.
I have this regret mainly because I was never among the most athletic players on my high school teams. (I know that a lot of this is genetics, but genetics doesn’t explain everything.) When I was on the high school soccer team, for instance, I was regularly among the slowest long-distance runners when we ran laps and probably the slowest sprinter on the team. And, while I had tried going to the weight room often, I was unable to really notice any strength difference. That changed once I had read Starting Strength and Stronglifts in college and got to see noticeable gains in my weight lifting and overall strength, but that begs the question: why didn’t I know about those resources before college? Fortunately, I’ve gotten a little better at working on my strength, but I’ve also been lagging behind on my running.
-
(5) I did not have a good diet until I was around 21. The biggest reason why I consider my my diet to be so bad was because I ate a lot of refined carbohydrates: lots of pizza, plain bagels, white rice, and (sometimes) white pasta and white cereals. Furthermore, even if I had always gone whole wheat for these, having a diet that is 90 percent based on whole wheat does not count as a good diet. I used to eat from Subway a lot, which has heavily processed meat. I also would drink a lot of diet soda, which are almost as bad as regular, sugary soda. What I should have done was emphasize lots of fruits and vegetables, lots of (properly-prepared) meat, and lots of eggs. Of course, all of these have to be cooked and prepared properly, especially in the case of meat. For this regret, I’m happy to say that I’ve made a lot of progress in overcoming my guilt over this. When I was 21, I forced myself to overhaul my diet, and it’s now far more rich and nutritious today than it was a few years ago.
-
(6) I spent too much time playing video games and computer games. I’ve played a variety of games in my lifetime: sports games, real time strategy games, turn-based games, shooter games, building/tycoon games, and others. The two that I have probably played the most are Age of Empires II and Civilization IV. In middle school and high school, I spent way too much time playing them than is healthy, sometimes spending ten hours a day when I didn’t have school. I guess one reason why I liked these games so much was that they were strategy games designed to test my mind, that they were related to designing and building empires, and that they were just a whole lot of fun. In addition, these games do not require me to understand any dialogue that happens in them. There are lots of in-game sounds, but that’s what they are: sounds, not words, which are harder for me to discriminate. Fortunately, while I still play some of these games once every few weeks, I no longer have the immediate urge to play a game whenever I have free time. I think I grew out of those during my college years.
-
(7) I didn’t read enough educational books in my spare time. It’s important to be clear about what I mean here: books assigned as class reading and books that can roughly be described as “non-educational” (e.g., comic books, books describing how to play games, most novels, etc.) do not count. I mostly want to read non-fiction books that cite relevant literature to back up their points. One of the few books I did read that satisfies my non-fiction criteria is Outliers, which I brought up earlier in point (1). It’s a testament to the book’s quality that I still remember a lot about it after eight years, but it’s also been a source of frustration for me. Outliers proposes an interesting “10,000-hour” rule, where one has to spend that amount of time deliberately practicing a skill in order to master it. But it cites Bill Gates as an example, who by the time he had arrived at Harvard as an undergraduate, already had lots of experience working with computers (and remember, this was back before they were commonplace). When I look at my life, I wish I had gotten a head-start on those 10,000 hours on a certain area; usually, I think of programming.
Fortunately, I now have gotten a lot better at reading more books. I have read fifteen books this year (so far) and plan to write up a summary of each book I’ve read in a giant blog post at the end of this year. Most of the books I read are well-regarded non-fiction books that relate to real-world subjects of interest: foreign policy, history, technology, psychology, and other areas. But I still feel like I am reading all these books partly to make up for lost time.
-
(8) I spent too much time browsing random websites and message boards. In part, this was due to my obsession with playing games. For instance, I have almost 6,000 posts on the Civilization Fanatics Forum and was known as one of the top single-player Civilization IV players on the forum. (Yeeeaah … I was really obsessed with that game!) I also posted on other message boards in addition to game-related ones. Sadly, College Confidential was one of them1. In part because I don’t play games that much anymore, I have been a lot better in avoiding message boards. In addition, because I have so much on my plate now in terms of research and coursework, I spend far less time aimlessly browsing the Internet.
Nowadays, there are only a handful of websites I check on a regular basis, and if they are blogs or news-related, I try not to check them until the evening. I deliberately have only a few websites bookmarked on Google Chrome, and I don’t spend much time reading other people’s blogs as I used to. Oh, and what about Facebook? Don’t worry – Facebook was actually one of the earliest sites that I was able to resist checking.
-
(9) In college, I was not aggressive enough in reaching out to other students to work on homework together. I think part of the reason for this is that, for some time, I actually wanted to do homework by myself. To be clear, I was not ignoring requests to work together; I was simply not active in reaching out to other students. I thought that if I worked on my own, I would avoid distractions and learn faster. That worked for a few courses, but as the material became more advanced, I needed to talk to more students, and it was hard for me because I lacked a social base. I relied almost entirely on TAs and professors for assistance with coursework. Fortunately, I’ve now completely changed my stubborn “work alone on homework” strategy and have found other students to work with during classes in recent semesters. As a bonus, my homeworks have generally improved.
-
(10) This is the most recent regret I have, focusing on my experience during the past three years. For some reason, I’ve (hopefully temporarily) lost the capability to ignore my isolation. I have let it adversely affect my mood and productivity and I worry about how others view me. It’s true that being able to do better in my courses and, especially, getting some research papers would help me combat my constant obsession about isolation, but at the moment I need to figure out how to ignore these thoughts. I think part of it has to do with growing up and getting older; I have higher expectations for myself, both socially and academically, and I want to aim high.
Hopefully in five more years I can look back at some of the progress I’ve made. As covered earlier, I have made some progress on overcoming some of the constant guilt I feel about myself. I just want to be a better person and not feel like I am constantly in “catch-up” mode with regards to my life.
-
College Confidential is one of the most depressing places on the Internet. Please don’t go there. ↩
The Four Classes That I Have Self-Studied
While I have access to many advanced and high-quality classes at Berkeley, sometimes I need or want to review foundational topics to make sure I really get the material. I skipped (or did not do well in) some early prerequisites for upper-level computer science and math courses, so I constantly feel like I have to make up for that in my own time.
In this post, I describe four classes that I have self-studied to a substantial extent. Two are from MIT’s Open Course Ware (OCW), and two are from UC Berkeley. All four of my self-studying pursuits were enormously beneficial to me.
Here are the courses listed according to the time I self-studied the material (“My Time”):
18.440, Probability and Random Variables
- Institution: Massachusetts Institute of Technology
- Professor: Scott Sheffield
- Course Offering: Spring 2011
- My Time: Summer 2012
To prepare for my probability class at Williams, I decided to go through MIT’s version of the same class. (In fact, I even made a blog post about this.) Unfortunately, the version on OCW doesn’t offer any lecture videos, so I instead went through all the lecture slides and made sure to understand basically everything covered there. I also took both practice midterms and the practice final, which were surprisingly easy.
To increase my understanding as I was studying the OCW materials, I also read a draft of The Probability Lifesaver, written by Steven Miller (a professor at Williams College).
CS 61B, Data Structures
- Institution: University of California, Berkeley
- Professor: Jonathan Shewchuk
- Course Offering: Spring 2014
- My Time: Summer 2014
I went through all of the class lecture notes from the course website (accessible through Shewchuk’s homepage) and made sure to study them well. I went through all of the homeworks and labs, and made some progress on all three of the major projects. I didn’t complete them – I just got to a stage where I knew I had made a lot of progress and felt that I understood the purpose of the project. One thing I wish I had time for was to do more practice exams, especially those from Paul Hilfinger’s versions of CS 61B (a.k.a. the harder versions).
This class was super helpful for me because I never had a strong data structures education, so I reviewed a lot of concepts that I had implicitly assumed were true but didn’t know why. Reviewing CS 61B made it possible for me to do the tough Java programming assignments in CS 288.
18.06, Linear Algebra
- Institution: Massachusetts Institute of Technology
- Professor: Gilbert Strang
- Course Offering: Spring 2010
- My Time: December 2014 and January 2015
This is a fairly popular MIT OCW course, in part because of the reasonably high quality video lectures. Gilbert Strang lectures at a relatively slow pace, which is fine with me because I prefer slow-paced lectures (and tough assignments). I went through all of the video lectures and made sure to understand them as much as I could, which alone was enough for me to feel like I learned a lot. I briefly read some other related class handouts, but most of the time, my supplemental learning resource was … Wikipedia.
In the future, I should do some of the practice exams.
CS 188: Introduction to Artificial Intelligence
- Institution: University of California, Berkeley
- Professors: Pieter Abbeel and Daniel Klein
- Course Offering: Spring 2012, 2013, and 2014 (varies)
- My Time: Summer 2015
This is a popular undergraduate CS course, both within CS and outside of CS for student who want to “try out computer science.” Fortunately, the class has a lot of material online. I went through all 24 video lectures, but I used different years depending on which YouTube videos had auto-captions and/or which ones had louder sound. Each lecture came with detailed (and humorous) slides, so I read all of those as well.
In addition, I think I took about 15 practice exams (yes, that is not a typo) and rigorously checked my answers with the solutions. It was probably overkill for me, but I really wanted to know this material well. To my disappointment, I noticed that certain questions were recycled (in some form) year after year. Thus, I can’t wait to be a GSI for this class later so I can ramp up the difficulty of the exams by not using those kind of questions.
The Future
I plan to continue my self-studying pursuits during the upcoming summer. Here are the courses on my “self-study radar”:
-
At UC Berkeley, CS 61C, Machine Structures. This in in progress … but barely. I’ve personally resolved that I won’t do any other self-studying of a computer science course until I finish this one. Knowing this material down cold is simply too important for me. After this, I can branch off to other, more advanced areas such as self-studying operating systems.
-
At MIT, 8.01, Introduction to Physics. I’ve never taken a physics course before and I have not started doing this. The downside is that it might be tough to find practice material since MIT had to pull down the material due to Walter Lewin’s inappropriate actions. The videos are online, but I may have to do some searching for the assignments and exams.
I don’t have anything on my radar for math and statistics, in part because probability and linear algebra are so ridiculously important, that if I really wanted to do any self-studying, it would be better for me to actually re-re-study those two courses! In fact, I should probably be doing that this summer anyway.
Are Deaf People Immune to Certain Things?
Yesterday, I finished reading Atul Gawande’s fascinating 2002 book Complications: A Surgeon’s Notes on an Imperfect Science. This is the first of his four books – all of them bestsellers – and I read his other three books earlier this year. I’m staying on track to read by far more books than I had planned to as part of my New Year’s Resolution, so that’s nice. Also, unlike in December 2015, when I only discussed the top three books I read, in December 2016, I plan to cover all of the books I’ve read that year. I’ll do it in one blog post, with one paragraph for each book, plus some additional commentary. Complications is already the fourteenth book I’ve read in 2016, so that blog post will be super-long. (It’s currently in a draft state behind the scenes so that I don’t have to write it all at once.) Stay tuned until December 31, 2016, everyone!
But anyway, I wanted to comment on a particularly interesting portion of the book. In a chapter describing a pregnant woman’s intense nausea which mystified her doctors (hence the title of the book), the following text came up:
In 1882, the Harvard psychologist William James observed that certain deaf people were immune to seasickness, and since then a great deal of attention has been focused on the role of the vestibular system—the inner ear components that enable us to track our position in space. Scientists came to believe that vigorous motion overstimulates this system, producing signals in the brain that trigger nausea and vomiting.
My first reaction was: hey, this is pretty cool! And this was done in 1882? Really?
Just to give my personal experience: while I’ve occasionally had mild cases of nausea, I can’t recall ever feeling sea sickness1, or any kind of motion sickness. I’m a huge fan of roller coasters, for instance, and I can ride them often without feeling sick. To make the point clear: when I was in eighth grade, I rode the Boomerang Roller Coaster at The Great Escape twenty-five times – in one day. (Ahh … those memories of empty lines and being able to quickly exit the coaster and race to get back on.)
It’s pretty cool to think about being immune to something. My mind wandered to thoughts about whether deaf people might be immune to things such as deadly diseases. I remembered that passage at the start of The Death Cure when the Rat-Man told Thomas2: “The Flare virus lives in every part of your body, yet it has no effect on you, nor will it ever. You’re a member of an extremely rare group of people. You’re immune to the Flare.”.
I thought about some of these things as I read through the rest of Complications, so after I finished the book, I decided to briefly investigate further. Here is what I found.
-
First, it’s clear that it’s not deafness that causes the so-called “immunity” but, as Gawande points out, the condition of the vestibular system. I’m not sure as to whether a weakened vestibular system is the cause for my deafness. I was deaf since birth and as far as I know, there’s no explanation for it besides the randomness of genetics.
-
One of the most commonly cited sources for this fact (or “myth” as some might call it) is an old 1968 paper called Symptomatology under storm Conditions in the North Atlantic in Control Subjects and in Persons with Bilateral Labyrinthine Defects. Yeah, the title is pretty bad but the paper showed that in an experiment, a few deaf people did not experience seasickness.
-
The original source, William James’ 1882 “study” is called “the sense of dizziness in deaf-mutes”, but I can’t figure out a way to access it; it’s trapped behind several websites that restrict access (ugh). I can’t even use my Berkeley credentials. All of my knowledge about that paper therefore comes from third-party sources.
-
Almost all other sources about this topic are from really random and ancient research or (worse) newspaper articles. Here’s one example from a 1986 article on the SunSentinel, and it’s pretty lame. Also, I tend not to trust articles that appear on ad-heavy websites.
So yeah, there isn’t that much focus on deafness so far as the vestibular system. Shucks.
As I was reading through these ancient sources (well, the ones I could access), I also wondered about the evolutionary benefit of being deaf. I can’t think of any, unless deafness somehow came with another benefit to counteract its negative effects. I hope it’s some secret immunity.
I mean, think about how bad life would have been during the years humans have lived. If I had been born in 1800, for instance, I wouldn’t have had access to the high-quality hearing aids I’m wearing as I type this blog post. In fact, the best kind of “hearing aid” I could have used would be those terrifying (and ineffective) ear trumpets. Ugh.
Going further, consider the prototypical “cavemen”. For them, having good hearing would be more important than it is for humans today; there was no sort of disability law and little to no visible communication mediums (e.g. writing) to compensate.
This line of reasoning could also extend to other disabilities. Why do they keep appearing in our population? A quick Google search of “evolutionary benefit of disabilities” resulted in several random, small news articles after another, hardly convincing evidence. Another, non-disability related one might be homosexuality; indeed, that was one of the choices of text that Google suggested for me when I was typing “evolutionary benefit of”. It seems to be fairly accepted that homosexuality is not a choice, but then this raises the question: what is its evolutionary benefit? And what about, er, this kind of stuff? All right, that’s enough of this thinking for today.
Why I (Reluctantly) Don't Show up to Class
At the end of the first CS 267 (Applications of Parallel Computing) lecture, I was looking forward to the rest of the class.
Well, after three more lectures, I’m probably done attending them for the semester.
No, don’t worry, I’m still taking the class1, but I negotiated an unusual accommodation with Berkeley’s Disabled Students’ Program (DSP). All CS 267 lectures are recorded and available on YouTube to accommodate the large number of students who take it as Berkeley students and as non-Berkeley students. The course is also offered almost every year, so students can watch lectures and study the slides from previous iterations of the class.
So what did I suggest to DSP? I told them that it was probably best for me not to attend classes, but to watch the lectures on YouTube, so long as DSP could caption those videos.
Why did I do this? Because CS 267 has three factors that are essentially the death-knell for my sign language interpreting accommodations:
-
The material is highly technical.
-
The lecturer (Professor Jim Demmel) goes through the material quickly.
-
I am not familiar with the foundational topics of this course.
The last one was the real deal-breaker for me. Even in classes that completely stressed me out due to the pace of the lectures and lack of suitable accommodations (CS 288 anyone?), I still had the foundational math and machine learning background to help me get through the readings.
But for a class about lower-level computing details? I have to check Wikipedia and Stack Overflow for even the most basic topics, and I could not understand what was being discussed in lecture.
Thus, I will watch lectures on YouTube, with captions. Unfortunately, DSP said that they required at least a 72-hour turnaround time to get the captions ready2, and I’m also not sure who will make them. I think it would be hard for the typical captioner to caption this material. I suggested that using YouTube’s auto-captions could be a useful starting point to build a transcript, but I don’t know how feasible it is to do this.
I suppose I could fight and demand a shorter turnaround time, but honestly, YouTube’s auto-captions are remarkably helpful with these videos, since I can usually fill in for the caption’s mistakes. Also, the limiting factor in my progress in this course isn’t my understanding of the lecture material – it’s my C programming ability. Finally, I have other issues to worry about, and I’d rather not get into tense negotiations with DSP. For instance, I still regularly feel resentment at the EECS department for what I perceive as their failure to help me get acclimated into a research group. I am only now starting to do research where I am not the lead and can work with more experienced researchers, but it took so long to get this and I’m still wondering about how anyone manages to get research done. My research — and overall mood — has been a little better this semester, but not that much, compared to last semester. I don’t want the same feelings to be present for my opinion of DSP.
Hopefully this new accommodation system for CS 267 will go well.