My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
Is it Better to Work Without Hearing Aids?

Tomorrow, I will finish up a software engineering internship. I usually work at home, and lately I’ve been getting out of bed, wolfing down breakfast (berries, broccoli, and eggs), and conducting my morning coding session, all without putting on my hearing aids. Sometimes, I don’t touch them until the afternoon.
This raises the following question:
Is it better for someone like me to work without hearing aids?
Naturally, this would only apply during individual work sessions. If I’m working on a team project with a partner right by my side and we need constant communication, I’ll keep my hearing aids on. The one exception would be if that other person wants to speak using ASL, but that’s generally not a common occurrence.
I recall performing this “no hearing aid” tactic during my time working in the Williams College computer science lab. During peak hours, usually Sunday or Thursday evenings, the lab would get so packed that I couldn’t focus with all the screaming going on. (It sounds like screaming when 30 regular-volume conversations are happening in one small area.) If I wasn’t holding a TA session, then I would go to a corner of the back room of the lab, turn off my hearing aids, and work in peace.
The advantage of this is that I often reap the benefits of a short-term focus spike; it’s definitely nice to be able to mute all conversations under those circumstances. But should eschewing hearing aids be my default behavior when I work on something myself? Even if the only external noise is a fan?
Okay, I have to confess: part of the reason why I haven’t put on my hearing aids until so late during the past few days has partly been out of experimental interest. I want to see how effectively I work with and without hearing aids while having little to mild background noise. (It’s not a perfect experiment, because my surroundings are too quiet.) My impression is that I think turning off hearing aids can be useful under extremely noisy circumstances, but for most cases, I would not recommend it because there are too many downsides:
- I’m more vulnerable to danger. If the roof of my house were about to collapse due to hail, but I couldn’t feel it (I know this example is crazy…) then you can imagine what would happen.
- It creates some awkwardness if I need to turn on my hearing aids when someone wants to talk to me. My hearing aids — the Oticon Sensei — take roughly six seconds to start up from the moment I press the switch. So … I have to figure out how to stall for six seconds. And what if that person just wanted to say hi?
- Related to that previous point, when I turn off my hearing aids, it’s not at all obvious to anyone else in the same room that I actually do have them off. My hearing aid’s on and off states are hard to distinguish unless a person has a clear side view of me. Perhaps if I physically took them out of my ears, but that creates a whole host of other complications. In this situation, if someone needs my attention, he or she is going to have to work a harder to reach me, and everyone else in the room will probably be watching us.
- One thing I’ve also noticed in the past few days is that, when I turn off hearing aids, it blocks external noise but doesn’t silence my brain. It seems like if I don’t hear any natural sounds, sometimes my brain tries to “fill in” for me by repeating voices and sounds, which can be annoying. I think if I have my hearing aids on, some of the natural sounds can break that up (but not always).
Thus, while turning off hearing aids is useful when faced with prolonged noise exposure, it is not generally a long-term solution. With situations such as shared offices, which are a typical work environment for graduate students, I think the benefits decrease and the drawbacks (as stated earlier) become more striking. (At Berkeley, I’m pretty sure graduate students periodically interrupt each other to talk about research.) As a possible alternative, I could utilize noise-canceling headphones that cover my hearing aids (without causing any “ringing”) which would take care of some of the problems I mentioned. Interestingly enough, the last time I tried wearing noise-canceling headphones over my hearing aids, they didn’t cancel out any noise! So it seems to me that I just need to get used to working with background noise.
What Happens the Summer Before Grad School?
In about a week, I’ll be heading over to Berkeley to begin my graduate career.1 Consequently, I thought I’d take some time to reflect on what’s been going on this summer, particularly with regards to preparation for graduate school. Perhaps this will be useful to future generations of Berkeley EECS Ph.D. students.
Once students confirm that they are going to Berkeley, then they’ll be put on a mailing list (or more accurately, a “Google Group”) that includes all incoming EECS students, a few existing EECS students, and a few staff members. Important emails will be flying around by early May, so technically one’s preparation for Berkeley should start even before the summer begins.
Of the emails that are being sent, by far the most important ones to read are those about housing.
For people like me who don’t have any connections in the Bay Area, contacting other incoming students about housing opportunities is extremely important, unless you want to hedge your bets on living by yourself or with non-EECS students. Fortunately — at least during the summer of 2014 — there seemed to be enough people in my situation that finding a group to live with wasn’t too difficult. I did have to go through several failed attempts at forming a group, as well as one rejected housing application (that really hurt), but by the start of July, I had secured a place to live. One key tip is to keep in touch with the incoming students who are already around the Bay Area; they’ll be the ones conducting most of the house visits to make sure that the house you found on craigslist isn’t terrible. That reminds me: if you have no experience with craigslist, I suggest learning how to use it. And another tip about housing: I think it’s easier to get housing if you can find a nice place to rent and then advertise it to the group, rather than if you form a group first and then find a house.
Of course, there are other emails to read as well. Most of the non-housing emails fall into the category of incoming students asking current students questions. But worry about those after housing.
The Berkeley Graduate Division also sends out monthly emails. Those emails are short but have links to a bunch of detailed PDFs and websites. There’s too much information to absorb at once, but read as much as you can. You’ll also want to read a little more about the department’s Ph.D. requirements. Here’s a refresher.
At the start of July, you’ll also be assigned a temporary advisor. Send him or her a few emails (but not too many … see the Email Event Horizon for why). You may ask advice on what courses to enroll in, but the class schedule is online and most students have a good idea of what to take anyway. You can sign up for classes starting in August, but be careful not to take more than two a semester.
Finally, if you were to ask me advice on what to do during the summer before graduate school, I would recommend either a research or software engineering internship to keep your skills sharp, but it’s OK to use this time to travel or pursue other interests. While you can pursue them at Berkeley, the 167-hour work week makes things a little time-intensive.
-
Just in case you were wondering, I do plan on maintaining this blog during my time in Berkeley. I haven’t run out of things to say. ↩
Andrew Ng’s Machine Learning Class on Coursera
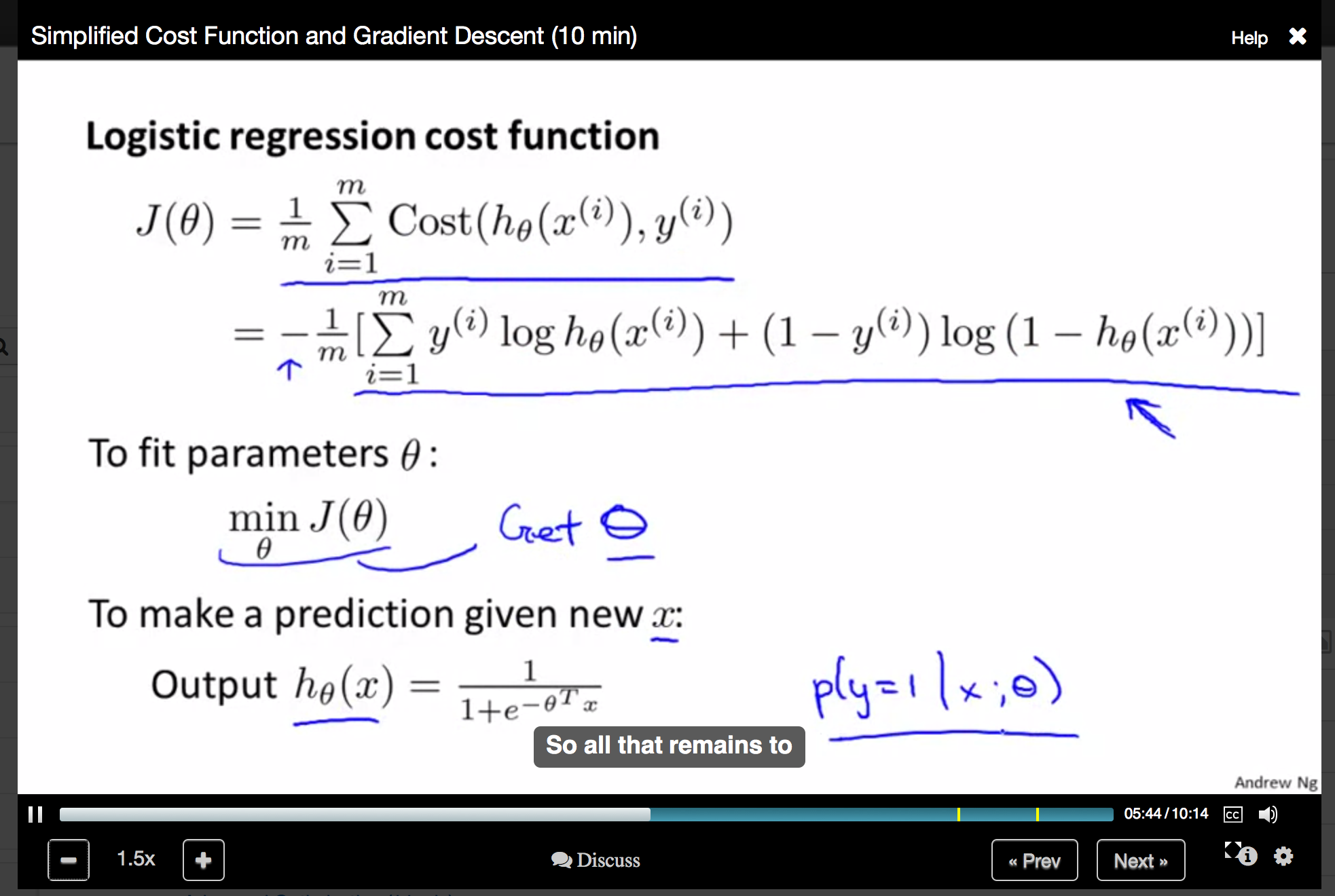
If you’re interested in taking a free online course, consider Coursera. It takes seconds to make an account and filter through the 700 or so classes currently in the database to find what interests you. Classes are generally affiliated with a university, and professors are often the ones lecturing in the videos online. In addition to video lectures, there are homework assignments and exams, which are submitted electronically, as well as user discussion forums where the students can discuss class concepts.
Coursera embodies the concept of the massive open online course (MOOC) which aims to have unlimited participation to allow (theoretically) anyone in the world to obtain an education for free. Founded in 2012 by Daphne Koller and Andrew Ng of Stanford University, Coursera now has over 7 million users and sports an impressive list of university partners. (Check out this paper for an interesting discussion about MOOCs.)
Coursera is similar to the well-known MIT OpenCourseWare, but it has several advantages. The biggest one is that courses on Coursera will have all class material eventually available to the students who sign up, whereas on MIT OpenCourseWare, you face the repeated problem of lack of video lectures, lack of exams and solutions, and other information, especially with the upper-level courses. Coursera’s website design is also vastly superior. On the other hand, Coursera classes requires the user to sign up in a certain date range, so if you go on Coursera right now, chances are high that some of the classes that you want to take aren’t offered in the near future (and you might have to add it to your “watch list” for the next session).
In the meantime, I’ve been checking out Andrew Ng’s machine learning class, which was what really started Coursera. It’s designed to be a ten-week course, with the following syllabus:
- Week 1: Introduction, Linear Algebra Review, Linear Regression with One Variable
- Week 2: Linear Regression with Multiple Variables
- Week 3: Logistic Regression and Regularization
- Week 4: Neural Networks (Representation)
- Week 5: Neural Networks (Learning)
- Week 6: Applying Machine Learning Algorithms
- Week 7: Support Vector Machines
- Week 8: Clustering, Dimensionality Reduction
- Week 9: Anomaly Detection, Recommender Systems
- Week 10: Large-Scale Machine Learning
A third of the grade is based on multiple-choice quizzes, and the rest is determined by programming assignments, to be done in MATLAB or Octave, the latter of which is an excellent free version of the former. Octave is one of the simplest programming languages out there, so it shouldn’t be too difficult for one to get used to it.
After going through the first few weeks of the course, here are some quick impressions:
- Advantages: The class doesn’t have many prerequisites (no calculus, no probability, etc.) and is accessible to a broad audience. Professor Ng’s video lectures are excellent. In fact, it’s nice to see that someone who can write complicated papers can clearly explain the basics. There seems to be a lot of collaboration among the students. The class covers most of the concepts I’d expect in a machine learning class, but for some reason doesn’t seem to cover the naive bayes and decision tree learning algorithms.
- Disadvantages: The simplicity of the class is also its major drawback — to someone like me who already knows machine learning, the class is too easy and I watch video lectures (for review purposes) at 1.5x or 1.75x the speed (a nice feature, by the way). Professor Ng often has to say “the discussion of this concept is beyond the scope of this course….” Consequently, a student at Stanford is better off taking Professor Ng’s “actual” machine learning course.
Again, if you’re interested in learning more about any subject, I encourage you to check out Coursera. There’s definitely a heavy focus on computer science — not surprising, given that the founders are computer science professors — but there are courses in subjects as diverse as health, law, engineering, and music.
Friendly Computer Science Textbooks
I’d been meaning to post this earlier, but I got sidetracked by Project Euler (more on that later). In any case, I want to list a few computer science textbooks that, in my opinion, are written in a friendly style and are easy for someone to read like a novel. These are my favorite kind of textbooks, because they often incorporate two important aspects: elaboration and examples. Notice that this does not mean that mastering the corresponding subject is easy! It just makes it easier for an experienced and educated reader to do so.
I’m inspired to think about this because, as much as I enjoyed my complex analysis class last fall, the textbook we used glosses over so many details that it made analyzing some of the proofs excruciatingly difficult. At least, for me … I can’t speak for everyone in the class, but my professor did have to explain that the goal of his lectures was to emphasize why the authors/book did something in their proofs.
In the past few weeks, I read parts of Methods of Mathematical Economics, a textbook about the mathematics behind linear programming and other popular applied mathematics techniques. It is written in a conversational style (the author uses “I” instead of “we”), and it was very helpful to me for a final project.
Here are four books on the computer science side that I’ve found to be very readable.
- Algorithm Design, by Jon Kleinberg, and Eva Tardos, presents an introduction to the common themes underlying an algorithms course. I enjoyed it because it emphasizes the decision-making behind many of the proofs. In addition, it contains several sample problems with detailed solutions. These solutions also explain why certain approaches might not work or are suboptimal.
- Artificial Intelligence: A Modern Approach, by Stuart Russell and Peter Norvig, is a surprisingly readable “encyclopedia-like” book about AI. I do not recommend reading the entire thing, especially in one sitting! But if you pick out a single chapter, the book should serve you well. I talked with Stuart when I was visiting Berkeley, and he told me I needed to know more learning theory. I asked him how I could learn more, and he said: “read the book.” Good — I’ll do that!
- Distributed Systems: Principles and Paradigms, by Andrew S. Tanenbaum and Maarten Van Steen, is about concepts of distributed systems (i.e., those relying on multiple computers/machines). This book is filled with examples. Almost every concept is explained with an immediate real-life example.
- Introduction to the Theory of Computation, by Michael Sipser, overlaps somewhat with Algorithm Design, but emphasizes automata, computability, and complexity, rather than pure algorithms. It is a concise book, but somehow provides the impression that it’s detailed and expansive. Fortunately, each chapter contains problems with full solutions.
I’d be interested in knowing if there are other popular, readable computer science textbooks.
2014 Williams College Phi Beta Kappa and Sigma Xi
After finding out I made it into the Williams College Phi Beta Kappa and Sigma Xi honor societies, I went online looking for more information about the induction ceremonies. Unlike the commencement exercises, there does not seem to be much out there about these two ceremonies, so I figured I might explain what goes on during these events.
Just a quick background: Phi Beta Kappa and Sigma Xi are two honor societies that some colleges and universities offer to their students. Phi Beta Kappa tends to admit students based on GPA and breadth of coursework, while Sigma Xi admits those who have done and plan to continue doing science and math research. (At Williams College, Phi Beta Kappa is solely based off of GPA; roughly the top 12.5% of the class gets in.) In the Williams College class of 2014, I believe there were 68 Phi Beta Kappa inductees and 56 Sigma Xi inductees. Of course, there was significant overlap among the two groups.
Phi Beta Kappa
We had several speakers in this ceremony. Some provided administrative information, such as “welcome to the society” and “please do X to complete your application” type of stuff.
To me, the most notable speaker was the Williams professor who introduced us to the history of the Williams College Phi Beta Kappa charter. It started in 1776 at the College of William and Mary (the college that, according to the speaker, our grandmothers still think we go to) and then spread to Massachusetts when Harvard acquired a charter in 1779. Williams tried numerous times to acquire one from Harvard, but did not succeed until 1864. The charter we obtained, written in Latin, was shown on display throughout the ceremony. Sadly, it appears to be the only one of its kind in which the granting institution’s name (“Harvard”) was written in much larger text than the name of the school being awarded (“Williams”)!
After the history talk, another guest speaker highlighted the diversity of the majors studied and languages spoken among the Phi Beta Kappa members. He listed almost every major and language, except for computer science and American Sign Language. I am not sure how those two didn’t make it on his lists. I mean … maybe if one of my two “diversity contributions” was listed, I wouldn’t have made a big deal out of it, but both?
Near the end of the ceremony, each of us went on stage to receive Phi Beta Kappa materials.
Sigma Xi
This induction ceremony was much shorter than the one for Phi Beta Kappa. The Sigma Xi speaker spoke briefly about how he wished us all an excellent career in science, and encouraged us to try and get promoted to full membership. All the Sigma Xi inductees stood up and got to the stage to get our materials, and then we stood there while all the parents and other family members took pictures. I noticed at least one of the old class pictures is online — if the 2014 one goes up, you should try and find me.
Speak vs. Use ASL
Here’s an interesting question to consider: which one of “he/she/someone uses ASL” or “he/she/someone speaks ASL” should you use in writing and conversation? The answer isn’t obvious to most people without knowledge of ASL, because while speak is the default term for most languages, it’s not clear if ASL falls under that category due to its visual nature (and, I might add, its no-speaking requirement).
I never had someone tell me which of the two phrases to use, and I’ve flip-flopped on my usage. I would say speak when I was younger, then in recent years I switched to saying use, and now I’m starting to think I should go back to speak. My recent shift is due to a discussion on the Deaf Academics mailing list.
Here is a video of someone arguing on behalf of speak, and here is the transcript (the meaning of s5s is explained in the video):
“Hi, I’m Michele Westfall and I currently write for ASL Rose. John Clark asked me to talk with you about Speak vs Sign, and I’m happy to do so. It’s no problem at all. Why? For the past couple of years, I’ve been encouraging Deaf people … really, everyone to use the word “speak” in relation to ASL. Why? I’ve been noticing that the hearing society frequently sees us as “silent.” Yes, they regard ASL as “beautiful,” but when it really counts and really comes down to it, we are still SILENT in their eyes. I’ve noticed that both hearing and Deaf people tend to say “ASL users”…and that bothers me.
Think about it: hearing people never say “English users”…”French users”…”Spanish users”…”Chinese users.” Really, the contrast is huge. We say “ASL users”, “we sign”, “we do ASL”….which serves to emphasize the difference between ASL and all other voiced languages and puts way too much emphasis on the Voice. Hearing people get to say “speak”…and we can’t.
I disagree with that. I say, YES, we speak ASL. Understand, I’m not saying we have to say “We speak [using 4-handshape on chin] ASL.” That’s wrong. What’s the right way? “We speak [using s-5-s handshape] ASL.” Get it? s5s = speak…that’s our version of speak. Don’t say 4-handshape on chin/speak. That’s the hearing version (or the hearing-minded version). We s5s/speak ASL. Or…”I’m an ASL s5s/person [speaker].” Or “The ASL s5s/person [speaker] for the day is XXXXX.”
Just an example. You s5s/speak ASL. I s5s/speak ASL. To let you know, I’ve been saying this for the past several years. I even write it…for example “I speak ASL.” on paper. In English sentence….I speak ASL/you speak ASL. And hearing people always accept it and never object. They don’t say, “Wait a minute! What’s this?” They accept it because it seems natural to them. I think…it’s time. We’ve been saying all along that ASL is a language. It means we must change our words to reflect that reality. What’s our reality? ASL is our language, and therefore…what? We speak ASL! We don’t sign ASL.
Saying “We sign ASL” gives way too much credit/weight to Voice. No. Enough. It’s time to bring ASL on equal footing with all other voiced languages. You speak ASL. I speak ASL. We don’t “do” ASL. We don’t “use” ASL. We speak ASL. We are ASL speakers. I hope this makes sense to you. If not, let me know. Bye bye.”
Git and Git Immersion
One critical skill I acquired this past year was how to use git. It’s a distributed version control system that is often used by programmers and software companies to manage their code. The reason why git and other version/revision control systems are so useful is that they allow multiple people to easily work together on a project by means of a shared code repository. Rather than have one person work on a small part of a project and email any updates to everyone else, he or she can instead “push” their modifications to the repository, and other collaborators can “pull” the updated code so that they are working with the latest version. (I use “push” and “pull” since these are git-related terms, but other systems have different terminologies for adding and getting repository code.)
If the current code has serious issues, it is possible to roll back to a previous version, which is just like having a bunch of backup files. This is one of the main benefits of using version control systems, even for a project managed by just one person. For instance, I used git for my undergraduate thesis and the related code, so whenever I wanted to work on it, I would just pull from the current repository, make my changes, and then push at the end. Git turned out to be a lifesaver when, two weeks before I had to send my thesis to the rest of the department, I accidentally deleted a chapter. The solution? Pull the latest version of that chapter from the repository.
Git is very common among computer science students, and possibly even more popular among computer
science Ph.D. students, so it’s a good skill to have in one’s toolkit. I learned git
largely by trial and error and having other people tell me what to do, but one resource I found that
might be useful to beginners is Git Immersion. This is a tutorial that walks you through the
basic commands of git. It was mostly review for me, but I did learn a few things, such as git
mv which will save me time when moving files in my repositories. In the past, I would move files,
then delete the original files from git, then add the new ones (in the different location), then
commit everything, but git mv does all that at once. My one qualm is that I wish they incorporated
GitHub in the tutorial, but it’s technically not part of git, so I can see the reason for
excluding it.
Say, I wonder how non-computer scientists write their theses, or more accurately, those who don’t employ version control systems. I would hate having to save countless backups for a variety of files. In addition, another key benefit of git is that each time you make a change, you can record the high-level idea of this modification, and it will appear in the log for future reference. This makes it easy to go back and search for an old version of a file.
Two Suggestions on Grading
As my final college grades come in, I once again reflect back on my undergraduate classes and their grading schemes. The key question: how much did my grades correspond to the amount of material I learned or the amount of the subject I mastered? This is a tricky question to consider. Obviously, the amount of “mastery” required to get an A varies from school to school, subject to subject, and even course to course within the same field. But I believe that everyone can give a rough interpretation of how much he or she learned from a class (at least, right after it finishes). This may or may not correspond to the actual grade.
For the sake of completeness, here are four cases that can occur, supposing for simplicity that an A is the standard for excellence:
- You get an A, and feel like you deserved it.
- You get an A, but don’t feel like you deserved it.
- You get less than an A, and feel like you deserved it.
- You get less than an A, and don’t feel like you deserved it.
I have had all four of these cases happen at Williams. Case 4 is obviously bad, since everyone feels slighted when this happens. But Case 2 can arguably be just as worse in the long run, since you know less about the subject than what might be suggested from your transcript, but employers may not see that until after you’re on the job. In an ideal grading scheme, only cases 1 and 3 would occur.
So how can classes be designed to reduce instances of the two undesirable cases? I have two suggestions, but keep in mind that these are aimed at computer science and/or mathematics courses. I don’t have enough experience with other majors, though these might work for corresponding classes anyway.
Suggestion 1: Require Individual Work
One of the main observations I’ve made while at Williams is that sometimes it is possible to “hide” your weaknesses by joining a group and earning the group’s collective grade. For instance, this might involve a computer science group project where everyone in the group gets the same grade. In these cases, your grade is largely determined by who you work with!
Learning how to work in groups is certainly an important skill, so I’m not suggesting that these projects be eliminated entirely. Instead, I urge professors to divide up projects in two categories: those that allow groups and those that must be done individually. Or during a group project, perhaps require that everyone give a self-evaluation of their peers. This happened in my African Studies class in the Spring 2013 semester. (But this tactic runs into problems if you work with shady people … again, it matters who you work with!)
In a typical computer science course, grading is determined by a combination of group work, homework, and exams. For mathematics courses, they typically use only homework and exams. This brings me to my next suggestion…
Suggestion 2: Make Exam Score Ranges Larger
I think this suggestion will be more helpful than requiring individual work, and in any case exams are (I hope!) an example of something in that category. The problem that I have experienced in Williams classes is that exams are often set so that the vast majority of students (say, 85%) get scores in the 85-100 range. In a ten question exam where all questions are weighted equally, the first nine might be minor variations of homework problems, and only the last question gets used to differentiate between those who really know the material.
But this doesn’t give enough discrimination among students, and it means more students might get As because they lucked out on that tricky question, and more students might get Bs because they happened to make a careless error on one of the easier questions.
Increasing the exam score range so that the median and mean are within the 70-75 range would give professors more ability in distinguishing the different categories of students. With an “85-100 exam,” if I get a 94 and another person gets a 95, should I consider myself equal to that other person in terms of knowing the material? If I lucked out on that last question, that class might end up giving me an A, but I might view it as Case 2. But if scores were distributed over a 40-100 range, all of a sudden that 94 starts looking a lot better. And if I end up with, say, a 70 on an exam where lots of students get 90s, I’ll be momentarily disappointed, but the grade I get will reflect that I didn’t know enough of the material to warrant a higher grade, and that others were more deserving of getting an A.
I think a lot of students won’t like larger score ranges, but really, this shouldn’t be the case. Professors should assign grade ranges appropriately, so that scores in the 80-100 range would be an A, rather than the “standard” 90-100 range. All these numbers are really arbitrary, and in the real world, no one knows “100 percent” of their field/profession anyway.
PS: It’s good that Williams’ final exam period ends five days before the last day of May. Otherwise, I would have broken my streak of having at least one blog post a month…
I’m Going to Berkeley!

This entry is a few days overdue — my apologies. (Excuse of the day: my thesis is due in a few weeks.) Admitted students had until April 15th to make their graduate school choices, and I made mine on April 13. As you can no doubt tell from the title of this post, I have committed to the University of California, Berkeley. I will start pursuing a Ph.D. in computer science there this fall.
It was not an easy decision, especially because I only applied to top-tier schools. I was debating for a full month between Berkeley and Washington (with each school seemingly have the edge on various days), but in the end, there were several factors that made me end up on Berkeley.
It’s an exciting time for me! I have already received an email about setting up my Berkeley ID, and I can’t wait to get started this fall. I hope that the next six years (five if I’m extraordinarily lucky) will bring fulfilling and rewarding experiences.
Are You Disabled? Your Boss Needs to Know
Recently, there’s been a flurry of emails in one of my subscribed email lists about some recent regulations that require employers to ask if their employees have a disability. I’ll list the main points of the linked Wall Street Journal article.
- U.S. regulations now require federal contractors to ask their employees if they have a disability. It is up to employees to determine if they wish to disclose any information. (So the title is actually misleading, as the bosses don’t need to know.)
- Those contractors that don’t employ a minimum of 7 percent, or can’t prove they are taking steps to achieve this goal, could face penalties.
- This applies to contractors with at least 50 employees or at least $50,000 in government money.
- The Labor Department issued these regulations to help combat the high jobless rate of the disabled population.
Some people responded to the email list saying that these regulations were long overdue, but a few were not satisfied or had reservations. (To put it briefly, I think these are “overdue” mainly because they help raise awareness of the challenges disabled people face in the workforce, but for now I’ll discuss what others have said.)
A number of people talked about how disclosing information is a difficult and sensitive topic for people with hidden disabilities. Should they tell their bosses or not? Consider the case of someone with a hidden disability applying for a job. Do they feel confident enough to disclose their disability to a hiring committee before any job offer? I suspect that if the job applicant knows that these contractors are trying to recruit people with disabilities, that will raise the probability of disclosure, but I doubt any information will be easily accessible.
Related to the visible/hidden disability discussion, some also worried that employers would give preference to people with visible disabilities to fill in the ranks if not enough employees were willing to disclose hidden disabilities. Because of how the ADA has expanded the definition of a disability, it’s very likely that contractors already have way more than 7% of employees who are disabled.
And of course, there is the possibility that managers and hiring committees of these contractors will protest, arguing that they now have to “lower the bar” to hire a specific group of people.
There didn’t seem to be much discussion about deaf people, which would have been related to the visible/hidden disability discussion because I would argue that deafness can fall in both categories.
Graduate School Visit #4: The University of Washington
I departed from San Francisco and landed in Seattle near midnight. Fortunately, Washington’s visit days didn’t start until the following day (Tuesday). They were the only school I visited that restricted their visit days to be two days, probably because they know they have lots of cross-admits with Berkeley. I rode a shuttle that brought me back to the Silver Cloud Inn near the university’s campus. I did request to live with graduate students, but I was told that Washington had over ninety students show up to visit days, and there were sadly not enough hosts to accommodate all of us.

The following morning, another shuttle took a group of students from the hotel to the Paul G. Allen Center. It was quite nostalgic coming back to the same building that I spent a lot of time in while at the 2011 Summer Academy, and I still remembered my way around it.
Unlike Berkeley, Washington’s schedule started super-early, with breakfast at 8:00 AM. Then the department chair gave us a slide show welcoming us to Washington and gave us reasons why we should attend the Ph.D. program. One of them was that Washington would be substantially expanding the size of their faculty, which increases the pool of potential advisors for incoming students. I remember back in 2012 when Washington shocked the computer science world by hiring seven faculty members. They followed that up with four new hires in 2013. Hiring eleven in the span of two years is is rare enough, but Washington isn’t done yet! The department will be hiring six faculty members in 2014 and then six more in 2015, for a grand total of twenty-three hires in four years! Indeed, the department is going to look very different soon. I also found out from several reliable sources that one of the new 2014 hires is a machine learning expert. The list of new faculty will probably be announced sometime in late May or early June.
After the chair’s presentation, four faculty members gave quick technical talks to highlight the breadth of research in the department. Then there was, as usual, a graduate student panel. According to the current students, the worst thing about being at Washington was (unsurprisingly) the cold weather. I don’t think there was anything super-surprising I learned from the panel.
Later that day, we had faculty and laboratory meetings. I went to the databases and machine learning meetings, which were each an hour long and involved the usual series of faculty talks. Washington’s style is to have grad students groups in the center of the building (usually) with professors on the outer side, but the Paul Allen center has a giant atrium inside of it so it doesn’t feel too isolating. To clarify, each floor has some conference rooms in the center of the building, and the shared offices for graduate students are shown on the right side in the following image:

The machine learning lab was packed with faculty and admits, which forced many people to stand due to the lack of chairs. It was clear to me that machine learning is one of Washington’s strengths. When I had lunch earlier, a current graduate student told me he estimated that more than half of the students were working on either machine learning or HCI.
Quite surprisingly, I was also scheduled to have one-on-one meetings with *graduate students. *These meetings were not a part of UT Austin, Cornell, or Berkeley’s visit days, and I consider that a plus for Washington. (I sent in requests to meet certain faculty members, but not graduate students.) All one-on-one meetings, by the way, lasted 20-30 minutes, which seems to be standard among the schools I visited.
At 5:30 PM, there was a reception in the Allen Atrium with beer, wine, soda, veggies, and cheese/crackers. It was a bit on the noisy side, but I had some worthwhile conversations. (The wine was also good.) Then the admits, current students, and faculty walked as a group to a nearby building where we all had a formal dinner. The food was great.
I had a few more meetings scheduled on Wednesday and also visited the HCI laboratory, but the highlights of the day took place after lunch, where research groups hosted different activities. I went on the AI/ML/Robotics boat tour. Sadly, it was cloudy, so the view wasn’t that great, but it was nice to be outside for a while.
After eating a quick dinner on “The Ave,” I found some time to catch up on email, turn in some late homework, etc., then I took the shuttle back to Seattle. I flew back Wednesday night (in Seattle time) and arrived on the east coast at roughly 9:00 AM. I barely made it back in time for my Distributed Systems lecture on Thursday. It was time for my life to get back to normal, but I admit that traveling was fun.
I also need to decide on which graduate school to attend! That’s what I’ve been doing and still will be doing for another few weeks.
Graduate School Visit #3: The University of California, Berkeley

After visiting Cornell, I had a short break at Williams and then traveled to San Francisco to visit the University of California at Berkeley.
I arrived at around 5:00 PM and one of my graduate student hosts drove me over to his house, where I would be staying at for the next two nights. I think Berkeley gave admits the option to reside in a hotel or stay with graduate students. Naturally, I chose to stay with the students, since I think one learns more by living with them. My host’s house was quite nice, and gave me a splendid aerial-like view of their new (and controversial) football field.
There was still plenty of time left in the evening, so my host drove me over to Soda Hall where the admits were getting together. And … wow, there were a lot of admits! One of the visit day coordinators told me that Berkeley had 130 admitted students show up! About half of the students were electrical engineering admits, though, since Berkeley has a joint EECS program.
By the time I had gotten to the lounge, the food was pretty much gone and I was left to stand awkwardly in a noisy, crowded room. Fortunately, I was saved by a group of current Berkeley students who took some of the late arrivals out to dinner. I ended up eating a salad meal from a Vietnamese place near campus, and then went back to my host’s house for the night.
The second day was action-packed, though surprisingly, it started quite late at 9:30 am (good news for those who are night owls!). I went over to Sutardja Dai Hall, which served us breakfast. I had a nice time eating and chatting with other prospective students, and Berkeley even gave free hoodies to us! One interesting thing about the way Berkeley handles the visit days is that they were the only school I visited that gave out name tags to people that also included their undergraduate institution and their research area. That’s very clever, as “Where do you go to school?” and “What are your research interests?” are the first two questions that the admits always ask each other!
At 11:00 AM, we all gathered in an auditorium, where the department chair gave an hour-long presentation introducing us to Berkeley. To the surprise of no one, the chair emphasized how Berkeley had the best placement of faculty members in top computer science departments. He also talked about the department ranking (#1 in computer science, #1 in electrical engineering) and gave us this table based on the 2014 rankings:
- Ranking in AI: (1) Stanford, (2) CMU, (3) MIT, (4) Berkeley
- Ranking in Programming Languages: (1) CMU, (2) Berkeley, (3) Stanford, (4) MIT
- Ranking in Systems: (1) Berkeley, (2) MIT, (3) Stanford, (4) CMU
- Ranking in Theory: (1) Berkeley, (2) MIT, (3) Stanford, (5) CMU (Princeton is #4)
- Average ranking (1) Berkeley = 2.0, (2) Stanford = 2.5, (3) MIT = 2.75, (4) CMU = 3
The chair also listed some of the incredible accomplishments made by Berkeley alums. He later gave us more reasons why they were better than MIT, starting with the warm weather. (At the time I visited there a few weeks ago, the high in Boston was around 26 degrees. Yikes.)
After the chair’s presentation, there were group meetings based on research area. My main interests are in AI, but my name tag actually said my research area was “HCI” and I think this was because the HCI professors were the ones that reached out to me the most. (One professor who talked to me was “cross-listed” in both AI and HCI.) So I went with the HCI group, and got to see some of their latest work while eating lunch. Then they gave me a quick tour across their facilities, followed by another long series of research presentations at the Visual Computing Lab. One graduate student had a really cool project I remember: he used data from images to infer crime rate in cities and applied that to a shortest-safest-path software. Thus, unlike Google maps, which suggests the most direct route when given two points to connect, his software would redirect the person to a longer but safer route. He collected data from San Francisco and inferred it on the Chicago maps, and confirmed its accuracy with real Chicago data. Amazing!
After all that was the campus tour at 4:00 PM. I went inside the Sather Tower and took the following photo while I was at the top. Another one of my photos is the one that starts this blog post.

The day wouldn’t have been complete without the graduate student panel, which took place right after the tour. It was similar to the ones at Cornell and UT Austin. I was genuinely interested to see what the graduate students would answer to the question of “What is the worst thing about Berkeley?” After all, they cannot use the excuses of either the weather being cold (it’s not) or the school not being the highest ranked (it has the best ranking). The grad students said: getting through the bureaucracy.
Right before dinner, there was a light reception at Soda Hall. I got to meet some more amazing admits (some of them are remarkably talented!) and current grad students, and I also had the pleasure of seeing a concert featuring David Culler (guitar), Michael I. Jordan (drums), and a few other graduate students. Then we went to dinner, where one of the professors on the admissions committee recognized me immediately and mentioned that he saw my blog. Say, many of the faculty members knew who I was before I arrived … I guess that’s a good sign.
The third day was when all the one-on-one, 30-minute faculty meetings occurred. I met with five professors and got a good sense of the kind of problems I might work on this fall should I accept their offer of admission. In my free time, I was touring the AI and HCI labs and chatting with some of the current students. My main regret from my visit to Berkeley is that I didn’t get to meet enough machine learning faculty and students, so I’ve been sending a few emails asking questions to the relevant people. At Berkeley, incidentally, the students have shared, open workspaces that are typically surrounded by faculty offices.
After my final faculty meeting of the day, I was able to sneak in another hour or two to do some late Operations Research homework. For dinner, I headed out with the HCI group, and then later took the train to San Francisco airport since, like many of the Berkeley admits, I had to head to Seattle for another visit days starting the next morning….
Graduate School Visit #2: Cornell University
Sorry for the delay in posting this entry. Cornell’s visit days happened on March 9-11, but as usual, I did not have much time to write about it until now, which corresponds to my long-overdue spring break.
Cornell did not give visiting admits the option to stay with graduate students. Instead, we were all assigned rooms in the Statler Hotel. Not only is this located right in campus, but it’s literally just a one-minute walk away from Cornell’s brand-new computer science building, called the Bill & Melinda Gates Hall. (Yes, sound familiar?)

The first night proceeded as expected. The current and visiting students split into groups to go to dinner. Following that, students either played board games (this is what I did), went to a planetarium (I think that’s what it was…), or just went back to the Statler (this is what I probably should have done, based on my mountain of homework).
The second day, March 10, was filled with activities. The admits gathered in the third floor of Gates lounge to have breakfast. The department chair gave us a slide show presentation that highlighted some of the department’s strengths. Here is what I remember:
- They moved into Gates Hall three weeks ago. (So now, it’s been about six weeks.)
- The department had multiple new hires for this year and planned to continue expanding the faculty in the near future. The chair also told us that Cornell had hired a prominent researcher from another company (i.e., a major victory), but said the hiring was supposed to remain a secret for now. I’m not sure if I’m allowed to say who it is, since I don’t see any announcements and his/her website doesn’t yet indicate that he/she is going to Cornell.
- The chair listed some of the schools or companies where recent Ph.D. graduates were now working. A few Ph.D. grads got faculty positions at top-tier universities.
- The chair said the professors and students truly had a close relationship with each other, probably closer than that of other comparable schools. (And he showed us a few party-related pictures to confirm this … actually I think some of the graduate students put them in the slide show while the chair was away from his computer.)
I didn’t have much time to relax afterwards, due to faculty meetings. At Cornell, I had meetings with seven professors, more than any other school I visited. That made it challenging to prepare well. I like being able to check professor’s websites so I can avoid asking redundant questions.
We also ate lunch in Gates Hall. Cornell had different lunches based on research area. I attended the AI lunch, which was a fairly standard buffet. About five AI-affiliated faculty members also gave brief talks about their research at that time. Following the AI lunch was a theory meeting, where the theory professors discussed their research.
I noticed that AI and theory were incredibly popular among the admits. Almost everyone visiting Cornell was interested in one of AI, machine learning, algorithms, or theory. I suspect that some of these AI/theory admits might have to switch to systems or programming languages research.
After the theory talks was the grad student panel. Visiting students asked the standard questions such as “what’s the worst thing about Ithaca?” and “what’s the living situation like?”. I’m not sure why people kept asking the former question, because the answer is always the same for northern schools: the cold weather.
I did ask one question: which professors are the most popular to hang out with socially, and which ones are the most well-known in terms of research? I probably should keep their answers to myself, but I think most outsiders can state the highest-profile faculty with enough Internet searching.
I had a little more time to relax before dinner, so I briefly chatted with other admits and students. Then it was dinner, where just like the previous night, we went out to eat at different restaurants. Afterwards, there was a “party” in the Gates Hall lounge, featuring ice cream and a ton of beer. I met more students and professors, including one current faculty member who graduated from Williams College. I think he thought I was a student at the University of Washington at first, since I wore my Williams jacket with a large purple W, which also correlates with Washington. During visit days, I met at least three students or admits who did their undergrad studies at Washington, so it’s definitely a place with solid representation at Cornell. Three admits also went to Harvey Mudd College. I believe there were no other current students or visiting admits from Williams except me, unfortunately.
Then I went back to the hotel room and turned in some late homework while briefly chatting with my hotel roommate.
The third day was fairly relaxed compared to the second day. There was an excellent brunch at the Statler Hotel featuring tons of fruit, bacon, and french toast (of course, I didn’t eat the french toast). I still had a few more faculty meetings to attend, and after that, I left, departing the hilly environment of Ithaca/Cornell back to Williamstown. Ithaca, by the way, seems remarkably similar to Williamstown.
Overall, it was another nice visit.
The 2013 Turing Award and the 2014 Computer Science Ph.D. Rankings
In the past few weeks, there were two notable events in the computer science community. The first was the announcement of the 2013 Turing Award winner: Leslie Lamport, for his contributions to distributed and concurrent systems. I am learning about his work in my distributed systems course this semester, so it is nice to see that he is getting recognized.
Here is the updated list of Turing Award laureates by university affiliation. MIT is now gaining ground on Stanford and Berkeley.
The second major piece of news relates to the new computer science Ph.D. rankings, which is nice because before that, the last update was in 2010. The top four schools — Carnegie Mellon, MIT, Stanford, and Berkeley — did not change in rank, but Cornell dropped from five to six, while Illinois retained their status as fifth. Washington moved up from seven to six, which might be a reflection of their latest faculty hiring spree. Princeton stayed at eighth, while the UT Austin dropped from eight to nine.
Cornell and UT Austin can’t be happy about their rank dropping, as it will adversely affect their yield for both their graduate and undergraduate enrollment. As I mentioned earlier, UT Austin is planning to substantially expand the size of their department, and last I heard, Cornell is doing the same (more on that later), so they are fighting to get their ranking up. Unfortunately, this means that in about five years, professorships will be tough to get.
Side note: after Googling my own name, I’m happy to see that Seita’s Place is the first hit. Technically, for most of the past two years, the first hit was actually the Hello World entry. Why was that post ranked higher over the blog homepage for so long?
Mamoru Samuragochi, the Fraudulent Deaf Japanese Composer
A few weeks ago, The New York Times published an article about a “deaf” person who was exposed as a fraud. Mamoru Samuragochi, a popular Japanese composer whose deafness made him seem like a modern-day Beethoven, staged a career-long hoax in which someone else surreptitiously wrote his compositions. Furthermore, it seems like he faked his hearing disability.
Reading this article makes me consider two perhaps unfortunate scenarios.
- A person faking a hearing disability to make him or her stand out, win praise from others for overcoming obstacles, etc.
- A deaf person who has enough hearing and speaking ability from hearing aids or cochlear implants such that others mistakenly view him or her as hearing.
It would be incredibly naive to think that neither of these scenarios occur. Sadly, they do, and Samuragochi seems to be a prime example of Scenario #1. Fortunately, I don’t know of any others off the top of my head.
But what about Scenario #2? I think I fit into this one. With amplification from powerful hearing aids, I can easily communicate to someone so long as there is insignificant background noise. I’m sure that others have doubted my deafness in the past.
The problem is that, in the absence of medical records and audiograms, there isn’t a clear-cut algorithm for determining if a person qualifies as being deaf. A person wearing hearing aids could be wearing them for just a tiny, almost negligible benefit, or the hearing aids could mean the difference between hearing anything versus nothing at all. Speaking ability also varies from person to person. There is an abstract spectrum of “deafness,” and I think it’s challenging for people to determine where anyone else lies within it.