My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
My PhD Dissertation, and a Moment of Thanks
Back in May, I gave my PhD dissertation talk, which is the second-to-last major milestone in getting a PhD. The last one is actually writing it. I think most EECS PhD students give their talk and then file in the written dissertation a few days afterwards. I had a summer-long gap, but the long wait is finally over. After seven (!) years at UC Berkeley, I have finally written up my PhD dissertation and you can download it here. It’s been the ride of a lifetime, from the first time I set foot at UC Berkeley during visit days in 2014 to today. Needless to say, so much has changed since that day. In this post, I discuss the process of writing up my dissertation and (for fun) I share the acknowledgments.
The act of writing the dissertation was pretty painless. In my field, making the dissertation typically involves these steps:
-
Take 3-5 of your prior (ideally first-author) papers and stitch them back-to-back, with one paper as one chapter.
-
Do a find-and-replace to change all instances of “paper” to “chapter” (so that in the dissertation, the phrase “In this paper, we show…” turns to “In this chapter, we show …”.
-
Add an introduction chapter and a conclusion chapter, both of which can be just a handful of pages long. The introduction explains the structure of the thesis, and the conclusion has suggestions for future work.
-
Then the little (or not so little things, in my case): add an acknowledgments section at the beginning, make sure the title and LaTeX formatting all look good, and then get signatures from your committee.
That’s the first-order approximation to writing the PhD. Of course, the Berkeley Graduate Division claims that the chapters must be arranged and written in a “coherent theme” but I don’t think people pay much attention to that rule in practice.
On my end, since I had already given a PhD talk, I basically knew I had the green-light to write up the dissertation. My committee members were John Canny, Ken Goldberg, and Masayoshi Tomizuka, 3 of the 4 professors who were on my qualifying exam committee. I emailed them a few early drafts, and once they gave approval via email, it was a simple matter of uploading the PDF to ProQuest, as per instructions from the Berkeley Graduate Division. Unfortunately the default option for uploading the PDF is to not have it open access (!!), which requires an extra fee of USD 95.00. Yikes! Josh Tobin has a Twitter post about this, and I agree with him. I am baffled as to why this is the case. My advice, at least to Berkeley EECS PhD students, is to not pay ProQuest, because we already have a website which lists the dissertations open-access, as it should be done — thank you Berkeley EECS!
By the way, I am legitimately curious: how much money does ProQuest actually make from selling PhD theses? Does anyone pay for a dissertation??? A statistic would be nice to see.
I did pay for something that is probably a little more worthwhile: printed copies of the dissertations, just so that I can have a few books on hand. Maybe one day someone besides me will read through the content …
Well, that was how I filed in the dissertation. What I wanted to do next here was restate what I wrote in the acknowledgments section of my dissertation. This section is the most personal one in the dissertation, and I enjoy reading what other students have to say. In fact, the acknowledgments are probably the most common part of theses that I read. I wrote a 9-page acknowledgments section, which is far longer than typical (but is not a record).
Without further ado, here are the acknowledgments. I hope you enjoy reading it!
When I reflect back on all these years as a PhD student, I find myself agreeing to what David Culler told me when I first came to Berkeley during visit days: “you will learn more during your years at Berkeley than ever before.” This is so true for me. Along so many dimension, my PhD experience has been a transformative one. In the acknowledgments to follow, I will do my best to explain why I owe so many people a great debt. As with any acknowledgments, however, there is only so much that I can write. If you are reading this after the fact and wish that I had written more about you, please let me know, and I will treat you to some sugar-free boba tea or keto-friendly coffee, depending on your preferred beverage.
For a variety of reasons, I had one of the more unusual PhD experiences. However, like perhaps many students, my PhD life first felt like a struggle but over time became a highly fulfilling endeavor.
When I arrived at Berkeley, I started working with John Canny. When I think of John, the following phrase comes to mind: “jack of all trades.” This is often paired with the somewhat pejorative “master of none” statement, but a more accurate conclusion for John would be “master of all.” John has done research in a wider variety of areas than is typical: robotics, computer vision, theory of computation, computational geometry, human computer interaction, and he has taught courses in operating systems, combinatorics, and social justice. When I came to Berkeley, John had already transitioned to machine learning. I have benefited tremendously from his advice throughout the years, first primarily on machine learning toolkits when we were working on BIDMach, a library for high throughput algorithms. (I still don’t know how John, a highly senior faculty, had the time and expertise to implement state-of-the-art machine learning algorithms with Scala and CUDA code.) Next, I got advice from John for my work in deep imitation learning and deep reinforcement learning, and John was able to provide technical advice for these rapidly emerging fields. As will be highlighted later, other members of his group work in areas as diverse as computer vision for autonomous driving, video captioning, natural language processing, generating sketches using deep learning, and protein folding — it sometimes seems as if all areas of Artificial Intelligence (and many areas of Human Computer Interaction) are or were represented in his group.
A good rule of thumb about John can be shown by the act of asking for paper feedback. If I ask an undergrad, I expect them to point out minor typos. If I ask a graduate student, I expect minor questions about why I did not perform some small experiment. But if I ask John for feedback, he will quickly identify the key method in the paper — and its weaknesses. His advice also extended to giving presentations. In my first paper under his primary supervision, which we presented at the Conference on Uncertainty in Artificial Intelligence (UAI) in Sydney, Australia, I was surprised to see him making the long trip to attend the conference, as I had not known he was coming. Before I gave my 20-minute talk on our paper, he sat down with me in the International Convention Centre Sydney to go through the slides carefully. I am happy to contribute one thing: that right after I was handed the award for “Honorable Mention for Best Student Paper” from the conference chairs, I managed to get the room of 100-ish people to then give a round of applause to John. In addition, John is helpful in fund-raising and supplying the necessary compute to his students. Towards the end of my PhD, when he served as the computer science division department chair, he provided assistance in helping me secure accommodations such as sign language interpreters for academic conferences.
I also was fortunate to work with Ken Goldberg, who would become a co-advisor and who helped me transition into a full-time roboticist. Ken is a highly energetic professor who, despite being a senior faculty with so many things demanding of his time, is able to give some of the most detailed paper feedback that I have seen. When we were doing serious paper writing to meet a deadline, I would constantly refresh my email to see Ken’s latest comments, written using Notability on his iPad, and then immediately rush to address them. After he surprised me by generously giving me an iPad midway through my PhD, the first thing I thought of doing was to provide paper feedback using his style and to match his level of detail in the process. Ken also provides extremely detailed feedback on our research talks and presentations, an invaluable skill given the need to communicate effectively.
Ken’s lab, called the “AUTOLab,” was welcoming to me when I first joined. The Monday evening lab meetings are structured so that different lab members present on research progress in progress while we all enjoy good food. Such meetings were one of the highlights of my weeks at Berkeley, as were the regular lab celebrations to his house. I also appreciate Ken’s assistance in networking across the robotics research community at various conferences, which has helped me feel more involved in the research community and also became the source for my collaboration with Honda and Google throughout my PhD. Ken is very active in vouching for his students and, like John, is able to supply the compute we need to do compute-intensive robot learning research. Ken was also helpful in securing academic accommodations at Berkeley and in international robotics conferences. Much of my recent, and hopefully future, research is based on what I have learned from being in Ken’s lab and interacting with his students.
To John and Ken, I know I was not the easiest student to advise, and I deeply appreciate their willingness to stick with me over all these years. I hope that the end, I was able to show my own worth as a researcher. In academic circles, I am told that professors are sometimes judged based on what their students do, so I hope that I will be able to continue working on impactful research while confidently acting as a representative example for your academic descendants.
During my first week of work at Berkeley, I arrived to my desk in Soda Hall, and in the opposite corner of the shared office of six desks, I saw Biye Jiang hunched over his laptop working. We said “hi,” but this turned out to be the start of a long-time friendship with Biye. It resonated with me when I told him that because of my deafness, I found it hard to communicate with others in a large group setting with lots of background noise, and he said he sometimes felt the same but for a different reason, as an international student from China. I would speak regularly with him for four years, discussing various topics over frequent lunches and dinners, ranging from research and then to other topics such as life in China. After he left to go to work for Alibaba in Beijing, China, he gave me a hand-written note saying: “Don’t just work harder, but also live better! Enjoy your life! Good luck ^_^” I know I am probably failing at this, but it is on my agenda!
Another person I spoke to in my early days at Berkeley was Pablo Paredes, who was among the older (if not the oldest!) PhD students at Berkeley. He taught me how to manage as a beginning PhD student, and gave me psychological advice when I felt like I was hitting research roadblocks. Others who I spoke with from working with John include Haoyu Chen and Xinlei Pan, both of whom would play a major role in me getting my first paper under John’s primary supervision, which I had the good fortunate to present at UAI 2017 in Sydney, Australia. With Xinlei, I also got the opportunity to help him for his 2019 ICRA paper on robust reinforcement learning, and was honored to give the presentation for the paper in Montreal. My enthusiasm was somewhat tempered by how difficult it was for Xinlei to get visas to travel to other countries, and it was partly his own experience that I recognized how difficult it could be for an international student in the United States, and that I would try to make the situation easier for them. I am also honored that Haoyu later gave a referral for me to interview at Waymo.
In November of 2015, when I had hit a rough patch in my research and felt like I had let everyone down, Florian Pokorny and Jeff Mahler were the first two members of Ken Goldberg’s lab that I got to speak to, and they helped me to get my first (Berkeley) paper, on learning-based approaches for robotics. Their collaboration became my route to robotics, I am forever grateful that they were willing to work to me when it seemed like I might have little to offer. In Ken’s lab, I would later get to talk with Animesh Garg, Sanjay Krishnan, Michael Laskey, and Steve McKinley. With Animesh and Steve, I only wish I could have joined the lab earlier so that I could have collaborated with them more often. Near the end of Animesh’s time as a PhD student, he approached me after a lab meeting. He had read a blog post of mine and told me that I should have hung out with him more often — and I agree, I wish I did. I was honored when Animesh, now a rising star faculty at the University of Toronto, offered for me to apply for a postdoc with him. Once COVID-19 travel restrictions ease up, I promise that I will make the trip to Toronto to see Animesh, and similarly, to go to Sweden to see Florian.
Among those who I initially worked with in the AUTOLab, I want to particularly acknowledge Jeff Mahler’s help with all things related to grasping; Jeff is one of the leading minds in robotic manipulation, and his Dex-Net project is one of the AUTOLab’s most impactful projects, and shows the benefit of using a hybrid analytic and learned model in an age when so many have turned to pure learning. I look forward to seeing what his startup, Ambi Robotics, is able to do. I also acknowledge Sanjay’s patience with me when I started working with the lab’s surgical robot, the da Vinci Research Kit (dVRK). Sanjay was effectively operating like a faculty at that time, and had a deep knowledge of the literature going on in machine learning and robotics, and even databases (which was technically his original background and possibly his “official” research area, but as Ken said, “he’s one of the few people who can do both databases and robotics”). His patience when I asked him questions was invaluable, and I often start research conversations by thinking about how Sanjay would approach the question. With Michael Laskey, I acknowledge his help in getting me started with the Human Support Robot and with imitation learning. The bed-making project that I took over with him would mark the start of a series of fruitful research papers on deformable object manipulation. Ah, those days of 2017 and 2018 were sweet, while Jeff, Michael, and Sanjay were all in the lab. Looking back, there were times on Fridays when I most looked forward to our lab “happy hours” in Etcheverry Hall. Rumor has it that we could get reimbursed by Ken for these purchases of corn chips, salsa, and beer, but I never bothered. I would be willing to pay far more to have these meetings happen again.
After Jeff, Michael, and Sanjay, came the next generation of PhD students and postdocs. I enjoyed my conversations with Michael Danielczuk, who helped to continue much of the Dex-Net and YuMi-related projects after Jeff Mahler’s graduation. I will also need to make sure I never stop running so that I can inch closer and closer to his half-marathon and marathon times. I also enjoyed my conversations with Carolyn Matl and Matthew Matl, over various lab meetings and dinners, about research. I admire Carolyn’s research trajectory and her work on manipulating granular media and dough manipulation, and I look forward to seeing Matthew’s leadership at Ambi Robotics, and I hope we shall have more Japanese burger dinners in the future.
With Roy Fox, we talked about some of the most interesting topics in generative modeling and imitation learning. There was a time in summer 2017 in our lab when the thing I looked forward to the most was a meeting with Roy to check that my code implementations were correct. Alas, we did not get a new paper from our ideas, but I still enjoyed the conversations, and I look forward to reading about his current and future accomplishments at UC Irvine. With our other postdoc from Israel, Ron Berenstein, I enjoyed our collaboration on the robotic bed-making project, which may have marked the turning point of my PhD experience, and I appreciate him reminding me that “your time is valuable” and that I should be wisely utilizing my time to work on important research.
Along with Roy and Ron, Ken continued to show his top ability in recruiting more talented postdocs to his lab. Among those who I was fortunate to meet include Ajay Kumar Tanwani, Jeff Ichnowski, and Minho Hwang. My collaboration with Ajay started with the robot bed-making project, and continued for our IROS 2020 and RSS 2020 fabric manipulation papers. Ajay has a deep knowledge of recent advances in reinforcement learning and machine learning, and played key roles in helping me frame the messaging in our papers. Jeff is an expert kinematician who understands how to perform trajectory optimization with robotics, and we desperately needed him to improve the performance of our physical robots. With Minho, I enjoyed his help on getting the da Vinci Surgical Robot back in operation and with better performance than ever before. He is certainly, as Ken Goldberg proudly announced multiple times, “the lab’s secret weapon,” as should no doubt be evident from the large amount of papers the AUTOLab has produced in recent years with the dVRK. I wish him the best as a faculty at DGIST. I thank him for the lovely Korean tea that he gave me after our farewell sushi dinner at Akemi’s! I took a picture of the kind note Minho left to me with the box of tea, so that as with Biye’s note, it is part of my permanent record. During the time these postdocs were in the lab, I also acknowledge Jingyi Xu from the Technical University of Munich in Germany, who spent a half-year as a visiting PhD student, for her enthusiasm and creativity with robot grasping research.
To Ashwin Balakrishna and Brijen Thananjeyan, I’m not sure why you two are PhD students. You two are already at the level of faculty! If you ever want to discuss more ideas with me, please let me know. I will need to study how they operate to understand how to mentor a wide range of projects, as should be evident by the large number of AUTOLab undergraduates working with them. During the COVID-19 work-from-home period, it seemed as if one or both of them was part of all my AUTOLab meetings. I look forward to seeing their continued collaboration in safe reinforcement learning and similar topics, and maybe one day I will start picking up tennis so that running is not my only sport.
After I submitted the robot bed-making paper, I belatedly started mentoring new undergraduates in the AUTOLab. The first undergrad I worked with was Ryan Hoque, who had quickly singled me out as a potential graduate student mentor, while mentioning his interest in my blog (this is not an uncommon occurrence). He, and then later Aditya Ganapathi, were the first two undergraduates who I felt like I had mentored at least somewhat competently. I enjoyed working and debugging the fabric simulator we developed, which would later form the basis of much of our subsequent work published at IROS, RSS, and ICRA. I am happy that Ryan has continued his studies as a PhD student in the AUTOLab, focusing on interactive imitation learning. Regarding the fabrics-related work in the AUTOLab, I also thank the scientists at Honda Research Institute for collaborating with us: Nawid Jamali, Soshi Iba, and Katsu Yamane. I enjoyed our semi-regular meetings in Etcheverry Hall where we could go over research progress and brainstorm some of the most exciting ideas in developing a domestic home robot.
While all this was happening, I was still working with John Canny, and trying to figure out the right work balance with two advisors. Over the years, John would work with PhD students David Chan, Roshan Rao, Forrest Huang, Suhong Moon, Jinkyu Kim, and Philippe Laban, along with a talented Master’s student Chen (Allen) Tang. As befitting someone like John, his students work on a wider range of research areas than is typical for a research lab. (There is no official name for John Canny’s lab, so we decided to be creative and called it … “the CannyLab.”) With Jinkyu and Suhong, I learned more about explainable AI and its application for autonomous driving, and on the non-science side, I learned more about South Korea. Philippe taught me about natural language processing, summarizing text, and his “NewsLens” project resonated with me, given the wide variety of news that I read these days, and I enjoyed the backstory for why he was originally motivated to work on this. David taught me about computer vision (video captioning), Roshan taught me about proteins, and Forrest taught me about sketching. Philippe, David, Roshan, and Forrest also helped me understand Google’s shiny new neural network architecture, the Transformer, as well as closely-related architectures such as OpenAI’s GPT models. I also acknowledge David’s help for his work getting the servers set up for the CannyLab, and for his advice in building a computer. Allen Tang’s master’s thesis on how to accelerate deep reinforcement learning played a key role in my final research projects.
For my whole life, I had always wondered what it was like to intern at a company like Google, and have long watched in awe as Google churned out impressive AI research results. I had applied to Google twice earlier in my PhD, but was unable to land an internship. So, when the great Andy Zeng sent me a surprise email in late 2019, after my initial shock and disbelief wore off, I quickly responded with my interest in interning with him. After my research scientist internship under his supervision, I can confirm that the rumors are true: Andy Zeng is a fantastic intern host, and I highly recommend him. The internship in 2020 was virtual, unfortunately, but I still enjoyed the work and his frequent video calls helped to ensure that I stayed focused on producing solid research during my internship. I also appreciated the other Google researchers who I got to chat with throughout the internship: Pete Florence, Jonathan Tompson, Erwin Coumans, and Vikas Sindhwani. I have found that the general rule that others in the AUTOLab (I’m looking at you, Aditya Ganapathi) have told me is a good one to follow: “think of something, and if Pete Florence and Andy Zeng like it, it’s good, and if they don’t like it, don’t work on it.” Thank you very much for the collaboration!
The last two years of my PhD have felt like the most productive of my life. During this time, I was collaborating (virtually) with many AUTOLab members. In addition to those mentioned earlier, I want to acknowledge undergraduate Haolun (Harry) Zhang on dynamic cable manipulation, leading to the accurately-named paper Robots of the Lost Arc. I look forward to seeing Harry’s continued achievements at Carnegie Mellon University. I was also fortunate to collaborate more closely with Huang (Raven) Huang, Vincent Lim, and many other talented newer students to Ken Goldberg’s lab. Raven seems like a senior PhD student instead of just starting out, and Vincent is far more skilled than I could have imagined from a beginning undergraduate. Both have strong work ethics, and I hope that our collaboration shall one day lead to robots performing reliable lassoing and tossing. In addition, I also enjoyed my conversations with the newer postdocs to the AUTOLab, Daniel Brown and Ellen Novoseller, from whom I have learned a lot of inverse reinforcement learning and preference learning. Incoming PhD student Justin Kerr also played an enormous role in helping me work with the YuMi in my final days in the AUTOLab.
I also want to acknowledge the two undergraduates from John Canny’s lab who I collaborated with the most, Mandi Zhao and Abhinav Gopal. Given the intense pressure of balancing both coursework and others, I am impressed they were willing to stick around with me while we finalized our work with John Canny. With Mandi, I hope we can continue discussing research ideas and US-China relations over WeChat, and with Abhinav, I hope we can pursue more research ideas in offline reinforcement learning.
Besides those who directly worked with me, my experience at Berkeley was enriched by the various people from other labs who I got to interact with somewhat regularly. Largely through Biye, I got to know a fair amount of Chinese international students, among them include Hezheng Yin, Xuaner (Cecilia) Zhang, Qijing (Jenny) Huang, and Isla Yang. I enjoyed our conversations over dinners and I hope they enjoyed my cooking of salmon and panna cotta. I look forward to the next chapter in all of our lives. It’s largely because of my interaction with them that I decided I would do my best to learn more about anything related to China, which explains book after book that I have on my iBooks app.
My education at Berkeley benefited a great deal from what other faculty taught me during courses, research meetings, and otherwise. I was fortunate to take classes from Pieter Abbeel, Anca Dragan, Daniel Klein, Jitendra Malik, Will Fithian, Benjamin Recht, and Michael I. Jordan. I also took the initial iteration of Deep Reinforcement Learning (RL), back when John Schulman taught it, and I thank John for kindly responding to questions I had regarding Deep RL. Among these professors, I would like to particularly acknowledge Pieter Abbeel, who has regularly served as inspiration for my research, and somehow remembers me and seems to have the time to reply to my emails even though I am not a student of his nor a direct collaborator. His online lecture notes and videos in robotics and unsupervised learning are among those that I have consulted the most.
In addition to my two formal PhD advisors, I thank Sergey Levine and Masayoshi Tomizuka for serving on my qualifying exam committee. The days leading up to that event were among the most stressful I had experienced in my life, and I thank them for taking the time to listen to my research proposal. I also enjoyed learning more about deep reinforcement learning through Sergey Levine’s course and online lectures.
I also owe a great deal to the administrators at UC Berkeley. The ones who helped me the most, especially during the two times during my PhD when I felt like I had hit rock bottom (in late 2015 and early 2018), were able to offer guidance and do what the could to help me stay on track to finish my PhD. I don’t know all the details about what they did behind the scenes, but thank you, to Shirley Salanio, Audrey Sillers, Angie Abbatecola, and the newer administrators to BAIR. Like Angie, I am an old timer of BAIR. I was even there when it was called Berkeley Vision and Learning Center (BVLR), before we properly re-branded the organization to become Berkeley Artificial Intelligence Research (BAIR). I also thank their help in getting the BAIR Blog up and running.
My research was supported initially by a university fellowship, and then later by a six-year Graduate Fellowships for STEM Diversity (GFSD) which was formerly called the National Physical Science Consortium (NPSC) Fellowship. At the time I received the fellowship, I was in the middle of feeling stuck on several research progress. I don’t know precisely why they granted me the fellowship, but whatever their reasons, I am eternally grateful for the decision they made. One of the more unusual conditions of the GFSD fellowship is that recipients are to intern at the sponsoring agency, which for me was the National Security Agency (NSA). I went there for one summer in Laurel, Maryland, and got a partial peek past the curtain of the NSA. By design, the NSA is one of the most secretive United States government agencies, which makes it difficult for people to acknowledge the work they do. Being there allowed me to understand and appreciate the signals intelligence work that the NSA does on behalf of the United States. Out of my NSA contacts, I would like to particularly mention Grant Wagner and Arthur Drisko.
While initially apprehensive about Berkeley, I have now come to accept it for some of the best it has to offer. I will be thankful of the many cafes I spent time in around the city, along with the frequent running trails both on the streets and in the hills. I only wish that other areas of the country offered this many food and running options.
Alas, all things must come to an end. While my PhD itself is coming to a close, I look forward to working with my future supervisor, David Held, in my next position at Carnegie Mellon University. Throughout the time when I was searching for a postdoc, I thank other faculty who took the time out of their insanely busy schedules to engage with me and to offer research advice: Shuran Song of Columbia, Jeannette Bohg of Stanford, and Alberto Rodriguez of MIT. I am forever in awe of their research contributions, and I hope that I will be able to achieve a fraction of what they have done in their careers.
In a past life, I was an undergraduate at Williams College in rural Massachusetts, which boasts an average undergraduate student body of about 2000 students. When I arrived at campus on that fall day in 2010, I was clueless about computer science and how research worked in general. Looking back, Williams must have done a better job preparing me for the PhD than I expected. Among the professors there, I owe perhaps the most to my undergraduate thesis advisor, Andrea Danyluk, as well as the other Williams CS faculty who taught me at that time: Brent Heeringa, Morgan McGuire, Jeannie Albrecht, Duane Bailey, and Stephen Freund. I will do my best to represent our department in the research area, and I hope that the professors are happy with how my graduate trajectory has taken place. One day, I shall return in person to give a research talk, and will be able to (in the words of Duane Bailey) show off my shiny new degree. I also majored in math, and I similarly learned a tremendous amount from my first math professor, Colin Adams, who emailed me right after my final exam urging me to major in math. I also appreciate other professors who have left a lasting impression on me: Steven Miller, Mihai Stoiciu, Richard De Veaux, and Qing (Wendy) Wang. I appreciate their patience during my frequent visits to their office hours.
During my undergraduate years, I was extremely fortunate to benefit from two Research Experiences for Undergraduates (REUs), the first at Bard College with Rebecca Thomas and Sven Andersen, and the second at the University of North Carolina at Greensboro, with Francine Blanchet-Sadri. I thank the professors for offering to work with me. As with the Williams professors, I don’t think any of my REU advisors had anticipated that they would be helping to train a future roboticist. I hope they enjoyed working with me just as much as I enjoyed working with them. To everyone from those REUs, I am still thinking of all of you and wish you luck wherever you are.
I owe a great debt to Richard Ladner of the University of Washington, who helped me break into computer science. He and Rob Roth used to run a program called the “Summer Academy for Advancing Deaf and Hard of Hearing in Computing.” I attended one of the iterations of this program, and it exposed to me what it might have been like to be a graduate student. Near the end of the program, I spoke with Richard one-on-one, and asked him detailed questions about what he thought of my applying to PhD programs. I remember him expressing enthusiasm, but also some reservation: “do you know how hard it is to get in a top PhD program?” he cautioned me. I thanked him for taking the time out of his busy schedule to give me advice. In the upcoming years, I always remembered to work hard in the hopes of achieving a PhD. (The next time I visited the University of Washington, years later, I raced to Richard Ladner’s office the minute I could.) Also, as a fun little history note, when I was there that I decided to start my (semi-famous?) personal blog, which seemingly everyone at Berkeley’s EECS department has seen, in large part because I felt like I needed to write about computer science in order to understand it better. I still feel that way today, and I hope I can continue writing.
Finally, I would like to thank my family for helping me persevere throughout the PhD. It is impossible for me to adequately put in words how much they helped me survive. My frequent video calls with family members helped me to stay positive during the most stressful days of my PhD, and they have always been interested in the work that I do and anything else I might want to talk about. Thank you.
Reframing Reinforcement Learning as Sequence Modeling with Transformers?
The Transformer Network, developed by Google and presented in a NeurIPS 2017 paper, is one of the few papers that can truly claim to have fundamentally transformed (pun intended) the field of Artificial Intelligence. Transformer Networks have become the foundation of some of the most dramatic performance advances in Natural Language Processing (NLP). Two prominent examples are Google’s BERT model, which uses a bidirectional Transformer, and OpenAI’s line of GPT models, which uses a unidirectional Transformer. Both papers have substantially helped out their respective companies’ bottom line: BERT has boosted Google’s search capabilities to new tiers and OpenAI uses GPT-3 for automatic text generation in their first commercial product .
For a solid understand of Transformer Networks, it is probably best to read the original paper and try out sample code. However, the Transformer Network paper has also spawned a seemingly endless series of blog posts and tutorial articles, which can be solid references (though with high variance in quality). Two of my favorite posts are from well-known bloggers Jay Alammar and Lilian Weng, who serve as inspirations for my current blogging habits. Of course, I am also guilty of jumping on this bandwagon, since I wrote a blog post on Transformers a few years ago.
Transformers have changed the trajectory of NLP and other fields such as protein modeling (e.g., the MSA transformer) and computer vision. OpenAI has an ICML 2020 paper which introduces Image-GPT, and the name alone should be self-explanatory. But, what about the research area I focus on these days, robot learning? It seems like Transformers have had less impact in this area. To be clear, researchers have already tried to replace existing neural networks used in RL with Transformers, but this does not fundamentally change the nature of the problem, which is consistently framed as a Markov Decision Process where states follow the Markovian property of being a function of only the prior state and action.
That might now change. Earlier this month, two groups in BAIR released arXiv preprints that use Transformers for RL, and which do away with MDPs and treat RL as one big sequence modeling problem. They propose models called Decision Transformer and Trajectory Transformer. These have not yet been peer-reviewed, but judging from the format, it’s likely that both are under review for NeurIPS. Let’s dive into the papers, shall we?
Decision Transformer
This paper introduces the Decision Transformer, which takes a particular trajectory representation as input, and outputs action predictions at training time, or the actual actions at test time (i.e., evaluation).
First, how is a trajectory represented? In RL, these are typically a sequence of states, actions, and rewards. In this paper, however, they consider the return to go:
\[\hat{R}_t = \sum_{t'=t}^{T} r_{t'}\]resulting in the full trajectory representation of:
\[\tau = (\hat{R}_1, s_1, a_1, \hat{R}_2, s_2, a_2, \ldots, \hat{R}_T, s_T, a_t)\]This already raises the question of why this representation is chosen. The reason is that at test time, the Decision Transformer must be paired up with a desired performance, which is cumulative episodic return. Given that as input, after each time step, the agent gets the per-time step reward from the environment emulator, and decreases the desired performance by that amount. Then, this revised desired performance value is passed again as input, and the process repeats. The immediate question I had after this was whether it would be possible to predict the return-to-go accurately, and if the Decision Transformer could extrapolate beyond the best return-to-go in the training data. Spoiler alert: the paper reports experiments with this, finding a strong correlation between predicted and actual return, and it is possible to extrapolate beyond the best return in the data, but only by a little bit. That’s fair, it would be unrealistic to assume it could get any return-to-go feasible from the environment emulator.
The input to the Decision Transformer is a subset of the trajectory $\tau$ consisting of the $K$ most recent time steps, each of which consists of a tuple with three items as noted above (the return-to-go, state, and action). Note how this differs from a DQN-style method, which for each time step, takes in 4 stacked game frames but does not take in rewards or prior actions as input. Furthermore, in this paper, Decision Transformers use values such as $K=30$, so they consider a longer history.
The output of Decision Transformer simply requires predicting an action (during training), so it can be trained with the usual cross-entropy or mean square error loss functions, depending on whether the action is discrete or continuous.
Now, what is the architecture for predicting or generating actions? Decision Transformers use GPT, which is an auto-regressive model which means it handles probabilities of the form $p(x_t | x_{t-1}, \ldots, x_1)$ where the prediction of something at a current time is conditioned on all prior data. GPT uses this to generate (that’s what the “G” stands for) by sampling the $x_t$ term. In my notation of the $x_i$ terms, imagine all of those represent data tuples of (return-to-go, state, action) – that’s what the GPT model deals with, and it produces the next predicted tuple. Well, technically they only need to predict the action, but I wonder if state prediction could be useful? From communicating with the authors, they didn’t get much performance benefit from predicting states, but it is doable.
There are also various embedding layers applied on the input before it is passed to the GPT model. I highly recommend looking at Algorithm 1 in the paper, which has it in nicely written pseudocode. The Appendix also clarifies the code bases that they build upon, and both are publicly available. Andrej Karpathy’s miniGPT code looks nice and is self-contained.
That’s it! Notice how the Decision Transformer does not do bootstrapping to estimate value functions.
The paper evaluates on a suite of offline RL tasks, using environments from Atari (discrete control), from D4RL (continuous control), and from a “Key-to-Door” task. Fortunately for me, I had recently done a lot of reading on offline RL, and I even wrote a survey-style blog post about it a few months ago. The Decision Transformer is not specialized towards offline RL. It just happens to be the problem setting the paper considers, because not only is it very important, it is also a nice fit in that (again) the Decision Transformer does not perform bootstrapping, which is known to cause diverging Q-values in many offline RL contexts.
The results suggest that Decision Transformer is on par with state-of-the-art offline RL algorithms. It is a little worse on Atari, and a little better on D4RL. It seems to do a lot better on the Key-to-Door task but I’m not sufficiently familiar with that benchmark. However, since the paper is proposing an approach fundamentally different from most RL methods, it is impressive to get similar performance. I expect that future researchers will build upon the Decision Transformer to improve its results.
Trajectory Transformer
Now let us consider the second paper, which introduces the Trajectory Transformer. As with the prior paper, it departs from the usual MDP assumptions, and it also does not require dynamic programming or bootstrapped estimates. Instead, it directly uses properties from the Transformer to encode all the ingredients it needs for a wide range of control and decision-making problems. As it borrows techniques from language modeling, the paper argues that the main technical innovation is understanding how to represent a trajectory. Here, the trajectories $\tau$ are represented as:
\[\tau = \{ \mathbf{s}_t^0, \mathbf{s}_t^{1}, \ldots, \mathbf{s}_t^{N-1}, \mathbf{a}_t^0, \mathbf{a}_t^{1}, \ldots, \mathbf{a}_t^{M-1}, r_t \}_{t=0}^{T-1}\]My first reaction was that this looks different than the trajectory representation for Decision Transformers. There’s no return-to-go written here, but this is a little misleading. The Trajectory Transformer paper tests three decision-making settings: (1) imitation learning, (2) goal-conditioned RL, and (3) offline RL. The Decision Transformer paper focuses on applying the framework to offline RL only. For offline RL, the Trajectory Transformer actually uses the return-to-go as an extra component in each data tuple in $\tau$. So I don’t believe there is any fundamental difference in terms of the trajectory consisting of states, actions, and return-to-go, though the Trajectory Transformer seems to also take in the current scalar $r_t$ as input, so that could be one difference, and it also appears to use a discount factor in the return-to-go. Both seem minor.
Perhaps a more fundamental difference is with discretization. The Decision Transformer paper doesn’t mention discretization, and from contacting the authors, I confirm they did not discretize. So for continuous states and actions, the Decision Transformer likely just represents them as vectors in $\mathbb{R}^d$ for some suitable $d$ representing the state or action dimension. In contrast, Trajectory Transformers use discretized states and actions as input, and the paper helpfully explains how the indexing and offsets work. While this may be inefficient, the paper states, it allows them to use a more expressive model. My intuition for this phrase comes from histograms — in theory, histograms can represent arbitrarily complex 1D data distributions, whereas a 1D Gaussian must have a specific “bell-shaped” structure.
As with the Decision Transformer, the Trajectory Transformer uses a GPT as its backbone, and is trained to optimize log probabilities of states, actions, and rewards, conditioned on prior information in the trajectory. This enables test-time prediction by sampling from the trained model using what is known as beam search. This is another core difference between the Trajectory Transformer and Decision Transformer. The former uses beam search, the latter does not, and that’s probably because with discretization, it may be easier to do multimodal reasoning.
For quantitative results, they again test on D4RL for offline RL experiments. The results suggest that Trajectory Transformers are competitive with prior state-of-the-art offline RL algorithms. Again, as with Decision Transformers, the results aren’t significant improvements, but the fact that they’re able to get to this performance for the first iteration of this approach is impressive in its own right. They also show a nice qualitative visualization where their Trajectory Transformer can produce a long sequence of predicted trajectories of a humanoid, whereas a popular state-of-the-art model-based RL algorithm known as PETS makes significantly worse predictions.
The project website succinctly summarizes the comparisons between Trajectory Transformer and Decision Transformer as follows:
Chen et al concurrently proposed another sequence modeling approach to reinforcement learning. At a high-level, ours is more model-based in spirit and theirs is more model-free, which allows us to evaluate Transformers as long-horizon dynamics models (e.g., in the humanoid predictions above) and allows them to evaluate their policies in image-based environments (e.g., Atari). We encourage you to check out their work as well.
To be clear, the idea that Trajectory Transformer is model-based and that Decision Transformer is model-free is partly because the former predicts states, whereas the latter only predicts actions.
Concluding Thoughts
Both papers show that we can consider RL as a sequence learning problem, where Transformers can take in a long sequence of data and predict something. The two approaches can get around the “deadly triad” in RL since bootstrapping value estimates is not necessary. The use of Transformers enables building upon an extensive literature for Transformers in other fields — and it’s very extensive, despite how Transformers are only 4 years old (it has an absurd 22955 Google Scholar citations as of today)! The models use the same fundamental backbone, and I wonder if there are ways to merge the approaches. Would beam search, for example, be helpful in Decision Transformers, and would conditioning on return-to-go be helpful for Trajectory Transformer?
To reitertate, the results are not “out of this world” compared to current state-of-the-art RL using MDPs, but as a first step, these look impressive. Moreover, I am guessing that the research teams are busy extending the capabilities of these models. These two papers have very high impact potential. Assuming the research community is able to improve upon these models, this approach may even become the standard treatment for RL. I am excited to see what will come.
My PhD Dissertation Talk
The long wait is over. After many years, I am excited to share that I delivered my PhD dissertation talk. I gave it on May 13, 2021 via Zoom. I recorded the 45-minute talk and you can find the video above.
I had multiple opportunities to practice the PhD talk, as I gave several talks earlier with a substantial amount of overlap, such as the one “at” Toronto in March (see the blog post here). My PhD talk, like prior talks, heavily focuses on robot manipulation of deformables, and includes discussions of my IROS 2020, RSS 2020, and ICRA 2021 papers. However, I wanted the focus to be broader than deformable manipulation alone, so I structured the talk to feature “robot learning” prominently, of which “deformable manipulation” is one particular example of robot learning. Then, rather than go through the “Model-Free,” “Model-Based,” and “Transporter Network” sections from my prior talks, I chose to title talk sections as follows: “Simulated Interactions,” “Architectural Priors,” and “Curricula.” This also gave me the chance to feature some of my curriculum learning work with John Canny.
The audience had some questions at the end, but overall, the questions were generally not too difficult to answer. Perhaps in years past, it was typical to have very challenging questions at the end of a dissertation talk, and students may have failed if they couldn’t answer well enough. Nowadays, every Berkeley EECS PhD student who gives a dissertation talk is expected to pass. I’m not aware of anyone failing after giving the talk.
I want to thank everyone who helped me get to this point today, especially when earlier in my PhD, I thought I would never reach this point. Or at the very least, I thought I would not have as strong a research record as I now have. A proper and more detailed set of acknowledgments will come at a later date.
I am not a “Doctor” yet, since I still need to write up the actual dissertation itself, which I will do this summer by “stitching” together my 4-5 most relevant first-author papers. Nonetheless, giving this talk is a huge step forward in finishing up my PhD, and I am hugely relieved that it’s out of the way.
I will also be starting a postdoc position in a few months. More on that to come later …
Inverse Reinforcement Learning from Preferences
It’s been a long time since I engaged in a detailed read through of an inverse reinforcement learning (IRL) paper. The idea is that, rather than the standard reinforcement learning problem where an agent explores to get samples and finds a policy to maximize the expected sum of discounted rewards, we instead are given data already, and must determine the reward function. After this reward function is learned, one can then learn a new policy based on this reward function by running standard reinforcement learning, but where the rewards for each state (or state-action) is determined from the learned reward function. As a side note, since this appears to be quite common and “part of” IRL, then I’m not sure why IRL is often classified as an “imitation learning” algorithm when reinforcement learning has to be run as a subroutine. Keep this in mind when reading papers on imitation learning, which often categorize algorithms as supervised learning (e.g., behavioral cloning) approaches vs IRL approaches, such as in the introduction of the famous Generative Adversarial Imitation Learning paper.
In the rest of this post, we’ll cover two closely-related works on IRL that cleverly and effectively rely on preference rankings among trajectories. They also have similar acronyms: T-REX and D-REX. The T-REX paper presents the Trajectory-ranked Reward Extrapolation algorithm, which is also used in the D-REX paper (Disturbance-based Reward Extrapolation). So we shall first discuss how reward extrapolation works in T-REX, and then we will clarify the difference between the two papers.
T-REX and D-REX
The motivation for T-REX is that in IRL, most approaches rely on defining a reward function which explains the demonstrator data and makes it appear optimal. But, what if we have suboptimal demonstrator data? Then, rather than fit a reward function to this data, it may be better to instead figure out the appropriate features of the data that convey information about the underlying intentions of the demonstrator, which may be extrapolated beyond the data. T-REX does this by working with a set of demonstrations which are ranked.
To be concrete, denote a sequence of $m$ ranked trajectories:
\[\mathcal{D} = \{ \tau_1, \ldots, \tau_m \}\]where if $i<j$, then $\tau_i \prec \tau_j$, or in other words, trajectory $\tau_i$ is worse than $\tau_j$. We’ll assume that each $\tau_i$ consists of a series of states, so that neither demonstrator actions nor the reward are needed (a huge plus!):
\[\tau_i = (s_0^{(i)}, s_1^{(i)}, \ldots, s_T^{(i)})\]and we can also assume that the trajectory lengths are all the same, though this isn’t a strict requirement of T-REX (since we can normalize based on length) but probably makes it more numerically stable.
From this data $\mathcal{D}$, T-REX will train a learned reward function $\hat{R}_\theta(s)$ such that:
\[\sum_{s \in \tau_i} \hat{R}_\theta(s) < \sum_{s \in \tau_j} \hat{R}_\theta(s) \quad \mbox{if} \quad \tau_i \prec \tau_j\]To be clear, in the above equation there is no true environment reward at all. It’s just the learned reward function $\hat{R}_\theta$, along with the trajectory rankings. That’s it! One may, of course, use the true reward function to determine the rankings in the first place, but that is not required, and that’s a key flexibility advantage for T-REX – there are many other ways we can rank trajectories.
In order to train $\hat{R}_\theta$ so the above criteria is satisfied, we can use the cross entropy loss function. Most people probably start using the cross-entropy loss function in the context of classification tasks, where the neural network outputs some “logits” and the loss function tries to “get” the logits to match a true one-hot vector distribution. In this case, the logic is similar. The output of the reward network forms the (un-normalized) probability that one trajectory is preferable to another:
\[P(\hat{J}_\theta(\tau_i) < \hat{J}_\theta(\tau_j)) \approx \frac{\exp \sum_{s \in \tau_j} \hat{R}_\theta(s) }{ \exp \sum_{s \in \tau_i}\hat{R}_\theta(s) + \exp \sum_{s \in \tau_j}\hat{R}_\theta(s) }\]when we then use in this loss function:
\[\mathcal{L}(\theta) = - \sum_{\tau_i \prec \tau_j } \log \left( \frac{\exp \sum_{s \in \tau_j} \hat{R}_\theta(s) }{\exp \sum_{s \in \tau_i} \hat{R}_\theta(s)+ \exp \sum_{s \in \tau_j}\hat{R}_\theta(s) } \right)\]Let’s deconstruct what we’re looking at here. The loss function $\mathcal{L}(\theta)$ for training $\hat{R}_\theta$ is binary cross entropy, where the two “classes” involved here are whether $\tau_i \succ \tau_j$ or $\tau_i \prec \tau_j$. (We can easily extend this to include cases when the two are equal, but let’s ignore for now.) Above, the true class corresponds to $\tau_i \prec \tau_j$.
If this isn’t clear then reviewing the cross entropy (e.g., from this source), we see that between a true distribution “$p$” and a predicted distribution “$q$”, it is defined as: $-\sum_x p(x) \log q(x)$ where the sum over $x$ iterates through all possible classes – in this case we only have two classes. The true distribution is $p=[0,1]$ if we interpret the two components as expressing the class $\tau_i \succ \tau_j$ at index 0, or $\tau_i \prec \tau_j$ at index 1. In all cases, the “class” we assign is to index 1 by design. The predicted distribution comes from the output of the reward function network:
\[q = \Big[1 - P(\hat{J}_\theta(\tau_i) < \hat{J}_\theta(\tau_j)), \; P(\hat{J}_\theta(\tau_i) < \hat{J}_\theta(\tau_j)) \Big]\]and putting this together, the cross entropy term reduces to $\mathcal{L}(\theta)$ as shown above, for a single training data point (i.e., a single training pair $(\tau_i, \tau_j)$). We would then sample many of these pairs during training for each minibatch.
To get this to work in cases when the two trajectories are ambiguous, then you can set the “target” distribution to be $[0.5, 0.5]$. This is made explicit in this NeurIPS 2018 paper from DeepMind which uses the same loss function.
The main takeaway is that this process will learn a reward function assigning greater total return to higher ranked trajectories. As long as there are features associated with higher return that are identifiable from the data, then it may be possible to extrapolate beyond the data.
Once the reward function is learned, T-REX then runs policy optimization by running reinforcement learning, which in both papers here is Proximal Policy Optimization. This is done in an online fashion, but where instead of data coming in as $(s,a,r,s’)$ tuples, they will be $(s,a,\hat{R}_\theta(s),s’)$, where the reward is from the learned policy.
This makes sense, but as usual, there are a bunch of practical tips and tricks to get things working. Here are some for T-REX:
-
For many environments, “trajectories” often refer to “episodes”, but these can last for a large number of time steps. To perform data augmentation, one can subsample trajectories of the same length among pairs of trajectories $\tau_i$ and $\tau_j$.
-
Training an ensemble of reward functions for $\hat{R}_\theta$ often helps, provided the individual components have values at roughly the same scale.
-
The reward used for the policy optimization stage might need some extra “massaging” to it. For example, with MuJoCo, the authors use a control penalty term that gets added to $\hat{R}_\theta(s)$.
-
To check if reward extrapolation is feasible, one can plot a graph that shows ground truth returns on the x-axis and predicted return on the y-axis. If there is strong correlation among the two, then that’s a sign extrapolation is more likely to happen.
In both T-REX and D-REX, the authors experiment with discrete control and continuous control using standard environments from Atari and MuJoCo, respectively, and find that overall, their two stage approach of (1) finding $\hat{R}_\theta$ from preferences and (2) running PPO on top of this learned reward function, works better than competing baselines such as Behavior Cloning and Generative Adversarial Imitation Learning, and that they can exceed the performance of the demonstration data.
The above is common to both T-REX and D-REX. So what’s the difference between the two papers?
-
T-REX assumes that we have rankings available ahead of time. This can be from a number of sources. Maybe they were “ground truth” rankings based on ground truth rewards (i.e., just sum up the true reward within the $\tau_i$s), or they might be noisy rankings. An easy way to test noisy rankings is to rank trajectories based on the time in training history if we extract trajectories from an RL agent’s history. Another, but more cumbersome way (since it relies on human subjects) is to use Amazon Mechanical Turk. The T-REX paper does a splendid job testing these different rankings – it’s one reason I really like the paper.
-
In contrast, D-REX assumes these rankings are not available ahead of time. Instead, the approach involves training a policy from the provided demonstration data via Behavior Cloning, then taking that resulting snapshot and rolling it out in the environment with different noise levels. This naturally provides a ranking for the data, and only relies on the weak assumption that the Behavior Cloning agent will be better than a purely random policy. Then with these automatic rankings, D-REX can just do exactly what T-REX did!
-
D-REX makes a second contribution on the theoretical side to better understand why preferences over demonstrations can reduce reward function ambiguity in IRL.
Some Theory in D-REX
Here’s a little more on the theory from D-REX. We’ll follow the notation from the paper and state Theorem 1 here (see the paper for context):
If the estimated reward function is $\;\hat{R}(s) = w^T\phi(s),\;$ the true reward function is \(\;R^*(s) = \hat{R}(s) + \epsilon(s)\;\) for some error function \(\;\epsilon : \mathcal{S} \to \mathbb{R}\;\) and \(\;\|w\|_1 \le 1,\;\) then extrapolation beyond the demonstrator, i.e., \(\; J(\hat{\pi}|R^*) > J(\mathcal{D}|R^*),\;\) is guaranteed if:
\[J(\pi_{R^*}^*|R^*) - J(\mathcal{D}|R^*) > \epsilon_\Phi + \frac{2\|\epsilon\|_\infty}{1 - \gamma}\]where \(\;\pi_{R^*}^* \;\) is the optimal policy under $R^*$, \(\;\epsilon_\Phi = \| \Phi_{\pi_{R^*}^*} - \Phi_{\hat{\pi}}\|_\infty,\;\) and \(\|\epsilon\|_\infty = {\rm sup}\{ | \epsilon(s)| : s \in \mathcal{S} \}\).
To clarify the theorem, $\hat{\pi}$ is some learned policy for which we want to outperform the average episodic return in the demonstration data $J(\mathcal{D}|R^*)$. We begin by considering the difference in return between the optimal policy under the true reward (which can’t be exceeded w.r.t. that reward by definition) and the expected return of the learned polcy (also under that true reward):
\[\begin{align} J(\pi_{R^*}^*|R^*) - J(\hat{\pi}|R^*) \;&{\overset{(i)}=}\;\; \left| \mathbb{E}_{\pi_{R^*}^*} \Big[ \sum_{t=0}^\infty \gamma^t R^*(s) \Big] - \mathbb{E}_{\hat{\pi}} \Big[ \sum_{t=0}^\infty \gamma^t R^*(s) \Big] \right| \\ \;&{\overset{(ii)}=}\;\; \left| \mathbb{E}_{\pi_{R^*}^*} \Big[ \sum_{t=0}^\infty \gamma^t (w^T\phi(s_t)+\epsilon(s_t)) \Big] - \mathbb{E}_{\hat{\pi}} \Big[ \sum_{t=0}^\infty \gamma^t (w^T\phi(s_t)+\epsilon(s_t)) \Big] \right| \\ \;&{\overset{(iii)}=}\; \left| w^T\Phi_{\pi_{R^*}^*} + \mathbb{E}_{\pi_{R^*}^*} \Big[ \sum_{t=0}^\infty \gamma^t \epsilon(s_t) \Big] - w^T\Phi_{\hat{\pi}} - \mathbb{E}_{\hat{\pi}} \Big[ \sum_{t=0}^\infty \gamma^t \epsilon(s_t) \Big] \right| \\ \;&{\overset{(iv)}\le}\;\; \left| w^T(\Phi_{\pi_{R^*}^*} -\Phi_{\hat{\pi}}) + \mathbb{E}_{\pi_{R^*}^*} \Big[ \sum_{t=0}^\infty \gamma^t \sup_{s\in \mathcal{S}} \epsilon(s) \Big] - \mathbb{E}_{\hat{\pi}} \Big[ \sum_{t=0}^\infty \gamma^t \inf_{s \in \mathcal{S}} \epsilon(s) \Big] \right| \\ \;&{\overset{(v)}=}\;\; \left| w^T(\Phi_{\pi_{R^*}^*} -\Phi_{\hat{\pi}}) + \Big( \sup_{s\in \mathcal{S}} \epsilon(s) - \inf_{s \in \mathcal{S}} \epsilon(s) \Big) \sum_{t=0}^{\infty} \gamma^t \right| \\ \;&{\overset{(vi)}\le}\;\; \left| w^T(\Phi_{\pi_{R^*}^*} -\Phi_{\hat{\pi}}) + \frac{2 \|\epsilon\|_\infty}{1-\gamma} \right| \\ \;&{\overset{(vii)}\le}\;\; \left| w^T(\Phi_{\pi_{R^*}^*} -\Phi_{\hat{\pi}})\right| + \frac{2 \|\epsilon\|_\infty}{1-\gamma} \\ \;&{\overset{(viii)}\le}\; \|w\|_1 \|\Phi_{\pi_{R^*}^*} -\Phi_{\hat{\pi}})\|_\infty + \frac{2 \|\epsilon\|_\infty}{1-\gamma} \\ &{\overset{(ix)}\le}\; \epsilon_\Phi + \frac{2\|\epsilon\|_\infty}{1 - \gamma} \end{align}\]where
-
in (i), we apply the definition of the terms and put absolute values around the terms. I don’t think this is necessary since the LHS must be positive, but it doesn’t hurt.
-
in (ii), we substitute $R^*$ with the theorem’s assumption about both the error function and how the estimated reward is a linear combination of features.
-
in (iii) we move the weights $w$ outside the expectation as they are constants and we can use linearity of expectation. Then we use the paper’s definition of $\Phi_\pi$ as the expected feature counts for given policy $\pi$.
-
in (iv) we move the two $\Phi$ terms together (notice how this matches the theorem’s $\epsilon_\Phi$ definition), and we then make this an inequality by looking at the expectations and applying “sup”s and “infs” to each time step. This is saying if we have $A-B$ then let’s make the $A$ term larger and the $B$ term smaller. Since we’re doing this for an infinite amount of time steps, I am somewhat worried that this is a loose bound.
-
in (v) we see that since the “sup” and “inf” terms no longer depend on $t$, we can move them outside the expectations. In fact, we don’t even need expectations anymore, since all that’s left is a sum over discounted $\gamma$ terms.
-
in (vi) we apply the geometric series formula to get rid of the sum over $\gamma$ and then the inequality results from replacing the “sup”s and “inf”s with the \(\| \epsilon \|_\infty\) from the theorem statement – the “2” helps to cover the extremes of a large positive error and a large negative error (note the absolute value in the theorem condition, that’s important).
-
in (vii) we apply the Triangle Inequality.
-
in (viii) we apply Hölder’s inequality.
-
finally, in (ix) we apply the theorem statements.
We now take that final inequality and subtract the average demonstration data return on both sides:
\[\underbrace{J(\pi_{R^*}^*|R^*)- J(\mathcal{D}|R^*)}_{\delta} - J(\hat{\pi}|R^*) \le \epsilon_\Phi + \frac{2\|\epsilon\|_\infty}{1 - \gamma} - J(\mathcal{D}|R^*)\]Now we finally invoke the “if” condition in the theorem. If the equation in the theorem holds, then we can replace $\delta$ above as follows since it’s just reducing the LHS:
\[\epsilon_\Phi + \frac{2\|\epsilon\|_\infty}{1 - \gamma} - J(\hat{\pi}|R^*) \le \epsilon_\Phi + \frac{2\|\epsilon\|_\infty}{1 - \gamma} - J(\mathcal{D}|R^*)\]which implies:
\[- J(\hat{\pi}|R^*) \le - J(\mathcal{D}|R^*) \quad \Longrightarrow \quad J(\hat{\pi}|R^*) > J(\mathcal{D}|R^*),\]showing that $\hat{\pi}$ has extrapolated beyond the data.
What’s the intuition behind the theorem? The LHS of the theorem shows the difference in the return based on the optimal policy versus the demonstration data. By definition of optimality, the LHS is at least 0, but it can get very close to 0 if the demonstration data is very good. That’s not good for extrapolation, and hence the condition for outperforming the demonstrator is less likely to hold (which makes sense). Focusing on the RHS, we see that it’s value is larger if the maximum error in $\epsilon$ is large. This might be a very restrictive condition, since it’s considering the maximum absolute error over the entire state set $\mathcal{S}$. Since there are an infinite amount of states in many practical applications, this means even one large error might cause the inequality in the theorem statement to fail.
The proof also relies on the assumption that the estimated reward function is a linear combination of features (that’s what $\hat{R}(s)=w^T\phi(s)$ means) but $\phi$ could contain arbitrarily complex features, so I guess it’s a weak assumption (which is good), but I am not sure?
Concluding Remarks
Overall, the T-REX and D-REX papers are nice IRL papers that rely on preferences between trajectories. The takeaways I get from these works:
-
While reinforcement learning may be very exciting, don’t forget about the perhaps lesser-known task of inverse reinforcement learning.
-
Taking subsamples of trajectories is a helpful way to do data augmentation when doing anything at the granularity of episodes.
-
Perhaps most importantly, I should understand when and how preference rankings might be applicable and beneficial. In these works, preferences enable them to train an agent to perform better than demonstrator data without strictly requiring ground truth environment rewards, and potentially without even requiring demonstrator actions (though D-REX requires actions).
I hope you found this post helpful. As always, thank you for reading, and stay safe.
Papers covered in this blog post:
-
Daniel S. Brown, Wonjoon Goo, Prabhat Nagarajan, Scott Niekum. Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations, ICML 2019.
-
Daniel S. Brown, Wonjoon Goo, Scott Niekum. Better-than-Demonstrator Imitation Learning via Automatically-Ranked Demonstrations, CoRL 2019.
Research Talk at the University of Toronto on Robotic Manipulation
A video of my talk at the University of Toronto with the Q-and-A at the end.
Last week, I was very fortunate to give a talk “at” the University of Toronto in their AI in Robotics Reading Group. It gives a representative overview of my recent research in robotic manipulation. It’s a technical research talk, but still somewhat high-level, so hopefully it should be accessible to a broad range of robotics researchers. I normally feel embarrassed when watching recordings of my talks, since I realize I should have done X instead of Y in so many places. Fortunately I think this one turned out reasonably well. Furthermore, and to my delight, the YouTube / Google automatic captions captured my audio with a high degree of accuracy.
My talk covers these three papers in order:
- Deep Imitation Learning of Sequential Fabric Smoothing From an Algorithmic Supervisor, IROS 2020.
- VisuoSpatial Foresight for Multi-Step, Multi-Task Fabric Manipulation, RSS 2020.
- Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks, ICRA 2021.
We covered the first two papers in a BAIR Blog post last year. I briefly mentioned the last one in a personal blog post a few months ago, with the accompanying backstory behind how we developed it. A joint Google AI and BAIR Blog post is in progress … I promise!
Regarding that third paper (for ICRA 2021), when making this talk in Keynote, I was finally able to create the kind of animation that shows the intuition for how a Goal-Conditioned Transporter Network works. Using Google Slides is great for drafting talks quickly, but I think Keynote is better for formal presentations.
I thank the organizers (Homanga Bharadhwaj, Arthur Allshire, Nishkrit Desai, and Professor Animesh Garg) for the opportunity, and I also thank them for helping to arrange the two sign language interpreters for my talk. Finally, if you found this talk interesting, I encourage you to view the talks from the other presenters in the series.
Getting Started with SoftGym for Deformable Object Manipulation
This is a regularly updated post, last updated October 05, 2023.

Visualization of the PourWater environment from SoftGym. The animation is
from the project website.
Over the last few years, I have enjoyed working on deformable object manipulation for robotics. In particular, it was the focus of my Google internship work, and I previously did some work with deformables before that, highlighted with our BAIR Blog post here. In this post, I’d like to discuss the SoftGym simulator, developed by researchers from Carnegie Mellon University in their CoRL 2020 paper. I’ve been exploring this simulator to see if it might be useful for my future projects, and I am impressed by the simulation quality and how it also has support for fluid simulation. The project website has more information and includes impressive videos. This blog post will be similar in spirit to one I wrote almost a year ago about using a different code base (rlpyt) with a focus on the installation steps for SoftGym.
Installing SoftGym
The first step is to install SoftGym. The provided README has some information but it wasn’t initially clear to me, as shown in my GitHub issue report. As I stated in my post on rlpyt, I like making long and detailed GitHub issue reports that are exactly reproducible.
The main thing to understand when installing is that if you’re using an Ubuntu 16.04 machine, you (probably) don’t have to use Docker. (However, Docker is incredibly useful in its own right, so I encourage you to learn how to use it if you haven’t done so already.) If you’re using Ubuntu 18.04, then you definitely have to use Docker. However, Docker is only used to compile PyFleX, which has the physics simulation for deformables. The rest of the repository can be managed through a standard conda environment.
Here’s a walk-through of my installation and compilation steps on an Ubuntu 18.04 machine, and I assume that conda is already installed. If conda is not installed, I encourage you to check another blog post which describes my conda workflow.
So far, the code has worked for me on a variety of CUDA and NVIDIA driver versions. You can find the CUDA version by running:
seita@mason:~ $ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
For example, the above means I have CUDA 10.0. Similarly, the driver version
can be found from running nvidia-smi.
Now let’s get started by cloning the repository and then creating the conda environment:
conda env create -f environment.yml
This command will create a conda environment that has the necessary packages with their correct version. However, there’s one more package to install, the pybind11 package, so I would install that after activating the environment:
conda activate softgym
conda install pybind11
At this point, the conda environment should be good to go.
Next we have the most interesting part, where we use Docker. Here’s the installation guide for Ubuntu machines in case it’s not installed on your machine yet. I’m using Docker version 19.03.6. A quick refresher on terminology: Docker has images and containers. An image is like a recipe, whereas a container is an instance of it. StackOverflow has a more detailed explanation. Therefore, after running this command:
docker pull xingyu/softgym
we are downloading the author’s pre-provided Docker image, and it should be
listed if you type in docker images on the command line:
seita@mason:~$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
xingyu/softgym latest 2cbcd6a50965 3 months ago 2.44GB
If you’re running into issues with requiring “sudo”, you can mitigate this by adding yourself to a “Docker group” so that you don’t have to type it in each time. This Ask Ubuntu post might be helpful.
Next, we have to run a command to start a container. Here, we’re using
nvidia-docker since this requires CUDA, as one would expect given that FleX
is from NVIDIA. This is not installed when you install Docker, so please refer
to this page for installation instructions. Once that’s done, to be safe,
I would check to make sure that nvidia-docker -v works on your command line
and that the version matches what’s printed from docker -v. I don’t know if
it is necessary to have the two versions match.
As mentioned earlier, we have to start a container. Here is the command I use:
(softgym) seita@mason:~/softgym$ nvidia-docker run \
-v /home/seita/softgym:/workspace/softgym \
-v /home/seita/miniconda3:/home/seita/miniconda3 \
-v /tmp/.X11-unix:/tmp/.X11-unix \
--gpus all \
-e DISPLAY=$DISPLAY \
-e QT_X11_NO_MITSHM=1 \
-it xingyu/softgym:latest bash
Here’s an explanation:
- The first
-vwill mount/home/seita/softgym(i.e., where I cloned softgym) to/workspace/softgyminside the Docker container’s file system. Thus, when I enter the container, I can change directory to/workspace/softgymand it will look as if I am in/home/seita/softgymon the original machine. The/workspaceseems to be the default directory we start in Docker containers. - A similar thing happens with the second mounting command for miniconda. In fact I’m using the same exact directory before and after the colon, which means the directory structure is the same inside the container.
- The
-itandbashportions will create an environment in the container which lets us type in things on the command line, like with normal Ubuntu machines. Here, we will be the root user. The Docker documentation has more information about these arguments. Note that-itis shorthand for-i -t. - The other commands are copied from the SoftGym Docker README.
October 2023 update: if you are running Ubuntu 22.04, I have gotten the
compilation working with a few modifications. First, I use docker instead of
nvidia-docker since it seems like a separate nvidia-docker installation is
not necessary. Second, I omit the --gpus all argument.
Running the command means I enter a Docker container as a “root” user, and you
should be able to see this container listed if you type in docker ps in
another tab (outside of Docker) since that shows the activate container IDs. At
this point, we should go to the softgym directory and run the scripts to (1)
prepare paths and (2) compile PyFleX:
root@82ab689d1497:/workspace# cd softgym/
root@82ab689d1497:/workspace/softgym# export PATH="/home/seita/miniconda3/bin:$PATH"
root@82ab689d1497:/workspace/softgym# . ./prepare_1.0.sh
(softgym) root@82ab689d1497:/workspace/softgym# . ./compile_1.0.sh
The above should compile without errors. That’s it! One can then exit Docker (just type in “exit”), though I actually would recommend keeping that Docker tab/window open on your command line editor, because any changes to the C++ code will require re-compiling it, so having the Docker already set in place to compile with one command makes things easier. Adjusting the C++ code is (almost) necessary if you wish to create custom environments.
If you are using Ubuntu 16.04, the steps should be similar but also much simpler, and here is the command history that I have when using it:
git clone https://github.com/Xingyu-Lin/softgym.git
cd softgym/
conda env create -f environment.yml
conda activate softgym
. ./prepare_1.0.sh
. ./compile_1.0.sh
cd ../../..
The last change directory command is because the compile script changes my
path. Just go back to the softgym/ directory and you’ll be ready to run.
Code Usage
Back in our normal Ubuntu 18.04 command line setting, we should make sure our conda environment is activated, and that paths are set up appropriately:
(softgym) seita@mason:~/softgym$ export PYFLEXROOT=${PWD}/PyFlex
(softgym) seita@mason:~/softgym$ export PYTHONPATH=${PYFLEXROOT}/bindings/build:$PYTHONPATH
(softgym) seita@mason:~/softgym$ export LD_LIBRARY_PATH=${PYFLEXROOT}/external/SDL2-2.0.4/lib/x64:$LD_LIBRARY_PATH
To make things easier, you can use a script like their provided
prepare-1.0.sh to adjust paths for you, so that you don’t have to keep typing
in these “export” commands manually.
Finally, we have to turn on headless mode for SoftGym if running over a remote machine. This was a step that tripped me up for a while, even though I’m usually good about remembering this after having gone through similar issues using the Blender simulator (for rendering fabric images remotely). Commands like this should hopefully work, which run the chosen environment and have the agent take random actions:
(softgym) seita@mason:~/softgym$ python examples/random_env.py --env_name ClothFlatten --headless 1
If you are running on a local machine with a compatible GPU, you can remove the headless option to have the animation play in a new window. Be warned, though: the size of the window should remain fixed throughout, since the code appends frames together, so don’t drag and resize the window. You can right click on the mouse to change the camera angle, and use W-A-S-D keyboard keys to navigate.
The given script might give you an error about a missing directory, but just
add mkdir data/.
Long story short, SoftGym contains one of the nicest looking physics simulators I’ve seen for deformable objects. I also really like the support for liquids. I can imagine future robots transporting boxes and bags of liquids.
Working and Non-Working Configurations
I’ve tried installing Docker on a number of machines. To summarize, here are
all the working configurations, which are tested by running the
examples/random_env.py script:
- Ubuntu 16.04, CUDA 9.0, NVIDIA 440.33.01, no Docker at all.
- Ubuntu 18.04, CUDA 10.0. NVIDIA 450.102.04, only use Docker for installing PyFleX.
- Ubuntu 18.04, CUDA 10.1. NVIDIA 430.50, only use Docker for installing PyFleX.
- Ubuntu 18.04, CUDA 10.1. NVIDIA 450.102.04, only use Docker for installing PyFleX.
- Ubuntu 18.04, CUDA 11.1. NVIDIA 455.32.00, only use Docker for installing PyFleX.
To clarify, when I list the above “CUDA” versions, I am getting them from
typing the command nvcc --version, and when I list the “NVIDIA” driver
versions, it is from nvidia-smi. The latter command also lists a “CUDA
Version” but that is for the driver, and not the runtime, and these two
CUDA versions can be different (on my machines the versions usually do
not match).
Unfortunately, I have run into a case where SoftGym does not seem to work:
- Ubuntu 16.04, CUDA 10.0, NVIDIA 440.33.01, no Docker at all. The only difference from a working setting above is that it’s CUDA 10.0 instead of 9.0. This setting is resulting in:
Waiting to generate environment variations. May take 1 minute for each variation...
*** stack smashing detected ***: python terminated
Aborted (core dumped)
I have yet to figure out how to fix this. If you’ve found and addressed this fix, it would be nice to inform the code maintainers.
The Code Itself
The code does not include their reinforcement learning benchmarks. That is in a separate code base, which as of March 2021 is now public. In SoftGym, there is a basic pick and place action space with fake grippers, which may be enough for preliminary usage. In the GIFs for fabric environments, you can see these fake grippers with moving white spheres.
Fortunately, the SoftGym code is fairly readable and well-structured. There’s a
FlexEnv class and a sensible class hierarchy for the different types of
deformables supported – rope, cloth, and liquids. Here’s how the classes are
structured, with parenting relationships based on the indentation below:
FlexEnv
RopeNewEnv
RopeFlattenEnv
RopeConfigurationEnv
ClothEnv
ClothDropEnv
ClothFlattenEnv
ClothFoldEnv
ClothFoldCrumpledEnv
ClothFoldDropEnv
FluidEnv
PassWater1DEnv
PourWaterPosControlEnv
PourWaterAmountPosControlEnv
One can generally match the environment names reported in the CoRL 2020 paper with the code classes. For example, the “FoldCloth” and “SpreadCloth” environments reported in the paper correspond to the “ClothFoldEnv” and “ClothFlattenEnv” classes.
The code maintainers responded to some questions I had in this GitHub issue report about making new environments. The summary is that (1) this appears to require knowledge of how to use a separate library, PyFleX, and (2) when we make new environments, we have to make new header files with the correct combination of objects we want, and then re-compile PyFleX.
As of November 2021, I have been using the code more and thus am more familiar with it compared to when I initially wrote this blog post. If you have questions on the code, I encourage you to file an issue report.
Conclusion
I hope this blog post can be of assistance when getting started with SoftGym. I am excited to see what researchers try with it going forward, and I’m grateful to be in a field where simulation for robotics is an activate area of research.
July 21, 2021: updated the post to reflect some of my additional tests, and to add the separate reinforcement learning algorithms repository.
November 06, 2021: updated the post to clarify best practices with compiling, and to explain that I have been using the code.
Five New Research Preprints Available
The video for the paper "Learning to Rearrange Deformable Cables, Fabrics, and
Bags with Goal-Conditioned Transporter Networks."
The Fall 2020 semester was an especially busy one, since I was involved in multiple paper submissions with my outstanding collaborators. Five preprints are now available, and this post summarizes each of these, along with some of the backstories behind the papers. In all cases, arXiv should have the most recent, up to date version of the paper.
- Learning Dense Visual Correspondences in Simulation to Smooth and Fold
Real Fabrics
Aditya Ganapathi, Priya Sundaresan, Brijen Thananjeyan, Ashwin Balakrishna, Daniel Seita, Jennifer Grannen, Minho Hwang, Ryan Hoque, Joseph Gonzalez, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg
The bulk of this work was actually done in Spring 2020, but we’ve made some significant improvements in the latest version on arXiv by expanding the experiments and improving the writing. The main idea in this paper is to use dense object descriptors (see my blog post here) in simulation to get correspondences between two different images of the same object, which in our case would be fabrics. If we see two images of the same fabric, but where the fabric’s appearance may be different in the two images (e.g., having a fold versus no fold), we would like to know which pixels in image 1 correspond to pixels in image 2, in the sense that the correspondence will give us the same part of the fabric. We can use the learned correspondences to design robot policies that smooth and fold real fabric, and we can even do this in real environments with the aid of domain randomization.
I was originally hoping to include this paper in our May 2020 BAIR Blog post on fabric manipulation, but the blog authors and I decided against this, since this paper doesn’t neatly fit into the “model-free” vs “model-based” categorization.
- Intermittent Visual Servoing: Efficiently Learning Policies Robust to Tool
Changes for High-precision Surgical Manipulation
Samuel Paradis, Minho Hwang, Brijen Thananjeyan, Jeffrey Ichnowski, Daniel Seita, Danyal Fer, Thomas Low, Joseph E. Gonzalez, Ken Goldberg
This paper proposes Intermittent Visual Servoing (IVS), a framework which uses a coarse controller in free space, but employs imitation learning to learn precise actions in regions that have the highest accuracy requirements. Intuitively, many tasks are characterized by some “bottleneck points”, such as tightening a screw, and we’d like to specialize the learning portion for those areas.
To benchmark IVS, we test on a surgical robot, and train it to autonomously perform surgical peg transfer. For some context: peg transfer is a task commonly used as part of a curriculum to train human surgeons for robot surgery. Robots are commonly used in surgery today, but in all cases, these involve a human manipulating tools, which then cause the surgical robot to move in known directions. This process is specifically referred to as “teleoperation.”
For our automated surgical robot on peg transfer, we show high success rates, and transferability of the learned model across multiple surgical arms. The latter is a known challenge as different surgical arm tools have different mechanical properties, so it was not clear to us if off-the-shelf IVS could work, but it did!
- Superhuman Surgical Peg Transfer Using Depth-Sensing and Deep Recurrent
Neural Networks
Minho Hwang, Brijen Thananjeyan, Daniel Seita, Jeffrey Ichnowski, Samuel Paradis, Danyal Fer, Thomas Low, Ken Goldberg
This paper is an extension of our ISMR 2020 and IEEE RA-Letters 2020 papers, which also experiment with surgical peg transfer. It therefore relates to the prior paper on Intermittent Visual Servoing, though I would not call it an extension of that paper, since we don’t actually apply IVS here, nor do we test transferability across different surgical robot arms.
In this work, we use depth sensing, recurrent neural networks, and a new trajectory optimizer (thanks to Jeff Ichnowski) to get an automated surgical robot to outperform a human surgical resident on the peg transfer task. In this and our ISMR 2020 paper, Danyal Fer acted as the human surgical resident. For our ISMR 2020 paper, we couldn’t get the surgical robot to be as good as him on peg transfer, prompting this frequent internal comment among us: Danyal, how are you so good??
Well, with the combination of these new techniques, plus terrific engineering work from postdoc Minho Hwang, we finally obtained accuracy and timing results at or better than those Danyal Fer obtained. I am looking forward to seeing how far we can push ahead in surgical robotics in 2021.
- Robots of the Lost Arc: Learning to Dynamically Manipulate Fixed-Endpoint
Ropes and Cables
Harry Zhang, Jeffrey Ichnowski, Daniel Seita, Jonathan Wang, Ken Goldberg
This shows a cool application of using a UR5 arm to perform high speed dynamic rope manipulation tasks. Check out the video of the paper (on the project website), which comes complete with some Indiana Jones style robot whipping demonstrations. We also name the proposed learning algorithm in the paper using the INDY acronym, for obvious reasons.
The first question I would have when thinking about robots whipping rope is: how do we define an action? We decided on a simple yet flexible enough approach that worked for whipping, vaulting, and weaving tasks: a parabolic action motion coupled with a prediction of the single apex point of this motion. The main inspiration for this came from the “TossingBot” paper from Andy Zeng, which used a similar idea for parameterizing a tossing action. That brings us to the fifth and final paper featured in this blog post …
- Learning to Rearrange Deformable Cables, Fabrics, and Bags with
Goal-Conditioned Transporter Networks
Daniel Seita, Pete Florence, Jonathan Tompson, Erwin Coumans, Vikas Sindhwani, Ken Goldberg, Andy Zeng
Here, we finally have the one paper where I’m the first author, and the one for which I expended the bulk of my research efforts. (You can imagine what my work days were like last fall, with me working on this paper in the mornings and afternoons, followed by the other papers above in the evenings.) This paper came out of my Summer 2020 virtual internship with Google Robotics, where I was hosted by the great Andy Zeng. Before the internship began, Andy and I knew we wanted to work on deformable object manipulation, and we thought it would be nice to show a robot manipulating bags, since that would be novel. But we weren’t sure what method to use to train the robot.
Fortunately, at that time, Andy was hard at work on something called Transporter Networks. It ended up as one of the top papers presented at CoRL 2020. Andy and I hypothesized that Transporter Networks could work well on a wide range of deformable object manipulation tasks. So, I designed over a dozen simulated environments using PyBullet that included the full suite of 1D, 2D, and 3D deformables. We were actually thinking of using Blender before the internship, but at some point I realized that Blender would not be suitable. Pivoting to PyBullet, though painful initially, proved to be one of the best decisions we made.
While working on the project, Andy and I wanted to increase the flexibility of Transporter Networks to different task specifications. That’s where the “goal-conditioned” version came from. There are multiple ways of specifying goals; here, we decided to specify an image of the desired rearrangement configuration.
Once we had the architectures and the simulated tasks set up, it was a matter of finding the necessary compute to run the experiments, and iterating upon the design and tasks.
I am very pleased with how the paper came out to be, and I also hope to release a more detailed blog post about this paper, both here and on the BAIR and Google AI blogs. I also really enjoyed working with this team; I have not met any of the Google-affiliated authors in person, so I look forward to the day when the pandemic subsides.
I hope you find these papers interesting! If you have questions or would like to discuss topics in this papers further, feel free to reach out.
Books Read in 2020
Every year I have a tradition where I try to write down all the books I read, and to summarize my thoughts. Despite how 2020 was quite different from years past, I was able to get away from the distractions of the world by diving into books. I have listed 40 books here:
- Popular Science (6 books)
- Current Events (4 books)
- Business and Technology (5 books)
- China (4 books)
- Race and Anti-Racism (5 books)
- Countries (4 books)
- Psychology and Psychiatry (4 books)
- Miscellaneous (8 books)
The total is similar to past years (2016 through 2019): 34, 43, 35, 37. As always you can find prior summaries in the archives. I tried to cut down on the length of the summaries this year, but I was only partially successful.
Group 1: Popular Science
Every year, I try to find a batch of books that quenches my scientific curiosity.
-
** Physics of the Future: How Science Will Shape Human Destiny and Our Daily Lives by the Year 2100 ** (2011) blew me away via a whirlwind tour of the future. Michio Kaku, a famous theoretical physicist and CUNY professor, attempts to predict 2100. Kaku’s vision relies on (a) what is attainable subject to the laws of physics, and (b) interviews with hundreds of leading scientific experts, including many whose names I recognize. Crudely, one can think of Physics of the Future as a more general vision of Ray Kurzweil’s How to Create a Mind (discussed below) in that Kurzweil specializes in AI and neuroscience, whereas Kaku focuses on a wider variety of subjects. Physics of the Future has separate chapters on: Computers, AI, Medicine, Nanotech, Energy, Space Travel, Wealth, Humanity, and then the last one is about “Day in the Life of 2100.” Kaku breaks down each subject into what he thinks will happen in (a) the near future to 2030, (b) then later in 2030-2070, and (c) from 2070-2100. For example, in the chapter on computers, much discussion is spent on the limits of current silicon-based CPUs, since we are hitting the theoretical limit of how many transistors we can insert in a chip of silicon, which is why there’s been much effort on going beyond Moore’s Law, such as parallel programming and quantum computing. In the AI chapter, which includes robotics, there is a brief mention of learning-based versus “classical” approaches to creating AI. If Kaku had written this book just a few years later, this chapter would look very different. In biology and medicine, Kaku is correct in that we will try to build upon advances in gene therapy and extend the human lifespan, which might (and this is big “might”) be possible with the more recent CRISPR technologies (not mentioned in the book, of course). While my area of expertise isn’t in biology and medicine, or the later chapters on nanotechnology and energy, by the time I finished this book, I was in awe of Kaku’s vision of the future, but also somewhat tempered by the enormous challenges ahead of us. For a more recent take on Kaku’s perspective, here is a one-hour conversation on Lex Fridman’s podcast where he mentions CRISPR-like technologies will let humans live forever by identifying “mistakes” in cells (i.e., the reason why we die). I’m not quite as optimistic as Kaku is on that prospect, but I share his excitement of science.
-
** How to Create a Mind: The Secret of Human Thought Revealed ** (2012) by the world’s most famous futurist, Ray Kurzweil. While his most popular book is The Singularity is Near from 2005, this shorter book — a follow-up in some ways — is a pleasure to read. In How to Create a Mind Kurzweil focuses on reverse-engineering the brain by conjecturing how the brain works, and how the process could be emulated in a computer. The aspiration is obvious: if we can do this, then perhaps we can create intelligent life. If, in practice, machines “trick” people into thinking they are real brains with real thought, then Kurzweil argues that for all practical purposes they are conscious (see Chapter 9).1 There was some discussion about split-brain patients and the like, which overlaps with some material in Incognito, which I read in 2017. Throughout the book, there is emphasis on the neocortex, which according to Wikipedia, plays a fundamental role in learning and memory. Kurzweil claims it acts as a pattern recognizer, and that there’s a hierarchy to let us conduct higher-order reasoning. This makes sense, and Kurzweil spends a lot of effort describing ways we can simulate the neocortex. That’s not to say the book is 100% correct or prescient. He frequently mentions Hidden Markov Models (HMMs), but I hardly ever read about them nowadays. Perhaps the last time I actually implemented HMMs was for a speech recognition homework assignment in the Berkeley graduate Natural Language Processing course back in 2014. The famous AlexNet paper was published just a few months after this book was published, catalyzing the Deep Learning boom. Also, Kruzweil’s prediction that self-driving cars would be here “by the end of the decade” were wildly off. I think it’s unlikely we will see them publicly available even by the end of this new decade, in December of 2029. But he also argues that as of 2012, the trends from The Singularity is Near are continuing, with updated plots showing that once a technology becomes an information technology then the “law of accelerating returns” will kick in, creating exponential growth. There are “arguments against incredulity,” as argued by the late Paul Allen. Kurzweil spends the last chapter refuting Allen’s arguments. I want to see an updated 2021 edition of Kurzweil’s opinions on topics in this book, just like I do for Kaku’s book.
-
** A Crack in Creation: Gene Editing and the Unthinkable Power to Control Evolution ** (2017) by Berkeley Professor Jennifer A Doudna and her former PhD student Samuel H Sternberg (now at Columbia University). The Doudna lab has a website with EIGHTEEN postdocs at the time of me reading this! I’m sure that can’t be the norm, since Doudna is one of the stars of the Berkeley chemistry department and recently won the 2020 Nobel Prize in Chemistry. This book is about the revolutionary technology called CRISPR. The first half provides technical background, and the second half describes the consequences, both the good (what diseases it may cure) and the bad (ethics and dangers). In prior decades, I remember hearing about “gene therapy,” but CRISPR is “gene editing” — it is far easier to use CRISPR to edit genes than any prior technology, which is one of the reasons why it has garnered widespread attention since a famous 2012 Science paper by Doudna and her colleagues. The book provides intuition showing how CRISPR works to edit genes, though as with anything, it will be easier to understand for people who work in this field. The second half of the book is more accessible and brings up the causes of concern: designer babies, eugenics, and so on. My stance is probably similar to Doudna and of most scientists in that I support investigating the technology with appropriate restrictions. A Crack in Creation was published in 2017, and already in November 2018, there was a story that broke (see MIT Review, and NYTimes articles) about the scientist He Jiankui who claimed to create the first gene-edited humans. The field is moving so fast, and reading this book made it clear the obvious similarities between CRISPR and AI technologies and how they are (a) growing so powerful and (b) require safety and ethical considerations. Sadly, I also see how CRISPR can lead to battle lines over who has credit for the technology; in AI, we have a huge problem with “flag planting” and “credit assignment” and I hope this does not damage the biochemistry field. I am also curious about the relationship between CRISPR and polygenic scores,2 which were discussed in the book Blueprint (see my thoughts here). I wish there were more books like A Crack in Creation.
-
** Scale: The Universal Laws of Growth, Innovation, Sustainability, and the Pace of Life in Organisms, Cities, Economies, and Companies ** (2017) is one of my favorites this year. By Geoffrey West, a Santa Fe Institute theoretical physicist, and who’s more accurately described as a “jack of all trades,” the book unifies the theme of “scale” across organisms, cities, and companies. It asks questions like: why aren’t there mammals the size of Godzilla? Why aren’t humans living for 200 years? How does income and crime scale with city size? Any reputable scientist can answer the question about Godzilla: anything Godzilla’s would not be able to support itself, unless it were somehow made of “different” living material. West’s key insights are to relate this to an overarching theme of exponential growth and scaling. For example, consider networks and capillaries. Mammals have hearts that pump blood into areas of the body, with the vessel size decreasing up to the capillaries at the end. But across all mammals, the capillaries at the “ends” of this system are roughly the same size, and optimize the “reachability” of a system. Furthermore, this is similar to a water system in a city, so perhaps the organization and size limitations of cities are similar to those of mammals. Another key finding is that many attributes of life are constant across many organisms. Take the number of heartbeats in a mammal’s lifespan. Smaller mammals have much faster heart rates, whereas bigger mammals have much slower heart rates, yet the number of heart beats is roughly the same across an enormous variety of organisms. That factor, along with mortality rates for humans, suggests a natural limit to human lifespans, so West is skeptical that humans will live far beyond the current record of 122 years. Scale is filled with charts showing various qualities that are consistent across organisms, cities, and companies, and which also demonstrate exponential growth. It reminds me of Steven Pinker’s style of research in adding quantitative metrics to social sciences research. West’s concludes with disconcerting discussions about whether humanity can continue accelerating at the superexponential rate we’ve been living. While careful not to fall under the “Malthusian trap,” he’s concerned that the environment will no longer be able to support our rate of living. Scale is a great book from one of academia’s brightest minds that manages to make the scientific details into something readable. If you don’t have the time to read 450+ pages, then his 2011 TED Talk might be a useful alternative.
-
** The Book of Why: The New Science of Cause and Effect ** (2018) is by 2011 Turing Award winner Judea Pearl, a professor at UCLA and a leading researcher in AI, along with science writer Dana MacKenzie3. I first remember reading about Pearl’s pioneering work in Bayesian Networks when I was an undergrad trying (unsuccessfully) to do machine learning research. To my delight, Bayesian Networks are featured in The Book of Why, and I have fond memories of studying them for the Berkeley AI Prelims. Ah. Pearl uses a metaphor of a ladder with three rungs that describe understanding. The first rung is where the current Deep Learning “revolution” lies, and relates to pattern matching. In the second rung, a machine must be able to determine what happens when something is applied. Finally, the third and most interesting rung is on counterfactual inference: what happened if, instead of \(X\), we actually did \(Y\)? It requires us to imagine a world that did not exist, and Pearl argues that this thinking is essential to create advanced forms of AI. Pearl is an outspoken skeptic of the “Big Data” trend, where one just looks at the data to find a conclusion. So this book is his way of expressing his journey through causal inference to a wider audience, where he introduces the “\(P(X | do(Y))\)” operator (in contrast to \(P(X | Y)\)), how to disentangle the effect of confounding, and how to perform counterfactual inference. What is the takeaway? I’m judging the “Turing Award” designation correctly, it seems like Pearl’s work and causality is widely accepted or at least not vigorously opposed by those in the community, so I guess it’s been a success? I should also have anticipated that Andrew Gelman would review the book on his famous blog with some mixed reactions. To summarize (and I might share this view) while The Book of Why brings many interesting points, it may read too much as someone who’s reveling in his “conquering” of “establishment statisticians,” which might turn off readers. Some of the text is also over-claiming: the book says causality can help with smoking, taxes, climate change, and so forth, but those can arguably be done without necessarily resorting to the exact causal inference machinery.
-
** Human Compatible: Artificial Intelligence and the Problem of Control ** (2019) is by Berkeley computer science professor Stuart Russell and a leading authority on AI. Before the pandemic, I frequently saw Prof. Russell as our offices are finally on the same floor, and I enjoyed reading and blogging about his textbook (soon to be updated!) back when I was studying for the AI prelims. A key message from Human Compatible is that we need to be careful when designing AI. Russell argues: “machines are beneficial to the extent that their actions can be expected to achieve our objectives”. In other words, we want robots to achieve our intended objectives, which is not necessarily — and usually is not! — what we exactly specified in the objective through a cost or reward function. Instead of this, the AI field has essentially been trying to make intelligent machines achieve “the machine’s” objective. This is problematic in several ways, one of which is that humans are bad at specifying their intents. A popular example of this is in OpenAI’s post about faulty reward functions. The BAIR blog has similar content in this post and a related post (by Stuart Russell’s students, obviously). As AI becomes more powerful, mis-specified objective functions have greater potential for negative consequences, hence the need to address this and other mis-uses of AI (e.g., see Chapter 4 and lethal autonomous weapons). There are a range of possible techniques for obtaining provably beneficial AI, such as making machines “turn themselves off” and ensuring they don’t block that, or having machines ask humans for assistance in uncertain cases, or having machines learn human preferences. Above all, Russell makes a convincing case for human-compatible AI discourse, and I recommend the book to my AI colleagues and to the broader public.
Group 2: Current Events
These are recent books covering current events.
-
** Factfulness: Ten Reasons We’re Wrong About the World — and Why Things Are Better Than You Think ** (2018) by the late Hans Rosling, who died of cancer and was just able to finish this book in time with his family. Hans Rosling was a Swedish physician and academic, and from the public’s view, may be best known for his data visualization techniques4 to explain why many of us in so-called “developed countries” have misconceptions about “developing countries” and the world more broadly. (Look him up online and watch his talks, for example this TED talk.) The ten reasons in Factfulness are described as “instincts”: gap, negativity, straight line, fear, size, generalization, destiny, single perspective, blame, and urgency. In discussing these points, Rosling urges us to dispense with the terms “developing” and “developed” and instead to use a four-level scale, with most of the world today on “Level 2” (and the United States on “Level 4”). Rosling predicts that in 2040, most of the world will be on Level 3. Overall, this book is similar to Steven Pinker’s Better Angels and Enlightenment Now so if you like those two, as I did, you will probably like Factfulness. However, there might not be as much novelty. I want to conclude with two thoughts. The criticism of “cherry-picking facts” is both correct but also unfair since any book that covers a topic as broadly as the state of the world will be forced to do so. Second, while reading this book, I think there is a risk of focusing too much on countries that have a much lower baseline of prosperity to begin with (e.g., countries on Level 1 and 2) and it would be nice to see if we can get similarly positive news for countries which are often viewed as “wealthy but stagnant” today, such as Japan and (in many ways) the United States. Put another way, can we develop a book like Factfulness that will resonate with factory workers in the United States who have lost jobs due to globalization, or people lamenting soaring income inequality?
-
** The Coddling of the American Mind: How Good Intentions and Bad Ideas are Setting Up a Generation for Failure ** (2018) was terrific. It’s written by Greg Lukianoff, a First Amendment lawyer specializing in free speech on campuses, and Jonathan Haidt, a psychology professor at NYU, and one of the most well-known in his field. For perspective, I was aware of Haidt before reading this book. Coddling of the American Mind is an extended version of their article in The Atlantic, which introduced their main hypothesis that the trend of protecting students from ideas they don’t like is counterproductive. Lukianoff and Haidt expected a wave of criticism after their article, but it seemed like there was agreement from across the political spectrum. They emphasize how much of the debate over free speech on college campuses is a debate within the political left, given the declining proportion of conservative students and faculty. The simple explanation is that the younger generation disagrees with older liberals, the latter of whom generally favor freer speech. The book mentions both my undergrad, Williams College, and my graduate school, the University of California, Berkeley, since both institutions have faced issues with free speech and inviting conservative speakers to campus. More severe were the incidents at Evergreen State, though fortunately what happened there was far from typical. Lukianoff and Haidt also frequently reference Jean Twenge’s book IGen: Why Today’s Super-Connected Kids Are Growing Up Less Rebellious, More Tolerant, Less Happy – and Completely Unprepared for Adulthood – and What That Means for the Rest of Us, with a long self-explanatory subtitle. I raced through The Codding of the American Mind and will definitely keep it in mind for my own future. Like Haidt, I generally identify with the political left, but I read a fair amount of conservative writing and feel like I have significantly benefited from doing so. I also generally oppose disinviting speakers, or “cancel culture” more broadly. This book was definitely a favorite of mine this year. The title is unfortunate, as the “coddling” terminology might cause the people who would benefit the most to avoid reading it.
-
** The Tyranny of Merit: What’s Become of the Common Good? ** (2020) by Michael J. Sandel, a Professor of Government at Harvard University who teaches political philosophy. Sandel’s objective is to inform us about the dark side of meritocracy. Whereas in the past, being a high-status person in American society was mainly due to being white, male, and wealthy, nowadays America’s educational system has changed to a largely merit-based one, however one defines “merit.” But for all these changes, we still have low income mobility, where the children of the wealthy and highly educated are likely to remain in high status professions, and the poor are likely to remain poor. Part of this is because elite colleges and universities are still overly-represented by the wealthy. But, argues Sandel, even if we achieve true meritocracy, would that actually be a desirable thing? He warns us that this will exacerbate credentialism as “the last acceptable prejudice,” where for the poor, the message we send to them is bluntly that they are poor because they are bad on the grounds of merit. That’s a tough pill to swallow, which can breed resentment, and Sandel argues for this being one of the reasons why Trump won election in 2016. There are also questions about what properly defines merit, and unfortunate side effects of the race for credentialism, where “helicopter parenting” means young teenagers are trying to fight to gain admission to a small pool of elite universities. This book is more about identifying the problem rather than proposing solutions, but Sandel includes some modest approaches, such as (a) adding a lottery to admissions processes at elite universities, and (b) taxing financial transactions that add little value (though these seem quite incremental to me). Of course, he agrees, it’s better to not have wealth or race be the deciding factor that determines quality of life, as Sandel opens up in his conclusion when describing how future home run record holder Hank Aaron had to practice batting using sticks and bottle caps due to racism. But that does not mean the current meritocracy status quo should be unchallenged.
-
** COVID-19: The Pandemic That Never Should Have Happened, and How to Stop the Next One ** (2020) by New Scientist reporter Debora MacKenzie, was quickly written in early 2020 and published in June, while the world was still in the midst of the pandemic. The book covers the early stages of the pandemic and how governments and similar organizations were unprepared for one of this magnitude despite early warnings. MacKenzie provides evidence that scientists were warning for years about the risks of pandemics, but that funding, politics, and other factors hindered the development of effective pandemic strategies. The book also provides a history of some earlier epidemics, such as the flu of 1918 and SARS in 2003, and why bats are a common source of infectious diseases. (But don’t go around killing bats, that’s a completely misguided way of fighting COVID-19.) MacKenzie urges us to provide better government support for research and development into vaccines, since while markets are a great thing, it is difficult for drug and pharmaceutical companies to make profits off of vaccines while investing in the necessary “R and D.” She also wisely says that we need to strengthen the World Health Organization (WHO), so that the WHO has the capability to quickly and decisively state when a pandemic is occurring without fear of offending governments. I think MacKenzie hits on the right cylinders here. I support globalization when done correctly. We can’t tear down the world’s gigantic interconnected system, but we can at least make systems with more robustness for future pandemics and catastrophic events. As always, though, it’s easier said than done, and I am well aware that many people do not think as I do. After all, my country has plenty of anti-vaxxers, and every country has its share of politicians who are hyper-nationalistic and are willing to silence their own scientists who have bad news to share.
Group 3: Business and Technology
-
Remote: Office Not Required (2013) is a concise primer on the benefits of remote work. It’s by Jason Fried and David Hansson, cofounders of 37Signals (now Basecamp), a software company which specializes in one product (i.e., Basecamp!) to organize projects and communication. I used it once, back when I interned at a startup. Basecamp has unique work policies compared to other companies, which the authors elaborate upon in their 2017 manifesto It Doesn’t Have to be Crazy At Work (discussed below). This book narrows down on the remote aspect of their workforce, reflecting how Basecamp’s small group of employees works all around the world. Fried and Hansson describe the benefits of remote work: a traditional office is filled with distractions, the commute to work is generally unpleasant, talent isn’t bound in specific cities, and so on. Then, they show how Basecamp manages their remote work force, essentially offering a guide to other companies looking to make the transition to remote work. I think many are making the transition if they haven’t done so already. If anything, I was surprised that it’s necessary to write a book on these “obvious” facts, but then again, this was published right when Marissa Mayer, then Yahoo!’s CEO, famously said Yahoo! would not permit remote work. In contrast, I was reading this book in April 2020 when we were in the midst of the COVID-19 pandemic which essentially mandated remote work. While I miss in-person work, I’m not going to argue against the benefits of some remote work.
-
Chaos Monkeys: Obscene Fortune and Random Failure in Silicon Valley (2016) is by Antonio García Martínez. A “gleeful contrarian” who entered the world of Silicon Valley after a failed attempt at becoming a scientist (formerly a physics PhD student at UC Berkeley) and then a stint as a Goldman Sachs trader, he describes his life at Adchemy5, then as the CEO of his startup, AdGrok, and then his time at Facebook. AdGrok was a three-man startup with Martínez and two other guys, specializing in ads, and despite all their missteps, it got backed by the Y-Combinator. Was it bought by Facebook? Nope — by Twitter, and Martínez nearly screwed the whole acquisition by refusing to work for Twitter and joining Facebook, essentially betraying his two colleagues. At Facebook, he was a product manager specializing in ads, and soon got embroiled over the future ads design; Martínez was proposing a new system called “Facebook Exchange” whereas his colleagues mostly wanted incremental extensions of the existing Facebook Ads system (called “Custom Audiences”). He was eventually fired from Facebook, and then went to Twitter as an adviser, and as of 2019 he’s at Branch. Here’s a TL;DR opinionated summary: while I can see why people (usually men) might like this fast-paced exposé of Silicon Valley, I firmly believe there is a way to keep his good qualities — his determination, passion, focus — without the downsides of misogyny, getting women pregnant two weeks after meeting them, and flouting the law. I’ll refer you to this criticism for more details, and to add on to this, while Martínez is able to effectively describe concepts in Silicon Valley and computing reasonably well, he often peppers those comments with sexual innuendos. This is absolutely not the norm among the men I work with. I wonder what his Facebook colleagues thought of him after reading this book. On a more light-hearted note, soon after reading Chaos Monkeys, I watched Michael I Jordan’s excellent podcast conversation with Lex Fridman on YouTube6. Prof. Jordan discusses and criticizes Facebook’s business model for failing to create a “consumer-producer ecosystem” and I wonder how much the idea of Facebook Exchange overlaps with Prof. Jordan’s ideal business model.
-
** It Doesn’t Have to Be Crazy at Work ** (2017). The authors are (again) Jason Fried and David Hansson, who wrote Remote: Office Not Required (discussed above). I raced through this book, with repeated smiles and head-nodding. Perhaps more adequately described as a rousing manifesto, it’s engaging, fast-paced, and effectively conveys how Basecamp manages to avoid enforcing a crazy work life. Do we really need 80-hour weeks, endless emails, endless meetings, and so on? Not according to Basecamp: “We put in about 40 hours a week most of the year […] We not only pay for people’s vacation time, we pay for the actual vacation, too. No, not 9 p.m. Wednesday night. It can wait until 9 a.m. Thursday morning. No, not Sunday. Monday.” Ahh … Now, I definitely don’t follow what this book says word-for-word. For example, I work far more than 40 hours a week. My guess is 60 hours, and I don’t count time spent firing off emails in the evening. But I do my best. I try to ensure that my day isn’t consumed by meetings or emails, and that I have long time blocks to myself for focused work. So far I think it’s working for me. I feel reasonably productive and have not burnt out. I try to continue this during the age of remote work. Basecamp has been a working remotely for 20 years, and their software (and hopefully work culture) may have gotten more attention recently as COVID-19 spread through the world. Perhaps more employers will enable remote work going forward.
-
** Brotopia: Breaking Up the Boys’ Club of Silicon Valley ** (2018) is by Emily Chang, a journalist, author, and current anchor of Bloomberg Technology. For those of us wondering why Silicon Valley continues to be heavily male-dominated despite years and years of public outcry, Chang offers a compelling set of factors. Brotopia briefly covers the early history of the tech industry and how employees were screened for certain factors that statistically favored men. She reviews the “Paypal Mafia” and why meritocracy is a myth, and then covers Google, a company which has for years had good intentions but has experienced its own share of missteps, lawsuits, and press scrutiny over its treatment of women. Then there’s the chapter that Chang reportedly said was “the hardest to research by far,” about secret parties hosted by Venture Capitalists and other prominent men in the tech industry, where they network and invite young women.7 Chang points out that incentives given by tech companies to employees (e.g., food, alcohol, fitness centers, etc.) often cater to the young and single, and encourage a blend of work and life, meaning that for relatively older women, work-family imbalance is a top reason why they leave the workforce at alarming numbers. The list of factors which make it difficult for women to enter and comfortably remain in tech goes on and on. After reading this book, I am constantly feeling depressed about the state of affairs here — can things really be that bad? There are, of course, things I should do given my own proximity and knowledge of the industry from an academic’s viewpoint in STEM, where we have similar gender representation issues. I can at least provide a minimal promise that I will remember the history in this book and ensure that social settings are more comfortable for women.
-
** The Making of a Manager: What to do When Everyone Looks to You ** (2019) is by Julie Zhuo, who worked at Facebook for 14 years, and quickly rose through the ranks to become a manager at age 25, and eventually held a Vice President (VP) title. This book, rather than focusing on Zhuo’s personal career trajectory, is best described as a general guide to managing with some case studies from her time at Facebook (appropriately anonymized, of course). Zhuo advises on the first few months of managing, on managing small versus large teams, the importance of feedback (both to reports and to managers), on hiring great people, and so on. A consistent theme is that the goal of managing is to increase the output of the entire team. I also liked her perspective on how to delegate tasks, because as managers rise up the hierarchy, meetings became the norm rather than the exception, and so the people who do “real work” are those lower in the hierarchy but who have to be trusted by managers. I generally view managing in the context of academia, since I am managed by my PhD advisors, and I manage several undergraduates who work with me on research projects. There is substantial overlap in the academic and industry realms, particularly with delegating tasks, and Zhuo’s book — even with its focus on tech — provides advice applicable to a variety of domains. I hope that any future managers I have will be similar in spirit to Zhuo. Now, while reading, I couldn’t help but think about how someone like Zhuo would manage someone like Antonio García Martínez, who wrote Chaos Monkeys (discussed earlier) and overlapped with her time at Facebook, since those two seem to be the polar opposites of each other. Whereas Zhuo clearly values empathy, honesty, diversity, support, and so on, Martínez gleefully boasts about cutting corners and having sex, including one case involving a Facebook product manager. The good news is that Martínez only lasted a few years at Facebook, whereas Zhuo was there for 14 years and left on her own accord to start Inspirit. Hopefully Inspirit will grow into something great!
Group 4: China
As usual, I find that I have an insatiable curiosity for learning more about China. Two focus on women-specific issues. (I have another one that’s more American-based, near the end of this post, along with the “Brotopia” one mentioned above.)
-
** Leftover Women: The Resurgence of Gender Inequality in China ** (2014) is named based on the phrase derisively describing single Chinese women above a certain age (usually 25 to 27) who are pressured to marry and have families. It’s written by Leta Hong Fincher, an American (bilingual in English and Chinese) who got her PhD in sociology at Tsinghua University. Leftover Women grew out of her dissertation work, which involved interviews with several hundred Chinese, mostly young well-educated women in urban areas. I had a rough sense of what gender inequality might be like, given its worldwide prevalence, but the book was able to effectively describe the issues specific to China. One major theme is housing in big cities, along with a 2011 law passed by the Chinese Supreme Court which (in practice) meant that it became more critical whose name was on the house deed. For married couples who took part in the house-buying spree over the last few decades (as part of China’s well-known and massive rural-to-urban migration), usually the house deed used the man’s name. This exacerbates gender inequality, as Hong Fincher repeatedly emphasizes that property and home values have soared in recent years, making those more important to consider than the salary one gets from a job. Despite these and other issues in China, Hong-Fincher reports some promising ways that grassroots organizations are attempting to fight these stereotypes for women, despite heavy government censorship and disapproval. I was impressed enough by Hong-Fincher’s writing to read her follow-up 2018 book. In addition, I also noticed her Op-Ed for CNN arguing that women are disproportionately better at handling the COVID-19 pandemic.8 Her name has come up repeatedly as I continue my China education.
-
** Betraying Big Brother: The Feminist Awakening in China ** (2018) is the second book I read from Leta Hong Fincher. Whereas Leftover Women featured the 2011 Chinese Supreme Court interpretation of a housing deed law, this book emphasizes the Feminist Five, young Chinese women who were arrested for protesting sexual harassment. You can find an abbreviated overview with a Dissent article which is a nice summary of Betraying Big Brother. The Feminist Five women were harassed in jail and continually spied upon and followed after their release. (Their release may have been due to international pressure). It was unfortunate to see what these women had to go through, and I reminded myself that I’m lucky to live in a country where women (and men) can perform comparable protests with limited (if any) repercussions. In terms of Chinese laws, the main one relevant to this book is a recent 2016 domestic violence law, the first of its kind to be passed in China. While Fincher praises the passage of this law, she laments that enforcement is questionable and that gender inequality continues to persist. She particularly critiques Xi Jinping and the “hypermasculinity” that he and the Chinese Communist Party promotes. The book ends on an optimistic note on how feminism continues to persist despite heavy government repression. Furthermore, though this book focuses on China, Hong Fincher and the Feminist Five emphasize the need for an international movement of feminism that spans all countries (I agree). As a case in point, Hong Fincher highlights how she and other Chinese women attended the American women’s march to protest Trump’s election. While I didn’t quite learn as much from this book compared to Leftover Women, I still found this to be a valuable item in my reading list about feminism.
-
** Superpower Showdown: How the Battle Between Trump and Xi Threatens a New Cold War ** (2020) by WSJ reporters Bob Davis and Lingling Wei was fantastic – I had a hard time putting this book down. It’s a 450-page, highly readable account of diplomatic relations between the United States and China in recent years. The primary focus is the negotiation behind the scenes that led to the US-China Phase 1 trade deal in January 2020. As reporters, the authors had access to high-ranking officials and were able to get a rough sense of how each “side” viewed each other, not only from the US perspective but also from China’s. The latter is unusual, as the Chinese government is less open with its decision-making, so it was nice to see a bit into how Chinese government officials viewed the negotiations. Davis and Wei likely split the duties by Davis reporting from the American perspective, and Wei reporting from the Chinese perspective. (Wei is a naturalized US citizen, and was among those forced to leave China when they expelled journalists in March 2020.) The authors don’t editorialize too much, beyond trying to describe why they believed certain negotiations failed via listing the mistakes made on both sides — and there were a lot of failed negotiations. Don’t ever say geopolitics is easy. Released in Spring 2020, Superpower Showdown was just able to get information about the COVID-19 pandemic, before it started to spread rapidly in the United States. Unfortunately, COVID-19, rather than uniting the US and China against a common enemy, instead further deteriorated diplomatic relations. Just after finishing the book, I found a closely-related Foreign Affairs essay by Trump’s trade representative Robert E. Lighthizer. Consequently, I now have Foreign Affairs on my reading list.
-
** Blockchain Chicken Farm: And Other Stories of Tech in China’s Countryside ** (2020) by Xiaowei Wang, who like me is a PhD student at UC Berkeley (in a different department, in Geography). Xiaowei is an American who has family and friends throughout China, and this book is partially a narrative of Wang’s experience visiting different parts of the country. Key themes are visiting rural areas in China, rather than the big cities which get much of the attention (as China is also undergoing a rural-to-urban migration as in America), and the impact of technology towards rural areas. For example, the book mentions how chickens and pigs are heavily monitored with technology to maximize their fitness for human consumption, how police officers are increasingly turning to facial recognition software while still heavily reliant on humans in this process, and the use of Blockchain even though the rural people don’t understand the technology (to be fair, it’s a tricky concept). Wang cautions us that increased utilization of technology and AI will not be able to resolve every issue facing the country, and come with well-known drawbacks (that I am also aware of given the concern over AI ethics in my field) that will challenge China’s leaders, so that they can continue to feed their citizens and maintain political stability. It’s a nice, readable book that provides a perspective of the pervasiveness but also the limitations of technology in rural China.
Group 5: Race and Anti-Racism
-
** Evicted: Poverty and Profit in the American City ** (2016) is incredible. I can’t add much more praise to what’s already been handed to this Pulitzer Prize-winning book. Evicted is by Matthew Desmond, a professor of sociology at Princeton University. Though published in 2016, it was in 2008 and 2009 when he was a graduate student at the University of Wisconsin, when he moved into a trailer park in Milwaukee where poor whites lived. Desmond spent a few months following and interviewing residents and the landlord. He then repeated the process in the North Side of Milwaukee, where poor blacks lived. The result is an account of what it is like to be poor in America and facing chronic evictions.9 One huge problem: these tenants often had to pay 60-80 percent of their government welfare checks to rent. I also learned about how having children increases the chances of eviction, and how women are more vulnerable to eviction than men, and the role of race. The obvious question, of course, is what kind of policy solutions can help to improve the status quo. Desmond’s main suggestion he posits in the epilogue is for a universal housing voucher, which might reduce the amount spent on homeless shelters. Admittedly, I understand that we need both good policies and better decision-making on the part of these tenants, so it’s important for us to ensure that there are correct incentives for people to “graduate from welfare.” Interestingly, Desmond didn’t seem to discuss rent control that much, despite how it is a common topic I hear about nowadays. Another policy that might be relevant to this book is drug use, since pretty much every tenant here was on drugs. I generally oppose rent control and oppose widespread drug usage, but I also admit that implementing these policies would not fix the immediate problems the tenants face. Whatever your political alignments, if you haven’t done so, I strongly recommend you add Evicted to your reading list. The only very minor suggestion I would ask for this book is to have an easy-to-find list of names and short biographies of the tenants at the start of the book.
-
** White Fragility: Why It’s So Hard to Talk to White People About Racism ** (2018), by Robin DiAngelo, shot up to the NYTimes best-sellers list earlier this year, in large part from racial protests happening in the United States. Her coined phrase “white fragility” has almost become a household name. As DiAngelo says in the introduction, she is white and the book is mainly addressed to a white audience. (I am not really the target audience, but I still wanted to read the book.) DiAngelo discusses her experience trying to lead racial training training sessions among employees, and how whites often protest or push back against what she says. This is where the term “white fragility” comes from. Most whites she encounters are unwilling to have extensive dialogues that acknowledge their racial privileges, or try to end the discussion by saying defensive statements such as: “I am not racist, so I’m OK, someone else is the problem, end of story.” I found the book to be helpful and thought provoking, and learned about several traps that I will avoid when thinking about race. When reading the book, while I don’t think I personally felt challenged or insulted, I thought it served exactly as DiAngelo intended: to help me build up knowledge and stamina for discussion over racial issues.
-
** So You Want to Talk About Race ** (2018), by Ijeoma Oluo, attempts to provide guidelines for how we can talk about race. Like many books falling under the anti-racist theme, it’s mainly aimed for white people to help them understand why certain topics or conduct are not appropriate for conversations on race. For example, consider chapters titled “Why can’t I say the ‘N’ word?” and “Why can’t I touch your hair?”. While some of these seem like common sense to me — I mean, do people actually go about touching Black people’s hair, or anyone’s body? — I know that there’s enough people who do this that we need to have this conversation. Oluo also effectively dispels the notion that we can just talk about class instead of race, or that we’ll get class out of the way first. I also appreciate her mention of Asians in the chapter on why the model minority myth is harmful. I also see that Oluo wrote in the introduction about how she wished she could have allocated more discussion on Indigenous people. I agree, but no book can contain every topic, so it’s not something I would use to detract from her work. Oluo has a follow-up book titled Mediocre: The Dangerous Legacy of White Male America, which I should check out soon.
-
Me and White Supremacy: Combat Racism, Change the World, and Become a Good Ancestor (2020) by Layla F. Saad. This started as a 28-day Instagram challenge that went viral. It was published in January 2020, and the timing could not have been better, given that just a few months later, we would see America face enormous racial protests. I read this book right after reading White Fragility, whose author (Robin DiAngelo) wrote the foreword, and says that Layla F. Saad gives us a roadmap for addressing the most common question white people have after an antiracist presentation: “What do I do?” In her introduction, Saad says: ““The system of white supremacy was not created by anyone who is alive today. But it is maintained and upheld by everyone who holds white privilege.” Saad, an East African and Middle Eastern Black Muslim women who lives in Qatar and is a British citizen, wants us to tackle this problem so that we leave the world a better place than it is today. Me and White Supremacy is primarily aimed at white people, but also applies to people of color who hold “white privilege” which would apply to me. There are four parts: (1) the basics, (2) anti-blackness, racial stereotypes, and cultural appropriation, (3) allyship, and (4) power, relations, and commitments. For example, the allyship chapter mentions white apathy, white saviorism (as shown in The Blind Side and others), tokenism, and being “called out” for racism, which Saad says is inevitable if we take part in anti-racism work. In contrary to what I think Saad was expecting out of readers, I didn’t experience too many conflicting emotions or uncomfortable feelings when reading this book. I don’t know if that’s a good thing or a bad thing. It may have been because I read this after White Fragility and So You Want to Talk About Race?. I will keep this book in mind, particularly the allyship section, now and in the future.
-
** My Vanishing Country: A Memoir ** (2020) is a memoir by Bakari Sellers, who describes his experience living in South Carolina. The value of the book is providing the perspective of Black rural working class America, instead of the white working class commonly associated with rural America (as in J.D. Vanci’s Hillbilly Elegy). I read the memoir quickly and could not put it down. Here are some highlights from Sellers’ life. When he was 22, freshly graduated out of Morehouse College and in his first year of law school at the University of South Carolina, he was elected to the South Carolina House of Representatives.10 Somehow, he simultaneously served as a representative while also attending law school. His representative salary was only 10,000 USD, which might explain why it’s hard for the poor to build a career in state-level politics. He earned attention from Barack Obama, whom Sellers asked to come to South Carolina in return for Sellers’ endorsement in the primaries. Eventually, he ran for Lieutenant Governor (as a Democrat), a huge challenge in a conservative state such as South Carolina, and lost. He’s now a political commentator and a lawyer. The memoir covers the Charleston massacre in 2015, his disappointment when Trump was elected president (he thought that white women would join forces with non-whites to elect Hilary Clinton), and a personal story where his wife had health issues when giving birth, but survived. Sellers credits the fact that the doctors and nurses there were Black and knew Sellers personally, and he concludes with a call to help decrease racial inequities in health care, which persist today in the mortality rate when giving birth, and also with lead poisoning in many predominantly Black communities such as in Flint, Michigan.
Group 6: Countries
I continue utilizing the “What Everyone Needs to Know” book series. However, the batch I picked this year was probably less informative compared to others in the series. However, I’m especially happy to have read the fourth book here about Burma (not part of “What Everyone Needs to Know”), which I found from reading Foreign Affairs.
-
Brazil: What Everyone Needs to Know (2016) by Riordan Roett, Professor Emeritus at the Johns Hopkins University’s School of Advanced International Studies (SAIS), who specializes in Latin American studies. Brazil is always a country that I’ve wanted to know more, given its size (in population and land area), its geopolitical situation in a place (Latin America) that I know relatively little about, and because of the Amazon rain forest. The book begins with the early recorded history of Brazil based on the Portuguese colonization, followed by the struggle for independence. It also records Brazil’s difficulties with establishing Democracy versus military rule. Finally, it concludes with some thought questions about foreign affairs, and Brazil’s relations with the US, China, and other countries. This isn’t a page-turner book, but I think the bigger issue is that so much of what I want to know about Brazil relates to what happened over the last 5 years, particularly given the increasingly authoritarian nature of Brazil’s leadership since then, with President Jair Bolsonaro.
-
Iran: What Everyone Needs to Know (2016), by the late historian Michael Axworthy, provides a concise overview of Iran’s history. I bought it on iBooks and started reading it literally the day before the murder of Qasem Soleimani. Soleimani was widely believed to be next-in-line to succeed Ali Khamenei as the Supreme Leader of Iran; the “Supreme Leader” is the highest office in Iran. If you are interested in a recap of those events, see this NYTimes account on the events that nearly brought war between the US and Iran. The book was published in 2016 so it did not contain that information, and the last question was predictably about the future of Iran after the 2015 Nuclear Deal,11 with Axworthy noting that Iran seems to be pulled in “incompatible directions,” one for liberalization and modernity, the other for conservative Islam and criticism of Israel. The book mentions the history of the people who lived in the area that is now Iran. Back then, that was the Persian Empire, and I liked how Axworthy commented on Cyrus and Darius I, since they are the two Persian leaders in the Civilization IV computer game that I used to play. Later, Axworthy mentions the Iran-Iraq war and the Revolution of 1979 which deposed the last Shah (Mohammad Reza Pahlavi) in favor of Ruhollah (Ayatollah) Khomeini. Overall, this book is OK but was boring in some areas, and is too brief. It may be better to read Axworthy’s longer (but older) book about Iran.
-
Russia: What Everyone Needs to Know (2016) is by Timothy J. Colton, a Harvard University Professor of Government and Russian Studies. The focus of this book is on Russia, which includes the Soviet Union from the period of 1922 to its dissolution in 1991 into 15 countries, one of which was Russia itself. As usual for “What Everyone Needs to Know” books, it starts with dry early history. The book gets more interesting when it presents the Soviet Union (i.e., USSR) and its main leaders: Joseph Stalin, Nikita Krushchev, Leonid Brezhnev, and Mikhail Gorbachev. Of those leaders, I support Gorbachev the most due to glasnost, and oppose Stalin the most, from the industrial-scale killing on his watch. Then there was Boris Yeltsin and, obviously, Vladimir Putin, who is the subject of much of the last chapter of the book. This book, like the one about North Korea I read last year, ponders about who might succeed Vladimir Putin as the de facto leader of Russia? Putin is slated to be in power until at least 2024, and he likely won’t give it to his family given that he has no sons. Russia faces other problems, such as alcoholism and demographics, with an aging population and a significantly lower average lifespan for males compared to other countries of Russia’s wealth. Finally, Russia needs to do a better job at attracting and retaining talent in science and engineering. This is one of the key advantages the United States has. (As I said earlier, we cannot relinquish this advantage.) Final note: Colton uses a lot of advanced vocabulary in this book. I had to frequently pause my reading to refer to a dictionary.
-
** The Hidden History of Burma: Race, Capitalism, and the Crisis of Democracy in the 21st Century ** (2020) is Thant Myint-U’s latest book on Burma (Myanmar)12. Thant Myint-U is is now one of my expert sources for Burmese-related topics. He’s lived there for many years, and has held American and Burmese citizenship at various points in his life. He is often asked to advise the Burmese government and frequently engages with high-level foreign leaders. His grandfather, U Thant, was the third Secretary General of the United Nations from 1961 to 1971, and I’m embarrassed I did not know that; amusingly, Wikipedia says U Thant was the first Secretary General who retired while on speaking terms with all major powers. The Hidden History of Burma discusses the British colonization, the struggle for independence, and the dynamics of the wildly diverse population (in terms of race and religion). Featured heavily, of course, is Aung San Suu Kyi, the 1991 Nobel Peace Prize13 recipient, and a woman who I first remember learning about back in high school. She was once viewed as the beacon of Democracy and human rights — until, sadly, the last few years. She’s been the current de facto leader of government and overseeing one of the most brutal genocides in modern history of the Rohingya Muslims. Exact numbers are unclear, but it’s estimated that hundreds of thousands have either been killed or have fled to neighboring Bangladesh. How did this happen? The summary is that it wasn’t so much that Burma (and Aung San Suu Kyi) made leaps and bounds of progress before doing a 180 sometime in 2017. Rather, the West, and other foreigners who wanted to help, visit, and invest in the country, badly miscalculated and misinterpreted the situation in Burma while wanting to view Aung San Suu Kyi as an impossibly impeccable hero. There’s a lot more in the book about race, identity, and capitalism, and how this affects Burma’s past, present, and future. Amusingly, I’ve been reading Thant Myint-U’s Twitter feed, and he often fakes confusion as to whether his tweets are referring to the US or Burma: A major election? Widening income inequality? Illegal immigrants? Big bad China? Environmental degradation? Social media inspired violence? Who are we talking about here? For another perspective on the book, see this CFR review.
Group 7: Psychology and Psychiatry
-
** 10% Happier: How I Tamed the Voice in My Head, Reduced Stress Without Losing My Edge, and Found Self-Help That Actually Works–A True Story ** (2014) is a book by Dan Harris which (a) chronicles his experience with meditation and how it can reduce stress, and (b) attempts to present meditation as an option to many readers but without the big “PR problem” that Harris admits plagues meditation. For (a), Harris turned to meditation to reduce the anxiety and stress he was experiencing as a television reporter; he had several panic attacks on air and, for a time, turned to drugs. His news reporting got him involved with religious, spiritual, and “happiness” gurus who turned out to be frauds (Ted Haggard and James Arthur Ray), which led Harris to question the self-help industry. A key turning point in Harris’ life was attending a 10-day Buddhist meditation retreat in California led by Joseph Goldstein. He entered the retreat in part due to the efforts of famous close friend Sam Harris (no relation). After the retreat, he started practicing meditation and even developed his own “10% Happier app” with colleagues. Harris admits that meditation isn’t a panacea for everything, so that’s one of the reasons for the wording “10% happier” in the title. I read many books, so because of sheer quantity, it’s rare when I can follow through on a book’s advice. I will try my best here. My field of computer science and robotics research is far different from Harris’ field, I also experience some stress in maintaining my edge due to the competitive nature of research, so hopefully I can follow this. Harris says all we need are 5 minutes a day. To start: sit comfortably, feel your breath, and each time you get lost in thought, please gently return to breath and start over.
-
** Misbehaving: The Making of Behavioral Economics ** (2015) by Nobel Laureate Richard Thaler of the University of Chicago, is a book that relates in many ways to Daniel Kahneman’s Thinking, Fast and Slow (describing work in collaboration with Amos Tversky). If you like that book, you will probably like this one, since it covers similar themes, which shouldn’t be surprising as Thaler collaborated with Kahneman and Tversky for portions of his career. Misbehaving is Thaler’s personal account of his development of behavioral economics, a mix of an autobiography and “research-y” topics. It describes how economics has faced internal conflicts between those who advocate for a purely rational view of agents (referred to as “Econs” in the book) and those who incorporate elements of human psychology into their thinking, which may cause classical economic theory to fail due to irrational behavior by humans. In chapter after chapter, Thaler argues convincingly that human behavior must be considered to understand and properly predict economic behavior.
-
Option B: Facing Adversity, Building Resilience, and Finding Joy (2016) is co-written by Sheryl Sandberg and Adam Grant, and for clarity is told from the perspective of Ms. Sandberg. She’s the well-known Chief Operating Officer of Facebook and the bestselling author of Lean In, which I read a few years ago. This book arose out of the sudden death of her former husband, Dave Goldberg, in 2015, and how she went through the aftermath. Option B acknowledges that, sometimes, people simply cannot have their top option, and must deal with the second best situation, or the third best, and so on. It also relates to Lean In to some extent; that book was criticized for being elitist in nature, and Option B emphasizes that many women may face roadblocks to career success and financial safety, and hence have to consider “second options.” Option B contains anecdotes from Sandberg’s experience in the years after her husband’s death, and integrates other stories (such as the famous Uruguay flight which crashed, leading survivors to resort to cannibalism) and psychological studies to investigate how people can build resilience and overcome such traumatic events. As of mid-2020, it looks like Ms. Sandberg is now engaged again, so while this doesn’t negate her pain of losing Dave Goldberg, she shows – both in the book and in person – that one can find joy again after tragedy.
-
Good Reasons for Bad Feelings: Insights from the Frontier of Evolutionary Psychiatry (2019), by Randolph M. Nesse, a professor at Arizona State University, is about psychiatry. Wikipedia provides a short intro: psychiatry is the medical specialty devoted to the diagnosis, prevention, and treatment of mental disorders. This book specializes in the evolutionary aspect of psychiatry. A key takeaway from the book is that humans did not evolve to have mental illness or disorders. Dr. Nesse has an abbreviation for this: Viewing Diseases As Adaptations (VDAA), which he claims is the most common and serious mistake in evolutionary medicine. The correct question is, instead, why did natural selection shape traits that make us vulnerable to disease? There are intuitive explanations. For one, any personality trait exhibits itself across a spectrum of extremity. Some anxiety is necessary to help protect against harm, but having too much can be a classic sign of a mental disorder. Also, what was best back for our ancestors is not true today, as vividly demonstrated by the surge in obesity in developed countries. Another takeaway, one that I probably should have expected, is that the science of psychiatry has had plenty of controversy. Consider the evolutionary benefits of homosexuality (if any). Dr. Nesse says it’s a common question he gets, and he avoids answering because he doesn’t think it’s settled. From my non-specialist perspective, this book was a readable introduction to evolutionary psychiatry.
Group 8: Miscellaneous
-
** The Conscience of a Liberal ** (2007, updated forward 2009) is a book by the well-known economist and NYTimes columnist Paul Krugman. The title is similar to that of Barry Goldwater’s 1960 book, and of course, the 2017 version from former Senator Jeff Flake (which I read). In The Conscience of a Liberal, Krugman describes why he is a liberal, discusses the rise of modern “movement” Conservatism, and argues that a Democratic presidential administration must prioritize universal health care. The book was written in 2007, so he couldn’t have known that Obama would win in 2008 and pursue Obamacare, and I know from reading Krugman’s columns over the years that he’s very pro-Obamacare. Many of Krugman’s columns today at the NYTimes reflect the writing in this book. That’s not to say the ideas are stale — much of it is due to the slow nature of government in that it takes us ages to make progress on any issue, such as the still-unseen universal health care. Krugman consistently argues in the book (as in his columns) for having a public option in addition to a strong private sector, rather than creating true socialized medicine which is what Britain uses. Regarding Conservatism, Krugman gets a lot right here: he essentially predicts correctly that Republicans can’t just get rid of Obamacare due to the huge backlash, just like Eisenhower-type Republicans couldn’t get rid of the New Deal. I also think he’s right on race, in that the Republicans have been able to get an alliance between the wealthy pro-business and low-tax elite with the white working class, a bond which is even stronger today under Trump. My one qualm is his surprising discounting of abortion as a political issue. It’s very strong in unifying the Republican party, but perhaps he’d change that in a modern edition.
-
** Steve Jobs ** (2011) by acclaimed writer Walter Isaacson is the definitive biography of Steve Jobs. Described as a classic “wartime CEO” by Ben Horowitz in The Hard Thing About Hard Things, Jobs co-founded Apple with Steve Wozniak, but by 1985, Jobs was forced to leave in the wake of internal disagreements. Then, after some time in another startup and at Pixar, Jobs returned to Apple in 1997 when it was on the verge of bankruptcy, and somehow in the 2010s, Apple was on its way to being the most valuable company in the world and the first to hit 1 trillion in market capitalization. While writing the biography, Isaacson had access to Steve Jobs, his family, friends, and enemies. In fact, Isaacson had explicit approval from Jobs, who asked him to write the book on the basis of Isaacson’s prior biographies of Benjamin Franklin, Albert Einstein, and others. I am not sure if Jobs ever read this book, since he passed away from cancer only a few months after this book was published. The book is a mammoth 550-page volume, but it reads very quickly, and I often found myself wishing I could read more and more – Isaacson has a gift for tracing the life of Jobs, his upsides and downsides, and interactions with people as part of his CEO experience. There’s also a fair amount about the business aspects of Apple that made me better understand how things work. I can see why people might think it’s definitely recommended reading for MBAs. I wonder, and I hope, that there are ways to achieve his business success and talents without having the downsides of: angry outbursts, super-long work hours, demand for control, refusing and imposing unrealistic expectations (his “reality distortion field”). I would be curious to see how he contrasts with the style of other CEOs.
-
The Only Investment Guide You’ll Ever Need by Andrew Tobias is a book with a bad title but which has reasonably good content. It was first written in 1978, but has been continually updated over the years, and the most recent version which I read was the 2016 edition. As I prepare to move beyond my graduate student days, I should use my higher salary to invest more. Why? With proper investment, the rate of return on the money should be higher than if I let it sit in a savings account accumulating interest. Of course, that depends on investing wisely. The first part of the book has advice broadly applicable to everyone: how to save money in so-called incremental ways that add up over time. While advice such as buying your own coffee instead of going to Starbucks and living slightly below your means sounds boring and obvious, it’s important to get these basics out of the way. The second part dives more into investing in stocks, and covers concepts that are more foreign to me. My biggest takeaway is that one should avoid commission fees that add up, and that while it’s difficult to predict stocks, in the long run, investing in stocks generally pays off. This book, being a guide, is the kind that’s not necessarily meant to be read front-to-back, but one where I should return to every now and then on demand to get an opinion on an investing related topic.
-
Nasty Women: Feminism, Resistance, and Revolution in Trump’s America (2017) is a series of about 20 essays by a diverse set of women, representing different races, religions, disabilities, sexual orientations, jobs, geographic locations, and various other qualities. It was written shortly after Trump’s election, and these women unanimously oppose him. It was helpful to understand the experiences of these women, and how they felt threatened by someone who bragged about sexual assault and has some retrograde views on women. There was clear disappointment from these women towards the “53% of white women who voted for Trump,” a statistic repeated countless times in Nasty Women. On the issue of race, some of the Black women writers felt conflicted about attending the Women’s March, given that the original idea for these marches came from Black women. I agree with the criticism of these writers towards some liberal men, who may have strongly supported Bernie Sanders but had trouble supporting Clinton. For me, it was actually the reverse; I voted for Clinton over Sanders in the primaries. That said, I don’t agree with everything. For example, one author criticized the notion of Sarah Palin calling herself a feminist, and said that we need a different definition of feminism that doesn’t include someone like Palin. I think women have a wide range of beliefs, and we shouldn’t design feminism to leave Conservative women out of the umbrella. Nonetheless, there’s a lot of agreement between me and these authors.
-
The Hot Hand: The Mystery and Science of Streaks (2018) is by WSJ reporter Ben Cohen, who specializes in covering the NBA, NCAA, and other sports. “The hot hand” refers to a streak in anything. Cohen goes over the obvious: Stephen Curry is the best three point shooter in the history of basketball, and he can get on a hot streak. But, is there a scientific basis to this? Is there actually a hot hand, or does Curry just happen to hit his usual rate of shots, except that due to the nature of randomness, sometimes he will just have streaks? Besides shooting, Cohen reviews streaks in areas such as music, plays, academia, business, and Hollywood. From the first few chapters, it seems like most academics don’t think there is a hot hand, whereas people who actually perform the tasks (e.g., athletes) might think otherwise. The academics include Amos Tversky and Daniel Kahneman, the two famous Israeli psychologists who revolutionized their field. However, by the time we get to the last chapter of this book, Cohen points out two things that somehow were missed in most earlier discussions of the hot hand. First, basketball shots and similar things are not “independent, identically, distributed,” and controlling for the harder shot selection that people who think they have “the hot hand” take, they actually overperform relative to expectations. The second is slightly more involved but has to do with sequences of heads and tails that has profound implications in interpreting the hot hand. In fact, you can see a discussion on Andrew Gelman’s famous blog. So, is there a hot hand? The book leaves the question open, which I expected since a vague concept like this probably can’t be definitively proved or disproved. Overall, it’s a decent book. My main criticism is that some of the anecdotes (e.g., the search for a Swedish man in a Soviet prison and the Vincent van Gogh painting) don’t really mesh well with the book’s theme.
-
How to Do Nothing: Resisting the Attention Economy (2019) by artist and writer Jenny Odell is a manifesto about trying to move focus away from the “attention economy” as embodied by Facebook, Twitter, and other social media and websites which rely on click-through and advertisements for revenue. She wrote this after the Trump election, since (a) she’s a critic of Trump, and (b) Trump’s constant use of Twitter and other attention-grabbing comments have turned the country into a constant 24-hour news cycle. Odell cautions against us trying to use “digital detox” as a solution, and reviews the history of several such digital detox or “utopia” sessions that failed to pan out. The book isn’t the biggest page-turner but is still thought-provoking. However, I am not sure about her proposed tactics for “how to do nothing” except perhaps to focus on nature more? She supports preserving nature, along with people who protested the development of condos over preserved land, but this would continue to exacerbate the Bay Area’s existing housing crisis. I see the logic, but I can’t oppose more building. I do agree with reducing the need to attention, and while I do use social media and support its usage, I agree there are limits to it.
-
Inclusify: The Power of Uniqueness and Belonging to Build Innovative Teams (2020) is a recent book by Stefanie K. Johnson, a professor at the University of Colorado Boulder’s Leeds School of Business who studies leadership and diversity. Dr. Johnson defines inclusify “to live and lead in a way that recognizes and celebrates unique and dissenting perspectives while creating a collaborative and open-minded environment where everyone feels they truly belong.” She argues it helps increase sales, drives innovation, and reduces turnover, and the book is her attempt at distilling these lessons about improving diversity efforts at companies. She identifies six types of people who might be missing out on the benefits of inclusification: the meritocracy manager, the culture crusader, the team player, the white knight, the shepherd, and the optimist. I will need to keep these groups in mind to make sure I do not fall into these categories. Despite how I agree with the book’s claims, I’m not sure how much I benefited from reading Inclusify, given that I read this one after several other books this year that covered similar ground (e.g., many “anti-racist” books discuss these topics). I published this blog post a few months after reading the book, and I confess that I remember less about its contents as compared to other books.
-
Master of None: How a Jack-of-All-Trades Can Still Reach the Top (2020) is by Clifford Hudson, the former CEO of Sonic Drive-In, a fast food restaurant chain (see this NYTimes profile for context). This is an autobiography of Hudson who tries to push back against the notion that to live an accomplished life, one needs to master a particular skill, as popularized from books such as Malcolm Gladwell’s Outliers and his “10,000 Rule”. Hudson argues that his life has been fulfilling despite never deliberately mastering one skill. The world is constantly changing, so it is necessary to quickly adapt, to say “yes” to opportunities that arise, and to properly delegate tasks to others who know better. I think Hudson himself serves as evidence for not necessarily needing to master one skill, but the book seems well tailored for folks working in business, and I would be curious to see discussion in an academic context, where the system is built to encourage us to specialize in one field. It’s a reasonably good autobiography and a fast read. I would not call it super great or memorable. I may read David Epstein’s book Range: Why Generalists Triumph in a Specialized World to follow-up on this topic.
Well, that is it for 2020.
-
Kurzweil predicts that “we will encounter such a non-biological entity” by 2029 and that this will “become routine in the 2030s.” OK, let me revisit that in a decade! ↩
-
As far as I know, “polygenic scores” require taking a bunch of DNA samples and predicting outcomes, while CRISPR can actually do the editing of that DNA to lead to such outcomes. I’d be curious if any biochemists or psychologists could chime in to correct my understanding. ↩
-
Dana MacKenzie has an interesting story about being denied tenure at Kenyon College (which he taught after leaving Duke, when it was clear he would also not get tenure there). You can find it on his website. There is also a backstory on how he and Judea Pearl got together to write the book. ↩
-
Personally, I first found out about Hans Rosling through a Berkeley colleague’s research on data visualization. ↩
-
I didn’t realize that Martínez knew David Kauchak during their Adchemy days. I briefly collaborated with Kauchak during my undergraduate research. ↩
-
I somehow did not know about Lex Fridman’s AI podcast. If my book reading list feels shallower this year, then I blame his podcast for all those thrilling videos with pioneers of AI and related fields. ↩
-
To state the obvious, I have never been to one of these parties. Chang says: “the vast majority of people in Silicon Valley have no idea these kinds of sex parties are happening at all. If you’re reading this and shaking your head […] you may not be a rich and edgy male founder or investor, or a female tech in her twenties.” ↩
-
I rarely post status updates on my Facebook anymore, but a few days before her Op-Ed, I posted a graphic I created with pictures of leaders along with their country’s COVID-19 death count and death as a fraction of population. And, yes, my self-selected countries led by female leaders have done a reasonable job controlling the outbreak. I’m most impressed with Tsai Ing-wen of Taiwan, who had to handle this while (a) being geographically close to China itself, and (b) largely ostracized by the wider international community. For an example of the second point, look at how a WHO official dodged a question about Taiwan and COVID-19. ↩
-
If you’re curious, Desmond has a postscript at the end of the book explaining how he did this research project, including when he felt like he needed to intervene, and how the tenants treated him. It’s fascinating, and I wish this section of the book were much longer, but I understand if Desmond did not want to raise too much attention to himself. In addition, there is a lot of data in the footnotes. I read all the footnotes, and recommend reading them even if it comes at the cost of some “reading discontinuity.” ↩
-
When he ran for his state political office, he and a small group of campaigners went door-to-door and contacted people face-to-face. I don’t know how this would scale to larger cities or work in the age of COVID-19. Incidentally, there isn’t any discussion on COVID-19, but I suspect if Sellers had written the book just a few months later, he would discuss the pandemic’s disparate impact on Blacks. ↩
-
I do not feel like I know enough about the Iran Nuclear Deal to give a qualified statement. I was probably a lukewarm supporter of it, but since the deal no longer appears to be active as of January 2020, I am in favor of a stronger deal (as in, one that can get U.S. congressional approval) if that is at all possible. ↩
-
The ruling army junta (i.e., a government led by the military) changed the English name of the country from Burma to Myanmar in 1989. ↩
-
She isn’t the only terrible recipient of the Nobel Peace Prize. Reading the list of past recipients sometimes feels like going through one nightmare after the other. ↩
Mechanical Search in Robotics
One reason why I enjoy working on robotics is because many of the problems the research community explores are variants of tasks that we humans do on a daily basis. For example, consider the problem of searching for and retrieving a target object in clutter. We do this all the time. We might have a drawer of kitchen appliances, and may want to pick out a specific pot for cooking food. Or, maybe we have a box filled with a variety of facial masks, and we want to pick the one to wear today when venturing outside (something perhaps quite common these days). In the robotics community, recent researchers that I collaborate with have formulated this as the mechanical search problem.
In this blog post, I discuss four recent research papers on mechanical search, split up into two parts. The first two focus on core mechanical search topics, and the latter two propose using something called learned occupancy distributions. Collectively, these papers have appeared at ICRA 2019 and IROS 2020 (twice), and one of these is an ICRA 2021 submission.
Mechanical Search and Visuomotor Mechanical Search
The ICRA 2019 paper formalizes mechanical search as the task of retrieving a specific target object from an environment containing a variety of objects within a time limit. They frame the general problem using the Markov Decision Process (MDP) framework, with the usual states, actions, transitions, rewards, and so on. They consider a specific instantiation of the mechanical search MDP as follows:
- They consider heaps of 10-20 objects at the start.
- The target object to extract is specified by a set of $k$ overhead RGB images.
- The observations at each time step (which a policy would consume as input) are RGB-D, where the extra depth component can enable better segmentation.
- The methods they use do not use any reward signal.
- They enable three action primitives: (a) push, (b) suction, and (c) grasp.
The push action is there so that the robot can rearrange the scene for better suction and grasp actions, which are the primitives that actually enable the robot to retrieve the target object (or distractor objects, for that matter). While more complex action primitives might be useful for mechanical search, this would introduce complexities due to the curse of dimensionality.
Here’s the helpful overview figure from the paper (with the caption) showing their instantiation of mechanical search:
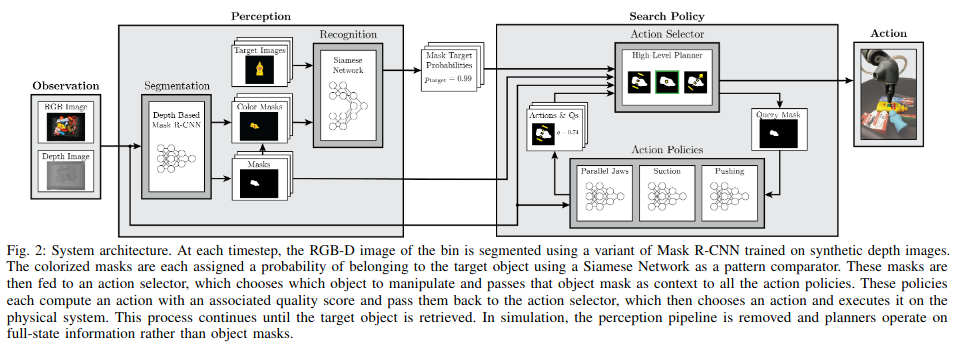
I like these type of figures, and they are standard for papers we write in Ken Goldberg’s lab.
The pipeline is split up into a perception stage and a search policy stage. The perception stage first computes a set of object masks from the input RGB-D observation. It then uses a trained Siamese Network to check the “similarity” between any of these masks, and those of the target images. (Remember, in their formulation, we assume $k$ separate images that specify the target, so we can feed all combinations of each target image with each of the computed masks.) If a target image is found, then they can run the search policy to select one of the three allowed action primitives, depending on the action primitive with the highest “score.” How is this value chosen? We can use off-the-shelf Dex-Net policies to compute the probability of action successes. Please refer to my earlier blog post here about Dex-Net.
Here are a couple of things that might not be clear upon a first read of the paper:
- There’s a difference between how action qualities are computed in simulation versus real. In simulation, grasp and suction actions both use indexed grasps from a simulated Dex-Net 1.0 policy in simulation, which is easy to use as it avoids having to run segmentation. In addition, Dex-Net 1.0 literally contains a dataset of simulated objects plus successful grasps for each object, so we can cycle through those as needed.
- In real, however, we don’t have easy access to this information. Fortunately, for grasp and suction actions, we have ready-made policies from Dex-Net 2.0 and Dex-Net 3.0, respectively. We could use them in simulation as well, it’s just not necessary.
To be clear, this is how to compute the action quality. But there’s a hierarchy: we need an action selector that can use the computed object masks (from the perception stage) to decide which object we want to grasp using the lower-level action primitives. This is where their 5 algorithmic policies come into play, which correspond to “Action Selector” in the figure above. They test with random search, prioritizing the target object (with and without pushing), and a largest first variant (again, with and without pushing).
The experiments show that, as expected, algorithmic policies that prioritize the target object and the larger objects (if the target is not visible) are better. However, a reader might argue that from looking closely at the figures in the paper, the difference in performance among the 4 algorithmic policies other than the random policy may be minor.
That being said, as a paper that introduces the mechanical search problem, they have a mandate to test the simplest types of policies possible. The conclusion correctly points out that an interesting avenue for future work is to do reinforcement learning. Did they do that?
Yes! This is good news for those of us who like to see research progress, and bad news for those who were trying to beat the authors to it. That’s the purpose of their follow-up IROS 2020 paper, Visuomotor Mechanical Search. It fills in the obvious gap made from the ICRA 2019 paper: that performance is limited by algorithmic policies, which are furthermore restricted to linear pushes parameterized by an initial point and then a push direction. Properly-trained learning-based policies that can perform continuous pushing strategies should be able to better generalize to complex configurations than algorithmic ones.
Since naively applying Deep RL is very sample inefficient, the paper proposes an approach combining three components:
- Demonstrations. It’s well-known that demonstrations are helpful in mitigating exploration issues, a topic I have previously explored on this blog.
- Asymmetric Information. This is a fancy way of saying that during training, the agent can use information that is not available at test time. This can be done when using simulators (as in my own work, for example) since the simulator includes detailed information such as ground-truth object positions which are not easily accessible from just looking at an image.
- Mid-Level Representations. This means providing the policy (i.e., actor) not the raw RGB image, but something “mid-level.” Here, “mid-level” means the segmentation mask of the target object, plus camera extrinsics and intrinsics. These are what actually get passed as input to the mechanical search policy, and the logic for this is that the full RGB image would be needlessly complex. It is better to just isolate the target object. Note that the full depth image is passed as input — the mid-level representation just replaces the RGB component.
In the MDP formulation for visuomotor mechanical search, observations are RGBD images and the robot’s end-effector, actions are relative end-effector changes, and the reward is a shaped and hand-tuned to encourage the agent to make the target object visible. While I have some concerns about shaping rewards in general, it seems to have worked for them. While the actor policy takes in the full depth image, it simultaneously consumes the mid-level representation of the RGB observation. In simulation, one can derive the mid-level representation from ground-truth segmentation masks provided by PyBullet simulation. They did not test on physical robots, but they claim that it should be possible to use a trained segmentation model.
Now, what about the teachers? They define three hard-coded teachers that perform pushing actions, and merge the teachers as demonstrators into the “AC-Teach” framework. This is the authors’ prior paper that they presented at CoRL 2019. I read the paper in quite some detail, and to summarize, it’s a way of performing training that can combine multiple teachers together, each of which may be suboptimal or only cover part of the state space. The teachers use privileged information by not using images but rather using positions of all objects, both the target and the non-target(s).
Then, with all this, the actor $\pi_\theta(s)$ and critic $Q_\phi(s, a)$ are updated using standard DDPG-style losses. Here is Figure 2 from the visuomotor mechanical search paper, which summarizes the previous points:
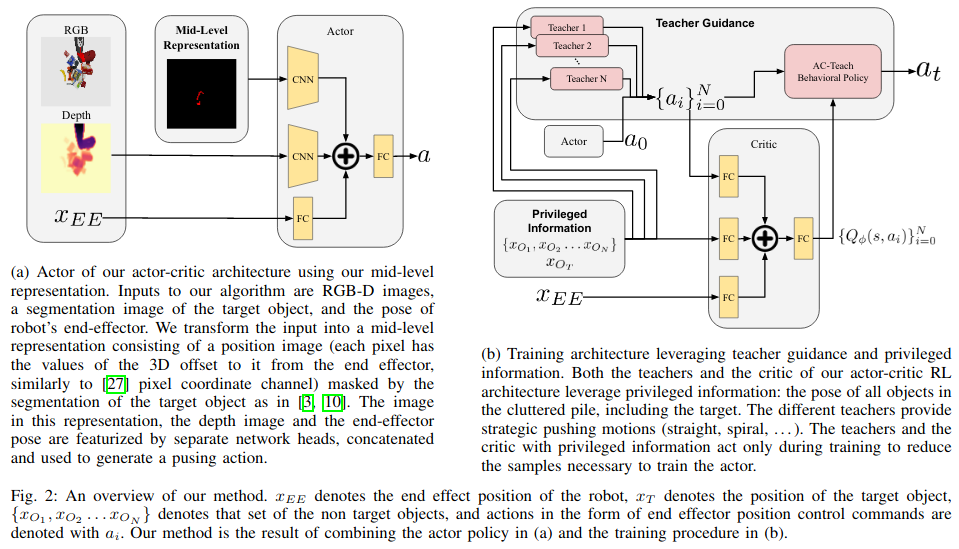
Remember that the policy executes these actions continuously, without retracting the arm after each discrete push, as done in the method from the ICRA 2019 paper.
They conduct all experiments in PyBullet simulation, and extensively test by ablating on various components. The experiments focus on either a single-heap or a dual-heap set of objects, which additionally tests if the policy can learn to ignore the “distractor” heap (i.e., the one without the target object in it) in the latter setting. The major future work plan is to address failure cases. I would also add that the authors could consider applying this on a physical robot.
These two papers give a nice overview of two flavors of mechanical search. The next two papers also relate to mechanical search, and utilize something known as learned occupancy distributions. Let’s dive in to see what that means.
X-RAY and LAX-RAY
In an IROS 2020 paper, Danielczuk and collaborators introduce the idea of X-RAY for mechanical search of occluded objects. To be clear: there was already occlusion present in the prior works, but this work explicitly considers it. X-RAY stands for maXimize Reduction in support Area of occupancY distribution. The key idea is to use X-RAY to estimate “occupancy distributions,” a fancy way of labeling each bounding box in an image with the likelihood that it contains the target object.
As with the prior works, there is an MDP formulation, but there are a few other important definitions:
- The modal segmentation mask: regions of pixels in an image corresponding to a given target object which are visible.
- The amodal segmentation mask: regions of pixels in an image corresponding to a given target image which are either visible or invisible. Thus, the amodal segmentation mask must contain the modal segmentation mask, as it has both the visible component, plus any invisible stuff (which is where the occlusion happens).
- Finally, the occupancy distribution $\rho \in \mathcal{P}$: the unnormalized distribution describing the likelihood that a given pixel in the observation image contains some part of the target object’s amodal segmentation mask.
This enables them to utilize the following reward function to replace a sparse reward:
\[\tilde{R}(\mathbf{y}_k, \mathbf{y}_{k+1}) = |{\rm supp}(f_\rho(\mathbf{y}_{k}))| - |{\rm supp}(f_\rho(\mathbf{y}_{k+1}))|\]where \(f_\rho\) is a function that takes in an observation \(\mathbf{y}_{k}\) (following the paper’s notation) and produces the occupancy distribution \(\rho_k\) for a given bounding box, and where \(|{\rm supp}(\rho)|\) for a given support \(\rho\) (dropping the $k$ subscript for now) is the number of nonzero pixels in \(\rho\).
Why is this logical? By reducing the occupancy distribution, one decreases the number pixels that MIGHT occlude the target objects, hence reducing uncertainty. Said another way, increasing this reward gives us greater certainty as to where the target object is located, which is an obvious prerequisite for mechanical search.
The paper then describes (a) how to estimate $f_\rho$ in a data-driven manner, and then (b) how to use this learned $f_\rho$, along with $\tilde{R}$, to define a greedy policy.
There’s an elaborate pipeline for generating the training data. Originally I was confused about their procedure for translating the target object. But after reading carefully and watching the supplementary video, I understand; it involves simulating a translation and rotation while keeping objects fixed. Basically, they pretend they can repeatedly insert the target object at specific locations underneath a pile of distractor objects, and if it results in the same occupancy distribution, then they can include such images in the data to expand the occupancy distribution to its maximum possible area (by aggregating all the amodal maps), meaning that estimates of the occupancy distribution are a lower bound on the area.
As expected, they train using a Fully Convolutional Network (FCN) with a pixel-wise MSE loss. You can think of this loss as taking the target image and the image produced from the FCN, unrolling them into long vectors \(\mathbf{x}_{\rm targ}\) and \(\mathbf{x}_{\rm pred}\), then computing
\[\|\mathbf{x}_{\rm targ} - \mathbf{x}_{\rm pred}\|_2^2\]to find the loss. This glosses over a tiny detail: the network actually predicts occupancy distributions for different aspect ratios (one per channel in the output image) and only the channel with the similar input aspect ratio gets considered for the loss. Not a huge deal to know if you’re skimming the paper: it probably suffices to just realize that it’s the standard MSE.
Here is the paper’s key overview figure:
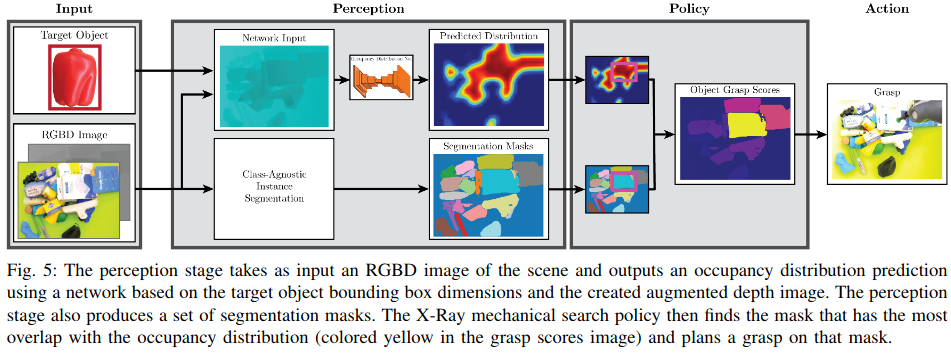
They propose to plan a grasp with the most amount of corresponding occupancy area. Why? A pick and place at that spot will greatly reduce the subsequent occupancy area of the target object.
It is nice that these FCNs can reasonably predict occupancy distributions for target objects unseen in training, and that it can generalize to the physical world without actually training on physical images. Training on real images would be harder since depth images would likely be noisier.
The two future works they propose are: relieving themselves of the assumption that the target object is flat, and (again) saying that they will do reinforcement learning. This paper was concurrent with the visuomotor mechanical search, but that paper did not technically employ X-RAY, so I suppose there is room to merge the two.
Next, what about the follow-up work of LAX-RAY? This addresses an obvious extension in that instead of top-down grasping, one can do lateral grasping, where the robot arm moves horizontally instead of vertically. This enables application to shelves. Here’s the figure summarizing the idea:

We can see that a Fetch robot has to reveal something deep into the shelf by pushing objects in front to either the left or the right. The robot has a long thin board attached to its gripper, it’s not the usual Fetch gripper. The task ends as soon as the target object, known beforehand, is revealed.
As with standard X-RAY, the method involves using a Fully Convolutional Network (FCN) to map from an image of the shelf to a distribution of where the target object could be. (Note: the first version of the arXiv paper says “fully connected” but I confirmed with the authors that it is indeed an FCN, which is a different term.) This produces a 2D image. Unlike X-RAY, LAX-RAY maps this 2D occupancy distribution to a 1D occupancy distribution. The paper visualizes these 1D occupancy distributions by overlaying them on depth images. The math is fairly straightforward on how to get a 1D distribution: just consider every “vertical bar” in the image as one point in the distribution, then sum over the values from the 2D occupancy distribution. That’s how I visualize it.
The paper proposes three policies for lateral-access mechanical search:
- Distribution Area Reduction (DAR): ranks actions based on overlap between the object mask and the predicted occupancy distribution, and picks the action that reduces the sum the most. This policy is the most similar, in theory, to the X-RAY policy: essentially we’re trying to “remove” the occupancy distribution to reduce areas where the object might be occluded.
- Distribution Entropy Reduction over n Steps (DER-n): this tries to predict what the 1D occupancy distribution will look like over $n$ steps, and then picks the one with lowest entropy. Why does this make sense? Because lower entropy means the distribution is less spread out, and concentrated towards one area, telling us where the occluded item is located. The authors also introduce this so that they can test with multi-step planning.
- Uniform: this tests a DAR ablation by removing the predicted occupancy distribution.
They also introduce a First-Order Shelf Simulator (FOSS), a simulator they use for fast prototyping, before experimenting with the physical Fetch robot.
What are some of my thoughts on how they can build upon this work? Here are a few:
- They can focus on grasping the object. Right now the objective is only to reveal the object, but there’s no actual robot grasp execution. Suctioning in a lateral direction might require more sensitive controls to avoid pushing the object too much, as compared to top-down where gravity stops the target object from moving away.
- The setup might be a bit constrained in that it assumes stuff can be pushed around. For example consider a vase with water and flowers. Those might be hard to push, and are at risk of toppling.
Parting Thoughts
To summarize, here is how I view these four papers grouped together:
- Paper 1: introduces and formalizes mechanical search, and presents a study of 5 algorithmic (i.e., not learned) policies.
- Paper 2: extends mechanical search to use AC-Teach for training a learned policy that can execute actions continually.
- Paper 3: combines mechanical search with “occupancy distributions,” with the intuition being that we want the robot to check the most likely places where an occluded object could be located.
- Paper 4: extends the prior paper to handle lateral access scenarios, as in shelves.
What are some other thoughts and takeaways I have?
- It would be exciting to see this capability mounted onto a mobile robot, like the HSR that we used for our bed-making paper. (We also used a Fetch, and I know the LAX-RAY paper uses a Fetch, but the Fetch’s base stayed put during LAX-RAY experiments.) Obviously, this would not be novel from a research perspective, so something new would have to be added, such as adjustments to the method to handle imprecision due to mobility.
- It would be nice to see if we can make these apply for deformable bags, i.e., replace the bins with bags, and see what happens. I showed that we can at least simulate bagging items in PyBullet in some concurrent work.
- There’s also a fifth mechanical search paper, on hierarchical mechanical search, also under review for ICRA 2021. I only had time to skim it briefly and did not realize it existed until after I had drafted the majority of this blog post. I have added it in the reference list below.
References
-
Michael Danielczuk, Andrey Kurenkov, Ashwin Balakrishna, Matthew Matl, David Wang, Roberto Martín-Martín, Animesh Garg, Silvio Savarese, Ken Goldberg. Mechanical Search: Multi-Step Retrieval of a Target Object Occluded by Clutter, ICRA 2019.
-
Andrey Kurenkov, Joseph Taglic, Rohun Kulkarni, Marcus Dominguez-Kuhne, Animesh Garg, Roberto Martín-Martín, Silvio Savarese. Visuomotor Mechanical Search: Learning to Retrieve Target Objects in Clutter, IROS 2020.
-
Michael Danielczuk, Anelia Angelova, Vincent Vanhoucke, Ken Goldberg. X-Ray: Mechanical Search for an Occluded Object by Minimizing Support of Learned Occupancy Distributions, IROS 2020.
-
Huang Huang, Marcus Dominguez-Kuhne, Jeffrey Ichnowski, Vishal Satish, Michael Danielczuk, Kate Sanders, Andrew Lee, Anelia Angelova, Vincent Vanhoucke, Ken Goldberg. Mechanical Search on Shelves using Lateral Access X-RAY, arXiv 2020.
-
Andrey Kurenkov, Ajay Mandlekar, Roberto Martin-Martin, Silvio Savarese, Animesh Garg. AC-Teach: A Bayesian Actor-Critic Method for Policy Learning with an Ensemble of Suboptimal Teachers, CoRL 2019.
-
Andrey Kurenkov, Roberto Martín-Martín, Jeff Ichnowski, Ken Goldberg, Silvio Savarese. Semantic and Geometric Modeling with Neural Message Passing in 3D Scene Graphs for Hierarchical Mechanical Search, arXiv 2020.
DAgger Versus SafeDAgger
The seminal DAgger paper from AISTATS 2011 has had a tremendous impact on machine learning, imitation learning, and robotics. In contrast to the vanilla supervised learning approach to imitation learning, DAgger proposes to use a supervisor to provide corrective labels to counter compounding errors. Part of this BAIR Blog post has a high-level overview of the issues surrounding compounding errors (or “covariate shift”), and describes DAgger as an on-policy approach to imitation learning. DAgger itself — short for Dataset Aggregation — is super simple and looks like this:
- Train \(\pi_\theta(\mathbf{a}_t \mid \mathbf{o}_t)\) from demonstrator data \(\mathcal{D} = \{\mathbf{o}_1, \mathbf{a}_1, \ldots, \mathbf{o}_N, \mathbf{a}_N\}\).
- Run \(\pi_\theta(\mathbf{a}_t \mid \mathbf{o}_t)\) to get an on-policy dataset \(\mathcal{D}_\pi = \{\mathbf{o}_1, \ldots, \mathbf{o}_M\}\).
- Ask a demonstrator to label $\mathcal{D}_\pi$ with actions $\mathbf{a}_t$.
- Aggregate $\mathcal{D} \leftarrow \mathcal{D} \cup \mathcal{D}_{\pi}$ and train again.
with the notation borrowed from Berkeley’s DeepRL course. The training step is usually done via standard supervised learning. The original DAgger paper includes a hyperparameter $\beta$ so that the on-policy data is actually generated with a mixture:
\[\pi = \beta \pi_{\rm supervisor} + (1-\beta) \pi_{\rm agent}\]but in practice I set $\beta=0$, which in this case means all states are generated from the learner agent, and then subsequently labeled from the supervisor.
DAgger is attractive not only in practice but also in terms of theory. The analysis of DAgger relies on mathematical ingredients from regret analysis and online learning, as hinted by the paper title: “A Reduction of Imitation learning and Structured Prediction to No-Regret Online Learning.” You can find some relevant theory in (Kakade and Tewari, NeurIPS 2009).
The Dark Side of DAgger
Now that I have started getting used to reading and reviewing papers in my field, I can more easily understand tradeoffs in algorithms. So, while DAgger is a conceptually simple and effective method, what are its downsides?
- We have to request the supervisor for labels.
- This has to be done for each state the agent encounters when taking steps in an environment.
Practitioners can mitigate these by using a simulated demonstrator, as I have done in some of my robot fabric manipulation work. In fact, I’m guessing this is the norm in machine learning research papers that use DAgger. This is not always feasible, however, and even with a simulated demonstrator, there are advantages to querying less often.
Keeping within the DAgger framework, an obvious solution would be to only request labels for a subset of data points. That’s precisely what the SafeDAgger algorithm, proposed by Zhang and Cho, and presented at AAAI 2017, intends to accomplish. Thus, let’s understand how SafeDAgger works. In the subsequent discussion, I will (generally) use the notation from the SafeDAgger paper.
SafeDAgger
The SafeDAgger paper has a nice high-level summary:
In this paper, we propose a query-efficient extension of the DAgger, called SafeDAgger. We first introduce a safety policy that learns to predict the error made by a primary policy without querying a reference policy. This safety policy is incorporated into the DAgger’s iterations in order to select only a small subset of training examples that are collected by a primary policy. This subset selection significantly reduces the number of queries to a reference policy.
Here is the algorithm:

SafeDAgger uses a primary policy $\pi$ and a reference policy \(\pi^*\), and introduces a third policy $\pi_{\rm safe}$, known as the safety policy, which takes in the observation of the state $\phi(s)$ and must determine whether the primary policy $\pi$ is likely to deviate from a reference policy \(\pi^*\) at $\phi(s)$.
A quick side note: I often treat “states” $s$ and “observations” $\phi(s)$ (or $\mathbf{o}$ in my preferred notation) interchangeably, but keep in mind that these technically refer to different concepts. The “reference” policy is also often referred to as a “supervisor,” “demonstrator,” “expert,” or “teacher.”
A very important fact, which the paper (to its credit) repeatedly accentuates, is that because $\pi_{\rm safe}$ is called at each time step to determine if the reference must be queried, $\pi_{\rm safe}$ cannot query \(\pi^*\). Otherwise, there’s no benefit — one might as well dispense with $\pi_{\rm safe}$ all together and query \(\pi^*\) normally for all data points.
The deviation $\epsilon$ is defined with the $L_2$ distance:
\[\epsilon(\pi, \pi^*, \phi(s)) = \| \pi(\phi(s)) - \pi^*(\phi(s)) \|_2^2\]since actions in this case are in continuous land. The optimal safety policy $\pi_{\rm safe}^*$ is:
\[\pi_{\rm safe}^*(\pi, \phi(s)) = \begin{cases} 0, \quad \mbox{if}\; \epsilon(\pi, \pi^*, \phi(s)) > \tau \\ 1, \quad \mbox{otherwise} \end{cases}\]where the cutoff $\tau$ is user-determined.
The real question now is how to train $\pi_{\rm safe}$ from data \(D = \{ \phi(s)_1, \ldots, \phi(s)_N \}\). The training uses the binary cross entropy loss, where the label is “are the two policies taking sufficiently different actions”? For a given dataset $D$, the loss is:
\[\begin{align} l_{\rm safe}(\pi_{\rm safe}, \pi, \pi^*, D) &= - \frac{1}{N} \sum_{n=1}^{N} \pi_{\rm safe}^*(\phi(s)_n) \log \pi_{\rm safe}(\phi(s)_n, \pi) + \\ & (1 - \pi_{\rm safe}^*(\phi(s)_n)) \log(1 - \pi_{\rm safe}(\phi(s)_n, \pi)) \end{align}\]again, here, \(\pi_{\rm safe}^*\) and \((1-\pi_{\rm safe}^*)\) represent ground-truth labels for the cross entropy loss. It’s a bit tricky; the label isn’t something inherent in a training data, but something SafeDAgger artificially enforces to get desired behavior.
Now let’s discuss the control flow of SafeDAgger. The agent collects data by following a safety strategy. Here’s how it works: at every time step, if $\pi_{\rm safe}(\pi, \phi(s)) = 1$, let the usual agent take actions. Otherwise, $\pi_{\rm safe}(\pi, \phi(s)) = 0$ (remember, this function is binary) and the reference policy takes actions. Since this is done at each time step, the reference policy can return control to the agent as soon as it is back into a “safe” state with low action discrepancy.
Also, when the reference policy takes actions, these are the data points that get labeled to produce a subset of data $D’$ that form the input to $l_{\rm safe}$. Hence, the process of deciding which subset of states should be used to query the reference happens during environment interaction time, and is not a post-processing event.
Training happens in lines 9 and 10 of the algorithm, which updates not only the agent $\pi$, but also the safety policy $\pi_{\rm safe}$.
Actually, it’s somewhat strange why the safety policy should help out. If you notice, the algorithm will continually add new data to existing datasets, so while $D_{\rm safe}$ initially produces a vastly different dataset for $\pi_{\rm safe}$ training, in the limit, $\pi$ and $\pi_{\rm safe}$ will be trained on the same dataset. Line 9, which trains $\pi$, will make it so that for all $\phi(s) \in D$, we have \(\pi(\phi(s)) \approx \pi^*(\phi(s))\). Then, line 10 trains $\pi_{\rm safe}$ … but if the training in the previous step worked, then the discrepancies should all be small, and hence it’s unclear why we need a threshold if we know that all observations in the data result in similar actions between \(\pi\) and \(\pi^*\). In some sense $\pi_{\rm safe}$ is learning a support constraint, but it would not be seeing any negative samples. It is somewhat of a philosophical mystery.
Experiments. The paper uses the driving simulator TORCS with a scripted demonstrator. (I have very limited experience with TORCS from an ICRA 2019 paper.)
-
They use 10 tracks, with 7 for training and 3 for testing. The test tracks are only used to evaluate the learned policy (called “primary” in the paper).
-
Using a histogram of squared errors in the data, they decide on $\tau = 0.0025$ as the threshold so that 20 percent of initial training samples are considered “unsafe.”
-
They report damage per lap as a way to measure policy safety, and argue that policies trained with SafeDAgger converge to a perfect, no-damage policy faster than vanilla DAgger. I’m having a hard time reading the plots, though — their “SafeDAgger-Safe” curve in Figure 2 appears to be perfect from the beginning.
-
Experiments also suggest that as the number of DAgger iterations increases, the proportion of time driven by the reference policy decreases.
Future Work? After reading the paper, I had some thoughts about future work directions:
-
First, SafeDAgger is a broadly applicable algorithm. It is not specific to driving, and it should be feasible to apply to other imitation learning problems.
-
Second, the cost is the same for each data point. This is certainly not the case in real life scenarios. Consider context switching: one can request the reference for help in time steps 1, 3, 5, 7, and 9, or it can request the reference for help in times 3, 4, 5, 6, and 7. Both require the same raw number of references, but it seems intuitive in some way that given a fixed budget of time, a reference policy should want a contiguous time step.
-
Finally, one downside strictly from a scientific perspective is that there are no other baseline methods tested other than vanilla DAgger. I wonder if it would be feasible to compare SafeDAgger with an approach such as SHIV from ICRA 2016.
Conclusion
To recap: SafeDAgger follows the DAgger framework, and attempts to reduce the number of queries to the reference/supervisor policy. SafeDAgger predicts the discrepancy among the learner and supervisor. Those states with high discrepancy are those which get queried (i.e., labeled) and used in training.
There’s been a significant amount of follow-up work on DAgger. If I am thinking about trying to reduce supervisor burden, then SafeDAgger is among the methods that come to my mind. Similar algorithms may get increasingly used in machine learning if DAgger-style methods become more pervasive in machine learning research, and in real life.
How I Made My IROS 2020 Conference Presentation Video
This is my official video presentation for IROS 2020.
The 2020 International Conference on Intelligent Robots and Systems (IROS) will be virtual. It was planned to be in Las Vegas, Nevada, from October 25-29. While this was unfortunately expected, I understand the need to reduce large gatherings, as the pandemic is still happening here. I wish our government, and private citizens, could look around the world and see where things are going right regarding COVID-19; for example, Taiwan is having 10,000 person concerts and has all of seven recorded deaths as of today, while the United States still has heavy restrictions on in-person gatherings with well over 200,000 deaths (here’s the source I’ve been checking to track this information).
For IROS 2020, I am presenting a paper on robot fabric manipulation, done in collaboration with wonderful colleagues from Berkeley and Honda Research Institute. IROS 2020 asked us to create a 15-minute video for each paper, and my final product is shown above and also available on my YouTube channel. This is by far the longest pre-recorded video I have ever made for a conference. I believe it’s also my first video with audio. Normally, my research videos are just a handful of minutes long, and if I need to clarify things in the video, I add text (subtitles) manually in the iMovie application. For my IROS video, however, I wanted to make the video longer with audio, but I also knew I needed a more scalable way to add subtitles, which would be necessary for me to completely understand the video if I were to re-watch it many years later. I also wanted to add subtitles and to make them unavoidably visible to encourage other researchers to add subtitles to their videos.
Here is the backstory of how I made this video.
First, as part of my research that turned into this paper, I had many short video clips of a robot manipulating fabric in iMovie on my MacBook Pro laptop. I started a fresh iMovie file, and picked the robot videos that I wanted to include.
Then, I created a new Google Slides and a new Google Doc. In the Google Slides file, I created the slides that I wanted to show in the final video. These slides were mostly copied and pasted from earlier, internal research presentations, and reformatted to a consistent font and size style.
In the Google Doc, I wrote down my entire transcript, which turned out to be slightly over four pages. I then practiced my audio by stating what I wrote on the transcript, peppered with my usual enthusiasm. I also tried to avoid talking too fast. I used the voice Memos app on my iPhone to record audio. I made multiple audio files, each about one minute long. This made it simpler to redo any audio (which I had to do frequently) since I only had to redo small portions instead of the entire video’s audio.
Once I felt like the slides were ready, and that they aligned well with the audio, I put in each slide and audio file into iMovie, carefully adjusting the time ranges to align them, and to make sure the video did not exceed the 15-minute limit. I made further edits and improvements to the video after getting feedback from my colleagues. When I was sufficiently satisfied with the result, I saved and got an .mp4 video file.
But what about adding subtitles?
iMovie contains functionality for adding subtitles, but the process is manual and highly cumbersome. After some research, I found this video tutorial which demonstrates how to use Kapwing to add subtitles. Kapwing is entirely web-based, so there’s no need to download it locally – I can upload videos to their website and edit in a web browser.
I can add subtitles to Kapwing by uploading audio files, and Kapwing will use automatic speech recognition to generate an initial draft, which I then fine-tune. Here is the interface for adding subtitles:
I paid 20 USD for a monthly subscription so that I could create a longer video, and followed the tutorial mentioned earlier to add subtitles. Eventually, I got my 15-minute video, which just barely fit under the 50MB file limit as mandated by IROS. I uploaded it to the conference, as well as to YouTube, which is the one at the top of this post.
I am happy with the final video product. That said, the process of adding subtitles was not ideal:
-
The automatic speech recognition for producing an initial guess at the subtitles is … bad. I mean, really bad. I guess it got less than 5% of my audio correct, so in practice I was adding all of my subtitles by manually copying and pasting from my Google Doc. To put things in perspective, Google Meet (my go-to video conferencing tool these days) handles my audio far better, with subtitles that are remarkably highly quality.
-
The interface for subtitles is also cumbersome to use, though to be fair, it’s an improvement over iMovie. As shown in the screenshot above, when re-editing a video, it doesn’t seem to preserve the ordering of the subtitles (notice how my first line in the video is listed second above). Furthermore, when editing and then clicking “Done”, I sometimes saw subtitles with incorrect sizes, so I had to re-edit the video … only to see a few subtitles disappear each time I did this. There also did not seem to be a way to change the subtitle size for all subtitles simultaneously. My solution was to forget about saving in progress, and to painstakingly go through each subtitle to change the size by manually clicking via a drop-down menu.
I hope this was useful! It is likely that future conferences will continue to be virtual in some way. For example, I am attempting to submit several papers to ICRA 2021, which will be in Xi’an, China, next summer. The website says ICRA 2021 will be a hybrid event with a mix of virtual and in-person events, but I would bet that many travel restrictions will still be in place, particularly for researchers from the United States. For that, and several other reasons, I am almost certainly going to be a virtual attendee, so I may need to revisit these instructions when making additional video recordings.
As always, thank you for reading, stay safe, and wear a mask.
The Virtual 2020 Robotics: Science and Systems Conference
I have attended eight international academic conferences that contain refereed paper proceedings. My situation is much different nowadays as compared to the middle of 2016, when I had attended zero academic conferences, thought my research career was going nowhere, and that I would leave Berkeley without a PhD.
The most recent conference I attended was also my first virtual one, the 2020 Robotics: Science and Systems, one of the world’s premier robotics conferences. It occurred last month, and in keeping up with the tradition of my blog, I will briefly discuss what happened while adding some thoughts about virtual conferences.
RSS 2020: The Workshop Days
RSS 2020 consisted of five days, with the first two dedicated to workshops. For the two workshop days, I checked the schedule in advance and decided on one workshop per day to attend, to avoid overextending my attention span and to keep my schedule manageable. For the first day, I attended the 2nd Workshop on Closing the Reality Gap in Sim2Real Transfer for Robotics. It was a fun one: much of it consisted of pre-recorded, two-on-two debates addressing controversial statements:
- “Investing into Sim2Real is a waste of time and money”
- “Sim2Real is old news. It’s just X (X=model-based RL, X=domain randomization, X=system identification)”
- “Sim2Real requires highly accurate physical simulators and photorealistic rendering”
I am a huge fan of Sim2Real, and several of my papers use the technique, so I was especially galled by the first claim. Surely it can’t possibly be a waste of time and money? (Full disclosure: one of my PhD advisors agrees with me and was in the debate arguing against the first claim, but I still would hold that belief even if he was not involved. You’ll have to take my word on that.) Going through the debate was enjoyable – despite my opposition to the statement, I appreciated the perspectives of the two CMU professors, Abhinav Gupta and Chris Atkeson, arguing in favor of the claim. While researching the academic publications of those professors, I found Chris Atkeson’s impressive and persuasive 100-page paper providing his advice for starting graduate students, which features some Sim2Real discussion.
Rather than try to further describe my messy notes, I will refer you to my former colleague (and now CMU PhD student) Jacky Liang, who wrote a nice summary of the workshop. I am still going to be doing some Sim2Real work in the near future, and particularly nowadays due to the pandemic limiting access to physical robots, an obvious point that was somehow only articulated at the end of the workshop, by Berkeley Professor Anca Dragan.
For the next day, I attended the workshop on Self-Supervised Robot Learning. This was a four-hour workshop, and one that was more traditional in the sense that it was a series of longer talks by professors and research scientists, with shorter “lightning talks” by authors of accepted workshop papers. I chose to attend this because I am very interested in the topic, and think getting automatic supervision without tedious, manual labeling is key for scaling up robots to the real world. Here’s a relevant blog post of mine if you would like to read more.
There were seven speakers, and I have personally spoken to six of them (all except Abhinav Gupta):
- Dieter Fox: discussed KinectFusion and self-correspondences with descriptors. I knew some of this material from reading the relevant papers, and (you guessed it) I have a relevant blog post.
- Abhinav Gupta: talked about much of newly-appointed Professor Lerrel Pinto’s work in scaling up robot learning. I have read almost all of Lerrel Pinto’s early papers and was pleased to see them resurface here.
- Pierre Sermanet: discussed his “learning from play” papers which involve planning and learning from language. It’s fascinating stuff, and I have his papers on my “to read” list.
- Roberto Calandra: provided a series of “lessons learned” in doing robot learning research, and commented about how COVID-19 might mandate more self-supervised robots that can run on their own.
- Chelsea Finn: presented a chronology over the last 5 years about how we acquire data for robot learning, and how we can make this scale up. Critically, we need to broaden the training data distribution to cover more test-time scenarios.
- Pieter Abbeel: presented the CURL and RAD papers which suggest that learning from pixels can be as efficient as learning from state. I have read the papers in some detail, and helped with formatting the recent BAIR blog post about CURL and RAD.
- Andy Zeng: provided his thoughts on the “object-ness” assumption in robot learning, and how he was able to get automatic labels for his papers. I described some of his great work in this blog post. I am also very fortunate to have him as my Google summer internship host!
It was a great workshop with great speakers.
RSS 2020: The Conference Days
The next three days were the formal conference days. In general, the schedule was similar for each day. Each had live talks and two hours of live poster sessions of accepted papers, all happening over Zoom. RSS is still a relatively small robotics conference, with only 103 accepted papers in 2020, in contrast to ICRA and IROS which now have well over 1000 accepted papers each year. This meant that RSS was “single track,” so only one thing was formally happening at once.
After the opening talks to introduce us to virtual RSS, we had the first of the two-hour paper discussion sections. I stayed primarily in the Zoom room allocated to my paper at RSS 2020.
University of Washington Professor Byron Boots gave an “early career” talk in the afternoon, featuring online learning and regret analysis, which befits his publication list. Some of his work involves analyzing Model Predictive Control (MPC), and once again I felt relieved about my RSS paper, which used MPC. Working on that project has made it so much easier for me to understand MPC and related topics.
The second day began with a Diversity and Inclusion panel, featuring people such as Michigan Professor Chad Jenkins. I watched the discussion and thought it went well. We then had the usual two hours of paper discussions. Most Zoom rooms were almost empty, with the exception of the paper authors. Honestly, I like this, because it made it easy for me to talk with various paper authors.
The keynote talk by MIT Professor Josh Tenenbaum later that day was excellent. He’s done great work in areas that overlap with robotics, most notably computer vision and psychology, and I was thinking about how I could incorporate his findings into my research agenda.
The third day of the conference began with a discussion and a town hall. Many conferences have started these discussions, which I suspect is in large part to solicit feedback on how to make conferences more inclusive to the research community. I recall that a conference organizer mentioned that we have professional real-time captioning for all the major talks, and praised it. I agree! There was some Q & A at the end, and one thought-provoking comment came from an audience member who thought that hybrid conferences that combine virtual and in-person events would not work well. While the commenter made it clear that he/she wanted to see a hybrid event work, there is a huge risk in creating an inequity to favor people who are there in-person over those who are attending virtually. It will be interesting to see what happens with ICRA 2021, which is planned to be in Xi’an, China, next May. The ICRA 2021 website is already saying that the conference will be hybrid.
After this, we had the usual paper discussions, followed by Stanford Professor Jeannette Bohg’s excellent early career talk. The day concluded with the paper awards and the farewell talk. First, congratulations to Google for winning several awards! Second, the conference organizers said they could not provide any definitive information about where RSS would be held next year.
RSS 2020: Thoughts
I read through various blog posts before attending RSS, such as one from Berkeley Professor Ben Recht and one from the organizers of ICLR 2020, which was one of the first conferences in 2020 that was forced to go virtual, so I had a rough sense of what to expect from a virtual conference. As usual, though, there’s no substitute for going through the process in person (I’m not sure if that should be a pun or not). Here are some brief thoughts:
- The conference had some virtual rooms, which I think are called “gather” sessions, for informal chats. Unfortunately, almost every time I logged into these rooms, I was the only one there. Did people make heavy use of these? On a related note, there were a few slack channels for the workshops, but I think hardly anyone used them. Maybe Slack channels should be deprioritized for smaller virtual conferences?
- Since it looks like many conferences will be virtual or hybrid going forward, perhaps we should get rid of the requirement that at least one author of each accepted paper has to physically attend the conference. Given the COVID-19 situation, and also geopolitical issues pertaining to visas and immigration, it seems like people ought to have the option to avoid travel.
- Getting a smaller conference to be time-zone friendly is a huge challenge. With a larger one like ICLR, it’s possible to have the conference run 24/7 with something happening for each time zone, but I don’t know of a good solution for one the size of RSS.
- I didn’t have the ability to set aside my entire week for the conference, since I was still interning at Google while this was happening, though I suppose I could have asked for a few days off. This meant I worked more on research than I usually do during conferences. I’m not sure if that’s a good thing or a bad thing.
- While I didn’t ask questions during the talks, I think a virtual setting makes it easier for many of us to ask questions. In a physical conference, we might have to walk to a microphone in an auditorium of thousands of people.
- As mentioned earlier, I like the smaller Zoom sessions that replace physical poster sessions. It was far easier for me to engage in substantive conversations with other researchers. In contrast, when I was at NeurIPS 2019, I could barely talk to any author given the size and the crowded, elbow-to-elbow poster sessions.
- I thought it was easier to get an academic accommodation; I requested professional captioning. For a virtual conference, it isn’t necessary to pay for someone (e.g., a sign language interpreter) to physically travel, which can increase costs.
To conclude this blog post, I want to thank the RSS organizers. I know things aren’t quite ideal, but virtual RSS went well, and I hope to attend in 2021, whether in person or virtual.
On Anti-Racism
The last few months have taught us a lot about America. Our country is facing the twin crises of COVID-19 and racism. While the former is novel and the current crisis is in part (actually, largely) due to a lack of leadership by our top political officials, the latter is perhaps the oldest problem that stubbornly never disappears. In this post, I discuss, in order: policing (including one benign encounter with a police officer), anti-racism in academia and AI, and what I will try to do for my anti-racist education. I will discuss what I am reading, where I am donating to, and what I can commit to doing in the near future.
Policing. I was as appalled as many others from watching videos of police treatment of African-Americans in this country, especially with the George Floyd case, and I share the concerns many have over police conduct against Blacks. On the other hand, I also believe there has to be a police presence — or law enforcement more broadly — of some sort. The 1969 Murray-Hill riots in Canada, for example, where a strike by Montreal police lead to widespread lawless activity, demonstrates just how badly society depends on law enforcement, and makes me worry that the absence of police presence can lead to anarchy.
Growing up, I was told to be extra cautious around the police, and to make my hearing disability clear and upfront to any police officers to avoid misunderstandings. There have been tragic cases of deaf people being harmed and even killed by law enforcement officers who presumed a deaf person could hear and was engaging in indifference or disobedience of law enforcement commands. I know my situation is not the same as and is far milder than what many Blacks experience. While I am not white, people often think I am white by my physical appearance, so my racial composition has not been problematic.
In my life, I have been stopped by the police a grand total of zero times. Well, except for (arguably) one case where Berkeley was running a random “sobriety test” on a Friday night, and police officers were stopping every car on the street that led to my apartment. That night I wasn’t driving home from a party; I was working in the robotics lab until 9:00pm.
When it was my turn, my conversation with the police officer went like this:
Me: Hello. Nice to meet you. Just to let you know I’m deaf and may not fully understand everything you say. But I’m happy to answer any questions you have. I am curious about what is happening here.
Police officer [smiling]: Gotcha. This is a random test that we’re having to check all drivers here. In any case I don’t smell any alcohol on you, so you’re free to go.
That’s it! I have otherwise never spoken to a police officer in any driving-related context, and my few other interactions with police officers have similarly been under extraordinarily uneventful and non-threatening situations. When people such as United States Senator Tim Scott of South Carolina get stopped by the police at the Senate as he describes in this interview, then I wonder how our society can fix this.
That said, I also want to take a data-driven approach to let sober facts dictate my beliefs, rather than emotions or one-time events. Dramatic videos only show a small fraction of all police activity. Given the authority, trust, and power we give to police officers, however, the bar for their code-of-conduct should be high.
To summarize, I don’t think we should get rid of the police. I do believe we need to continue and improve training of police officers, the majority of whom do not have a college education, and to provide support (and better pay) to the good police officers while firing the bad ones. It may also be helpful if we can collectively reduce the need for police officers to deal with non-critical cases such as parking tickets and jaywalking so that they can prioritize the truly dangerous criminals. I can’t claim to be an expert on policing, so I will continue learning as much as I can about this area.
Anti-Racism in Academia and Artificial Intelligence. The Berkeley EECS department, like many similar ones in the country, is heavily dominated by Whites and Asians, and has very few Blacks, so discussion of race and racism (at least from my conversations) tend to involve the White/Asian dynamic with limited commentary about other groups.
The good news is that there’s been recent discussion about how to be anti-racist, with increased focus on Blacks. There was an email sent out by the chairs of the department which linked to statements by much of the faculty affirming their support for anti-racism. Several department-wide reading groups, email lists, and committees now exist for supporting anti-racism. A PhD student in the department, Devin Guillory, has a manuscript on combating anti-Blackness with a specific focus on the Artificial Intelligence community.
I think it’s important for the AI community to discuss the broader impacts of how our technologies can be used both for good and for bad, particularly when they can exacerbate existing disparities. One recent technology that is worth discussing is facial recognition. While I don’t do research in this area, my robotics research often uses technologies based on Deep Convolutional Neural Networks that form the bedrock for facial recognition.
Rarely is it easy to admit that one is wrong, but I think I was wrong about my initial stance on facial recognition. When I first learned about the capabilities of Convolutional Neural Networks from CS 280 at Berkeley and then the associated facial recognition literature, I dreamed of society deploying the technology to detect and catch criminals with surgical precision. (I don’t have an earlier blog post or other writing about this, so you’ll have to take my word on it.)
Since then, I’ve done almost a complete reversal and now think we should limit facial recognition research and technology, at least until we can come up with solutions that explicitly consider minority interests. Here’s why:
-
I share concerns over potential inaccuracies in the technology when it pertains to racial minorities. For example, a landmark 2018 paper by Joy Buolamwini and Timnit Gebru showed that facial recognition technologies (at least at the time of publication) were far more inaccurate on people with darker skin. While the technology may have gotten more accurate on people with darker skin since it was published, a recent news article about a wrongful arrest of a black man due to facial recognition makes me anxious.
-
I also worry about facial recognition being used to limit and control personal freedom. I see the extreme case of facial recognition technologies in China, where particularly in Xinjiang, they have an extensive surveillance system over the Uighur Muslims. While it’s challenging to make imperfect comparisons across different countries and governance systems, I hope that the United States does not reach this level of surveillance, and the situation there should serve as a warning sign for American residents to be wary of facial recognition systems in our own communities.
When the ACM made the following tweet a few months ago, I was heartened to see pushback by many members of the computer science community. I hope this causes the community to carefully consider the development of facial recognition technologies.
Left: a tweet the ACM sent out regarding facial recognition. (I believe this is
the tweet; it's hard to find because they have deleted it.) Right: the ACM's
apology.
Anti-Racism More Broadly. As mentioned earlier, as part of my broader anti-racism education, I am pursuing three separate activities which can be categorized as reading books, donating to organizations, and making commitments about my actions now and in the future.
First, in terms of books, I have been reading these in recent months:
- Evicted: Poverty and Profit in the American City by Matthew Desmond (published 2016)
- White Fragility: Why It’s So Hard for White People to Talk About Racism by Robin DiAngelo (published 2018)
- So You Want to Talk About Race? by Ijeoma Oluo (published 2018)
- Me and White Supremacy: Combat Racism, Change the World, and Become a Good Ancestor by Layla F. Saad (published 2020)
- Stamped from the Beginning: The Definitive History of Racist Ideas in America by Ibram X. Kendi (published 2016)
I finished the first four books above, and recommend all of them. I am currently working through Ibram X. Kendi’s book. I enjoy reading the books — not, of course, in the sense that racism is “enjoyable” but because I think these are well-written, well-argued books that teach me.
In addition, I also commit to increasing the number of books I read about Blacks or by Black authors. Given that I post my reading list online (see the blog archives), it should be easy to keep me accountable.
Second, I have learned more about, and have donated to, these organizations:
All relate to tech: the first for young Black women, the second for Black researchers in AI, the third for Black and Latinx in tech, the fourth for under-represented minorities more broadly, and the fifth for low-income youth. There are other loosely related organizations that I support and have donated to in the past, but I think the above are the most relevant for the current blog post context.
Third, Going forward, I will commit to anti-racism. I will not shy away from discussing this topic. I will actively help with recruitment and retainment of Blacks within my work environment. I also will avoid comments that show insensitivity in race-related contexts, including but not limited to: “playing the race card,” “I don’t see color,” “All Lives Matter,” “I am not White,” or “I have Black friends.” I also will not claim that my research is entirely disjoint from race. My robotics research is less directly race-related as compared to facial recognition research, but that is different from saying that it has nothing to do with race.
I will be careful to consider a variety of perspectives when forming my own opinions for related events. It may be the case that I believe something which most of my nearby colleagues disagree with. We don’t have to agree on everything, but I would like the academic community to avoid cases similar to how US Senator Dick Durbin smeared fellow US Senator Tim Scott (since apologized), and more generally to avoid treating Blacks as a monolithic group.
Concluding Remarks. While this blog post is coming to a close, the process of being an anti-racist will be a lifelong process. I am never going to claim perfection or that I have passed some “anti-racist threshold” and am therefore one of the “good guys.” This is a lifelong process. I will make many mistakes along the way. I may discuss more about this in some future blog posts. In the meantime, let me know if you have comments or suggestions.
Regarding the ICE International Student Ban
I was going to email this letter to elected federal politicians, but fortunately, the U.S. Immigration and Customs Enforcement (ICE) seems to have repealed their misguided policy about forcing international students to take classes in-person. Nonetheless, here’s the letter, and in case a similar policy somehow re-emerges, I will start sending this message. This particular letter is addressed to U.S. Senator Dianne Feinstein given my California residency, her particular Senate Committee assignments, and because of the six offices I called last week, only hers had an actual human on the line for me to address my concerns. The letter is based on this template. Unfortunately I’m not sure who wrote it.
Dear Senator Dianne Feinstein,
My name is Daniel Seita. I currently reside in the San Francisco Bay Area. I am registered voter and thank you for your many years of service in the United States Senate representing California.
I am emailing to insist that you stop the recent student ban.
On July 6, 2020, the United States Immigration and Customs Enforcement announced that they will be modifying their Student and Exchange Visitor Program (SEVP) impacting F-1 and M-1 international students. Under the modified SEVP, F-1 and M-1 students with valid student visas would be forced to leave the United States if their college or university was not offering in-person classes.
International students pay the highest tuition to colleges and universities and shifting to an online-only syllabus does not reduce and shrink the economic burden of the high costs. Forcing international students to pay these high costs while also making them leave the country is unfair on many levels. Furthermore, the funds that international students bring in subsidize domestic students.
With the COVID-19 pandemic still spiking, the opening of in-person classes is unsafe and unnecessary. These new SEVP modifications force universities to choose between opening in-person classes even if it is not safe or lose their international student body who account for billions of dollars to the US economy.
International students have built lives for themselves while at school, and it is cruel to take it away. Students have signed leases and agreements, have possessions and belongings, and have loved ones and friends that they are being ripped apart from because of the unpredictable consequences of COVID-19. Many domestic students are unable to take classes in-person and it is an unfair expectation that international students who are here, legally, for school must be able to enroll in on-campus courses in order to stay in the country. With the fall semester rapidly approaching there is little time for students to transfer schools or find somewhere else to live.
The US has many of the best universities in the world, and a large part of that is due to immigration and international students. Our country has an unparalleled ability to recruit the best and brightest from all over the world, many of whom choose to stay in the country after their education. Without the contributions of international students and faculty, the quality of our education, research, and innovation would plummet.
I am a computer science PhD student at the University of California, Berkeley, and I work in artificial intelligence and robotics. I would guess that one-third of the people who I regularly collaborate with in my research are internationals. They have taught me so much about my field and have helped to raise my quality of research. Severing these collaborations will not only disrupt our research, but damage America’s global reputation.
I hope you consider these concerns and convince ICE to overturn the student ban.
Daniel Seita
Thanks to every international student and collaborator who teaches and inspires me.
When Deep Models for Visual Foresight Don't Need to be Deep
The virtual Robotics: Science and Systems (RSS) conference will happen in about a week, and I will be presenting a paper there. This is going to be my first time at RSS, and I was hoping to go to Oregon State University and meet other researchers in person, but alas, given the rapid disintegration of America as it pertains to COVID-19, a virtual meeting makes 100 percent sense. For RSS 2020, I’ll be presenting our paper VisuoSpatial Foresight for Multi-Step, Multi-Task Fabric Manipulation, co-authored with Master’s (and soon to be PhD!) student Ryan Hoque. This is based on a technique called visual foresight, and in this blog post, I’d like to briefly touch upon the technique, and then discuss a little more about our RSS 2020 paper, along with another surprising paper which shows that perhaps we need to rethink our deep models.
First, to make sure we’re on common ground here, what do people mean when we say the words “Visual Foresight”? This refers to the technique described in an ICRA 2017 paper by Chelsea Finn and Sergey Levine, which was later expanded upon in a longer journal paper with lead authors Chelsea Finn and Frederik Ebert. The authors are (or were) at UC Berkeley, my home institution, which is one reason why I learned about the technique.
Visual Foresight is typically used in a model-based RL framework. I personally categorize model-based methods into whether the models predict images or whether they predict some latent variables (assuming, of course, that the model itself needs to be learned). Visual Foresight applies to the former case for predicting images. In practice, given the difficult nature of image prediction, this is often done by predicting translations or deltas between images. For the second case of latent variable prediction, I refer you to the impressive PlaNet research from Google.
For another perspective on model-based methods, the following text is included in OpenAI’s “Spinning Up” guide for deep reinforcement learning:
Algorithms which use a model are called model-based methods, and those that don’t are called model-free. While model-free methods forego the potential gains in sample efficiency from using a model, they tend to be easier to implement and tune. As of the time of writing this introduction (September 2018), model-free methods are more popular and have been more extensively developed and tested than model-based methods.
and later:
Unlike model-free RL, there aren’t a small number of easy-to-define clusters of methods for model-based RL: there are many orthogonal ways of using models. We’ll give a few examples, but the list is far from exhaustive. In each case, the model may either be given or learned.
I am writing this in July 2020, and I believe that since September 2018, model-based methods have made enormous strides, to the point where I’m thinking that 2018-2020 might be known as the “model-based reinforcement learning” era. Also, to comment on a point from OpenAI’s text, while model-free methods might be easier to implement in theory, I argue that model-based methods can be far easier to debug, because we can check the predictions of the learned model. In fact, that’s one of the reasons why we took the model-based RL route in our RSS paper.
Anyway, in our RSS paper, we focused on the problem of deformable fabric manipulation. In particular, given a goal image of a fabric in any configuration, can we train a pick-and-place action policy that will manipulate the fabric from an arbitrary starting configuration to the goal configuration? For Visual Foresight, we trained a deep recurrent neural network model that could predict full 56x56 resolution images of fabric. We predicted depth images in addition to color images, making the model “VisuoSpatial.” Specifically, we used Stochastic Variational Video Prediction (SV2P) as our model. The wording “Stochastic Variational” means the model samples a latent variable before generating images, and the stochastic nature of that variable means the model is not deterministic. This is an important design aspect; see the SV2P paper for further details. But, as you might imagine, this is a very deep, recurrent, and complex model. Is all this complexity needed?
Perhaps not! In a paper at the Workshop on Algorithmic Foundations of Robotics (WAFR) this year, Terry Suh and Russ Tedrake of MIT show that, in fact, linear models can be effective in Visual Foresight.
Wait, really?
Let’s dive into that work in more detail, and see how it contrasts to our paper. I believe there are great insights to be gained from reading the WAFR paper.
In this paper, Terry Suh and Russ Tedrake focus on the task of pushing small objects into a target zone, such as pushing diced onions or carrots not unlike how a human chef might need do so. Their goal is to train a pushing policy that can learn and act based on greyscale images. They make a similar argument that we do in our RSS 2020 paper about the difficulty of knowing the “underlying physical state.” For us, “state” means vertices of cloth. For them, “state” means knowing all poses of objects. Since that’s hard with all these small objects piled upon each other, learning from images is likely easier.
The actions are 4D vectors $\mathbf{u}$ which have (a) the 2D starting coordinates, (b) the scalar push orientation, and (c) the scalar push length. They use Pymunk for simulation, which I’ve never heard of before. That’s odd, why not use PyBullet, which might be more standardized for robotics? I have explicitly been able to simulate this kind of environment in PyBullet.
That having been said, let’s consider first how (a) they determine actions, and (b) their visual foresight video prediction model.
Section 2.2 describes how they pick actions (for all methods they benchmark). Unlike us, they do not use the Cross Entropy Method (CEM) — there is no action sampling plus distribution refitting as happens in the CEM. The reason is that they can define a Lyapunov function which accurately characterizes performance on their task, and furthermore, they can minimize for it to get a desired action. The Lyapunov function $V$ is defined as:
\[V(\mathcal{X}) = \frac{1}{|\mathcal{X}|} \sum_{p_i \in \mathcal{X}} \min_{p_j \in \mathcal{S}_d} \|p_i - p_j\|_{p}\]where \(\mathcal{X} = \{p_i\}\) is the set of all 2D particle positions, and $\mathcal{S}_d$ is the desired target set for the particles. The notation \(\| \cdot \|_p\) simply refers to a distance metric in the $p$-norm.
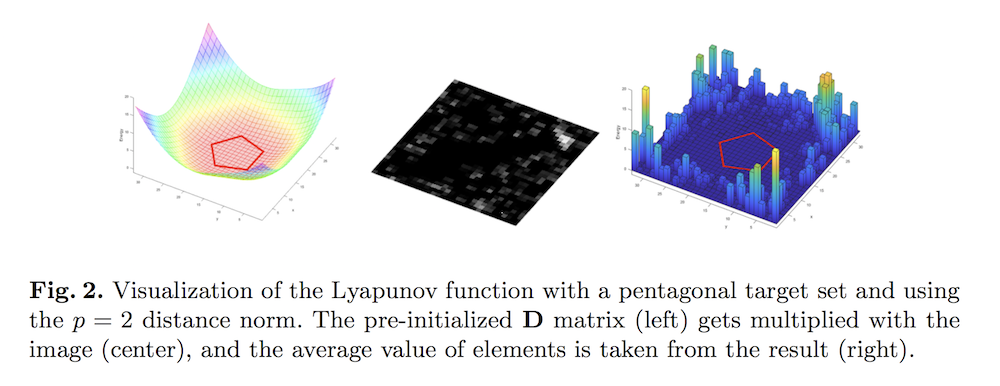
The figure above is from the paper, who visualizes the Lyapunov function. It is interpreted as a distance between a discrete set of points and a continuous target set. There’s a pentagon at the center indicating the target set. In their instantiation of the Lyapunov function, if all non-zero pixels (nonzero means carrots, due to height thresholding) in the image of the scene coincide with the pentagon, then the element-wise product of the two images is 0 everywhere, and summing it all will result in 0.
The paper makes the assumption that:
for every image that is not in the target set, we can always find a small particle to push towards the target set and decrease the value of the Lyapunov function.
I agree. While there are cases when pushing particles inwards might result in higher values (i.e., worse performance) due to pushing particles inside the zone to be outside of it, I think it is always possible to find some movement that gets a greater number of particles in the target. If anyone has a counter-example, feel free to share. This assumption may be more true for convex target sets, but I don’t think the authors make that assumption since they test on targets shaped “M”, “I”, and “T” later.
Overall, the controller appears to be accurate enough so that the prediction model performance is the main bottleneck. So which is better: deep or switched-linear? Let’s now turn to that, along with the “visual foresight” aspect of the paper.
Their linear model is “switched-linear”. This is an image-to-image mapping based on a linear map characterized by
\[y_{k+1} = \mathbf{A}_i y_k\]for \(i \in \{1, 2, \ldots, |\mathcal{U}|\}\), where $\mathcal{U}$ is the discretized action space and $y_k \in \mathbb{R}^{N^2}$ represents the flattened $N \times N$ image at time $k$. Furthermore, $\mathbf{A}_i \in \mathbb{R}^{N^2 \times N^2}$. This is a huge matrix, and there are as many of these matrices as there are actions! This appears to require a lot of storage.
My first question after reading this was: when they train the model using pairs of current and successor images $(y_{k}, y_{k+1})$, is it possible to train all the $\mathbf{A}_i$ matrices?
Or are we restricted to only the matrix corresponding to the action that was chosen to transform $y_k$ into $y_{k+1}$? If this were true, that is a serious limitation. I breathed a sigh of relief when the authors clarified that they can reuse training samples, up to the push length. They discretized the push length by 5, and then got 1000 data points (image pairs) for each of those, for 5000 total. Then they find the optimum matrices (and actions, since matrices are actions here) by the ordinary least squares
Their deep models are referred to as DVF-Affine and DVF-Original. The affine one is designed for fairer comparison with the linear model, so it’s an image-to-image prediction model, with five separate neural networks for each of the discretized push lengths. DVF-Original takes the action as an additional input, while DVF-Affine does not.
Surprisingly, their results show that their linear model has lower prediction error on a held-out set of 1000 test images. This should directly translate to better performance on the actual task, since more accurate models mean the Lyapunov function will be driven down to 0 faster. Indeed, their results confirm the prediction error results, in the sense that linear models are the best or among the best in terms of task performance.
Now we get to the big question: why are linear models better than deeper ones for these experiments? I thought of these while reading the paper:
-
The carrots are very tiny in the images, so perhaps the 32x32 resolution makes it hard to accurately capture the fine-grained nature of the carrots.
-
The images are grayscale and small, which means linear models may work better as opposed to if the images were larger. At some point the “$N$” in their paper will grow too large to be used with linear models. (Of course with larger images, the problem of video prediction becomes exponentially harder. Heck, we only used 56x56 in our paper, and the SV2P paper used 64x64 images.)
-
Perhaps there’s just not enough data? It looks like the experiments use 23,000 data points to train DVF-Original, and 5,000 data points for DVF-Affine? For a point of comparison, we used about 105,000 images of cloth.
-
Furthermore, the neural networks are trained directly on the pixels in an end-to-end manner using the Frobenius norm loss (basically mean square error on pixels). In contrast, models such as SV2P are trained using Variational AutoEncoder style losses, which may be more powerful. In addition, the SV2P paper explicitly stated that they performed a multi-stage training procedure since a single end-to-end procedure tends to converge to less than ideal solutions.
-
Perhaps the problem has a linear nature to it? While reading the paper, I was reminded of the thought-provoking NeurIPS 2018 paper on how simple random search on linear models is competitive for reinforcement learning on MuJoCo environments.
-
Judging from Figure 11, the performance of the better neural network model seems almost as good as the linear one. Maybe the task is too easy?
Eventually, the authors discuss their explanation: they believe that their problem has natural linearity in it. In other words, there is inductive bias in the problem. Inductive bias in machine learning is a fancy way of saying that different machine learning models make different assumptions about the prediction problem.
Overall, the WAFR 2020 paper is effective and thought-provoking. It makes me wonder if we should have at least tried a linear model that could perhaps predict edges or corners of cloth while trying to abstract away other details. I doubt it would work for complex fabric manipulation tasks, but perhaps for simpler ones. Hopefully someone will explore this in the future!
Here are the papers discussed in this post, ordered by publication date. I focused mostly on the WAFR 2020 paper, and the others are: my paper with Ryan for RSS, the two main Visual Foresight papers, and the S2VP paper that uses the video prediction model we’ve used for our paper.
-
Chelsea Finn and Sergey Levine. Deep Visual Foresight for Planning Robot Motion, ICRA 2017.
-
Frederik Ebert, Chelsea Finn, Sudeep Dasari, Annie Xie, Alex Lee, Sergey Levine. Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control , arXiv 2018.
-
Mohammad Babaeizadeh, Chelsea Finn, Dumitru Erhan, Roy H. Campbell, Sergey Levine. Stochastic Variational Video Prediction, ICLR 2018.
-
Ryan Hoque, Daniel Seita, Ashwin Balakrishna, Aditya Ganapathi, Ajay Tanwani, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg. VisuoSpatial Foresight for Multi-Step, Multi-Task Fabric Manipulation, RSS 2020.
-
H.J. Terry Suh and Russ Tedrake. The Surprising Effectiveness of Linear Models for Visual Foresight in Object Pile Manipulation, WAFR 2020.