My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
Batch Constrained Deep Reinforcement Learning
An interesting paper that I am reading is Off-Policy Deep Reinforcement Learning without Exploration. You can find the latest version on arXiv, where it clearly appears to be under review for ICML 2019. An earlier version was under review at ICLR 2019 under the earlier title Where Off-Policy Deep Reinforcement Learning Fails. I like the research contribution of the paper, as it falls in line with recent work on how to make deep reinforcement learning slightly more practical. In this case, “practical” refers to how we have a batch of data, from perhaps a simulator or an expert, and we want to train an agent to learn from it without exploration, which would do wonders for safety and sample efficiency.
As is clear from the abstract, the paper introduces the batch-constrained RL algorithm:
We introduce a novel class of off-policy algorithms, batch-constrained reinforcement learning, which restricts the action space in order to force the agent towards behaving close to on-policy with respect to a subset of the given data.
This is clear. We want the set of states the agent experiences to be similar to the set of states from the batch, which might be from an expert (for example). This reminded me of the DART paper (expanded in a BAIR Blog post) that the AUTOLAB developed:
- DART is about applying noise to expert states, so that behavior cloning can see a “wider” distribution of states. This was an imitation learning paper, but the general theme of increasing the variety of states seen has appeared in past reinforcement learning research.
- This paper, though, is about restricting the actions so that the states the agent sees match those of the expert’s by virtue of taking similar actions.
Many of the most successful modern (i.e., “deep”) off-policy algorithms use some variant of experience replay, but the authors claim that this only works when the data in the buffer is correlated with the data induced by the current agent’s policy. This does not work if there is what the authors define as extrapolation error, which is when there is a mismatch between the two datasets. Yes, I agree. Though experience replay is actually designed to break correlation among samples, the most recent information is put into the buffer, bumping older stuff out. By definition, that means some of the data in the experience replay is correlated with the agent’s policy.
But more generally, we might have a batch of data where nothing came from the current agent’s policy. The more I think about it, the more an action restriction makes sense. With function approximation, unseen state-action pairs $(s,a)$ might be more or less attractive than seen pairs. But, aren’t there more ways to be bad than there are to be good? That is, it’s easy to get terrible reward in environments, but harder to get the highest reward, which one can verify by mathematically assigning the probabilities of each random sequence of actions. This paper is about restricting the actions so that we keep funneling the agent towards the high-quality states in the batch.
To be clear, here’s what “batch reinforcement learning” means, and its advantages:
Batch reinforcement learning, the task of learning from a fixed dataset without further interactions with the environment, is a crucial requirement for scaling reinforcement learning to tasks where the data collection procedure is costly, risky, or time-consuming.
You can also view this through the lens of imitation learning, because the simplest form, behavior cloning, does not require environment interaction.1 Furthermore, one of the fundamental aspects of reinforcement learning is precisely environment interaction! Indeed, this paper benchmarks with behavior cloning, and freely says that “Our algorithm offers a unified view on imitation and off-policy learning.”2
Let’s move on to the technical and algorithmic contribution, because I’m rambling too much. Their first foray is to try and redefine the Bellman operator in finite, discrete MDPs in the context of reducing extrapolation error so that the induced policy will visit the state-action pairs that more closely correspond with the distribution of state-action pairs from the batch.
A summary of the paper’s theory is that batch-constrained learning still converges to an optimal policy for deterministic MDPs. Much of the theory involves redefining or inducing a new MDP based on the batch, and then deferring to standard Q-learning theory. I wish I had time to go through some of those older classical papers, such as this one.
For example, the paper claims that normal Q-learning on the batch of data will result in an optimal value function for an alternative MDP, $M_{\mathcal{B}}$, based on the batch $\mathcal{B}$. A related and important definition is the tabular extraploation error $\epsilon_{\rm MDP}$, defined as discrepancy between the value function computed with the batch versus the value function computed with the true MDP $M$:
\[\epsilon_{\rm MDP}(s,a) = Q^\pi(s,a) - Q_{\mathcal{B}}^\pi(s,a)\]This can be computed recursively using a Bellman-like equation (see the paper for details), but it’s easier to write as:
\[\epsilon_{\rm MDP}^\pi = \sum_{s} \mu_\pi(s) \sum_a \pi(a|s) |\epsilon_{\rm MDP}(s,a)|\]By using the above, they are able to derive a new algorithm: Batch-Constrained Q-learning (BCQL) which restricts the possible actions to be in the batch:
\[Q(s,a) \leftarrow (1 - \alpha ) Q(s,a) + \alpha\left( r + \gamma \left\{ \max_{a' \;{\rm s.t.}\; (s',a') \in \mathcal{B}} Q(s',a') \right\} \right)\]Next, let’s introduce their practical algorithm for high-dimensional, continuous control: Batch-Constrained deep Q-learning (BCQ). It utilizes four parameterized networks.
-
A Generative model $G_\omega(s)$ which, given the state as input, produces an action. Using a generative model this way assumes we pick actions using:
\[\operatorname*{argmax}_{a} \;\; P_{\mathcal{B}}^G(a|s)\]or in other words, the most likely action given the state, with respect to the data in the batch. This is difficult to model in high dimensional continuous control environments, so they approximate it with a variational autoencoder. This is trained along with the policy parameters during each for loop iteration.
-
A Perturbation model $\xi_\phi(s,a,\Phi)$ which aims to “optimally perturb” the actions, so that they don’t need to sample too much from $G_\omega(s)$. The perturbation applies noise in $[-\Phi,\Phi]$. It is updated via a deterministic policy gradient rule:
\[\phi \leftarrow \operatorname*{argmax}_\phi \;\; \sum_{(s,a) \in \mathcal{B}} Q_\theta\Big( s, a+\xi_\phi(s,a,\Phi)\Big)\]The above is a maximization problem over a sum of Q-function terms. The Q-function is differentiable as we parameterize it with a deep neural network, and stochastic gradient descent methods will work with stochastic inputs. I wonder, is the perturbation model overkill? Is it possible to do a cross entropy method, like what two of these papers do for robotic grasping?
-
Two Q-networks $Q_{\theta_1}(s,a)$ and $Q_{\theta_2}(s,a)$, to help push their policy to select actions that lead to “more certain data.” This is based on their ICML paper last year, which proposed the (now popular!) Twin-Delayed DDPG (TD3) algorithm. OpenAI’s SpinningUp has a helpful overview of TD3.
All networks other than the generative model also consist of target networks, following standard DDPG practices.
All together, their algorithm uses this policy:
\[\pi(s) = \operatorname*{argmax}_{a_i+\xi_\phi(s,a_i,\Phi)} \;\; Q_\theta\Big(s, a_i+\xi_\phi(s,a_i,\Phi)\Big) \quad \quad \{a_i \sim G_\omega(s) \}_{i=1}^n\]To be clear, they approximate this maximization by sampling $n$ actions each time step, and picking the best one. The perturbation model, as stated earlier, increases the diversity of the sampled actions. Once again, it would be nice to confirm that this is necessary, such as via an experiment that shows the VAE collapses to a mode. (I don’t see justification in the paper or the appendix.)
There is a useful interpretation of how this algorithm is a continuum between behavior cloning (if $n=1$ and $\Phi=0$) and Q-learning ($n\to \infty$ and $\Phi \to a_{\rm max}-a_{\rm min}$).
All right, that was their theory and algorithm — now let’s discuss the experiments. They test with DDPG under several different conditions. They assume that there is a “behavioral DDPG” agent which generates the batch of data, for which an “off-policy DDPG” agent learns from, without exploration. Their goal is to improve the learning of the “off-policy DDPG.” (Don’t get confused with the actor-critic framework of normal DDPG … just think of the behavioral DDPG as the thing that generates the batch in “batch-constrained RL.”)
-
Final Buffer. They train the behavioral DDPG agent from scratch for 1 million steps, adding more noise than usual for extra exploration. Then all of its experience is pooled inside an experience replay. That’s the “batch”. Then, they use it to train the off-policy DDPG agent. That off-policy agent does not interact with the environment — it just draws samples from the buffer. Note that this will result in widespread state coverage, including potentially the early states when the behavioral agent was performing poorly.
-
Concurrent. This time, as the behavioral DDPG agent learns, the off-policy one learns as well, using data from the behavioral agent. Moreover, the original behavioral DDPG agent is also learning from the same data, so both agents learn from identical datsets. To be clear: this means the agents have almost identical training settings. The only differences I can think of are: (a) noise in initial parameters and (b) noise in minibatch sampling. Is that it?
-
Imitation. After training the behavioral DDPG agent, they run it for 1 million steps. Those experiences are added to the buffer, from which the off-policy DDPG agent learns. Thus, this is basically the imitation learning setting.
-
Imperfect Demonstrations. This is the same as the “imitation” case, except some noise is added to the data, through Gaussian noise on the states and randomness in action selection. Thus, it’s like adding more coverage to an expert data.
The experiments use … MuJoCo. Argh, we’re still using it as a benchmark. They test with HalfCheetah-v1, Hopper-v1, and Walker2d-v1. Ideally there would be more, at least in the main part of the paper. The Appendix has some limited Pendulum-v0 and Reacher-v1 results. I wonder if they tried on Humanoid-v1.
They actually performed some initial experiments before presenting the theory, which justifies the need to correct for extrapolation error. The most surprising fact there was that the off-policy DDPG agent failed to match the behavioral agent even in the concurrent learning paradigm. That’s surprising!
This was what motivated their Batch-Constrained deep Q-learning (BCQ) algorithm, discussed above.
As for their results, I am a little confused after reading Figure 2. They say that:
Only BCQ matches or outperforms the performance of the behavioral policy in all tasks.
Being color-blind, the BCQ and VAE-BC colors look indistinguishable to me. (And the same goes for the DQN and DDPG baselines, which look like they are orange and orange, respectively.) I wish there was better color contrast, perhaps with light purple and dark blue for the former, and yellow and red for the latter. Oh well. I assume that their BCQ curve is the highest one on the rewards plot … but this means it’s not that much better than the baselines on Hopper-v1 except for the imperfect demonstrations task. Furthermore, the shaded area is only half of a standard deviation, rather than one. Finally, in the imitation task, simple behavior cloning was better. So, it’s hard to tell if these are truly statistically significant results.
While I wish the results were more convincing, I still buy the rationale of their algorithm. I believe it is a valuable contribution to the research community.
-
More advanced forms of imitation learning might require substantial environment interaction, such as Generative Adversarial Imitation Learning. (My blog post about that paper is here.) ↩
-
One of the ICLR reviewers brought up that this is more of an imitation learning algorithm than it is a reinforcement learning one … ↩
Deep Learning and Importance Sampling Review
This semester, I am a Graduate Student Instructor for Berkeley’s Deep Learning class, now numbered CS 182/282A. I was last a GSI in fall 2016 for the same course, so I hope my teaching skills are not rusty. At least I am a GSI from the start, and not an “emergency appointment” like I was in fall 2016. I view my goal as helping Professor Canny stuff as much Deep Learning knowledge into the students as possible so that they can use the technology to be confident, go forth, and change the world!
All right, that was cheesy, and admittedly there is a bit too much hype. Nonetheless, Deep Learning has been a critical tool in a variety of my past and current research projects, so my investment in learning the technology over the last few years has paid off. I have read nearly the entire Deep Learning textbook, but for good measure, I want to officially finish digesting everything from the book. Thus, (most of) my next few blog posts will be technical, math-oriented posts that chronicle my final journey through the book. In addition, I will bring up related subjects that aren’t explicitly covered in the book, including possibly some research paper summaries.
Let’s start with a review of Chapter 17. It’s about Monte Carlo sampling, the general idea of using samples to approximate some value of interest. This is an extremely important paradigm, because in many cases sampling is the best (or even only) option we have. A common way that sampling arises in Deep Learning is when we use minibatches to approximate a full-data gradient. And even for that, the full data gradient is really one giant minibatch, as Goodfellow nicely pointed out on Quora.
More formally, assume we have some discrete, vector-valued random variable $\bf{x}$ and we want the following expectation:
\[s = \sum_{x} p(x)f(x) = \mathbb{E}_p[f(\bf{x})]\]where $x$ indicates the possible values (or “instantiations” or “realizations” or … you get the idea) of random variable $\bf{x}$. The expectation $\mathbb{E}$ is taken “under the distribution $p$” in my notation, where $p$ must clearly satisfy the definition of being a (discrete) probability distribution. This just means that $\bf{x}$ is sampled based on $p$.
This formulation is broad, and I like thinking in terms of examples. Let’s turn to reinforcement learning. The goal is to find some parameter $\theta^* \in \Theta$ that maximizes the objective function
\[J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta(\tau)}[R(\tau)]\]where $\tau$ is a trajectory induced by the agent’s policy $\pi_\theta$; that probability is $\pi_\theta(\tau) = p(s_1,a_1,\ldots,s_T,a_T)$, and $R(\tau) = \sum_{t=1}^T R(s_t,a_t)$. Here, the objective plays the role of $\mathbb{E}_p[f(\bf{x})]$ from earlier with the trajectory $\tau$ as the vector-valued random variable.
But how would we exactly compute $J(\theta)$? The process would require us to explicitly enumerate all possible trajectories that could possibly arise from the environment emulator, and then weigh them all accordingly by their (log) probabilities, and compute the expectation from that. The number of trajectories is super-exponential, and this computation would be needed for every gradient update we need to perform on $\theta$, since the distribution of trajectories directly depends on $\pi_\theta(\tau)$.
You can see why sampling is critical for us to make any headway.
(For background on this material, please consult my older post on policy gradients, and an even older post on the basics of Markov Decision Processes.)
The solution is to take a small set of samples \(\{x^{(1)}, \ldots, x^{(n)}\}\) from the distribution of interest, to obtain our estimator
\[\hat{s}_n = \frac{1}{n} \sum_{i=1}^n f(x^{(i)})\]which is unbiased:
\[\mathbb{E}[\hat{s}_n] = \frac{1}{n}\sum_{i=1}^n \mathbb{E}[x^{(i)}] = \frac{1}{n}\sum_{i=1}^ns = s\]and converges almost surely to the expected value, so long as several mild assumptions are met regarding the samples.
Now consider importance sampling. As the book nicely points out, when using $p(x)f(x)$ to compute the expectation, the decomposition does not have to be uniquely set at $p(x)$ and $f(x)$. Why? We can introduce a third function $q$:
\[p(x)f(x) = q(x)\frac{p(x)f(x)}{q(x)}\]and we can sample from $q$ and average $\frac{pf}{q}$ and get our importance sampling estimator:
\[\hat{s}_p = \frac{1}{n} \sum_{i=1,\bf{x}^{(i)}\sim p}^n f(x^{(i)}) \quad \Longrightarrow \quad \hat{s}_q = \frac{1}{n} \sum_{i=1,\bf{x}^{(i)}\sim q}^n \frac{p(x^{(i)})f(x^{(i)})}{q(x^{(i)})}\]which was sampled from $q$. (The $\hat{s}_p$ is the same as $\hat{s}_n$ from earlier.) In importance sampling lingo, $q$ is often called the proposal distribution.
Think about what just happened. We are still computing the same quantity or sample estimator, and under expectation we still get $\mathbb{E}_q[\hat{s}_q] = s$. But we used a different distribution to get our actual samples. The whole $\bf{x}^{(i)}\sim p$ or $\bf{x}^{(i)}\sim q$ notation is used to control the set of samples that we get for approximating the expectation.
We employ this technique primarily to (a) sample from “more interesting regions” and (b) to reduce variance. For (a), this is often motivated by referring to some setup as follows:
We want to use Monte Carlo to compute $\mu = \mathbb{E}[X]$. There is an event $E$ such that $P(E)$ is small but $X$ is small outside of $E$. When we run the usual Monte Carlo algorithm the vast majority of our samples of $X$ will be outside $E$. But outside of $E$, $X$ is close to zero. Only rarely will we get a sample in $E$ where $X$ is not small.
where I’ve quoted this reference. I like this intuition – we need to find the more interesting regions via “overweighting” the sampling distribution there, and then we adjust the probability accordingly for our actual Monte Carlo estimate.
For (b), given two unbiased estimators, all other things being equal, the better one is the one with lower variance. The variance of $\hat{s}_q$ is
\[{\rm Var}(\hat{s}_q) = \frac{1}{n}{\rm Var} \left(\frac{p(\bf{x}) f(\bf{x})}{q(\bf{x})}\right)\]The optimal choice inducing minimum variance is $q^*(x) \propto p(x)|f(x)|$ but this is not usually attained in practice, so in some sense the task of importance sampling is to find a good sampling distribution $q$. For example, one heuristic that I’ve seen is to pick a $q$ that has “fatter tails”, so that we avoid cases where $q(x) \ll p(x)|f(x)|$, which causes the variance of $\frac{p(x)f(x)}{q(x)}$ to explode. (I’m using absolute values around $f(x)$ since $p(x) \ge 0$.) Though, since we are sampling from $q$, normally the case where $q(x)$ is very small shouldn’t happen, but anything can happen in high dimensions.
In a subsequent post, I will discuss importance sampling in the context of some deep learning applications.
I Will Make a Serious Run for Political Office by January 14, 2044
I have an official announcement. I am giving myself a 25-year deadline for making a serious run for political office. That means I must begin a major political campaign no later than January 14, 2044.
Obviously, I can’t make any guarantees about what the world will be like then. We know there are existential threats about which I worry. My health might suddenly take a nosedive due to an injury or if I somehow quit my addiction to salads and berries. But for the sake of this exercise, let’s assume away these (hopefully unlikely) cases.
People are inspired to run for political office for a variety of reasons. I have repeatedly been thinking about doing so, perhaps (as amazing as it sounds) even moreso than I think about existential threats. The tipping point for me making this declaration is our ridiculous government shutdown, now the longest in history.
This shutdown is unnecessary, counterproductive, and is weakening the United States of America. As many as 800,000 federal workers are furloughed or being forced to work without pay. On a more personal note, government cuts disrupt American science, a worrying sign given how China is investing vast sums of money in Artificial Intelligence and other sciences.
I do not know which offices I will target. It could be national or state-wide. Certain environments are far more challenging for political newcomers, such as those with powerful incumbents. But if I end up getting lucky, such as drawing a white supremacist like Steve King as my opponent … well, I’m sure I could position myself to win the respect of the relevant group of voters.
I also cannot state with certainty regarding my future political party affiliation. I am a terrible fit for the modern-day GOP, and an awkward one for the current Democratic party. But, a lot can change in 25 years.
To avoid distracting myself from more pressing circumstances, I will not discuss this in future blog posts. My primary focus is on getting more research done; I currently have about 20 drafts of technical posts to plow through in the next few months.
But stay tuned for what the long-term future may hold.
What Keeps Me Up at Night
For most of my life, I have had difficulty sleeping, because my mind is constantly whirring about some topic, and I cannot shut it down. I ponder about many things. In recent months, what’s been keeping me up at night are existential threats to humanity. Two classic categories are nuclear warfare and climate change. A more recent one is artificial intelligence.
The threat of civilization-ending nuclear warfare has been on the minds of many thinkers since the days of World War II.
There are nine countries with nuclear weapons: the United States, Russia, United Kingdom, France, China, India, Pakistan, Israel, and North Korea.
The United States and Russia have, by far, the largest nuclear weapons stockpiles. The Israeli government deliberately remains ambiguous about its nuclear arsenal. Iran is close to obtaining nuclear weapons, and it is essential that this does not happen.
I am not afraid of Putin ordering nuclear attacks. I have consistently stated that Russia (essentially, that means Putin) is America’s biggest geopolitical foe. This is not the same as saying that they are the biggest existential threat to humanity. Putin may be an dictator who I would never want to live under, but he is not suicidal.
North Korea is a different matter. I have little faith in Kim Jong Un’s mental acuity. Unfortunately, his regime still shows no signs of collapse. America must work with China and persuade them that it is in the interest of both countries for China to end their support of the Kim regime.
What about terrorist groups? While white supremacists have, I think, killed more Americans in recent years than radical Islamists, I don’t think white supremacist groups are actively trying to obtain nuclear weapons more as they want a racially pure society to live in, which by necessity requires some land usable and fallout-free.
But Islamic State, and other cult-like terrorist groups, could launch suicide attacks by stealing nuclear weapons. Terrorist groups lack homegrown expertise to build and launch such weapons, but they may purchase, steal, bribe, or extort. It is imperative that our nuclear technicians and security guards are well-trained, appropriately compensated, and have no Edward Snowdens hidden among them. It would also be prudent to assist countries such as Pakistan so that they have stronger defenses of their nuclear weapons.
Despite all the things that could go wrong, we are still alive today with no nuclear warfare since World War II. I hope that cool heads continue to prevail among those in possession of nuclear weapons.
A good overview of the preceding issues can be found in Charles D. Ferguson’s book. There is also a nice op-ed by elder statesmen George Shultz, Henry Kissinger, William Perry, and Sam Nunn on a world without nuclear weapons.
Climate change is a second major existential threat.
The good news is that the worst-case predictions from our scientists (and, ahem, Al Gore) have not materialized. We are still alive today, and the climate, at least from my personal experience — which cannot be used as evidence against climate change since it’s one data point — is not notably different from years past. The increasing use of natural gas has substantially slowed down the rate of carbon emissions. Businesses are aiming to be more energy-efficient. Scientists continue to track worldwide temperatures and to make more accurate climate predictions aided by advanced computing hardware.
The bad news is that carbon emissions will continue to grow. As countries develop, they naturally require more energy for the higher-status symbols of civilization (more cars, more air travel, and so on). Their citizens will also want more meat, causing more methane emissions and further strains on our environment.
Moreover, the recent Artificial Intelligence and Blockchain developments are computationally-heavy, due to Deep Learning and mining (respectively). Artificial Intelligence researchers and miners therefore have a responsibility to be frugal about their energy usage.
It would be ideal if the United States could take the lead in fighting climate change in a sensible way without total economic shutdown, such as by applying the carbon tax plan proposed by former Secretary of State George Shultz and policy entrepreneur Ted Halstead. Unfortunately, we lack the willpower to do so, and the Republican party in recent years has placed lower priorities on climate change, with their top politician even once Tweeting the absurd and patently false claim that global warming was a “hoax invented by the Chinese to make American manufacturing less competitive.” That most scientists are Democrats can be attributed in large part because of attacks on climate change (and the theory of evolution, I’d add), not because they are anti-capitalism. I bet most of us recognize the benefits of a capitalistic society like I do.
While I worry about carbon and temperature, they are not the only things that matter. Climate change can cause more extreme weather, such as droughts which have plagued the Middle East, exacerbating the current refugee crisis and destabilizing governments throughout the world. Droughts are also stressing supplies in South Africa, and even America, as we have sadly seen in California.
A more recent existential threat pertains to artificial intelligence.
Two classes of threats I ponder are (a) autonomous weapons, and a broad category that I call (b) the risks of catastrophic misinformation. Both are compounding factors that contribute to nuclear warfare or a more drastic climate trend.
The danger of autonomous weapons has been widely explored in recent books, such as Army of None (on my TODO list) and in generic Artificial Intelligence books such as Life 3.0 (highly recommended!). There are a number of terrifying ways in which these weapons could wreak havoc among populations throughout the world.
For example, one could also think of autonomous weapons merging with biological terrorism, perhaps via a swarm of “killer bee robots” spreading a virus. Fortunately, as summarized by Steven Pinker in the existential threats chapter of Enlightenment Now, biological agents are actually ill-suited for widespread terrorism and pandemics in the modern era. But autonomous weapons could easily be used for purposes that we can’t even imagine now.
Autonomous weapons will be applied on specially designed hardware. These won’t be like the physical, humanoid robots that Toyota is developing for home robots, because robotic motion that mimics human-like motion is too slow and cumbersome to cause an existential threat. Recent AI advances have been primarily from software. Nowhere was this more apparent to me from AlphaGo, which astonished the world by defeating a top Go player … but a DeepMind employee, following AlphaGo’s instructions, placed the stones on the board. The irony is that something as “primitive” as finely placing stones on a game board is beyond the ability of current robots. This means that I do not consider situations where a robot must physically acquire resources with its own hardware to be an existential threat.
The second aspect of AI that I worry about is, as stated earlier, “catastrophic misinformation.” What do I mean by this? I refer to how AI might be trained to create material that can drastically mislead a group of people, which might cause them to be belligerent with others, hence increasing the chances of nuclear or widespread warfare.
Consider a more advanced form of AI that can generate images (and perhaps videos!) far more complex than those that the NVIDIA GAN can create. Even today, people have difficulty distinguishing between fake and real news, as noted in LikeWar. A future risk for humanity might involve a world-wide “PizzaGate” incident where misled leaders go at war with each other, provoked by AI-generated misinformation from a terrorist organization running open-source code.
Even if we could count on citizens to hold their leaders accountable, (a) some countries simply don’t have accountable leaders or knowledgeable citizens, and (b) even “educated” people can be silently nudged to support certain issues. North Korea has brainwashed their citizens to obey their leaders without question. China is moving beyond blocking “Tiananmen Square massacre”-like themes on the Internet; they can determine social credit scores, automatically tracked via phone apps and Big Data. China additionally has the technical know-how, hardware, and data, to utilize the latest AI advances.
Imagine what authoritarian leaders could do if they wanted to rouse support for some controversial issue … that they learned via fake-news AI. That succinctly summarizes my concerns.
Nuclear warfare, climate change, and artificial intelligence, are currently keeping me up at night.
How to be Better: 2019 and Earlier Resolutions
I have written New Year’s resolutions since 2014, and do post-mortems to evaluate my progress. All of my resolutions are in separate text documents in my laptop’s desktop, so I see them every morning.
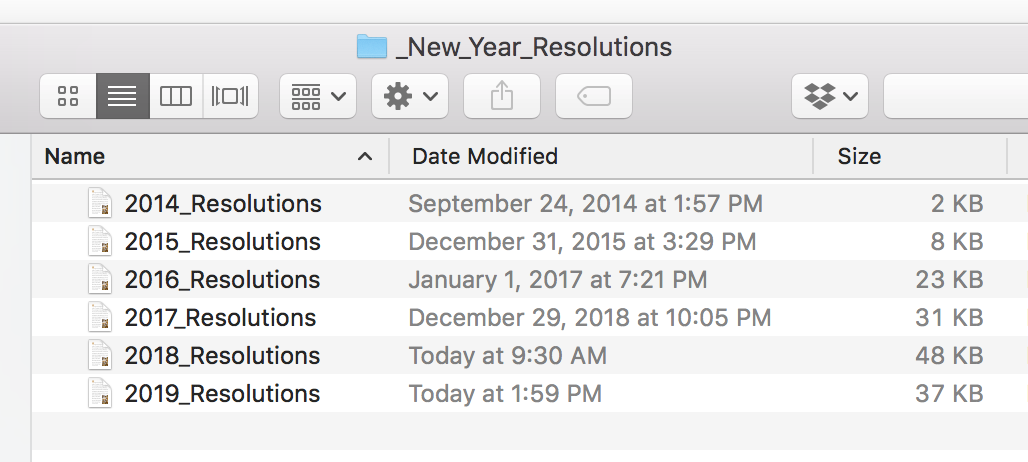
In the past I’ve only blogged about the 2015 edition, where I briefly covered my resolutions for the year. That was four years ago, so how are things looking today?
The good news: I have maintained tracking New Year’s resolutions throughout the years, and have achieved many of my goals. Some resolutions are specific, such as “run a half marathon in under 1:45”, but others are vague, such as “run consistently on Tuesdays and Thursdays”, so I don’t keep track of the number of successes or failures. Instead, I jot down several “positive,” “neutral,” and “negative” conclusions at each year’s end.
Possibly because of my newfound goals and ambitions, my current resolutions are much longer than they were in 2015. My 2019 resolutions are split into six categories: (1) reading books, (2) blogging, (3) academics, education, and work, (4) physical fitness and health, (5) money and finances, and (6) miscellaneous. Each is further sub-divided as needed.
Probably the most notable change I’ve made since 2015 is my book reading habit, which has rapidly turned into my #1 non-academic activity. It’s the one I default to during my evenings, my vacations, my plane rides, and on Saturdays when I generally do not work in order to recharge and to preserve my sanity.
Ultimately, much of my future career/life will depend on how well I meet my goals under class (3) above, in the academics, education, and work category, At a high level, the goals here (which could be applied to my other categories, but I view them mostly under the lens of “work”) are:
-
Be Better At Minimizing Distractions. I am reasonably good at this, but there is still a wide chasm between where I’m at and my ideal state. I checked email way too often this past year, and need to cut that down.
-
Be Better At Reading Research Papers. Reading academic papers is hard. I have read many, as evident by my GitHub paper notes repository. But not all of those notes have reflected true understanding, and it’s easy to get bogged down into irrelevant details. I also need to be more skeptical of research papers, since no paper is perfect.
-
Be Better At Learning New Concepts. When learning new concepts (examples: reading a textbook, self-studying an online course, understanding a new code base), apply deliberate practice. It’s the best way to quickly get up to speed and rapidly attain the level of expertise I require.
I hope I make a leap in 2019. Feel free to contact me if you’ve had some good experiences or insights from forming your own New Year’s resolutions!
Books Read in 2018
[Warning: Long Read]
As I did in 2016 and then in 2017, I am reporting the list of books that I read this past year1 along with brief summaries and my colorful commentary. This year, I read 34 books, which is similar to the amount in past years (35 and 43, respectively). This page will have any future set of reading list posts.
Here are the categories:
- Business, Economics, and Technology (9 books)
- Biographies and Memoirs (9 books)
- Self-Improvement (6 books)
- History (3 books)
- Current Events (3 books)
- Miscellaneous (4 books)
All books are non-fiction, and I drafted the summaries written below as soon as I had finished reading each book.
As usual, I write the titles below in bold text, and the books that I especially enjoyed reading have double asterisks (**) surrounding the titles.
Group 1: Business, Economics, and Technology
I’m lumping these all together because the business/econ books that I read tend to be about “high tech” industries.
-
** Crossing the Chasm: Marketing and Selling High-Tech Products to Mainstream Customers ** is Geoffrey A. Moore’s famous book (published in 1991, revised 1999 and 2014) aimed as a guide to high-tech start-up firms. Moore argues that start-ups initially deal with an early set of customers – the “visionaries” – but in order to survive long-term, they must transition to a mainstream market with pragmatist and conservative customers with different expectations and purchasing practices. Moore treats the gap between early and mainstream customers a chasm that many high-tech companies fail to cross. This is a waste of potential, and hence this book is a guide on how to successfully enter the mainstream market, which is when the company ideally stabilizes and rakes in the profits. Moore describes the solution with an analogy with D-Day: “Our long-term goal is to enter and take control of a mainstream market (Western Europe) that is currently dominated by an entrenched competitor (the Axis). For our product to wrest the mainstream market from this competitor, we must assemble an invasion force comprising other products and companies (the Allies) […]”. This is cheesy, but I admit it helped my understanding of Moore’s arguments, and on the whole, the advice in this book seems accurate, at least as good as one can expect to get in the business world. One important caveat: Crossing the Chasm is aimed at B2B (Business to Business) companies and not B2C (Business to Consumer) companies, so it might be slightly harder intuitively interpret “normal” business activity in B2B-land. Despite my lack of business-related knowledge, however, this book was highly readable. I learned more about business jargon which should make it easier for me to discuss and debate relevant topics with friends and colleagues. I read this book after it was recommended by Andrew Ng.2 While I don’t have any plans to create a start-up, Ng has recently founded Deeplearning.ai and Landing.ai, and serves as chairman of Woebot. For Landing.ai, which seems to be his main “B2B company,” I will see if I can interpret the company’s actions in the context of Crossing the Chasm.
-
How Asia Works: Success and Failure in the World’s Most Dynamic Region is a 2013 book by Joe Studwell, who I would classify as a “business journalist” (there isn’t much information about him, but he has a blog). Studwell attempts to identify why certain Asian countries have succeeded economically and technologically (Japan, Taiwan, South Korea, and now China, which takes up a chapter all on its own) while others have not (Thailand, Indonesia, Malaysia, and the Philippines). Studwell’s argument is split into three parts. The first is agriculture: successful states promote agriculture for farms instead of “efficient” large-scale businesses, since low-income countries have lots of low-skill laborers who can be effective farmers.3 The second step is to focus on manufacturing with the state providing political and economic support to get small companies to develop export discipline (something he brings up A LOT). The third part is on finance: governments need to support agriculture and manufacturing as discussed earlier, rather than lavish money towards real estate. The fourth chapter is about China. (In the first three chapters, he has five “journey” tales: Japan, Philippines, South Korea, Malaysia, and Indonesia. These were really interesting!) There are several broader takeaways. First, he repeatedly makes the case for more government intervention when the country is just developing, and not deregulation as the World Bank and United States keep saying. Of course, later deregulation is critical, but don’t do it too early! Studwell repeatedly criticizes economists who don’t understand history. But I doubt lots of government intervention is helpful. What about the famines in China and ethnic wars that were entirely due to government policy? To be fair, I agree that if governments follow his recipe, then countries are likely to succeed, but the recipe — though easy to describe — is astoundingly hard to achieve in practice due to a variety of reasons. The book is a bit dry and I wish some content had been cut off since it still wasn’t clear to me what happened to make agriculture so important in Japan and other countries, but I had to spend lots of time interrupting my reading to look up online about facts about Asia that I didn’t know. I wholeheartedly agree with Bill Gates’ final words: “How Asia Works is not a gripping page-turner aimed at general audiences, but it’s a good read for anyone who wants to understand what actually determines whether a developing economy will succeed. Studwell’s formula is refreshingly clear—even if it’s very difficult to execute.” Whatever my disagreements with Studwell, we can all agree that it is easy to fail and hard to succeed.
-
Blockchain Revolution: How the Technology Behind Bitcoin and Cryptocurrencies is Changing the World (2016, later updated in 2018) by father-son author team Don Tapscott and Alex Tapscott, describes how the blockchain technology will change the world. To be clear, blockchain already has done that (to some extent), but the book is mostly about the future and its potential. The technology behind blockchain, which has enabled bitcoin, was famously introduced in 2008 by Satoshi Nakamoto, whose true identity remains unknown. Blockchain Revolution gives an overview of Nakamoto’s idea, and then spends most of its ink describing problems that could be solved or ameliorated with blockchain, such as excess centralization of power, suppression of citizens under authoritarian governments, inefficiencies in payment systems, and so forth. This isn’t the book’s main emphasis, but I am particularly intrigued by the potential for combining blockchain technology with artificial intelligence; the Tapscotts are optimistic about automating things with smart devices. I still have lots of questions about blockchain, and to better understand it, I will likely have to implement a simplified form of it myself. That being said, despite the book’s optimism, I remain concerned for a few reasons. The first is that I’m worried about all the energy that we need for mining — isn’t that going to counter any efficiency gains from blockchain technology (e.g., due to smart energy grids)? Second, will this be too complex for ordinary citizens to understand and benefit, leaving the rich to get the fruits? Third, are we really sure that blockchain will help protect citizens from authoritarian governments, and that there aren’t any unanticipated drawbacks? I remain cautiously optimistic. The book is great at trying to match the science fiction potential with reality, but still, I worry that the expectations for blockchain are too high.
-
** The Industries of the Future ** is an engaging, informative book written by Alec Ross in 2016. Ross’ job description nowadays mostly consists of being an advisor to someone: advisor to Secretary of State Hillary Clinton, and to various other CEOs and organizations, and he’s a visiting scholar and an author (with this book!). It’s a bit unclear to me how one arrives at that kind of “advisor” position,4 but his book shows to me that he knows his stuff. Born in West Virginia, he saw the decline of coal and how opportunities have dwindled for those who have fallen behind in the new, information, data, and tech-based economy. In this book, Ross’ goal is to predict what industries will be “hot” in the next 20 years (2016-2036). He discusses robotics and machine learning (yay!), genomics, cryptocurrency and other currency, code wars, and so on. Amazingly, he cites Ken Goldberg and the work the lab has done in surgical robotics, which is impressive! (I was circling the citations and endnotes with my pencil, grinning from ear-to-ear when reading the book.) Now, Ross’ predictions are not exactly bold. There are a lot of people saying the same thing about future industries — but that also means Ross is probably more likely to be right than wrong. Towards the end of the book, he discusses how to best prepare ourselves for the industries of the future. His main claim is that leaders cannot be a control freak. (He also mentions the need to have women be involved in the industries of the future.) People such as Vladimir Putin and other leaders that want control will fall behind in such a world, so instead of “capitalism vs communism” of the 20th century, we have “open vs closed” of the 21st century. Of course, this happens on a spectrum. Some countries are closed politically but open economically (China is the ultimate case) and some are open politically (in the sense of democracy, etc.) but closed economically (India).5 Unfortunately I think he underestimated how much authoritarian leaders can retain control over their citizens and steal technologies (see LikeWar below). While his book is about predictions, not about policy solutions, Ross ran for Governor of Maryland in the Democratic primaries. Unfortunately, he got clobbered in the primaries, finishing 7th out of 9th. Well, we know by now that the most qualified candidate doesn’t always get the job…
-
** Driverless: Intelligent Cars and the Road Ahead ** is an academic book by Hod Lipson, Professor of Mechanical Engineering at Columbia, and Melba Kurman, a tech writer. I have always heard news about self-driving cars — I mean, look at my BARS 2018 experience — but never got around to understanding how they are actually retrofitted. Hence, why I read this book. It provides a decent overview of the history on self-driving cars, from the early, promising (but overly optimistic) 1950s era, to today, when they are now becoming more of a reality due to deep learning and other supporting technologies. The authors are advocates of self-driving cars, and for fully automatic cars (like with Google is trying to do), and not a gradual change from human-to-automatic (like what car manufacturers would like). They make a compelling case: if we try to develop self-driving cars by gradually transitioning to automation but keeping the human in the loop, it won’t work. Humans can’t suddenly jerk back to attention and take over when needed. It’s different in airfare, as David Mindell describes in Our Robots, Ourselves: Robotics and the Myths of Autonomy where there can be a sufficient mix of human and autonomy. Flying a plane is, parodoxically, actually easier in some ways than driving to have human-in-the-loop automation.6 While this might sound bad for car manufacturers, the good news is that the tech companies with the software powering the self-driving cars will need to partner with one of the manufacturers for the hardware. Later, Driverless book discusses the history of competitions such as DARPA, which I’ve seen in prior books. What distinguishes Driverless from prior books I’ve read is that they describe how modern self-driving cars are retrofitted, which was new to me. And then, finally, they talk about Deep Learning. That’s the final piece in the puzzle, and what really excites me going forward.
-
** Platform Revolution: How Networked Markets Are Transforming the Economy and How to Make Them Work for You ** is a recent 2016 book co-authored by a three-team of Geoffrey G. Parker, Marshall W. Van Alstyne, and Sangeet Paul Choudary. The first two are professors (of (management) engineering and business, respectively) and the third is a well-regarded platform business insider. Platform Revolution describes how traditional “pipeline” businesses are either transforming into or rapidly being usurped by competitors following a platform business model. They define a platform as “A business based on enabling value-creating interactions between external producers and consumers” and emphasize the differences between that and pipeline businesses where the value chain starts from the firm designing a product and soliciting materials, to consumers purchasing it at the end. Understanding platforms for business people and others is of paramount importance for an obvious reason: platform businesses have revolutionized the economy by tapping into previously dormant sources of value and innovation. It helps that many of the examples in this book are familiar: Uber, Lyft, Amazon, Google, Facebook, LinkedIn, dating apps, and so forth, but I also learned about lesser-known businesses. For me, key insights included how best to design platforms to enable rapid growth, how to create high-quality interactions, the challenges of regulating them, and of course, how platforms make money. For example, I already knew that Facebook makes a ton of money due to advertisements (and not for user sign-ups, thankfully), but what about lesser-known platforms? I will strive to recall the concepts in Platform Revolution if (more likely when) I enter the world of business. I agree with Andrew McAfee’s (author of “Machine Platform Crowd”, see below) praise that “you can either read [Platform Revolution] or try to keep it out of the hands of your competitors – present and future. I think it’s an easy call.”
-
** Machine Platform Crowd: Harnessing our Digital Future ** is the most recent book jointly authored by Brynjolfsson and McAfee. It was published in 2017, and I was excited to read it after thoroughly enjoying their 2014 book The Second Machine Age. The title implies that it overlaps with the previous book, and it does: on platforms, the effect of two-sided markets, and how they are disrupting businesses. But there’s also two other core aspects: the machine and the crowd. In the former (my favorite part, for obvious reasons), they talk about how AI and machine learning have been able to overcome “Polyani’s Paradox”, discussing DeepMind’s AlphaGo – yay! Key insight: experts are often incorrect, and it’s best to leave many decisions to machines. The other part is the crowd, and how the core of many participants can do better than a smaller group of so-called experts. One of the more interesting aspects is the debate on Bitcoin as an alternative to cash/currency, and the underlying Blockchain structure to help enforce contracts. However, they say that companies are not going obsolete, in part because contracts can never fully specify everything in the possible world, so companies can claim to do anything that’s not specified there if they own an asset, etc. Brynjolfsson and McAfee argue that while the pace of today’s world is incredible, companies will still have a role to play, and so will people and management, since they help to provide a conducive environment or mission to get things done. Overall, these themes combine together to form a splendid presentation in, effectively, how to understand all three of these aspects (the machine, the platform, and the crowd) in the context of our world today. Sure, one can’t know everything from reading a book, but it gives a tremendous starting point, hence why I enjoyed it very much.
-
** Hit Refresh: The Quest to Rediscover Microsoft’s Soul and Imagine a Better Future for Everyone ** is a recent 2017 book by Microsoft CEO Satya Nadella and co-authored with Greg Shaw and Jill Tracie Nichols. Nadella is the third CEO in Microsoft’s history, the others being Steve Ballmer and (of course) Bill Gates himself. (Hit Refresh is listed on Bill Gates’ book blog, which I should have anticipated like I expect the sun to rise tomorrow.) In this book, Nadella uses the analogy of “hitting refresh” to describe his approach to being a CEO: just as how hitting refresh changes a webpage on your computer but also preserves some of the existing internal structure, Nadella as CEO wanted to change some aspects of Microsoft but maintain what worked well. The main Microsoft-related takeaway I got was that, at the time Nadella took the reins, Microsoft was behind on the mobile and cloud computing markets, and had a somewhat questionable stance towards open source code. Fast forward just a few years later, and all of a sudden it’s like we’re seeing a new Microsoft, with its stock price tripled in just four years. Microsoft’s Azure cloud computing platform is now a respectable competitor to Amazon Web Services, and Microsoft’s acquisitions of Minecraft and – especially – GitHub show its commitment to engaging in the communities of gamers and open-source programmers. In the future, Nadella predicts that mixed reality, artificial intelligence, and quantum computing will be the key technologies going forward, and Microsoft should play a key role in ensuring that such developments benefit humanity. This book is also partly about Nadella’s background: how he went from Hyderabad, India, to Redmond, Microsoft, and I find the story inspiring, and wish I can replicate some of his success in my future, post-Berkeley career. Overall, Hit Refresh is a refreshing (pun intended) book to read, and I was happy to get an insider’s view of how Microsoft works, and Microsoft’s vision for the near future.
-
** Reinventing Capitalism in the Age of Big Data ** is a 2018 book by Oxford professor Viktor Mayer-Schönberger and writer Thomas Ramge, that describes their view of how capitalism works today. In particular, they focus on comparing markets versus firms in a manner similar to books such as Platform Revolution (see my comments above), but with perhaps an increased discussion over the role of prices. Historically, humans lacked all the data we have today, and condensing everything about an item for purchase in a single quantity made sense for the sake of efficiency. Things have changed in today’s Big Data world, where data can better connect producers and consumers. In the past, a firm could control data and coordinate efforts, but this advantage has declined over time, causing the authors to argue that markets are making a “comeback” against the firm, while the decline of the firm means we need to rethink our approaches towards employment since stable jobs are less likely. Reinventing Capitalism doesn’t discuss much about policies to pursue, but one that I remember they suggested is a data tax (or any “data-sharing mandate” for that matter) to help level the playing field, where data effectively plays the role of money from earlier, or fuel in the case of Artificial Intelligence applications. Obviously, this won’t be happening any time soon (and especially not with the Republican party in control of our government) but it’s certainly thought-provoking to consider what the future might bring. I feel that, like a Universal Basic Income (UBI), a data tax is inevitable, but will come too late for most of its benefits to kick in due to delays in government implementation. It’s an interesting book, and I would recommend it along with the other business-related books I’ve read here. For another perspective, see David Leonhardt’s favorable review in The New York Times.
Group 2: Biographies and Memoirs
This is rapidly becoming a popular genre within nonfiction for me, because I like knowing more about accomplished people who I admire. It helps drive me to become a better person.
-
** Lee Kuan Yew: The Grand Master’s Insights on China, the United States, and the World ** is a book consisting of a series of quotes from Lee Kuan Yew (LKY), either through his writing or interviews throughout his long life. LKY was the first Prime Minister of Singapore from 1959 to 1990, and the transformation was nothing short of astonishing: taking a third-world country to a first-world one with skyscrapers and massive wealth, all despite being literally the size of a single city! Written two years before LKY’s death in 2015, this book covers a wide range of topics: the future of the United States and China, the future of Radical Islam, the future of globalization, how leadership and democracy works, and so on. Former Secretary of State Henry Kissinger wrote the introduction to this book, marveling at LKY’s knowledge. The impression I get from this book is that LKY simply is the definition of competent. Many books and articles I read about economics, democracy, and nation-building cite Singapore as a case where an unusually competent government can bring a nation from the third world to the first in a single generation.7 Part of the reason why I like the book is that LKY shares many of the insights I’ve worked out through my own extensive reading over the last few years. He, like I would describe myself, considers himself a classical liberal who supports democracy, the free market, and a sufficient — but not overblown — welfare state to support the lower class who lose out on the free market. I also found many of his comments remarkably prescient. He was making comments in 2000 about the dangers of globalization and the gap between rural and urban residents, and other topics that became “household” ones after the 2016 US Presidential Election. He’s also right in that weaknesses of the US system include gridlock and an inability to control spending (despite the Republicans in power now). He additionally (and again, this was quite before 2016) commented that the strength of America is that it takes in a number of immigrants (unlike East Asian countries) but also that the US would face issues with the rise of minorities such as Hispanics. He describes himself as correct — not politically correct — though some of his comments could be taken as caustic. I admire that he describes his goal of governance as maximizing the collective good of the greatest amount of people, and that he doesn’t have a theory — he just wants to get things done and then he will do things that work, and he’ll “let others extract the principles from my successful solutions”, the “real life test.” Though he passed away in 2015, his legacy of competence continues to be felt in Singapore.
-
** Worthy Fights: A Memoir of Leadership in War and Peace ** is Leon Panetta’s memoir, co-written with Jim Newton. I didn’t know much about Panetta, but after reading this engaging story of his life, I’m incredibly amazed by his career and how Panetta has made the United States and the world better off. The memoir starts at his father’s immigration from Italy to the United States, and then discusses Panetta’s early career in Congress (first as an assistant to a Congressman, then as a Congressman himself), and then his time at the Office of Management and Budget, and then President Clinton’s Chief of Staff, and then (yes, there’s more!) Director of the CIA, and finally, President Obama’s Secretary of Defense. Wow — that’s a lot to absorb already, and I wish I could have a fraction of the success and impact that Panetta has had on the world. I appreciate Panetta for several reasons. First, he repeatedly argues for the importance of balancing budgets, something which I believe isn’t a priority for either political party; despite what some may say (especially in the Republican party), their actions suggest otherwise (let’s build a wall!!!). Panetta, though, actually helped to balance the federal budget. Second, I appreciated all the effort that he and the CIA did to find and kill Osama bin Laden — that was one of the best things to happen from the CIA over the last decade, and their efforts should be appreciated. The raid on Osama bin Laden’s fortress was the most thrilling part of the memoir by far, and I could not put the book down. Finally, and while this may just be me, I personally find Panetta to be just the kind of American that we need the most. His commitment to the country is evident by the words in the book, and I can only hope that we see more people like him — whether in politics or not — instead of the ones who try to run government shutdowns8 and deliberately provoke people for the sake of provocation. After Enlightenment Now (see below), this was my second favorite book of 2018.
-
** My Journey at the Nuclear Brink ** is William Perry’s story of his coming of age in the nuclear era. For those who don’t know him (admittedly, this included me before reading this book!) he served as the Secretary of Defense for President Clinton from February 1994 to January 1997. Before that he held an “undersecretary” position in government, and before that he was an aspiring entrepreneur and a mathematician, and earlier still, he was in the military. The book can be admittedly dry at times, but I still liked it and Perry recounts several occasions when he truly feared that the world would delve into nuclear warfare, most notably during the Cuban Missile Crisis. During the Cold War, as expected, Perry’s focus was on containing possible threats from the Soviet Union. Later, as Secretary of Defense, Perry was faced with a new challenge: the end of the Cold War meant that the Soviet Union dissolved into 15 countries, but this meant that nuclear weapons were spread out among different entities, heightening the risks. It is a shame that few people understand how essential Perry was (along with then-Georgia Senator Sam Nunn) in defusing this crisis by destroying or dis-assembling nuclear silos. It is also a shame that, as painfully recounted by Perry, Russia-U.S. relations have sunk to their lowest point since the high at 1996-1997 that Perry helped to facilitate. Relations sank in large part due to the expansion of NATO to include Eastern European countries. This was an important event discussed by Michael Mandelbaum in Mission Failure, and while Perry argued forcefully against NATO expansion, Clinton overrode his decision by listening to … Al Gore, of all people. Gaaah. In more recent years, Perry has teamed up with Sam Nunn, Henry Kissinger, and George Shultz to spread knowledge on the dangers of nuclear warfare. These four men aim to move towards a world without nuclear weapons. I can only hope that we achieve that ideal.
-
** The Art of Tough: Fearlessly Facing Politics and Life ** is Barbara Boxer’s memoir, published in 2016 near the end of her fourth (and last) term as U.S. Senator of California. Before that, she was in the House of Representatives for a decade. Earlier still, Boxer held some local positions while taking part in several other political campaigns. Before moving to California in 2014, I didn’t know about Barbara Boxer, so I learned more about her experiences in the previously mentioned positions; I got a picture of what it’s like to run a political campaign and then later to be a politician. The stories of the Senate are most riveting, since it’s a highly exclusive body that acts as a feeder for presidents. It’s also constantly under public scrutiny — a good thing! In the Senate, Boxer emphasizes the necessity of developing working relationships among colleagues (are you listening, Ted Cruz?). She also emphasizes the importance of being tough (hence the book’s title), particularly due to being one of the few women in the Senate. Another example of “being tough” is staking out a minority, unpopular political position, such as her vote against the Iraq war in 2002, which was the correct thing to do in hindsight. She concludes the memoir emphasizing that she didn’t retire because of hyper-partisanship, but rather because she thought she could be more effective outside the Senate and that California would produce worthy successors to her. Indeed, her successor Kamala Harris holds very similar political positions. The book was a quick, inspiring read, and I now want to devour more memoirs by famous politicians. My biggest complaint, by far, is that during the 1992 Senate election, Boxer described herself as “an asterisk in the polls” and said even as recently as a few months before the Democratic primary election, she was thinking of quitting. But then she won … without any explanation for how she overcame the other contestants. I mean, seriously? One more thing: truthfully, one reason why I read The Art of Tough was that I wanted to know how people actually get to the House of Representatives or the Senate. In Boxer’s case, her predecessor actually knew her and recommended that she run for his seat. Thus, it seems like I need to know more politically powerful people.
-
** Hillbilly Elegy: A Memoir of a Family and Culture in Crisis ** is a famous 2016 memoir by Venture Capitalist JD Vance. He grew up poor, in Jackson, Kentucky and Middletown, Ohio and describes poverty, alcoholicism, a missing Dad, and a drug-addicted Mom complete with a revolving door of male figures. He found hope with his grandparents (known as “Mamaw and Papaw”) whom he credits for helping him recover academically. Vance then spent several years in the Marines, because he admitted he wasn’t ready for higher education. But the years in the Marines taught him well, and he went to Ohio State University and then Yale Law School, where one of his professors, Amy Chua, would encourage him to write this book. Hillbilly Elegy is great; in the beginning, you have to reread a few of these names to understand the family tree, but once you do, you can get a picture of what life must have been like — and how even though Vance was able to break out of poverty, he still has traces of his past. For instance, he still sometimes storms away from his current wife (another Yale Law grad) since that’s what the men in his family would often do, and he still has to watch his mother who continues to cycle in and out of drug abuse. Today, Vance is a Venture Capitalist investing in the mid-west and other areas that he thinks have been neglected.9 Hillbilly Elegy became popular after the 2016 presidential election, because in many ways it encapsulated rural, mid-Western white America’s shift from Democratic to Republican. As expected, Vance is a conservative, but says he voted for a third party. But here’s what I don’t get. He often blames the welfare state, but then he also fully admits that many of the members of his party believe in myths such as Obama being a Muslim and so forth, and says politics cannot help them. Well then, what shall we do? I also disagree with him about the problem of declining church attendance. I would never do some of the things the men in his family would do, despite my lack of church attendance — it’s something other than church attendance that’s the problem. According to his Twitter feed, he considered running for a Senate seat in Ohio, but elected not to!10 For another piece on his views, see his great opinion piece in The New York Times about finding hope from Barack Obama.
-
** Alibaba: The House that Jack Ma Built ** is an engaging biography of Jack Ma by longtime friend Duncan Clark. Jack Ma is the co-founder and face of Alibaba, which has led to his net worth of about 35 billion today. Ma has an unusual background as an English teacher in China, with little tech knowledge (he often jokes about this), despite Alibaba being the biggest e-commerce thing in China. In Alibaba, Clark describes Ma’s upbringing from Zhejiang province in China, with pictures from his childhood. He then describes how the business-minded reforms of China allowed Ma to try his hand at entrepreneurship, and particularly at e-commerce due to the spread of the Internet in China. Alibaba wasn’t Ma’s first company — his first ended up not doing much, but like so many eventually successful businessmen, he learned and was able to co-found Alibaba, fighting off e-Bay in China and joining with Yahoo to skyrocket in wealth. Of course, Alibaba wasn’t a guaranteed success, and like many books about entrepreneurs, Clark goes over the difficulties Ma had, and times when things just seemed hopeless. But, here we are today, and Ma — despite sacrificing lots of equity to other employees and investors — somehow has billions of dollars. It is a rousing and inspiring success story for someone with an unusual background for entrepreneurship, which is one of the reasons (along with Jack Ma’s oral skill) why people find his story inspiring. Clark’s book was written in 2016, and a number of interesting things have happened since the book was published. First, John Canny has had this student and this student join Alibaba, who (as far as I know) apply Deep Learning techniques there. Second, Ma has stepped down (!!) from Alibaba and was revealed to be a member of the Communist party. Duncan Clark, the author of this book, was cited, quoting that this is a sign that the government may be exercising too much control. For the sake of business (and the usual human rights issues) in China, I hope that is not the case.
-
** Churchill and Orwell: The Fight for Freedom ** is a thrilling 2017 book by Thomas E. Ricks, a longtime reporter specializing in military and national security issues, and who writes the Foreign Policy blog Best Defense. Churchill and Orwell, provides a dual biography of these two Englishmen, first discussing them independently before weaving together their stories and then combining their legacies. By the end of the 20th Century, as the book correctly points out, both Churchill and Orwell would be considered as two of the most influential figures in protecting the rights and freedoms of people from intrusive state governments and outside adversaries. Churchill, obviously, was the Prime Minister of England during World War II and guided the country through blood and tears to victory versus the decidedly anti-freedom Nazi Germany. Orwell initially played a far lesser role in the fight for freedom, and was still an unknown quantity even during the 1940s as he was writing his two most influential works: Animal Farm and 1984. However, no one could ever have anticipated at the time of his death in 1950 (one year after publishing 1984) that those books would become two of the most wildly successful novels of all time11. As mentioned earlier, this book was published last year, but I think if Ricks had extra time, he would have mentioned Kellyanne Conway’s infamous “alternative facts” statement and how 1984 once again became a bestseller … decades after it was originally published. I’m grateful to Ricks for writing such an engaging book, but of course, I’m even more grateful for what Churchill and Orwell have done. Their legacies have a permanent spot in my heart.
-
** A Higher Loyalty: Truth, Lies, and Leadership ** is the famous 2018 memoir of James Comey, former FBI director and detested by Democrats and Republicans alike. I probably have a (pun intended) higher opinion of him than almost all “serious” Democrats and Republicans, given my sympathy towards people who work in intelligence and military jobs that are supposed to be non-political. I was interested in why Comey discussed Clinton’s emails they way he did, and also how he managed his interactions with Trump. Note that the Robert Mueller thing is largely classified, so there’s nothing in A Higher Loyalty about that, but his interactions with others at the highest levels of American politics is fascinating. Comey’s book, however, starts early, with a harrowing story about how Comey and his brother were robbed at gunpoint while in high school, an event which he would remember forever and which spurred him to join law enforcement. Among other great stories in the book (before the Clinton/Trump stuff) is when he threatened to resign as (deputy) Attorney General. That was when George Bush wanted to renew StellarWind, a program which would surge into public discourse upon Edward Snowden’s leaks. I knew about this, but Comey’s writing made this story thrilling: a race to try and protect a dying Attorney General’s approval to renew a law which Comey and other lawyers thought was completely indefensible. (It was criticized by WSJ writer Karl Rove as “melodramatic flair”). Regarding the Clinton emails, Comey did a good job explaining to me what needed to happen in order to prosecute Clinton, and I think the explanation he gave was fair. Now, about his renewal of the news 11 days before the election … Comey said either he could not say anything (and destroy the reputation of the FBI if the email investigation was found to continue) or say something (and get hammered now). One of the things that I’m most impressed about the book is Comey’s praise towards Obama, and oddly, Obama said he still thought highly of him at the end of 2016 when Comey was universally pilloried in the press. A Higher Loyalty is another book in my collection of those who have served in high levels of office (Leon Panetta, William Perry, Michael Hayden, Barbara Boxer, Sonia Sotomayor, etc.) so you can tell that there’s a trend here. The WSJ slammed him for being “more like Trump than he admits” but I personally can’t agree with that statement.
-
Faith: A Journey for All is one of former President James (“Jimmy”) Carter’s many books,12 this one published in 2018. I discussed it in this earlier blog post.
Group 3: Self-Improvement and Skills Development
I have long enjoyed reading these books because I want to use them to become a highly effective person who can change the world for the better.
-
** Stress Free For Good: 10 Scientifically Proven Life Skills for Health and Happiness ** is a well-known 2005 book13 co-authored by professors Fred Luskin and Kenneth R. Pelletier. The former is known for writing Forgive for Good and his research on forgiveness, while the latter is more on the medical side. In this book, they discuss two types of stress: Type I and Type II. Type I stress occurs when the stress source is easily identified and resolved, while Type II stress is (as you might guess) when the source cannot be easily resolved. Not all stress is bad — somewhat contradicting the title itself! – as humans clearly need stress and its associated responses if it is absolutely necessary for survival (e.g., running away from a murderer). But this is not the correct response for a chronic but non-lethal condition such as deteriorating familial relationships, challenging work environments, and so forth. Thus, Luskin and Pelletier go through 10 skills, each dedicated to its own chapter. Skills include the obvious, such as smiling, and the not-so-obvious, such as … belly-breathing?!? Yes, really. The authors argue that each skill is scientifically proven and back each with anecdotes from their patients. I enjoyed the anecdotes, but I wonder how much scientific evidence qualifies as “proven”. Stress Free For Good does not formally cite any papers, and instead concisely describes work done by groups of researchers. Certainly, I don’t think we need dozens of papers to tell us that smiling is helpful, but I think other chapters (e.g., belly breathing) need more evidence. Also, like most self-help books, it suffers from the medium of the written word. Most people will read passively, and likely forget about the skills. I probably will be one of them, even though I know I should practice these skills. The good news is, while I have lots of stress, it’s not the kind (at least right now, thankfully) that is enormously debilitating and wears me down. For those in worse positions than me, I can see this book being, if not a literal life saver, at least fundamentally useful.
-
** The Start-Up of You: Adapt to the Future, Invest in Yourself, and Transform Your Career ** is more about self-improvement rather than business. It’s a 2012 book by LinkedIn founder Reid Hoffman and entrepreneur Ben Casnocha. Regarding Hoffman, he left academia and joined the tech industry despite little tech background, starting at Apple for two years and then going to Fujitsu for product management. He founded an online dating company which didn’t work out, before experiencing success with PayPal’s team, and then of course, as the founder of the go-to social network for professionals, LinkedIn. And for Casnocha, I need to start reading his blog if I want to learn more about business. But anyway, this book is about how to improve yourself to better adapt to modern times, which (as we all know) is fast-paced and makes it less likely that one can hold one career for life. To drill this home, Hoffman and Casnocha start off by discussing Detroit and the auto industry. They criticize the “passion first, then job hunt” mantra a la Cal Newport — who applauds the book on his blog, though I’m guessing he wouldn’t like the social media aspects. Hoffman and Casnocha urge the reader to utilize LinkedIn, Facebook, and Twitter to network, of but course Hoffman wants us to utilize LinkedIn!! Less controversially (at least to me), the authors talk about having a Plan A, B, and Z (!!), and show examples of pivoting. For example, the Flickr team, Sheryl Sandberg, and Reid Hoffman ended up in wildly different areas than they would have expected. Things change and one cannot plan everything. In addition, they also suggest working on a team. I agree! Look at high-tech start-ups today. They are essentially all co-founded. In addition to anecdotes and high-level advice, Hoffman and Casnocha have some more specific suggestions that they list at the end of chapters. One explicitly tells the reader to reach out to five people who work in adjacent niches and ask for coffee. I’ve never been a fan of this kind of advice, but perhaps I should start trying at least something? What I can agree with is this: lifelong learning. Yes, I am a lifelong learner.
-
How to Invest Your Time Like Money is a brief 2015 essay by time coach Elizabeth Grace Saunders, and I found out about it by reading (no surprise here!) a blog post from Cal Newport. I bought this on my iBooks app while trying to pass the time at a long airport layover in Vancouver when I was returning from ICRA 2018. Like many similarly-themed books, she urges the reader to drop activities that aren’t high on the priority list and won’t have a huge impact (meetings!!), and to set aside sufficient time for relaxing and sleeping. The main distinction between this book and others in the genre is that Saunders tries to provide a full-blown weekly schedule to the reader, urging them to fill in the blanks with what their schedule will look like. The book also proffers formulaic techniques to figure out which activity should go where. This is the part that I’m not a fan of — I never like having to go that far in detail in my scheduling and I doubt the effectiveness of applying formulas to figure out my activities. I can usually reduce my work days to one or two critical things that I need to do, and block off huge amounts of flexible time blocks. A fixed, rigid schedule (as in, stop working on task A at 10:00am and switch to task B for two hours) rarely works for me, so I am not much of a fan of this book.
-
** Peak: Secrets from the New Science of Expertise ** is a 2016 book by Florida State University psychologist Anders Ericsson and science writer Robert Pool. Ericsson is well-known for his research on deliberate practice, a proven technique for rapidly improving one’s ability in some field,14 and this book presents his findings to educate the lay audience. Ericsson and Pool define deliberate practice as a special type of “purposeful practice” in which there are well-defined goals, immediate feedback, total focus, and where the practitioner is slightly outside his or her comfort zone (but not too much!). This starkly contrasts with the kind of ineffective practice where one repeats the same activity over and over again. Ericsson and Pool demonstrate how the principles of deliberate practice were derived not only from “the usual”15 fields of chess and music, but also from seemingly obscure tasks such as memorizing a string of numerical digits. They provide lessons on developing mental representations for deliberate practice. Ericsson and Pool critique Malcolm Gladwell’s famous “10,000-hour rule” and, while they agree that it is necessary to invest ginormous amounts of time to become an expert, that time must consist of deliberate practice rather than “ordinary” practice. A somewhat controversial topic that appears later is the notion of “natural talent.” Ericsson and Pool claim that it doesn’t exist except for height and body size for sports, and perhaps a few early advantages associated with IQ for mental tasks. They back their argument with evidence of how child prodigies (e.g., Mozart) actually invested lots of meaningful practice beforehand. And thus lies the paradox for me: I’m happy that there isn’t a “natural talent” for computer science and AI research, but I’m not happy that I got a substantially late start in developing my math, programming and AI skills compared to my peers. That being said, this book proves its worth as an advocate for deliberate practice and for its appropriate myth-busting. I will do my best to apply deliberate practice to my work and physical fitness.
-
** Grit: The Power of Passion and Perseverance **, a 2016 book by Angela Duckworth, a 2013 MacArthur Fellow and a professor of psychology at the University of Pennsylvania. Duckworth is noted for winning a “genius” grant, despite how (when growing up) her father would explicitly say that she wasn’t a genius. She explores West Point and the military, athletics, academia, and other areas (e.g., the business world), to understand what causes people to be high achievers while others achieve less? Her conclusion is that these people have “grit”. She develops a Grit scale – you can take it in the book. (I am always skeptical of these things, but it’s very hard to measure psychological factors.) Duckworth says people with grit combine passion and perseverance (see the book’s subtitle!). She cites West Point survivors, fellow MacArthur fellow Ta-Nehisi Coates, and Cody Coleman, who is now a computer science PhD candidate at Stanford University. But how do you get grit? Follow your passion is bad advice, which by now I’ve internalized. And yes, she cites Cal Newport’s So Good They Can’t Ignore You, but apparently Deep Work must have been published too late to make it into this book, because her FAQ later says she works about 70 hours a week in all; this is shorter than my work schedule but longer than Professor Newport’s.16 But anyway, she makes it clear that once people have started their passion or mission, they need to stick with it and not quit just because they’ve had one bad day. For Duckworth, her mission is about using psychology to maximize success in people, and children in particular. Part of this involves deliberate practice, and yes, she cites Anders Ericsson’s work, which is largely compatible with grit. Probably the major gap in the grit hypothesis is that stuff like poverty, racism and other barriers can throw a wrench in success, but grit can still be relatively useful regardless of circumstances. If you want to know more, you can check out her 6-minute TED talk.
-
** Great at Work: How Top Performers Do Less, Work Better, and Achieve More ** is a 2018 book by Berkeley management professor Morten T. Hansen. The book advertises itself as the empirically-backed version of The Seven Habits of Highly Effective People, and indeed, the main distinction this book has over other self-improvement books is that it’s based on a study Hansen conducted with 5000 participants. Hansen and his collaborators interviewed the people and scored them based on a series of survey questions. While there are obvious limitations to this, it’s unavoidable in a study of humans and it’s arguably the best we can realistically do if we exclude tracking Google Habits — see “Everybody Lies” later in this blog post. The main findings of Great at Work are not particularly surprising, and especially for me since I already read a number of books on self-improvement; heck, Hansen cites books I’ve read such as Peak (see above!) and Newport’s So Good They Can’t Ignore You. (It’s either a good sign or a bad sign that I know so many of Hansen’s book references.) One main point he makes is that the highest performers do few things, but obsess at being well at those things. So it’s not just enough to follow what most books tell you to do and pick a few tasks; you also have to really obsess to be the best at those. That seems to be the book’s most important advice. I know I need to do that. I’ve gotten better at “doing fewer things” because I’m finally focusing on robotics research only, but I still don’t feel like I’m the leading expert of any sub-field. I haven’t been as successful as a graduate student as I would have liked, hence why I read so many books like this. Perhaps that’s a sign I shouldn’t be reading so many books and instead internalizing the advice from a few of them — that’s a fair argument. Still, the book is a great read, and the empirical backing is a nice plus.
Group 4: History
This is a relatively short section, with just three books. Still, all three were excellent and highly educational. These books (especially the last two) can be harder to read than biographies, which is why I read fewer of them.
-
** The Post-American World ** a 2009 book by CNN host Fareed Zakaria. I don’t think I’ve ever seen him on TV, though I have seen him referenced many times in news articles, so this book allowed me to learn from him directly. The Post-American World is yet another book about the rise of other countries (especially China) and suggests that the United States is (gasp!) losing its aura of superiority; such books include as That Used to be Us and Mission Failure, both of which I read two years ago. The Post-American World is a fast-paced, easily readable book. At the time of publication, America was reeling from the financial crisis and suffering from the Iraq war. Zakaria has fair critiques of the Bush administration’s approach towards the war, and also wonders how the United States will manage its finances going forward. But fortunately, much of this book isn’t about pointing out the decline of America, so as it is about the uplifting of everyone else, which is a more pleasant tradeoff. I read this on my plane ride from Brisbane, Australia, to Vancouver, Canada, two countries that are not America (obviously) and which are also great places to visit and live. So, I don’t mind if other countries can lift their citizens out of poverty and ensure that their politics are working well and safe — it means much of the world is better off, not just America. I read this book literally the day after finishing Enlightenment Now, and I remember there being lots of similarities among the two books, and I was nodding and smiling along the way. My only wish was that it was slightly bit longer, since it was the only printed book I had on a 13.5-hour flight, and I feel like I forgot much of the details in the book in lieu of what was in Enlightenment Now (see below). For another perspective, the NYTimes reviewed it favorably.
-
** The Origins of Political Order: From Prehuman Times to the French Revolution ** is a book by political scientist Francis Fukuyama, and one that I’ve wanted to read for several years and finally finished it after the ICRA 2019 deadline. I discuss the book in a separate blog post, where I also discuss Jimmy Carter’s book. Fukuyama wrote a follow-up book which I bought after BARS 2018, but alas, I have not even started reading it. Neither did I read Fukuyama’s more famous work, The End of History and the Last Man. There is so much I need to read, but not enough time.
-
** Enlightenment Now: The Case for Reason, Science, Humanism, and Progress ** is a 2018 book by famous Harvard professor Steven Pinker,17 known for writing the 2011 bestseller The Better Angels of Our Nature and for research in cognitive psychology. I haven’t read Better Angels (I have a copy of it), but Enlightenment Now seems to be a natural sequel written in a similar style with graphs and facts galore about how the world has been getting better overall, and not worse as some might think from the “Again” in “Make America Great Again!!”. The bulk of the book consists of chapters on one main theme, such as life, the environment, equal rights, democracy, inequality, peace, existential threats, and other topics. For each, Pinker explains why things have gotten better by reporting on relevant long-term statistics. Enlightenment Now is probably as good as you can get in answering as many of humanity’s critical questions together in one bundle, and written by someone who, in the words of Scott Aaronson (amusingly referred to as “Aronson” in the acknowledgments) is “possibly the single person on earth most qualified to tackle those questions.” In the other parts of the book, Pinker defends Enlightenment thinking from other forces, such as religious thinking and authoritarianism. To me, one of the most impressive parts of the book may be that Pinker very often anticipates the counter-arguments and answers them right after making various claims. I find Pinker’s claims to be very reasonable and I can tell why Bill Gates refers to Enlightenment Now as “his new favorite book” (replacing Better Angels). And about Trump, it’s impossible to ignore him in a book about progress, because Trump’s “Make America Great Again” professes a nostalgia for a glorious past, but this would include (in the United States alone) segregation, bans on interracial marriage, gay sex, and birth control.18 Is that the kind of world we want to live in? Despite all the real problems we face today, if I had to pick any time to be born, it would be the present. Pinker is a great spokesman for Enlightenment thinking, and I’m happy to consider myself a supporter and ardent defender of these ideals. This was my favorite book I read in 2018.
Group 5: Current Events
Here are three books published in 2018 about current events, from a US-centric perspective, with some discussions about Russia sprinkled in.
-
** The Fifth Risk ** is the latest book by author and journalist Michael Lewis, who writes about the consequences of what happens when people in control of government don’t know how it works. In the words of John Williams, “I would read an 800-page history of the stapler if he wrote it”. That’s true for me as well. Lewis quickly hooked me with his writing, which starts off about … you guessed it, Rick Perry and the Department of Energy. The former Texas governor was somehow tapped to run the Department of Energy despite famously campaigning to abolish it back in the 2012 Republican primaries … when, of course, in a televised debate, he failed to remember it as the third government agency he would eliminate. Oops. Later, he admitted he regretted this, but still: of all the people that could possibly lead the Department of Energy, why did it have to be him?!?!?19 Other departments and agencies are also led by people with either little understanding of how it works, or industry lobbyists who stand to gain a large paycheck after leaving government. I want the best people to get the job, and that’s unfortunately not happening with Trump’s administration. Furthermore, not only do we have job mismatches, we also have repeated federal government shutdowns, at the time of me writing this blog post. Why should Americans want to work for the federal government if we can’t give them a stable wage? (That’s literally why many people aim for federal jobs, due presumably to more stability than the private sector.) The silver lining is that this book also consists of a series of interviews with unsung heroes in our government, who are working to maintain it and counter the influence of misguided decisions happen on top. The Fifth Risk will clearly not have any impact whatsoever on the Trump administration, because they would not bother reading books like this.
-
** LikeWar: The Weaponization of Social Media ** is a 2018 book that, like The Fifth Risk (see above), is engaging yet extremely disconcerting. It’s about how social media has grown out of an original innocence of “we can change the world” to something more sinister and dangerous that authoritarian governments and terrorists can exploit to advance their agendas. The authors, P.W. Singer and Emerson T Brooking, are experts in national security, conflict, and social media. At the beginning, they discuss Trump and Twitter, but LikeWar is not about Trump specifically. There was more discussion about Russia spawning fake accounts on Twitter and Facebook to influence American thinking and perpetuate fake news. (Though I don’t think this was directly due to Russia, remember PizzaGate?) ISIS, of course, ran roughshod on on Twitter to recruit terrorists. Also disconcerting are how China, Russia, Middle Eastern countries, and other authoritarian governments are salivating at the prospects of using social media and smartphone apps to police the thoughts of their citizens and (in China) assigning “scores” to them. At the end of the book, as I was worried about, the authors start talking about Artificial Intelligence, and how it can now be used to generate fake images, which will raise another host of worrisome issues. This is what keeps me up at night. Others agree: Gen. Michael Hayden, Vint Cerf, and Francis Fukuyama all provide their own praise for the book, showing the diverse audience of LikeWar. Singer and Brooking have some advice going forward: more information literacy, governments must view social media as another battleground, tech companies must step up, and so forth. I’m not optimistic that tech companies will do this, because they also have to satisfy shareholders who demand growth. Singer and Brooking resign to the fact that social media is part of our lives, and say we’re all addicted. That may be true, but that doesn’t mean people can’t change and cut down social media usage.
-
** The Assault on Intelligence: American National Security in an Age of Lies ** (2018) by General Michael V. Hayden, former director of CIA and NSA. Hayden makes it clear that he isn’t a fan of Trump, and describes his perspective on Trump and the IC from the period when Trump was a candidate up to his first 100 days in office. It’s not optimistic. Hayden admits that the personal relationship between the IC and Trump was “in the toilet.” The biggest failure is Trump’s frequent dismissal of the IC’s warnings about Russia (and by extension, Putin). Hayden lamented that the IC’s priorities are Russia, China, Radical Islam and ISIS, and drugs/gangs at the border, in descending order, yet Trump somehow seems fixated on the reverse: frequently bashing Mexico and talking about a “wall”, and then trying to ally with Putin to defeat Islamic State in Syria (even though that’s the narrative Putin and Assad want), and so forth. It’s distressing. The good news is that there are competent people in the administration: Hayden has high praise for Pompeo and Mattis. Of course, the book was published before Mattis resigned so … yeah. Hayden concludes that government leadership is necessary to combat misconceptions on truth and Russia, but the Trump administration isn’t up to the task. This book shares similar themes with LikeWar (see above); no wonder Hayden’s praise is on the jacket cover. The Assault on Intelligence is a fast and engaging read, and I enjoyed the insider perspective. Hayden comments on his interactions with current and former Trump cabinet officials. The main downside for someone like me who follows national security news semi-regularly is that, aside from these personal interactions, there wasn’t much new to me, since I was already aware of Putin’s misinformation campaign. Perhaps for those who will read the book in the future with less memory of current events, the material will be more novel. I thank General Hayden for writing this book, and for his service. I hope that the Trump era will turn out to be just a blip in the relationship between the government and the IC. I hope.
Group 6: Miscellaneous
Finally, we have some random books that didn’t make it into the above categories.
-
Nuclear Energy: What Everyone Needs to Know was written by Charles D. Ferguson, and provides an overview of various topics pertinent to nuclear energy. You can explore (Doctor) Ferguson’s background on his LinkedIn page, but to summarize: a PhD in physics followed by various government and think-tank jobs, most of which relate to nuclear energy and make him well-qualified to write this book. Published in 2011, just two weeks after the Fukushima accident and before the Iran Nuclear Deal, Nuclear Energy is organized as a set of eight chapters, each of which is broken up into a list of sections. Each section is highlighted by a question or two, such as “What is energy, and what is power?” in the first chapter on fundamentals, and “How many nuclear weapons do the nuclear armed countries have?” in the chapter on proliferation. I decided to read this book for two main reasons: the first is that I am worried about existential threats from nuclear warfare (inspired in part by reading William Perry’s book this year — see above), and the second is whether nuclear energy can be a useful tool for addressing climate change. For the former, I learned about the many agencies and people who are doing their part to stop proliferation, which partially assuages my concerns. For the latter, I got mixed messages, unfortunately. In general, Ferguson does a good job treating issues in a relatively unbiased manner, presenting both pros and cons. The book isn’t a page-turner, and I worry that the first chapter on fundamentals might turn off potential readers, but once a reader gets though the first chapter, the rest is easier reading. I am happy he wrote Nuclear Energy, and I plan to mention more in a subsequent blog post.
-
** Give and Take: Why Helping Others Drives Our Success ** is a 2014 book by Wharton Professor Adam Grant. I read his Originals last year (see my book list), so I had Give and Take on my radar for months. Written in his highly identifiable and engaging writing style, Grant explains that people can be categorized as “givers,” “takers,” or “matchers.” Givers spend more time helping others, takers place less priority on helping others,20 and matchers will help others so long as they are equally reciprocated. These labels are malleable: people can transition from taker to giver, as Grant demonstrates in his discussion about Freecycle21. People also act differently in various domains, such as being a giver in a volunteer hobby group but a taker during normal work hours. Having established these categories, Grant argues that we need to rethink the power of being a giver, and he provides evidence in domains ranging from schools to businesses that givers are the most likely to be successful. Adam Rifkin, America’s best networker, George Meyer of the Simpsons, and others who Grant describes as givers, have benefits over takers and matchers in communication, influencing, networking, and collaborating. Givers, however, need to protect themselves at the bargaining table to ensure that people don’t take advantage of them. His main strategy appears to be to give by default, but to transition to a (generous) tit-for-tat upon seeing any signs of trouble. Overall, the arguments and evidence seem reasonable. That’s not to say that I was not skeptical of some parts of the book. There’s the cherry picking as usual: what if there’s an enormous list of successful people who are takers, and perhaps these were simply ignored in Grant’s research? I do not hold this against Grant that much because, well, no one can collect and analyze every possible situation that might be of interest. Another possible limitation could be that giving takes too much time; as described in an excellent NYTimes article, Professor Grant — himself a giver, obviously — works extremely heavy hours, so I often wonder if it is possible to be such a highly productive giver with a tighter time budget. On balance, though, the book’s arguments appear reasonable and backed by studies, though obviously I haven’t read any of the academic references. I also naturally wonder what kind of giver, taker, or matcher label applies to me … comments welcome!
-
Turing’s Vision: The Birth of Computer Science is a brief book by math professor Chris Bernhardt which attempts to present the themes of Turing’s landmark paper of 1936 (written when he was just 24 years old) on the theory of computation. Most of the material was familiar to me as it is covered in standard theory of computation courses for undergraduates, though I have to confess that I forgot much of the material. And this, despite blogging about theory of computation several times on this blog! You can find the paper online, titled “On Computable Numbers, with an Application to the Entscheidungsproblem”. I think the book is useful as a general introduction to the lay reader (i.e., non computer scientist).
-
** Everybody Lies: Big Data, New Data, and What the Internet Can Tell Us About Who We Really Are ** is a brilliantly entertaining book published last year by researcher, writer, and lecturer Seth Stephens-Davidowitz. I’ll call him “Seth” in this post only because he isn’t much older than I am and his last-name is very long. Seth is an economist who is well-known for mining data from Google searchers to help us answer pressing questions such as the ones he lists on the cover of the book: How much sex are people really having?, How many Americans are actually racist?, and so on. Seth correctly points out that if these questions were listed in traditional surveys, few would answer honestly. Furthermore, some questions (e.g., how much sex?) are subject to the fallacies of human memory. The solution? Take a database of Google search terms and make inferences! Google searches have a number of benefits: that people are comfortable making sensitive searches in private, that people are using them a lot (hence, “Big Data”), and that there’s meta-data attached to it, such as the time and place of the search, which we can tie to specific events and/or political characteristics. Everybody Lies uses this and other factors to make what I think are quite reasonable conclusions about these sensitive topics (sex and racism are two common ones in this book), and brings what I think is a largely novel perspective of merging Big Data with traditional humanities research, something that Steven Pinker (who wrote the foreword to this book!) pointed out in Enlightenment Now. Seth, like any responsible author, points out the limitations and ethics of utilizing Big Data, and on the whole the perspective is balanced. One takeaway from this is that I should be thinking about data-driven things whenever I try to think about the humanities, or even about my own political positions. I’ll do my best!22
Whew, that’s 2018. Up next, 2019. Happy readings!
Update January 2, 2019: I revised the post since I had forgotten to include one book, and I actually read another one in between the December 27 publication date and January 1 of the new year. So that’s 34 books I read, not 32.
-
Technically, books that I finished reading this year, which includes those that I started reading in late 2017, and excludes those that I will finish in 2019. ↩
-
Yeah, yeah, if Andrew Ng says to read a book, then I will read it. Sorry, I can follow the leader a bit too much … ↩
-
One of the phrases that I remember well from the book is something like: “this is a book on how to get into the rich man’s club in the first place” (emphasis mine). ↩
-
I would be interested in being a “science advisor” to the President of the United States. ↩
-
It should surprise no one that I am a vocal proponent of an open society, both politically and economically. ↩
-
There’s less congestion in the air, and the skill required means all the “drivers” are far more sophisticated than the ground counterparts. ↩
-
Singapore is advanced enough in that top academic conferences are held there — think ICRA 2017. (Sadly, I was unable to attend, though I heard the venue was excellent.) In addition, Singapore is often the best country in terms of “number of academic papers with respect to total population” for obvious reasons. ↩
-
At the time I finished this book in early 2018 and drafted the summary for Worthy Fights in this blog post, the US Government was reeling from two government shutdowns, one from Chuck Schumer and the other from Rand Paul. And at the end of 2018, when I finished doing minor edits to the entire post before official publication, we were in the midst of the third government shutdown of the year, this time from Donald Trump who famously said he would “own” the shutdown in a televised interview. Don’t worry, this doesn’t hinder my interest in running for political office. If anything, the constant gridlock in Washington increases my interest in being there somehow, since I think I could improve the situation. ↩
-
This raises the question: if Vance says he should do that, shouldn’t other VCs help to invest in areas or in groups of people who haven’t gotten the fruits of VC funding, such as black people? ↩
-
This shocked me. If I were in his position, which admittedly I am not, there’s no way I would not run for office. I mean, he had people (not including — presumably — his relatives) clamoring him to run!! ↩
-
In 2005, TIME chose both Animal Farm and 1984 to be in their top 100 novels of all time. ↩
-
I mean, look at all of these books! ↩
-
I decided to read it upon seeing it featured on Professor Olga Russakovsky’s website. ↩
-
When I saw the book’s description, I immediately thought of Cal Newport’s Deep Work as a technique that merges well with deliberate practice, and I was therefore not surprised to see that deliberate practice has been mentioned previously on Study Hacks. ↩
-
I say “usual” here because chess and music are common domains where psychologists can run controlled experiments to measure expertise, study habits, and so on. ↩
-
I wonder what she would think of Newport’s Deep Work book. ↩
-
I bumped into Steven Pinker totally by coincidence at San Francisco International Airport (SFO) last month. I was surprised that he was all by himself, even when SFO is filled with people who presumably must have read his book. I only briefly mentioned to him that I enjoyed reading his book. I did not want to distub him. ↩
-
I should add from my perspective, the past also includes lack of technological and personal support for people with disabilities. ↩
-
Lewis, unfortunately, believes that Perry has not spent much time learning about the department from the previous energy secretary, an MIT nuclear physicist who played a role in the technical negotiations of the Iran nuclear deal. Dude, there’s a reason why President Obama chose nuclear physicists to run the Department of Energy. ↩
-
Unless they’re smooching to get that salary increase, or trying to con people à la Kenneth Lay. ↩
-
Freecycle seems like a cool resource. Think of it as a Craigslist but where all products must be sold for free. I’m surprised I never heard of Freecycle before reading Give and Take, but then again, I didn’t know anything about Craigslist until summer 2014, when I learned about it as I was searching for apartments in Berkeley. That’s why reading books so useful: I learn. ↩
-
I couldn’t help but end this short review with two quick semi-personal comments. First, I didn’t realize until reading the acknowledgments section (yes, I read every name in those!) that he is a close friend of CMU professor Jean Yang, whose blog I have known about for many years. Second, Seth cites the 2015 paper A Century of Portraits: A Visual Historical Record of American High School Yearbooks, by several students affiliated with Alexei Efros’ group. The citation, however, was incorrect since it somehow missed the lead author, so I took pictures and emailed the situation to him and the Berkeley authors. Seth responded with a one-liner: “Sorry. Not sure how that happened. I will change in future editions”, so hopefully there will be future editions (not sure how likely that is with books, though). I bet the Berkeley authors were surprised to see that (a) their work made it in Seth’s book, and (b) someone actually read the endnotes and caught the error. ↩
Better Saving and Logging for Research Experiments
In many research projects, it is essential to test which of several competing methods and/or hyperparameters works best. The process of saving and logging experiments, however, can create a disorganized jungle of output files. Furthermore, reproducibility can be challenging without knowing all the exact parameter choices that were used to generate results. Inspired in part by Dustin Tran’s excellent Research-to-Engineering framework blog post, in this post I will present several techniques that have worked well for me in managing my research code, with a specific emphasis on logging and saving experimental runs.
Technique 0. I will label this as technique “0” since it should be mandatory and generalizes far beyond logging research code compared to the other tips here: use version control. git, along with the “hub extension” to form GitHub, is the standard in my field, though I’ve also managed projects using GitLab.
In addition, I’ve settled on these relevant strategies:
- To evaluate research code, I create a separate branch strictly for this
purpose (which I name
eval-[whatever]), so that it doesn’t interfere with my main master branch, and to enable greater ease of reproducing prior results by simply switching to the appropriate branch. The alternative would be to reset and restore to an older commit in master, which can be highly error-prone. - I make a new Python virtualenv for each major project, and save a
requirements.txtsomewhere in the repository so that recreating the environment on any of the several machines I have access to is (usually) as simple aspip install -r requirements.txt. - For major repositories, I like to add a
setup.pyfile so that I can install the library usingpython setup.py develop, allowing me to freely import the code regardless of where I am in my computer’s directory system, so long as the module is installed in my virtualenv.
Technique 1. In machine learning, and deep learning in particular,
hyperparameter tuning is essential. For the ones I frequently modify, I use the
argparse library. This lets me run code on the command line like this:
python script.py --batch_size 32 --lrate 1e-5 --num_layers 4 <more args here...>
While this is useful, the downside is readily apparent: I don’t want to have to write down all the hyperparameters each time, and copying and pasting earlier commands might be error prone, particularly when the code constantly changes. There are a few strategies to make this process easier, all of which I employ at some point:
- Make liberal use of default argument settings. I find reasonable values of most arguments, and stick with them for my experiments. That way, I don’t need to specify the values in the command line.
- Create bash scripts. I like to have a separate folder called
bash/where I insert shell scripts (with the endname.sh) with many command line arguments for experiments. Then, after making the scripts executable withchmod, I can call experiment code using./bash/script_name.sh. - Make use of json or yaml files. For an alternative (or complimentary)
technique for managing lots of arguments, consider using
.jsonor.yamlfiles. Both file types are human-readable and have built-in support from Python libraries.
Technique 2. I save the results from experiment runs in unique directories
using Python’s os.path.join and os.makedirs functions for forming the string
and creating the resulting directory, respectively. Do not create the
directory with code like this:
directory = head + "/" + exptype + "/" + str(seed)because it’s clumsy and vulnerable to issues with slashes in directory names.
Just use os.path.join, which is so ubiquitous in my research code that by
habit I write
from os.path import joinat the top of many scripts.
Subdirectories can (and should) be created as needed within the head experiment
directory. For example, every now and then I save neural network snapshots in a
snapshots/ sub-directory, with the relevant parameter (e.g., epoch) in the
snapshot name.
But snapshots and other data files can demand lots of memory. The machines I use for my research generally have small SSDs and large HDDs. Due to memory constraints on the SSDs, which often have less than 1TB of space, I almost always save experiment logs in my HDDs.
Don’t forget to back up data! I’ve had several machines compromised by “bad guys” in the past, forcing me to reinstall the operating system. HDDs and other large-storage systems can be synced across several machines, making it easy to access. If this isn’t an option, then simply copying files over from machine-to-machine manually every few days will do; I write down reminders in my Google Calendar.
Technique 3. Here’s a surprisingly non-trivial question related to the prior tactic: how shall the directory be named? Ideally, the name should reflect the most important hyperparameters, but it’s too easy for directory names to get out of control, like this:
experiment_seed_001_lrate_1e-3_network_2_opt_adam_l2reg_1e-5_batchsize_32_ [ and more ...!]
I focus strictly on three or four of the most important experiment settings and put them in the file name. When random seeds matter, I also put them in the file name.
Then, I use Python’s datetime module to format the date that the experiment
started to run, and insert that somewhere in the file name. You can do this with
code similar to the following snippet:
def get_save_path(args, HEAD):
"""Make save path for whatever agent we are training.
"""
date = '{}'.format( datetime.datetime.now().strftime('%Y-%m-%d-%H-%M') )
seedstr = str(args.seed).zfill(3)
suffix = "{}_{}_{}_{}".format(args.alg, date, seedstr)
result_path = os.path.join(HEAD, suffix)
return result_pathwhere I create the “suffix” using the algorithm name, the date, and the random
seed (with str().zfill() to get leading zeros inserted to satisfy my OCD), and
where the “HEAD” is the machine-dependent path to the HDD (see my previous tip).
There are at least two advantages for having the date embedded in the file names:
- It avoids issues with duplicate directory names. This prevents the need to manually delete or re-name older directories.
- It makes it easy to spot-check (via
ls -lhon the command line) which experiment runs can be safely deleted if major updates were made since then.
Based on the second point above, I prefer the date to be human-readable, which is why I like formatting it the way I do above. I don’t put in the seconds as I find that to be a bit too much, but one can easily add it.
Technique 4. This last pair of techniques pertains to reproducibility. Don’t neglect them! How many times have you failed to reproduce your own results? I have experienced this before and it is embarrassing.
The first part of this technique happens during code execution: save all arguments and hyperparmaters in the output directory. That means, at minimum, write code like this:
with open(os.path.join(args.save_path,'args.pkl'), 'w') as fh:
pickle.dump(args, fh)which will save the arguments in a pickle file in the save path, denoted as
args.save_path which (as stated earlier) usually points somewhere in my
machine’s HDD. Alternatively, or in addition, you can save arguments in
human-readable form using json.
The second part of this technique happens during paper writing. Always write down the command that was used to generate figures. I mostly use Overleaf — now merged with ShareLaTeX — for writing up my results, and I insert the command in the comments above the figures, like this:
% Generate with:
% python [script].py --arg1 val1 --arg2 val2
% at commit [hashtag]
\begin{figure}
% LaTeX figure code here...
\end{figure}
It sounds trivial, but it’s helped me several times for last-minute figure
changes to satisfy page and margin limits. In many of my research projects, the
stuff I save and log changes so often that I have little choice but to have an
entire scripts/ folder with various scripts for generating figures depending
on the output type, and I can end up with tens of such files.
While I know that TensorBoard is popular for checking results, I’ve actually
never used it (gasp!); I find good old matplotlib to serve my needs
sufficiently well, even for checking training in progress. Thus, each of my
files in scripts/ creates matplotlib plots, all of which are saved in the
appropriate experiment directory in my HDDs.
Conclusion. These techniques will hopefully make one’s life easier in managing and parsing the large set of experiment results that are inevitable in empirical research projects. A recent example when these tips were useful to me was with the bed-making paper we wrote, with neural network training code here, where I was running a number of experiments to test different hyperparameters, neural network architectures, and so forth.
I hope these tips prove to be useful for your experimental framework.
Bay Area Robotics Symposium, 2018 Edition
 The auditorium where BARS 2018 talks occurred, which was within the Hoover
Institution. The number of attendees was capped at 400.
The auditorium where BARS 2018 talks occurred, which was within the Hoover
Institution. The number of attendees was capped at 400.
 An example presentation at BARS.
An example presentation at BARS.
A few weeks ago, I attended the Bay Area Robotics Symposium (BARS). Last year, BARS was at the UC Berkeley International House, and you can see my blog post summary here. This year, it was at Stanford University, within one of the Hoover Institution buildings. Alas, I did not get to meet 97-year-old George Shultz or 91-year-old William Perry so that I could thank them for helping to contain the threat of nuclear warfare from the Cold War to the present day.
Oh, and so that I could also ask how to become a future cabinet member.
The location of BARS alternates between Berkeley and Stanford since those are the primary sources of cutting-edge academic robotics research in the Bay Area. I am not sure what precisely differs “Berkeley-style” robotics from “Stanford-style” robotics. My guess is that due to Pieter Abbeel and Sergey Levine, Berkeley has more of a Deep Reinforcement Learning presence, but we also have a number of researchers in “classical” robotics (who may also use modern Deep Learning technologies) such as our elder statesmen Ken Goldberg and Masayoshi Tomizuka, and elder stateswoman Ruzena Bajcsy.
It is unclear what Stanford specializes in, though perhaps a reasonable answer is “everything important.” Like Berkeley, Deep Learning is extremely popular at Stanford. Pieter and Sergey’s former student, Chelsea Finn, is joining the Stanford faculty next year, which will balance out the Deep Reinforcement Learning research terrain.
The bulk of BARS consists of 10-minute faculty talks. Some interesting tidbits:
-
More faculty are doing research in core deep reinforcement learning, or (more commonly) making use of existing algorithms for applications elsewhere. There is also a concern over generalization to new tasks and setups. I distinctly remember Chelsea Finn saying that “this talk is about the less interesting stuff” — because generalizing to new scenarios outside the training distribution is hard.
-
Another hot area of research is Human-Robot Interaction (HRI), particularly with respect to communication and safety. With the recent hires of Dorsa Sadigh at Stanford and Anca Dragan at Berkeley, both schools now have at least one dedicated HRI lab.
-
Finally, my favorite talk was from Ken Goldberg. I was touched and honored when Ken talked about our work on bed-making, and commented on my BAIR Blog post from October which summarized key themes from the lab’s research.
Since BARS is funded in part by industry sponsors, the sponsors were allotted some presentation time. The majority were about self-driving cars. It was definitely clear what the hot topic was there …
In addition to the faculty and industry talks, there were two keynote talks. Last year, Professor Robert Full’s keynote was on mobile, insect-like robots. This year, Stanford NLP professor Chris Manning had the first slot, and in a sign of the increasing importance of robotics and the law, California Supreme Court Justice Mariano-Florentino Cuéllar gave the second keynote. That was unexpected.
During the Q-&-A session, I remember someone asking the two men how to deal with the rising pace of change and the threat of unemployment due to intelligent robots automating out jobs. I believe Professor Manning said we needed to be lifelong learners. That was predictable, and no worries, I plan to be one. I hope this was obvious to anyone who knows me! (If it was not, please contact me.)
But … Professor Manning lamented that not everyone will be lifelong learners, and disapprovingly commented about people who spend weekends on “football and beer.”
The Americans among us at BARS are probably not the biggest football fans (I’m not), and that’s before we consider the students from China, India, and other countries where football is actually soccer.
Professor Manning can get away with saying that to a BARS audience, but I would be a little cautious if the audience were instead a random sample of the American population.
BARS had two poster sessions with some reasonable food and coffee from our industry sponsors. These were indoors (rather than outdoors as planned) due to air quality concerns from the tragic California fires up north.
During the poster sessions, it was challenging to communicate with students, since most were clustered in groups and sign language interpreters can have difficulty determining the precise voice that needs to be heard and translated. Probably the most important thing I learned during the poster session was not even a particular research project. I spoke to a recent postdoc graduate from Berkeley who I recognized, and he said that he was part of a new robotics research lab at Facebook. Gee, I was wondering what took Facebook so long to establish one! Now Facebook joins Google, NVIDIA, and OpenAI with robotics research labs that, presumably, use machine learning and deep learning.
After BARS, I ate a quick dinner, bought Fukuyama’s successor book to the one I read and discussed earlier this month at the Stanford bookstore, and drove back home.
Overall, BARS went as reasonable as it probably could have gone for me.
One lasting impression on me is that Stanford’s campus is far nicer than Berkeley’s, and much flatter. No wonder Jitendra Malik was “joking” last year about how robots trained on Stanford’s smooth and orderly design would fail to generalize to Berkeley’s haphazardness.
 The Stanford campus.
The Stanford campus.
Dual Book Discussion on Political Development and Faith
I finally read two books that were on my agenda for a long time: Francis Fukuyama’s 2010 history book The Origins of Political Order: From Prehuman Times to the French Revolution and Jimmy Carter’s personal memoir Faith: A Journey for All. Reading these books took way longer than it should have, due to a research deadline. Fortunately, that’s in the past and I have pleasantly gotten back to reading too many books and spending too much time blogging.
Before proceeding, here’s a little background on Francis Fukuyama. It is actually tricky to succinctly describe his career. I view him a political scientist and author, but he has additionally been a professor, a senior fellow, a council member, and probably ten other things, at a variety of universities and think tanks related to the development of democracies. His most well-known work is the 1992 book The End of History and the Last Man, where he argues that liberal democracy represents the final, evolved form of government.1 Some events since the 1992 book — off the top of my head, 9/11, Radical Islam and ISIS, political populism, the rise of unaccountable and authoritarian governments in Russia and China — have made Fukuyama a frequent punching bag by various commentators. For one perspective, check out this recent New Yorker article for some background (and unsurprisingly, criticism) on Fukuyama, though that piece is mostly about Fukuyama’s 2018 book on identity politics and doesn’t make much reference to the book I will soon discuss on political development.
Fukuyama is also associated with the rise of neoconservatism, to which he distanced himself from due to the Iraq war. How do we know? He literally says so in a Quora answer.2 Ah, the wonders of the modern world and those “verified accounts” we see on Quora, Twitter, and other social media outlets!
Meanwhile, the second author whose book I will soon discuss, Jimmy Carter, needs no introduction. He served as the 39th President of the United States from 1977 to 1981.
You might be wondering why I am discussing their books in the same blog post. The books are different:
-
Fukuyama’s book is dense and scholarly, a 500-page historical account spanning from — as the subtitle makes clear — prehuman times to the French Revolution (1789-ish). The Origins of Political Order includes historical commentary on a variety of European countries, along with China, India, and the occasional detour into the Middle East, Latin America, and other areas. It frequently references other scholarly works that Fukuyama must have reviewed and digested in his long career.
-
Carter’s book, in contrast, is a brief personal memoir, and weighs in at around 160 pages. It describes his view of religion and how it has shaped his life, from his youth to his Navy service, to his time as president, and beyond.3
Yet, they have an interesting common theme.
First, consider The Origins of Political Order. It is a book describing how humans came to organize themselves politically, from forming small tribes and then later creating larger kingdoms and states. Fukuyama repeatedly refers to the following three political institutions:
- The State: government itself, which in particular, needs to consolidate and control power.
- Rule of Law: effective legal institutions that constrain what all people (most importantly, leaders!) can and cannot do.
- Accountable Government: having democratic elections to ensure leaders can be voted out of office.
He argues that successful, modern, liberal democracies (the kind of states I want to live in) combine these three institutions in an appropriate balance, which itself is an enormously challenging task. In particular, the pursuit of a strong state seems to be at odds with rulers and elected leaders being bound by a rule of law and accountable government.4
The Origins of Political Order attempts to outline the history, development, and evolution5 of these three institutions, focusing on factors that result in their formation (or decay). It does not attempt to describe a general “rule” or a set of instructions for the oft-used “Getting to Denmark” goal. Fukuyama believes that it is futile to develop clear theories or rules due to the multitude of factors involved.
If there is any “clear rule” that I learned from the book, it is that political decay, or the weakening of these institutions, is a constant threat to be addressed. Fukuyama invokes patrimonialism, the tendency for people to favor family and friends, as the prime factor causing political decay. He makes a strong case. Patrimonialism is natural, but doing so can lead to weaker governments as compared to those using more merit-based, impersonal systems to judge people. China, Fukuyama argues, was a pioneer in applying merit-based rules for civil service employees. Indeed, Fukuyama refers to China (and not Greece or Rome) as having built the first modern state.
The book was a deep dive into some long-term historical trends — the kind that I like to read, even if it was a struggle for me to weave together the facts. (I had to re-read many parts, and was constantly jotting down notes with my pencil in the book margins.) I was pleasantly reminded of Guns, Germs, and Steel along with The Ideas that Conquered the World, both of which I greatly enjoyed reading three years ago. I would later comment on them in a blog post.
I hope that Fukuyama’s insights can be used to create better governments throughout the world, and can additionally lead to the conclusion he sought when writing The End of History and the Last Man. Is Fukuyama right about liberal democracy being the final form of government? I will let the coming years answer that.
Do I hope Fukuyama turns out to be right all along, and vindicated by future scholars? Good heavens. By God, yes, I hope so.
Now let’s return to something I was not expecting in Fukuyama’s book: religion. (My diction in the prior paragraph was not a coincidence.) Fukuyama discusses how religion was essential for state formation by banding people together and facilitating “large-scale collective action”. To be clear, nothing in Fukuyama’s book is designed to counter the chief claims of the “new Atheist” authors he references; Fukuyama simply mentions that religion was historically a source of cohesion and unity.6
The discussion about religion brings us to Carter’s book.
In Faith, Carter explains that acquiring faith is rarely clear-cut. He does not attribute a singular event which caused him to be deeply faithful, as I have seen others do. Carter lists several deeply religious people who he had the privilege to meet, such as Bill Foege, Ugandan missionaries, and his brother. Much of Carter’s knowledge of Christianity derives from these and other religious figures, along with his preparation for when he teaches at Sunday School, which he still admirably continues to do so at 94.
Carter, additionally, explains how his faith has influenced his career as a politician and beyond. The main takeaways are that faith has: (1) provided stability to Carter’s life, and (2) driven him to change the world for the better.
Some questions that I had while reading were:
-
How do members of the same religion come to intensely disagree on certain political topics? Do disagreements arise from reading different Biblical sources or studying under different priests and pastors? Or are people simply misunderstanding the same text, just as students nowadays might misunderstand the same mathematics or science text?
Here are some examples. In Chapter 2, Carter mentions he was criticized by conservative Christians for appointing women and racial minorities to positions in government — where do such disagreements come from? Later, in Chapter 5, Carter rightfully admonishes male chauvinists who tout the Bible’s passage that says “Wives, submit yourselves to your own husbands, as you do to the Lord” because Carter claims that the Bible later says that both genders must commit to each other equally. But where do these male chauvinists come from? In Chapter 6, Carter mentions his opposition to the death penalty and opposition to discrimination on the basis of sexual orientation. Again, why are these straightforward-to-describe issues so bitterly contested?
Or do differences in beliefs come outside of religion, such as from “Enlightenment thinking”?
-
What does Carter believe we should do in light of “religious fundamentalism”? As Carter says in Chapter 2, this is when certain deeply religious people believe they are superior to others, particularly those outside the faith or viewed as insufficiently faithful. Moreover, what are the appropriate responses for when these people have political power and invoke their religious beliefs when creating and/or applying controversial laws?
-
What about the ages-old question of science versus religion? In Chapter 5, Carter states that scientific discoveries about the universe do not contradict his belief in a higher being, and serve to “strengthen the reverence and awe generated by what has already become known and what remains unexplained.” But, does this mean we should attribute all events that we can’t explain with science by defaulting to God and intelligent design? In addition, this also raises the question as to whether God currently exists, or whether God simply created the universe by gestating the Big Bang but then took his (or her??) hands permanently off the controls to see — but not influence — what would happen. This matters in the context of politicians who justify God for their political decisions. See my previous point.
Despite my frequent questions, it was insightful to understand his perspective on religion. Admittedly, I don’t think it would be fair to expect firm answers to any of my questions.
I am a non-religious atheist,7 and in all likelihood that will last for the remainder of my life, unless (as I mentioned at the bottom of this earlier blog post), I observe evidence that a God currently exists. Until then, it will be hard for me to spend my limited time reading the Bible or engaging in other religious activities when I have so many competing attentions — first among them, developing a general-purpose robot.
I will continue reading more books like Carter’s Faith (and Fukuyama’s book for that matter) because I believe it’s important to understand a variety of perspectives, and reading books lets me scratch the surface of deep subjects. This is the most time-efficient way for me to obtain a nontrivial understanding of a vast number of subjects.
On a final note, it was a pleasant surprise when Carter reveals in his book that people of a variety of different faiths, including potentially atheists, have attended his Sunday School classes. If the opportunity arises, I probably would, if only to get the chance to meet him. Or perhaps I could meet Carter if I get on a commercial airplane that he’s flying on. I would like to meet people like him, and to imagine myself changing the world as much as he has.
Since I currently have no political power, my ability to create a positive impact on the world is probably predicated in my technical knowledge. Quixotic though it may sound, I hope to use computer science and robotics to change the world for the better. If you have thoughts on how to do this, feel free to contact me.
-
I have not read The End of History and the Last Man. Needless to say, that book is high on my reading agenda. Incidentally, it seems that a number of people knowledgeable about history and foreign affairs are aware of the book, but have not actually read it. I am doing my best to leave this group. ↩
-
Let’s be honest: leaving the neoconservatism movement due to the Iraq war was the right decision. ↩
-
Carter has the longest post-presidency lifespan of any US president in history. ↩
-
There are obvious parallels in the “balance” of political institutions sought out by Fukuyama, and the “checks and balances” designed by the framers of the American Constitution. ↩
-
My word choice of “evolution” here is deliberate. Fukuyama occasionally makes references to Charles Darwin and the theory of evolution, and its parallels in the development of political institutions. ↩
-
I do not think it is fair to criticize the New Atheist claim that “religion is a source of violence”. I would be shocked if Dawkins, Harris, and similar people, believe that religion had no benefits early on during state formation. It is more during the present day when we already have well-formed states that such atheists point out the divisiveness that religion creates. ↩
-
In addition, I am also an ardent defender of free religion. ↩
BAIR Blog Post on Depth Maps and Deep Learning in Robotics
As usual, I have been slow blogging here. This time, I have a valid excuse. I was consumed with writing for another one: the Berkeley Artificial Intelligence Research (BAIR) blog, of which I serve as the primary editorial board member. If I may put my non-existent ego aside, the BAIR blog is more important (and popular!)1 than my personal blog. BAIR blog posts generally require more effort to write than personal blog posts. Quality over quantity, right?
You can read my blog post there, which is about using depth images in the context of deep learning and robotics. Unlike most BAIR blog posts, this one tries to describe a little history and a unifying theme (depth images) across multiple papers. It’s a little long; we put in a lot of effort into this post.
I also have an earlier BAIR blog post from last year, about the work I did with Markov chain Monte Carlo methods. I’ve since moved on to robotics research, which explains the sudden change in blogging topics.
Thank you for reading this little note, and I hope you also enjoy the BAIR blog post.
-
As of today, my blog (a.k.a., “Seita’s Place”) has 88 subscribers via MailChimp. The BAIR Blog has at least 3,600. ↩
Three Approaches to Deep Learning for Robotic Grasping
In ICRA 2018, “Deep Learning” was the most popular keyword in the accepted papers, and for good reason. The combination of deep learning and robotics has led to a wide variety of impressive results. In this blog post, I’ll go over three remarkable papers that pertain to deep learning for robotic grasping. While the core idea remains the same — just design a deep network, get appropriate data, and train — the papers have subtle differences in their proposed methods that are important to understand. For these papers, I will attempt to describe data collection, network design, training, and deployment.
Paper 1: Supersizing Self-supervision: Learning to Grasp from 50K Tries and 700 Robot Hours
 The grasping architecture used in this paper. No separate motor command is
passed as input to the network, since the position is known from the image patch
and the angle is one of 18 different discretized values.
The grasping architecture used in this paper. No separate motor command is
passed as input to the network, since the position is known from the image patch
and the angle is one of 18 different discretized values.
In this award-winning ICRA 2016 paper, the authors propose a data-driven grasping method that involves a robot (the Baxter in this case) repeatedly executing grasp attempts and training a network using automatically-labeled data of grasp success. The Baxter attempted 50K grasps which took 700 robot hours. Yikes!
-
Data Collection. Various objects get scattered across a flat workspace in front of the robot. An off-the-shelf “Mixture of Gaussians subtraction algorithm” is used to detect various objects. This is a necessary bias in the procedure so that a random (more like “semi-random”) grasp attempt will be near the region of the object and thus may occasionally succeed. Then, the robot moves its end-effector to a known height above the workspace, and attempts to grasp by randomly sampling a nearby 2D point and angle. To automatically deduce the success or failure label, the authors measure force readings on the gripper; if the robot has grasped successfully, then the gripper will not be completely closed. Fair enough!
-
Network Architecture. The neural network is designed to regress the grasping problem as an 18-way binary classification task (i.e., success or failure) over image patches. The 18-way branch at the end is because multiple angles may lead to successful grasps for an object, so it makes no sense to try and say only one out of 18 (or whatever the discretization) will work. Thus, they have 18 different logits, and during training on a given training data sample, only the branch corresponding to the angle in that data sample is updated with gradients.
They use a 380x380 RGB image patch centered at the target object, and downsample it to 227x227 before passing it to the network. The net uses fine-tuned AlexNet CNN layers pre-trained on ImageNet. They then add fully connected layers, and branch out as appropriate. See the top image for a visual.
In sum, the robot only needs to output a grasp that is 3 DoF: the \((x,y)\) position and the grasp angle \(\theta\). The \((x,y)\) position is implicit in the input image, since it is the central point of the image.
-
Training and Testing Procedure. Their training formally involves multiple stages, where they start with random trials, train the network, and then use the trained network to continue executing grasps. For faster training, they generate “hard-negative” samples, which are data points that the model thinks are graspable but are not. Effectively, they form a curriculum.
For evaluation, they can first measure classification performance of held-out data. This requires a forward pass for the grasping network, but does not require moving the robot, so this step can be done quickly. For deployment, they can sample a variety of patches, and for each, obtain the logits from the 18 different heads. Then for all those points, the robot picks the patch and angle combination that the grasp network rates as giving the highest probability of success.
Paper 2: Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
(Note that I briefly blogged about the paper earlier this year.)
 The grasping architecture used in this paper. Notice that it takes two RGB
images as input, representing the initial and current images for the grasp
attempt.
The grasping architecture used in this paper. Notice that it takes two RGB
images as input, representing the initial and current images for the grasp
attempt.
This paper is the “natural” next step, where we now get an order of magnitude more data points and use a much deeper neural network. Of course, there are some subtle differences with the method which are worth thinking about, and which I will go over shortly.
-
Data Collection. Levine’s paper uses six to fourteen robots collecting data in parallel, and is able to get roughly 800K grasp attempts over the course of two months. Yowza! As with Pinto’s paper, the human’s job is only to restock the objects in front of the robot (this time, in a bin with potential overlap and contact) while the robot then “randomly” attempts grasps.
The samples in their training data have labels that indicate whether a grasp attempt was successful or not. Following the trend of self-supervision papers, these labels are automatically supplied by checking if the gripper is closed or not, which is similar to what Pinto did. There is an additional image subtraction test which serves as a backup for smaller objects.
A subtle difference with Pinto’s work is that Pinto detected objects via a Mixture of Gaussians test and then had the robot attempt to grasp it. Here, the robot simply grasps at anything, and a success is indicated if the robot grasps any object. In fact, from the videos, I see that the robot can grasp multiple objects at once.
In addition, grasps are not executed in one shot, but via multiple steps of motor commands, ranging from \(T=2\) to \(T=10\) different steps. Each grasp attempt \(i\) provides \(T\) training data instances: \(\{(\mathbf{I}_t^i, \mathbf{p}_T^i - \mathbf{p}_t^i, \ell_i)\}_{t=1}^T\). So, the labels are the same for all data points, and all that matters is what happened after the last motor command. The paper discusses the interesting interpretation as reinforcement learning, which assumes actions induce a transitive relation between states. I agree in that this seems to be simpler than the alternative of prediction based on movement vectors at consecutive time steps.
-
Network Architecture. The paper uses a much deep convolutional neural network. Seriously, did they need all of those layers? I doubt that. But anyway, unlike the other architectures here, it takes two RGB 472x472x3 images as input (actually, both are 512x512x3 but then get randomly cropped for translation invariance), one for the initial scene before the grasp attempt, and the other for the current scene. The other architectures from Pinto and Mahler do not need this because they assume precise camera calibration, which allows for an open loop grasp attempt upon getting the correct target and angle.
In addition to the two input images, it takes in a 5D motor command, which is passed as input later on in the network and combined, as one would expect. This encodes the angle, which avoids the need to have different branches like in Pinto’s network. Then, the last part of the network predicts if the motor command will lead to (any) successful grasp (of any object in the bin).
-
Training and Testing Procedure. They train the network over the course of two months, updating the network 4 times and then increasing the number of steps for each grasp attempt from \(T=2\) to \(T=10\). So it is not just “collect and train” once. Each robot experienced different wear and tear, which I can agree with, though it’s a bit surprising that the paper emphasizes this a lot. I would have thought Google robots would be relative high quality and resistant to such forces.
For deploying the robot, they use a continuous servoing mechanism to continually adjust the trajectory solely based on visual input. So, the grasp attempt is not a single open-loop throw, but involves multiple steps. At each time step, it samples a set of potential motor commands, which are coupled with heuristics to ensure safety and compatibility requirements. The motor commands are also projected to go downwards to the scene, since this more closely matches the commands seen in the training data. Then, the algorithm queries the trained grasp network to see which one would have the highest success probability.
Levine’s paper briefly mentions the research contribution with respect to Dex-Net (coming up next):
Aside from the work of Pinto & Gupta (2015), prior large-scale grasp data collection efforts have focused on collecting datasets of object scans. For example, Dex-Net used a dataset of 10,000 3D models, combined with a learning framework to acquire force closure grasps.
With that, let’s move on to discussing Dex-Net.
Paper 3: Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics
(Don’t forget to check out Jeff Mahler’s excellent BAIR Blog post.)
 The grasping architecture used in this paper. Notice how the input image to the
far left is cropped and aligned to form the actual input to the GQ-CNN.
The grasping architecture used in this paper. Notice how the input image to the
far left is cropped and aligned to form the actual input to the GQ-CNN.
The Dexterity Network (“Dex-Net”) is an ongoing project at UC Berkeley’s AUTOLAB, led by Professor Ken Goldberg. There are a number of Dex-Net related papers, and for this post I will focus on the RSS 2017 paper since that uses a deep network for grasping. (It’s also the most cited of the Dex-Net related papers, with 80 as of today.)
-
Data Collection. Following their notation, states, grasps, depth images, and success metrics are denoted as \(\mathbf{x}\), \(\mathbf{u}\), \(\mathbf{y}\), and \(S(\mathbf{u},\mathbf{x})\), respectively. You can see the paper for the details. Grasps are parameterized as \(\mathbf{u} = (\mathbf{p}, \phi)\), where \(\mathbf{p}\) is the center of the grasp with respect to the camera pose and \(\phi\) is an angle in the table plane, which should be similar to the angle used in Pinto’s paper. In addition, depth images are also referred to as point clouds in this paper.
The Dex-Net 2.0 system involves the creation of a synthetic dataset of 6.7 million points for training a deep neural network. The dataset is created from 10K 3D object models from Dex-Net 1.0, and augmented with sampled grasps and robustness metrics, so it is not simply done via “try executing grasps semi-randomly.” More precisely, they sample from a graphical model to generate multiple grasps and success metrics for each object model, with constraints to ensure sufficient coverage over the model. Incidentally, the success metric is itself evaluated via another round of sampling. Finally, they create depth images using standard pinhole camera and projection models. They further process the depth images so that it is cropped to be centered at the grasp location, and rotated so that the grasp is at the middle row of the image.
Figure 3 in the paper has a nice, clear overview of the dataset generation pipeline. You can see the example images in the dataset, though these include the grasp overlay, which is not actually passed to the network. It is only for our human intuition.
-
Network Architecture. Unlike the two other papers I discuss here, the GQ-CNN takes in a depth image as input. The depth images are just 32x32 in size, so the images are definitely smaller as compared to the 227x227x3 in Pinto’s network, which in turn is smaller than the 472x472x3 input images for Levine’s network. See the image above for the GQ-CNN. Note the alignment of the input image; the Dex-Net paper claims that this removes the need to have a predefined set of discretized angles, as in Pinto’s work. It also arguably simplifies the architecture by not requiring 18 different branches at the end. The alignment process requires two coordinates of the grasp point \(\mathbf{p}\) along with the angle \(\phi\). This leaves \(z\), the height, which is passed as a separate layer. This is interesting, so instead of passing in a full grasp vector, three out of its four components are implicitly encoded in the image alignment process.
-
Training and Testing Procedure. The training seems to be straightforward SGD with momentum. I wonder if it is possible to use a form of curriculum learning as with Pinto’s paper?
They have a detailed experiment protocol for their ABB YuMi robot, which — like the Baxter — has two arms and high precision. I like this section of the paper: it’s detailed and provides a description for how objects are actually scattered across the workspace, and discusses not just novel objects but also adversarial ones. Excellent! In addition, they only define a successful grasp if the gripper held the object after not just lifting but also transporting and shaking. That will definitely test robustness.
The grasp planner assumes singulated objects (like with Pinto’s work, but not with Levine’s), but they were able to briefly test a more complicated “order fulfillment” experiment. In follow-up research, they got the bin-picking task to work.
Overall, I would argue that Dex-Net is unique compared to the two other papers in that it uses more physics and analytic-based prior methods to assist with Deep Learning, and does not involve repeatedly executing and trying out grasps.
In terms of the grasp planner, one could argue that it’s a semi-hybrid (if that makes sense) of the two other papers. In Pinto’s paper, the grasp planner isn’t really a planner: it only samples for picking the patches and then running the network to see the highest patch and angle combination. In Levine’s paper, the planner involves continuous visual servoing which can help correct actions. The Dex-Net setup requires sampling for the grasp (and not image patches) and, like Levine’s paper, uses the cross-entropy method. Dex-Net, though, does not use continuous servoing, so it requires precise camera calibration.
Update November 20, 2020: for a fourth way of doing this “deep learning and grasping” combination, check out my later post on how one can use fully convolutional neural networks for grasping. The advantage here is that execution time is faster, as it is not necessary to do any sampling of some sort, just a forward pass.
On OpenAI Baselines Refactored and the A2C Code
OpenAI, a San Francisco nonprofit organization, has been in the news for a number of reasons, such as when their Dota2 AI system was able to beat a competitive semi-professional team, and when they trained a robotic hand to have unprecedented dexterity, and in various contexts about their grandiose mission of founding artificial general intelligence. It’s safe to say that such lofty goals are characteristic of an Elon Musk-founded company (er, nonprofit). I find their technical accomplishments impressive thus far, and hope that OpenAI can continue their upward trajectory in impact. What I’d like to point out in this blog post, though, is that I don’t actually find their Dota2 system, their dexterous hand, or other research products to be their most useful or valuable contribution to the AI community.
I think OpenAI’s open-source baselines code repository wins the prize of their most important product. You can see an announcement in a blog post from about 1.5 years ago, where they correctly point out that reinforcement learning algorithms, while potentially simple to describe and outline in mathematical notation, are surprisingly hard to implement and debug. I have faced my fair share of issues in implementing reinforcement learning algorithms, and it was a relief to me when I found out about this repository. If other AI researchers base their code on this repository, then it makes it far easier to compare and extend algorithms, and far easier to verify correctness (always a concern!) of research code.
That’s not to say it’s been a smooth ride. Far from it, in fact. The baselines repository has been notorious for being difficult to use and extend. You can find plenty of complaints and constructive criticism on the GitHub issues and on reddit (e.g., see this thread).
The good news is that over the last few months — conveniently, when I was distracted with ICRA 2019 — they substantially refactored their code base.
While the refactoring is still in progress for some of the algorithms (e.g., DDPG, HER, and GAIL seem to be following their older code), the shared code and API that different algorithms should obey is apparent.
First, as their README states, algorithms should now be run with the following command:
python -m baselines.run --alg=<name of the algorithm> \
--env=<environment_id> [additional arguments]The baselines.run is a script shared across algorithms that handles the
following tasks:
-
It processes command line arguments and handles “ranks” for MPI-based code. MPI is used for algorithms that require multiple processes for parallelism.
-
It runs the training method, which returns a
modeland anenv.-
The training method needs to first fetch the learning function, along with its arguments.
-
It does this by treating the algorithm input (e.g.,
'a2c'in string form) as a python module, and then importing alearnmethod. Basically, this means in a sub-directory (e.g.,baselines/a2c) there needs to be a python script of the same name (which would bea2c.pyin this example) which defines alearnmethod. This is the main “entry point” for all refactored algorithms. -
After fetching the learning function, the code next searches to see if there are any default arguments provided. For A2C it looks like it lacks a
defaults.pyfile, so there are no defaults specified outside of thelearnmethod. If there was such a file, then the arguments indefaults.pyoverride those inlearn. In turn,defaults.pyis overriden by anything that we write on the command line. Whew, got that?
-
-
Then it needs to build the environment. Since parallelism is so important for algorithms like A2C, this often involves creating multiple environments of the same type, such as creating 16 different instantiations of the Pong game. (Such usage also depends on the environment type: whether it’s atari, retro, mujoco, etc.)
-
Without any arguments for
num_env, this will often default to the number of CPUs on the system from runningmultiprocessing.cpu_count(). For example, on my Ubuntu 16.04 machine with a Titan X (Pascal) GPU, I have 8 CPUs. This is also the value I see when runninghtop. Technically, my processor only supports 4 CPUs, but the baseline code “sees” 8 CPUs due to hyperthreading. -
They use the
SubprocVecEnvclasses for making multiple environments of the same type. In particular, it looks like it’s called as:SubprocVecEnv([make_env(i + start_index) for i in range(num_env)])from
make_vec_envinbaselines/common/cmd_util.py, where each environment is created with its own ID, and themake_envmethod further creates a random seed based on the MPI rank. This is a list of OpenAI gym environments, as one would expect. -
The current code comments in
SubprocVecEnvsuccinctly describe why this class exists:VecEnv that runs multiple environments in parallel in subproceses and communicates with them via pipes. Recommended to use when num_envs > 1 and step() can be a bottleneck.
It makes sense to me. Otherwise, we’d need to sequentially iterate through a bunch of
step()functions in a list — clearly a bottleneck in the code. Bleh! There’s a bunch of functionality that should look familiar to those who have used the gym library, except it considers the combination of all the environments in the list. -
In A2C, it looks like the
SubprocVecEnvclass is further passed as input to theVecFrameStackclass, so it’s yet another wrapper. Wrappers, wrappers, and wrappers all day, yadda yadda yadda. This means it will call theSubprocVecEnv’s methods, such asstep_wait(), and process the output (observations, rewards, etc.) as needed and then pass them to an end-algorithm like A2C with the same interface. In this case, I think the wrapper provides functionality to stack the observations so that they are all in one clean numpy array, rather than in an ugly list, but I’m not totally sure.
-
-
Then it loads the network used for the agent’s policy. By default, this is the Nature CNN for atari-based environments, and a straightforward (input-64-64-output) fully connected network otherwise. The TensorFlow construction code is in
baselines.common.models. The neural networks are not built until the learning method is subsequently called, as in the next bullet point: -
Finally, it runs the learning method it acquired earlier. Then, after training, it returns the trained model. See the individual algorithm directories for details on their
learnmethod.-
In A2C, for instance, one of the first things the
learnmethod does is to build the policy. For details, seebaselines/common/policies.py. -
There is one class there,
PolicyWithValue, which handles building the policy network and seamlessly integrates shared parameters with a value function. This is characteristic of A2C, where the policy and value functions share the same convolutional stem (at least for atari games) but have different fully connected “branches” to complete their individual objectives. When running Pong (see commands below), I get this as the list of TensorFlow trainable parameters:<tf.Variable 'a2c_model/pi/c1/w:0' shape=(8, 8, 4, 32) dtype=float32_ref> <tf.Variable 'a2c_model/pi/c1/b:0' shape=(1, 32, 1, 1) dtype=float32_ref> <tf.Variable 'a2c_model/pi/c2/w:0' shape=(4, 4, 32, 64) dtype=float32_ref> <tf.Variable 'a2c_model/pi/c2/b:0' shape=(1, 64, 1, 1) dtype=float32_ref> <tf.Variable 'a2c_model/pi/c3/w:0' shape=(3, 3, 64, 64) dtype=float32_ref> <tf.Variable 'a2c_model/pi/c3/b:0' shape=(1, 64, 1, 1) dtype=float32_ref> <tf.Variable 'a2c_model/pi/fc1/w:0' shape=(3136, 512) dtype=float32_ref> <tf.Variable 'a2c_model/pi/fc1/b:0' shape=(512,) dtype=float32_ref> <tf.Variable 'a2c_model/pi/w:0' shape=(512, 6) dtype=float32_ref> <tf.Variable 'a2c_model/pi/b:0' shape=(6,) dtype=float32_ref> <tf.Variable 'a2c_model/vf/w:0' shape=(512, 1) dtype=float32_ref> <tf.Variable 'a2c_model/vf/b:0' shape=(1,) dtype=float32_ref>There are separate policy and value branches, which are shown in the bottom four lines above. There are six actions in Pong, which explains why one of the dense layers has shape 512x6. Their code technically exposes two different interfaces to the policy network to handle stepping during training and testing, since these will in general involve different batch sizes for the observation and action placeholders.
-
The A2C algorithm uses a
Modelclass to define various TensorFlow placeholders and the computational graph, while theRunnerclass is for stepping in the (parallel) environments to generate experiences. Within thelearnmethod (which is what actually creates the model and runner), for each update step, the code is remarkably simple: call the runner to generate batches, call the train method to update weights, print some logging statistics, and repeat. Fortunately, the runner returns observations, actions, and other stuff in numpy form, making it easy to print and inspect. -
Regarding the batch size: there is a parameter based on the number of CPUs (e.g., 8). That’s how many environments are run in parallel. But there is a second parameter,
nsteps, which is 5 by default. This is how many steps the runner will execute for each minibatch. The highlights of the runner’srunmethod looks like this:for n in range(self.nsteps): actions, values, states, _ = self.model.step( self.obs, S=self.states, M=self.dones) # skipping a bunch of stuff ... obs, rewards, dones, _ = self.env.step(actions) # skipping a bunch of stuff ...The model’s
stepmethod returns actions, values and states for each of the parallel environments, which is straightforward to do since it’s a batch size in the network’s forward pass. Then, theenvclass can step in parallel using MPI and the CPU. All of these results are combined fornstepswhich multiplies an extra factor to the batch size. Then the rewards are computed based on thensteps-step returns, which is normally 5. Indeed, from checking the original A3C paper, I see that DeepMind used 5-step returns. Minor note: technically 5 is the maximum “step-return”: the last time step uses the 1-step return, the penultimate time step uses the 2-step return, and so on. It can be tricky to think about.
-
-
-
At the end, it handles saving and visualizing the agent, if desired. This uses the
stepmethod from both theModeland theenv, to handle parallelism. TheModelstep method directly calls thePolicyWithValue’sstepfunction. This exposes the value function, which allows us to see what the network thinks regarding expected return.
Incidentally, I have listed the above in order of code logic, at least as of today’s baselines code. Who knows what will happen in a few months?
Since the code base has been refactored, I decided to run a few training scripts to see performance. Unfortunately, despite the refactoring, I believe the DQN-based algorithms still are not correctly implemented. I filed a GitHub issue where you can check out the details, and suffice to say, this is a serious flaw in the baselines repository.
So for now, let’s not use DQN. Since A2C seems to be working, let us go ahead and test that. I decided to run the following command line arguments:
python -m baselines.run --alg=a2c --env=PongNoFrameskip-v4 --num_timesteps=2e7 \
--num_env=2 --save_path=models/a2c_2e7_02cpu
python -m baselines.run --alg=a2c --env=PongNoFrameskip-v4 --num_timesteps=2e7 \
--num_env=4 --save_path=models/a2c_2e7_04cpu
python -m baselines.run --alg=a2c --env=PongNoFrameskip-v4 --num_timesteps=2e7 \
--num_env=8 --save_path=models/a2c_2e7_08cpu
python -m baselines.run --alg=a2c --env=PongNoFrameskip-v4 --num_timesteps=2e7 \
--num_env=16 --save_path=models/a2c_2e7_16cpuYes, I know my computer has only 8 CPUs but I am running with 16. I’m not actually sure how this works, maybe each CPU has to deal with two processes sequentially? Heh.
When you run these commands, it (in the case of 16 environments) creates the following output in the automatically-created log directory:
daniel@takeshi:/tmp$ ls -lh openai-2018-09-26-16-06-58-922448/
total 568K
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.0.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.10.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.11.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.12.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.13.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.14.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.6K Sep 26 17:33 0.15.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.1.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.2.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.3.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.4.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.8K Sep 26 17:33 0.5.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.6.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.8K Sep 26 17:33 0.7.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.7K Sep 26 17:33 0.8.monitor.csv
-rw-rw-r-- 1 daniel daniel 7.8K Sep 26 17:33 0.9.monitor.csv
-rw-rw-r-- 1 daniel daniel 333K Sep 26 17:33 log.txt
-rw-rw-r-- 1 daniel daniel 95K Sep 26 17:33 progress.csv
Clearly, there is one monitor.csv for each of the 16 environments, which
contains the corresponding environment’s episode rewards (and not the other 15).
The log.txt is the same as the standard output, and progress.csv records
the log’s stats.
Using this python script, I plotted the results. They are shown in the image below, which you can expand in a new window to see the full size.
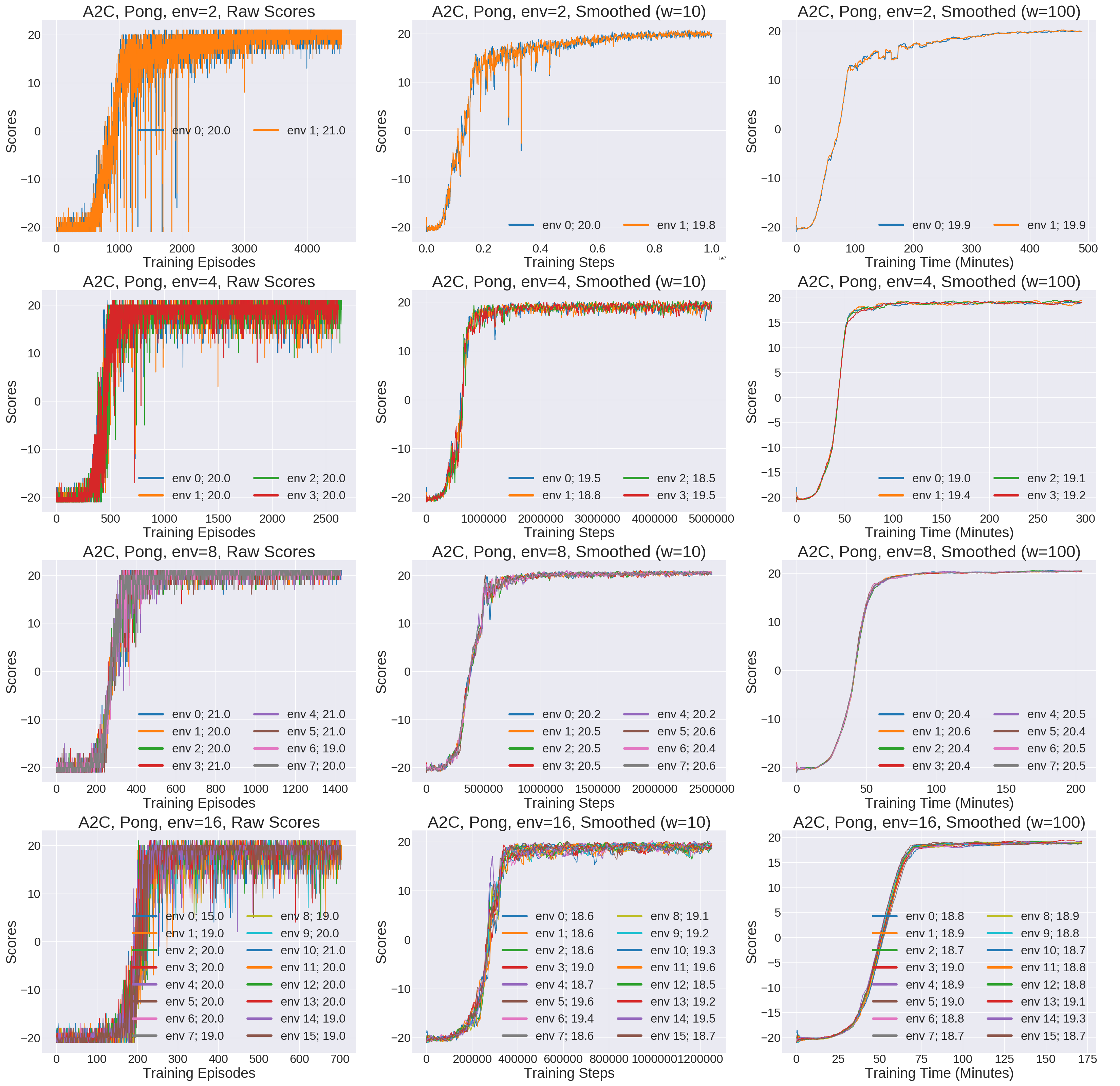
Results of the A2C commands. Each row corresponds to using a different number of
environments (2, 4, 8, or 16) in A2C, and each column corresponds to some
smoothing setting for the score curves, and some option for the x-axis
(episodes, steps, or time).
It seems like running with 8 environments results in the best game scores, with the final values for all 8 surpassing 20 points. The other three settings look like they need a little more training to get past 20. Incidentally, the raw scores (left column) are noisy, so the second and third column represent smoothing over a window of 10 and 100 episodes, respectively.
The columns also report scores as a function of different items we might care about: training episodes, training steps, or training time (in minutes). The x-axis values vary across the different rows, because the 2e7 steps limit considers the combination of all steps in the parallel environments. For example, the 16 environment case ran in 175 minutes (almost 3 hours). Interestingly enough, the speedup over the 8 environment case is smaller than one might expect, perhaps because my computer only has 8 CPUs. There is, fortunately, a huge gap in speed between the 8 and 4 settings.
Whew! That’s all for now. I will continue checking the baselines code repository for updates. I will also keep trying out more algorithms to check for correctness and to understand usage. Thanks, OpenAI, for releasing such an incredibly valuable code base!
Paper Notes: Learning to Teach
My overview of the "Learning to Teach" pipeline, using their example of
classifying MNIST images. The pipeline first samples a minibatch of data from
MNIST, and passes it through the student network to obtain statistics such as
the predicted class probabilities, the loss function value, and so on. No
training is done yet. The student architecture, incidentally, is a fully
connected 784-500-10 network. Then, these predictions, along with other
meta-data (e.g., training iteration number, one-hot vector labels, etc.) are
concatenated (shown in the dashed rectangle) and passed as input to the teacher
network, which determines whether to keep or reject the sample in the minibatch.
The teacher's architecture is (in the case of MNIST classification) a fully
connected 25-12-1 network. Only the non-rejected samples are used for the
purposes of updating the student network, via Adam gradient updates. Finally,
after a few updates to the student, the teacher network is adjusted using the
REINFORCE policy gradient rule, with a sparse reward function based on how soon
the student achieves a pre-defined accuracy threshold. Once the teacher and
student have been sufficiently trained, the teacher network can then be deployed
on other students --- even those with different neural network architectures and
testing on different datasets --- to accelerate learning.
Sorry for the post-free month — I was consumed with submitting to ICRA 2019 for the last two months, so I am only now able to get back to my various blogging and reading goals. As usual, one way I tackle both is by writing about research papers. Hence, in this post, I’ll discuss an interesting, unique paper from ICLR 2018 succinctly titled Learning to Teach. The OpenReview link is here, where you can see the favorable reviews and other comments.
Whereas standard machine learning investigates ways to better optimize an agent attempting to attain good performance for some task (e.g., classification accuracy on images), the machine teaching problem generally assumes the agent — now called the “learner” — is running some fixed algorithm, and the teacher must figure out a way to accelerate learning. Professor Zhu at Wisconsin has a nice webpage that summarizes the state of the art.
In Learning to Teach, the authors formalize their two player setup, and propose to train the teacher agent by reinforcement learning with policy gradients (the usual REINFORCE estimator). The authors explain the teacher’s state space, action space, reward, and so on, effectively describing the teaching problem as an MDP. The formalism is clean and well-written. I’m impressed. Kudos to the authors for clarity! The key novelty here must be that the teacher is updated via optimization-based methods, rather than heuristics or rules as in prior work.
The authors propose three ways the teacher can impact the student and accelerate its learning:
- Training data. The teacher can decide which training data to provide to the student. This is curriculum learning.1
- Loss function. The teacher can design an appropriate loss for the student to optimize.
- Hypothesis space. The teacher can restrict the potential hypothesis space of the student.
These three spaces make sense. I was disappointed, though, upon realizing that Learning to Teach is only about the training data portion. So, it’s a curriculum learning paper where the teacher is a reinforcement learning agent which designs the correct data input for the student. I wish there was some stuff about the other two categories: the loss function and the hypothesis space, since those seem intuitively to be much harder (and interesting!) problems. Off the top of my head, I know the domain agnostic meta learning (RSS 2018) and evolved policy gradients (NIPS 2018) papers involve changing loss functions, but it would be nice to see this in a machine teaching context.
Nonetheless, curriculum learning (or training data “scheduling”) is an important problem, and to the credit of the authors, they try a range of models and tasks for the student:
- MLP students for MNIST
- CNN students for CIFAR-10
- RNN students for text understanding (IMDB)
For the curriculum learning aspect, the teacher’s job is to filter each minibatch of data so that only a fraction of it is actually used for the student’s gradient updates. (See my figure above.) The evaluation protocol involves training the teacher and student interactively, using perhaps half of the dataset. Then, the teacher can be deployed to new students, with two variants: to students with the same or different neural network architecture. This is similar to the way the Born Again Neural Networks paper works — see my earlier blog post about it. Evaluation is based on how fast the learner achieves certain accuracy values.
Is this a fair protocol? I think so, and perhaps it is reflective of how teaching works in the real world. As far as I understand, for most teachers there is an initial training period before they are “deployed” on students.
I wonder, though, if we can somehow (a) evaluate the teacher while it is training, and (b) have the teacher engage in lifelong learning? As it is, the paper assumes the teacher trains and then is fixed and deployed, and hence the teacher does not progressively improve. But again, using a real-life analogy, consider the PhD advisor-student relationship. In theory, the PhD advisor knows much more and should be teaching the student, but as time goes on, the advisor should be learning something from its interaction with the student.
Some comments are in order:
-
The teacher features are heavily hand-tuned. For example, the authors pass in the one-hot vector label and the predicted class probabilities of each training input. This is 20 dimensions total for the two image classification tasks. It makes sense that the one-hot part isn’t as important (as judged from the appendix) but it seems like there needs to be a better way to design this. I thought the teacher would be taking in features from the input images so it could “tell” if they were close to being part of multiple classes, as is done in Hinton’s knowledge distillation paper. On the other hand, if Learning to Teach did that, the teachers would certainly not be able to generalize to different datasets.
-
Policy gradients is nothing more than random search but it works here, perhaps since (a) the teacher neural network architecture size is so small and (b) the features heavily are tuned to be informative. The reward function is sparse, but again, due to a short (unspecified) time horizon, it works in the cases they try, but I do not think it scales.
-
I’m confused by these sudden spikes in some of the CIFAR-10 plots. Can the authors explain those? It makes me really suspicious. I also wish the plots were able to show some standard deviation values because we only see the average over 5 trials. Nonetheless, the figures certainly show benefits to teaching. The gap may additionally be surprising due to the small teacher network and the fact that datasets like MNIST are simple enough that, intuitively, teaching might not be necessary.
Overall, I find the paper to be generally novel in terms of the formalism and teacher actions, which makes up for perhaps some simplistic experimental setups (e.g., simple teacher, using MNIST and CIFAR-10, only focusing on data scheduling) and lack of theory. But hey, papers can’t do everything, and it’s above the bar for ICLR.
I am excited to see what research will build upon this. Some other papers on my never-ending TODO list:
- Iterative Machine Teaching (ICML 2017)
- Towards Black-box Iterative Machine Teaching (ICML 2018)
- Learning to Teach with Dynamic Loss Functions (NIPS 2018)
Stay tuned for additional blog posts about these papers!
-
Note that in the standard reference to curriculum learning (Bengio et al., ICML 2009), the data scheduling was clearly done via heuristics. For instance, that paper had a shape recognition task, where the shapes were divided into easy and hard shapes. The curriculum was quite simple: train on easy shapes, then after a certain epoch, train on the hard ones. ↩
Saving and Loading TensorFlow Models, Without Reconstruction
Ever since I started using TensorFlow in late 2016, I’ve been a happy user of the software. Yes, the word “happy” is deliberate and not a typo. While I’m aware that it’s fashionable in certain social circles to crap on TensorFlow, to me, it’s a great piece of software that tackles an important problem, and is undoubtedly worth the time to understand in detail. Today, I did just that by addressing one of my serious knowledge gaps of TensorFlow: how to save and load models. To put this in perspective, here’s how I used to do it:
- Count the number of parameters in my Deep Neural Network and create a placeholder vector for it.
- Fetch the parameters (e.g., using
tf.trainable_variables()) in a list. - Iterate through the parameters, flatten them, and “assign” them into the
vector placeholder via
tf.assignby careful indexing. - Run a session on the vector placeholder, and save the result in a numpy file.
- When loading the weights, re-construct the TensorFlow model, download the numpy file, and re-assign weights.
You can see some sample code in a blog post I wrote last year.
Ouch. I’m embarrassed by my code. It was originally based on John Schulman’s TRPO code, but I think he did that to facilitate the Fisher-Vector products as part of the algorithm, rather than to save and load weights.
Fortunately, I have matured. I now know that it is standard practice to save and
load using tf.train.Saver(). By looking at the TensorFlow documentation
and various blog posts — one aspect where TensorFlow absolutely shines
compared to other Deep learning software — I realized that such savers could
save weights and meta-data into checkpoint files. As of TensorFlow 1.8.0, they
are structured like this:
name.data-00000-of-00001
name.index
name.meta
where name is what we choose. We have data representing the actual weights,
index representing the connection between variable names and values (like a
dictionary), and meta representing various properties of the computational
graph. Then, by reconstructing (i.e., re-running) code that builds the same
network, it’s easy to get the same network running.
But then my main thought was: is it possible to just load a network in a new Python script without having to call any neural network construction code? Suppose I trained a really Deep Neural Network and saved the model into checkpoints. (Nowadays, this would be hundreds of layers, so it’s impractical with the tools I have access to, but never mind.) How would I load it in a new script and deploy it, without having to painstakingly reconstruct the network? And by “reconstruction” I specifically mean having to re-define the same variables (the names must match!!) and building the same neural network in the same exact layer order, etc.
The solution is to first use tf.train.import_meta_graph. Then, to fetch the
desired placeholders and operations, it is necessary to call
get_tensor_by_name from a TensorFlow graph.
I have written a proof of concept of the above high-level description in my
aptly-named “TensorFlow practice” GitHub code repository. The goal is to
train on (you guessed it) MNIST, save the model after each epoch, then load it
in a separate Python script, and check that each model gets exactly the same
test-time performance. (And it should be exact, since there’s no
stochasticity.) As a bonus, we’ll learn how to use tf.contrib.slim, one of the
many convenience wrapper libraries around stock TensorFlow to make it easier to
design and build Deep Neural Networks.
In my training code, I use the keras convenience method for loading in MNIST. As usual, I check the shapes of the training and testing data (and labels):
(60000, 28, 28) float64 # x_train
(60000,) uint8 # y_train
(10000, 28, 28) float64 # x_test
(10000,) uint8 # y_test
Whew, the usual sanity check passed.
Next, I use tf.slim to build a simple Convolutional Neural Network. Before
training, I always like to print the state of the tensors after each layer, to
ensure that the sizing and dimensions make sense. The resulting printout is
here, where each line indicates the value of a tensor after a layer has been
applied:
Tensor("images:0", shape=(?, 28, 28, 1), dtype=float32)
Tensor("Conv/Relu:0", shape=(?, 28, 28, 16), dtype=float32)
Tensor("MaxPool2D/MaxPool:0", shape=(?, 14, 14, 16), dtype=float32)
Tensor("Conv_1/Relu:0", shape=(?, 14, 14, 16), dtype=float32)
Tensor("MaxPool2D_1/MaxPool:0", shape=(?, 7, 7, 16), dtype=float32)
Tensor("Flatten/flatten/Reshape:0", shape=(?, 784), dtype=float32)
Tensor("fully_connected/Relu:0", shape=(?, 100), dtype=float32)
Tensor("fully_connected_1/Relu:0", shape=(?, 100), dtype=float32)
Tensor("fully_connected_2/BiasAdd:0", shape=(?, 10), dtype=float32)
For example, the inputs are each 28x28 images. Then, by passing them through a convolutional layer with 16 filters and with padding set to the same, we get an output that’s also 28x28 in the first two axis (ignoring the batch size axis) but which has 16 as the number of channels. Again, this makes sense.
During training, I get the following output, where I evaluate on the full test set after each epoch:
epoch, test_accuracy, test_loss
0, 0.065, 2.30308
1, 0.908, 0.31122
2, 0.936, 0.20877
3, 0.953, 0.15362
4, 0.961, 0.12030
5, 0.967, 0.10056
6, 0.972, 0.08706
7, 0.975, 0.07774
8, 0.977, 0.07102
9, 0.979, 0.06605
At the beginning, the test accuracy is just 0.065, which isn’t far from random guessing (0.1) since no training was applied. Then, after just one pass through the training data, accuracy is already over 90 percent. This is expected with MNIST; if anything, my learning rate was probably too small. Eventually, I get close to 98 percent.
More importantly for the purposes of this blog post, after each epoch ep, I
save the model using:
ckpt_name = "checkpoints/epoch"
saver.save(sess, ckpt_name, global_step=ep) # saver is a `tf.train.Saver`I now have all these saved models:
total 12M
-rw-rw-r-- 1 daniel daniel 71 Aug 17 17:07 checkpoint
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:06 epoch-0.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:06 epoch-0.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:06 epoch-0.meta
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:06 epoch-1.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:06 epoch-1.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:06 epoch-1.meta
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:06 epoch-2.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:06 epoch-2.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:06 epoch-2.meta
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:06 epoch-3.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:06 epoch-3.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:06 epoch-3.meta
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:06 epoch-4.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:06 epoch-4.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:06 epoch-4.meta
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:06 epoch-5.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:06 epoch-5.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:06 epoch-5.meta
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:06 epoch-6.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:06 epoch-6.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:06 epoch-6.meta
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:06 epoch-7.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:06 epoch-7.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:06 epoch-7.meta
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:06 epoch-8.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:06 epoch-8.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:06 epoch-8.meta
-rw-rw-r-- 1 daniel daniel 1.1M Aug 17 17:07 epoch-9.data-00000-of-00001
-rw-rw-r-- 1 daniel daniel 1.2K Aug 17 17:07 epoch-9.index
-rw-rw-r-- 1 daniel daniel 95K Aug 17 17:07 epoch-9.meta
In my loading/deployment code, I call this relevant code snippet for each epoch:
for ep in range(0,9):
# It's a two-step process. For restoring, don't include the stuff
# from the `data`, i.e. use `name`, not `name.data-00000-of-00001`.
sess = tf.Session()
saver = tf.train.import_meta_graph('checkpoints/epoch-{}.meta'.format(ep))
saver.restore(sess, 'checkpoints/epoch-{}'.format(ep))Next, we need to get references to placeholders and operations. Fortunately we can do precisely that using:
graph = tf.get_default_graph()
images_ph = graph.get_tensor_by_name("images:0")
labels_ph = graph.get_tensor_by_name("labels:0")
accuracy_op = graph.get_tensor_by_name("accuracy_op:0")
cross_entropy_op = graph.get_tensor_by_name("cross_entropy_op:0")Note that these names match the names I assigned during my training code, except
that I append an extra :0 at the end of each name. The importance of getting
names right is why I will start carefully naming TensorFlow variables in my
future code.
After using these same placeholders and operations, I get the following test-time output:
1, 0.908, 0.31122
2, 0.936, 0.20877
3, 0.953, 0.15362
4, 0.961, 0.12030
5, 0.967, 0.10056
6, 0.972, 0.08706
7, 0.975, 0.07774
8, 0.977, 0.07102
9, 0.979, 0.06605
(I skipped over epoch 0, as I didn’t save that model.)
Whew. The above accuracy and loss values exactly match. And thus, we now know how to load and use stored TensorFlow checkpoints without having to reconstruct the entire training graph. Achievement unlocked.
Presenting to AI4ALL
 I, trying to inspire some high-schoolers with the Toyota HSR.
I, trying to inspire some high-schoolers with the Toyota HSR.
Last Friday — my 26th birthday, actually — I had the opportunity to give a brief demonstration of our Toyota Human Support Robot (HSR) as part of the AI4ALL program at UC Berkeley. I provided some introductory remarks about the HSR, which is a home robot developed by Toyota with the goal of assisting the elderly in Japan and elsewhere. I then demonstrated the HSR in action by showing how it could reach to a grasp pose on the “bed-making” setup shown in the picture above, and then pull the sheet to a target. (Our robot has some issues with its camera perception, so the demonstration wasn’t as complete as I would have liked it to be, but I hope I still managed to inspired some of the kids.)
I then discussed some of the practical knowledge that I’ve learned over the last year when dealing with physical robots, such as: (1) robots will break down, (2) robots will break down, and (3) robots will break down. Finally, I answered any questions that the kids had, and allowed a few volunteers to play around with the joystick to teleoperate the robot.
Some context: the Berkeley-specific AI4ALL session is a five-day program, from 8:00am to 5:00pm, at the UC Berkeley campus, and is designed to introduce Artificial Intelligence to socioeconomically disadvantaged kids (e.g., those who qualify for free school lunch) in the 9th and 10th grade. Attendance to AI4ALL is free, and admission is based on math ability. I am not part of the official committee for AI4ALL so I don’t know much beyond what is listed on their website. Last week was the second instance of AI4ALL, continuing last year’s trend, and involved about 25 high-school students.
AI4ALL isn’t just a Berkeley thing; there are also versions of it at Stanford, CMU, and other top universities. I took a skim at the program websites, and the Stanford version is a 3-week residential program, so it probably has slightly more to offer. Still, I hope we at Berkeley were at least able to inspire some of the next generation of potential AI employees, researchers, and entrepreneurs.
On a more personal note, this was my first time giving a real robot demonstration to an audience that didn’t consist of research collaborators. I enjoyed this, and hope to do more in the coming years. These are the kind of things one just cannot do with theoretical or simulator-based research.