My Blog Posts, in Reverse Chronological Order
subscribe via RSS or by signing up with your email here.
Max Welling's "Intelligence Per Kilowatt-Hour"
I recently took the time to watch Max Welling’s excellent and thought-provoking ICML keynote. You can view part 1 and part 2 on YouTube. The video quality is low, but at least the text on the slides is readable. I don’t think slides are accessible anywhere; I don’t see them on his Amsterdam website.
As you can tell from his biography, Welling comes from a physics background and spent undergraduate and graduate school in Amsterdam studying under a Nobel Laureate, and this background is reflected in the talk.
I will get to the main points of the keynote, but the main reason why I for once managed to watch a keynote talk (rather than partake in the usual “Oh, I’ll watch it later when I have time …” and then forgetting about it1) is that I wanted to test out a new pair of hearing aids and the microphone that came with it. I am testing the ReSound ENZO 3D hearing aids, along with the accompanying ReSound Multi Mic.
That microphone will use a 3.5mm mini jack cable to connect to an audio source, such as my laptop. Then, with an app through my iPhone, I can switch my hearing aid’s mode to “Stream,” meaning that the sound from my laptop or audio source, which is connected to the Multi Mic, goes directly into my hearing aids. In other words, it’s like a wireless headphone. I have long wanted to test out something like this, but never had the chance to do so until the appropriate technology came for the kind of hearing aid power I need.
The one downside, I suppose, of this is that if I were to listen to music while I work, there wouldn’t be any headphones visible (either wired or wireless) as would be the case with other students. This means someone looking at me might try and talk to me, and think I am ignoring him or her if I do not respond due to hearing only the sound streaming through the microphone. I will need to plan this out if I end up getting this microphone.
But anyway, back to the keynote. Welling titled the talk as “Intelligence Per Kilowatt-Hour” and pointed out early that this could also be expressed as the following equation:
Free Energy = Energy - Entropy
After some high-level physics comments, such as connecting gravity, entropy, and the second law of thermodynamics, Welling moved on to discuss more familiar2 territory to me: Bayes’ Rule, which we should all know by now. In his notation:
\[P(X) = \int d\Theta P(\Theta,X) = \int d\Theta P(\Theta)P(X|\Theta)\] \[P(\Theta|X) = \frac{P(X|\Theta)P(\Theta)}{P(X)}\]Clearly, there’s nothing surprising here.
He then brought up Geoffrey Hinton as the last of his heroes in the introductory parts of the talks, along with the two papers:
- Keeping the Neural Networks Simple by Minimizing the Description Length of the Weights (1993)
- A View of the EM Algorithm that Justifies Incremental, Sparse, and other Variants (1998)
I am aware of these papers, but I just cannot find time to read them in detail. Hopefully I will, someday. Hey, if I can watch Welling’s keynote and blog about it, then I can probably find time to read a paper.
Probably an important, relevant bound to know is:
\[\begin{align} \log P(X) &= \int d\Theta Q(\Theta) \log P(X|\Theta) - KL[Q(\Theta)\|P(\Theta)] + KL[Q(\Theta)\|P(\Theta|X)] \\ &\ge \int d\Theta Q(\Theta) \log P(X|\Theta) - KL[Q(\Theta)\|P(\Theta)] \\ &= \int d\Theta Q(\Theta) \log P(X|\Theta)P(\Theta) -\int d\Theta Q(\Theta) \log Q(\Theta) \end{align}\]where the equality to lower bound results because we ignore a KL divergence term which is always non-negative. The right hand side of the final line can be re-thought as negative energy plus entropy.
In the context of discussing the above math, Welling talked about intractable distributions, a thorn in the side of many statisticians and machine learning practitioners. Thus, he discussed two broad classes of techniques to approximate intractable distributions: MCMC and Variational methods. The good news is that I understood this because John Canny and I wrote a blog post about this last year on the Berkeley AI Research Blog3.
Welling began with his seminal work: Stochastic Gradient Langevin Dynamics, which gives us a way to use minibatches for large-scale MCMC. I won’t belabor the details of this, since I wrote a blog post (on this blog!) two years ago about this very concept. Here’s the relevant equation and method reproduced here, for completeness:
\[\theta_{t+1} = \theta_t + \frac{\epsilon_t}{2}\left(\nabla \log p(\theta_t) + \frac{N}{n} \sum_{i=1}^n \nabla \log p(x_{ti} \mid \theta_t)\right) + \eta_t\] \[\eta_t \sim \mathcal{N}(0, \epsilon_t)\]where we need \(\epsilon_t\) to vary and decrease towards zero, among other technical requirements. Incidentally, I like how he says: “sample from the true posterior.” This is what I say in my talks.
Afterwards, he discussed some of the great work that he has done in Variational Bayesian Learning. I’m most aware of him and his student, Durk Kingma, introducing Variational Autoencoders for generative modeling. That paper also popularized what’s known as the reparameterization trick in statistics. In Welling’s notation,
\[\Theta = f(\Omega, \Phi) \quad {\rm s.t.} \quad Q_{\Phi}(\Theta)d(\Theta) = P_0(\Omega)d\Omega\]I will discuss this in more detail, I swear. I have a blog post about the math here but it’s languished in my drafts folder for months.
In addition to the general math overview, Welling discussed:
- How the reparameterization trick helps to decrease variance in REINFORCE. I’m not totally sure about the details, but again, I’ll have to mention it in my perpetually-in-progress draft blog post previously mentioned.
- The local reparameterization trick. I see. What’s next, the tiny reparameterization trick?
- That we need to make Deep Learning more efficient. Right now, our path is not sustainable. That’s a solid argument; Google can’t keep putting this much energy into AI projects forever. To do this, we can remove parameters or quantize them. For the latter, this is like reducing them from float32 to int, to cut down on memory usage. At the extreme, we can use binary neural networks.
- Welling also mentioned that AI will move to the edge. This means moving from servers with massive computational power to everyday smart devices with lower compute and power. In fact, his example was smart hearing aids, which I found amusing since, as you know, the main motivation for me watching this video was precisely to test out a new pair of hearing aids! I don’t think there is AI in the ReSound ENZO 3D.
The last point above about AI moving to the edge is what motivates the title of the talk. Since we are compute- and resource-constrained on the edge, it is necessary to extract the benefits of AI efficiently, hence AI per kilowatt hour.
Towards the end of the talk, Welling brought up more recent work on Bayesian Deep Learning for model compression, including:
- Probabilistic Binary Networks
- Differentiable Quantization
- Spiking Neural Networks
These look like some impressive bits of research, especially spiking neural networks because the name sounds cool. I wish I had time to read these papers and blog about them, but Welling gave juuuuuuust enough information that I think I can give one or two sentence explanations of the research contribution.
Welling concluded with a few semi-serious comments, such as inquiring about the question of life (OK, seriously?), and then … oh yeah, that Qualcomm AI is hiring (OK, seriously again?).
Well, advertising aside — which to be fair, lots of professors do in their talks if they’re part of an industrial AI lab — the talk was thought-provoking to me because it forced me to consider energy-efficiency if we are going to make further progress in AI and to also ensure that we can maximally extract AI utility in compute-limited devices. These are things worth thinking about at a high level for our current and future AI projects.
-
To be fair, this happens all the time when I try and write long, lengthy blog posts, but then realize I will never have the effort to fix up the post to make it acceptable for the wider world. ↩
-
I am trying to self-study physics. Unfortunately, it is proceeding at a snail’s pace. ↩
-
John Canny also comes from a theoretical physics background, so I bet he would like Welling’s talk. ↩
Pre-Conference Logistics Checklist
I am finally attending more conferences and by now it’s become clear that I need a more formal checklist for future conferences, since there were many things I should have done further in advance. Hopefully this checklist will serve me well for future events.
-
Start planning for travel (plane tickets, hotels, etc.) no later than the point when I know I am attending for sure. The conferences I would attend mandate that someone from the author list of an accepted paper has to attend in order for the paper to appear in the “proceedings.” It is very likely, though, that authors can tell if their work will be accepted before the actual decision gets sent to them 2-4 months before the conference. This is especially true for conferences that offer multiple rounds of reviews, since the scores from the first set of reviews usually remain the same even after rebuttals. Thus, any planning of any sort should start before the final paper acceptance decision.
-
Email other Berkeley students or those who I know about the possibilities of having joint activities or a group hotel reservation. I would rather not miss out on any gatherings among awesome people (i.e., Berkeley students). For this, it’s helpful to know if or when the conference offers lunches and dinners. If the conference is smaller or less popular among Berkeley people, ask the organizers to add it to ConferenceShare and search there.
-
Normally, in order to get better rates, we book hotel rooms through the conference website, or though a related source (e.g., the “Federated AI Meeting” portal for ICML/IJCAI/etc.) which is not the official hotel website. Be extremely careful, however, if trying to upgrade or adjust the room. I nearly got burned by this in IJCAI because I think an external source canceled one of my original hotel reservations after I had upgraded the room by emailing the hotel directly. Lesson: always, always ask for confirmation of my room, and do this multiple times, spaced within a few weeks to avoid angry hotel receptionists.
-
Regarding academic accommodation (e.g., sign language interpreter or captioning), first figure out what I am doing. This itself is nontrivial, owing to the tradeoffs among different techniques and considering the conference location. Then, draft a “Conference XYZ Planning Logistics for [Insert Dates Here]” and email the details to Berkeley’s DSP. Email them repeatedly, every three days at minimum, demanding at minimum a confirmation that they have read my email and are doing something. I apologize in advance to Berkeley’s DSP for clogging up their inboxes.
-
If the accommodations will involve additional people attending the venue, which is nearly always the case, then get them in touch with the conference organizers so that they can get badges with name tags, and to ask about any potentially relevant information (e.g., space limitations in certain social events).
-
One thing I need to start doing is contacting the conference venue about the services they offer. For instance, many venues nowadays offer services such as hearing loops or captioning, which could augment or mix with those from Berkeley’s DSP. It’s also important to get a sense of how easily the lights or speakers can be adjusted in rooms. IJCAI was held at Stockholmsmässan, and the good news is that in the main lecture hall, it was straightforward for an IT employee to adjust the lighting to make the sign language interpreters visible (the room gets dark when speakers present), and to provide them with special microphones.
-
Attire: don’t bring two business suits. One is enough, if I want to bring one at all. Two simply takes too much space in a small suitcase, and there’s no way I’m risking checked-in luggage. Always bring an equal amount of undershirts which double as workout clothes, and make sure the hotel I’m in actually has a fitness center! Finally, bring two pairs of shoes: one for walking, one for running.
I likely won’t be attending conferences until the spring or summer of 2019, so best to jot these items down before forgetting them.
Quick Overview of the 27th International Joint Conference on Artificial Intelligence (IJCAI), with Photos
I recently attended the 27th International Joint Conference on Artificial Intelligence (IJCAI) in Stockholm, Sweden. Unlike what I did for UAI 2017 and ICRA 2018, I won’t be able to write daily blog posts about the conference. In part, this is because I got struck by some weird flu-like and fever symptoms on my flight to Sweden, which sapped my energy. I thought I was clever when my original plan was to rig my sleep schedule so that I’d skip sleep during my last night in the United States, and then get a full 8-hours’ worth of sleep on the flight to Stockholm, upon which I’d arrive at 7:00am (in Stockholm time) feeling refreshed. Unfortunately, my lack of sleep probably exacerbated the unexpected illness, so that plan went out of whack.
On a more positive note, here were some of the highlights of IJCAI. I’ll split this into three main sections, followed by some concluding comments and the photos I took.
Keynote Talks (a.k.a., “Invited Talks”):
- I enjoyed Yann LeCun’s keynote on Deep Learning. Because it’s Yann LeCun and Deep Learning.
- Jean-François Bonnefon’s gave a thought-providing talk about The Moral Machine Experiment. Think of what happens with a self-driving car. Suppose it’s in a situation when people are blocking the car’s way, but it’s going too fast to stop. Either it continues going forward (and kills the people in front of it) or it swerves and hits a nearby wall (and kills the passengers). What characteristics of the passengers or pedestrians would cause us to favor which of the two groups to kill?
- There was also a great talk about “Markets Without Money” by Nicole Immorlica of Microsoft Research. It was a high-level talk discussing some of the theoretical work tying together economics and computer science, about some of the markets we’re engaged in, but which aren’t money-centric. I was reminded of many related books that I’ve been reading about platforms.
- On the last day there were four invited talks: Andrew Barto for a career achievement award (postponed one year as he was supposed to give it last year), Jitendra Malik for this year’s career achievement award, Milind Tambe for the John McCarthy award, and Stefano Ermon for the IJCAI Computers and Thought award. I enjoyed all the talks.
Workshops, Tutorials, Various Sessions, and Other Stuff:
- IJCAI had several parallel workshops and tutorials on the first three days, which were co-located with ICML and other AI conferences. I only attended the last day since I had to recover from my illness, and on that day, I attended tutorials about AI and the Law and Predicting Human Decision-Making. They were interesting, though I admit that it was hard to focus after two or three hours. The one on human decision-making, as I predicted, brought up Daniel Kahneman’s 2011 magnus opus Thinking, Fast and Slow, one of my favorite books of all time.
- There was a crowd-captivating robotics performance during the opening remarks before Yann LeCun’s keynote; a mini-robot and a human actor moved alongside while performing a slow dance-like motion. See my photos — it was entertaining! I’m not sure how the robot was able to conduct such dexterous movements.
- On the penultimate day, there were back-to-back sessions about AI in Europe. The first featured a lively panel of seven Europeans who opinionated about Europe’s strengths and weaknesses in AI, and what it can do in the future. Several common themes stood out: the need to prevent “brain drain” to the United States and the need for more investment in AI. Notably, the panel’s only mention of Donald Trump was when Max Tegmark (himself one of Europe’s “brain drains!”) criticized America’s leadership and called for Europe to resist Trump when needed. The second session was about Europe’s current AI strategy and consisted of four consecutive talks. They were a bit dry and the speakers spoke with a flat tone while reading directly from text on the slides, so I left early to attend the student reception.
- Unique to IJCAI, it hosts a “Sister Track for Best Papers.” Authors of papers that won some kind of award in other AI conferences are invited to speak about their work in IJCAI. This is actually why I was there, due to my UAI paper, so I’m grateful that IJCAI includes such sessions.
- IJCAI also has early career talks. For these, pre-tenure faculty come and give 25-minute talks on their research. This was the most common session I attended (not including keynotes), because faculty tend to be better at giving presentations than graduate students, who make up the bulk of the speakers in most sessions.
Our Social Events:
- A visit to Skansen, a large open museum, where we could see what a Swedish village might have looked like many years ago. It is a pleasantly surprising mix of a zoo, a hodgepodge of old architecture, and employees acting as ancient Swedish citizens. The Skansen event was joint with ICML and the other co-located conferences, so I saw several Berkeley people (ICML is more popular among us). The food was mediocre, but this was countered by an insane amount of Champagne. Sadly, I was still recovering from my illness and couldn’t drink any.
- A reception at City Hall, which is most famous for hosting the annual Nobel Prize ceremony. The city of Stockholm actually paid for us, so it wasn’t included as part of any IJCAI registration fees. (They must really want AI researchers to like Sweden!) The bad news? There were over 2000 IJCAI registrants, but City Hall has a strict capacity of 1200, so the only people who could get in were those that skipped the last session of talks that day. I felt this was unfair to those speakers, and I hope if similar scenarios happen in future iterations, IJCAI can hold a lottery and offer a second banquet for those who don’t get in the first one.
- A conference banquet, held at the Vasa Museum near Skansen. I was excited about attending, but alas, it was closed to students. This was unclear from the conference website and program, and judging from what others said on the Whova app for the conference, I wasn’t the only one confused. That this was not open to students caused one of the faculty attending to boycott the dinner, according to his comments on Whova.
- To make up for that (I suppose?), there was a student reception the next day, open to students only (obviously). As usual, the wine and beer was great, though the food itself — served cocktail-style — was short of what would qualify as a full dinner. There was a minor steak dish, along with some green soup for vegetarians, but I don’t think the vegetarians were pleased with the options available.
- A closing reception, at the very end of the conference. It was in the conference venue and offered the usual wine, beer, non-alcoholic drinks, and some small food dishes. There wasn’t much variety in the food offering.
Since I blogged about ICRA 2018 at length, I suppose it’s inevitable to make a (necessarily incomplete) comparison among the two.
In terms of food, ICRA completely outclasses IJCAI. ICRA included lunch (whereas IJCAI didn’t) and the ICRA evening receptions all had far richer food offerings than IJCAI’s. The coffee breaks for ICRA also had better food and drink, including free lattes (ah, the memories…). It looks like the higher registration fees we pay for ICRA are reflected in the proportionately better food and drink quality. The exception may be the alcoholic beverages; the offerings from ICRA and IJCAI seemed to be comparable, though I’ll add that I still haven’t developed the ability to tell great wine from really, really great wine.
ICRA also has a better schedule in that poster sessions were clearly labeled in the schedule, whereas IJCAI’s weren’t explicitly scheduled, meaning that it was technically “all day”. Finally, I think the venue for ICRA — the Brisbane Convention & Exhibition Centre — is better designed than Stockholmsmässan, and furthermore, there’s more interesting stuff within walking distance to Brisbane’s convention. (To mitigate this, IJCAI wisely offered a public transportation card for all attendees.)
That’s not to say ICRA was superior in every metric — far from it! The main advantage of IJCAI is probably that we get to see more of the city itself, as I mention in the social events above.
Here are the photos I took while I was at IJCAI, which I’ve hosted in my Flickr account. (For future conferences I will probably host pictures on Flickr, since I’ve used up a dangerously high amount of my memory allocation for hosting on GitHub.) There are about 150 of them in the album, and I hope you enjoy them.
May 2020 update. The photos were originally private. I have changed the permission settings.
Actor-Critic Methods: A3C and A2C
Actor-critic methods are a popular deep reinforcement learning algorithm, and having a solid foundation of these is critical to understand the current research frontier. The term “actor-critic” is best thought of as a framework or a class of algorithms satisfying the criteria that there exists parameterized actors and critics. The actor is the policy \(\pi_{\theta}(a \mid s)\) with parameters \(\theta\) which conducts actions in an environment. The critic computes value functions to help assist the actor in learning. These are usually the state value, state-action value, or advantage value, denoted as \(V(s)\), \(Q(s,a)\), and \(A(s,a)\), respectively.
I suggest that the most basic actor-critic method (beyond the tabular case) is vanilla policy gradients with a learned baseline function.1 Here’s an overview of this algorithm:

The basic vanilla policy gradients algorithm. Credit: John Schulman.
I also reviewed policy gradients in an older blog post, so I won’t repeat the details.2 I used expected values in that post, but in practical implementations, you’ll just take the saved rollouts to approximate the expectation as in the image above. The main point to understand here is that an unbiased estimate of the policy gradient can be done without the learned baseline \(b(s_t)\) (or more formally, \(b_{\theta_C}(s_t)\) for parameters \(\theta_C\)) by just using \(R_t\), but this estimate performs poorly in practice. Hence why, people virtually always apply a baseline.
My last statement is somewhat misleading. Yes, people apply learned baseline functions, but I would argue that the more important thing is to ditch vanilla policy gradients all together and use a more sophisticated framework of actor critic methods, called A3C and popularized from the corresponding DeepMind ICML 2016 paper.3 In fact, when people refer to “actor-critic” nowadays, I think this paper is often the associated reference, and one can probably view it as the largest or most popular subset of actor-critic methods. This is despite how the popular DDPG algorithm is also an actor-critic method, perhaps because its is more commonly thought of as the continuous control analogue of DQN, which isn’t actor-critic as the critic (Q-network) suffices to determine the policy; just take a softmax and pick the action maximizing the Q-value.
A3C stands for Asynchronous Advantage Actor Critic. At a high level, here’s what the name means:
-
Asynchronous: because the algorithm involves executing a set of environments in parallel (ideally, on different cores4 in a CPU) to increase the diversity of training data, and with gradient updates performed in a Hogwild! style procedure. No experience replay is needed, though one could add it if desired (this is precisely the ACER algorithm).
-
Advantage: because the policy gradient updates are done using the advantage function; DeepMind specifically used \(n\)-step returns.
-
Actor: because this is an actor-critic method which involves a policy that updates with the help of learned state-value functions.
You can see what the algorithm looks like mathematically in the paper and in numerous blog posts online. For me, a visual diagram helps. Here’s what I came up with:
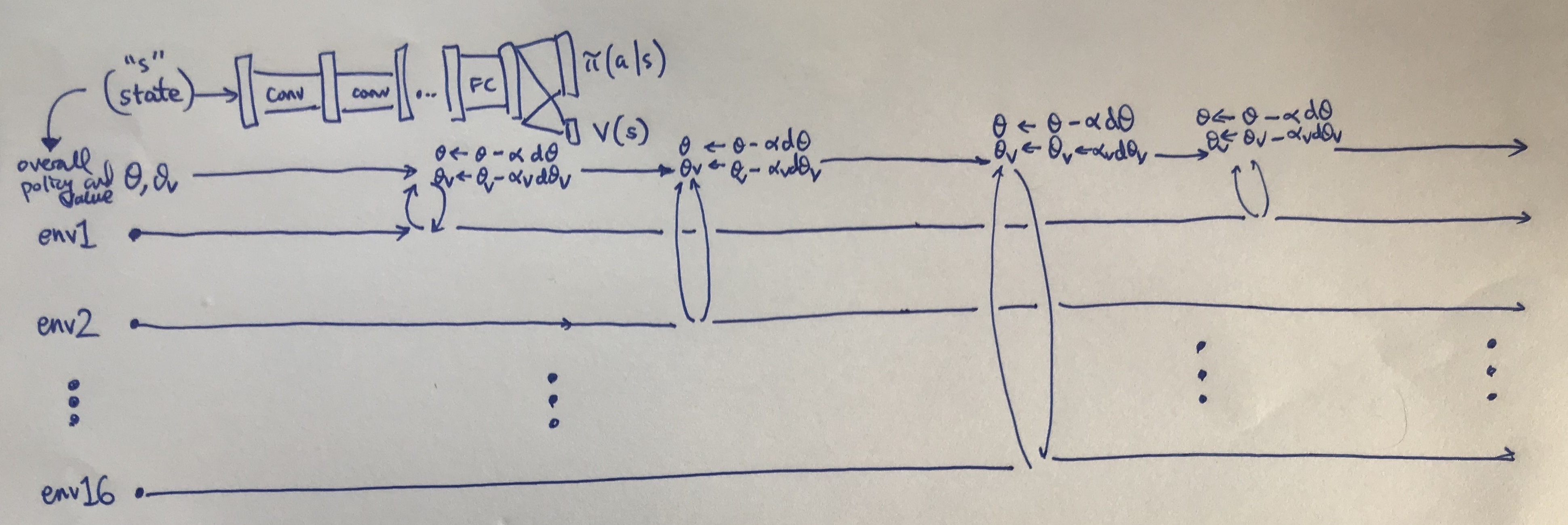 My visualization of how A3C works.
My visualization of how A3C works.
A few points:
-
I’m using 16 environments in parallel, since that’s what DeepMind used. I suppose I could use close to this in modern machines since many CPUs have four or six cores, and with hyperthreading we get double that. Of course, it might be easier to simply use Amazon Web Services … and incidentally, no GPU is needed.
-
I share the value function and the policy in the same way DeepMind did, but for generality I keep the gradient updates separate for \(\theta\) (the policy) and \(\theta_v\) (the value function) and have respective learning rates \(\alpha\) and \(\alpha_v\). In TensorFlow code, I would watch out for the variables that my optimizers update.
-
The policy has an extra entropy bonus regularizer that is embedded in the \(d\theta\) term to encourage exploration.
-
The updates are done in Hogwild! fashion, though nothing I drew in the figure above actually shows that, since it assumes that different threads reached their “update point” at different times and update separately. Hogwild! would apply when two or more threads call a gradient update to the shared parameter simultaneously, raising the possibility of one thread overwriting another. This shouldn’t happen too often, since there’s only 16 threads — my intuition is that it’d be a lot worse with orders of magnitude more threads — but the point is even if they do, things should be fine in the long run.
-
The advantage is computed using \(n\)-step returns with something known as the forward view, rather than the backward view, as done with eligibility traces. If you are unfamiliar with “eligibility traces” then I recommend reading Sutton and Barto’s online reinforcement learning textbook.
I’ll expand on the last point a bit, drawing upon some math from my older blog post about Generalized Advantage Estimation. The point here is to use more than just the one-step return from the standard Q-value definition. Despite the addition of more time steps, we still get an approximation of the advantage function (and arguably a better one). At each time step, we can accumulate a gradient, and at the designated stopping point, that thread pushes the updates to the central parameter server. Even though I’m sure all the thread’s gradients are highly correlated, the different threads in use should suffice for a diverse set of gradients.
To be clear about this, for some interval where the thread’s agent takes steps, we get rewards \(r_1, r_2, \ldots, r_k\), where upon reaching the \(k\)-th step, the agent stopped, either due to reaching a terminal state or because it’s reached the human-designated maximum number of steps before an update. Then, for the advantage estimate, we go backwards in time to accumulate the discounted reward component. For the last time step, we’d get
\[A(s_k,a_k) \approx \Big( r_k + \gamma V(s_{k+1};\theta_v) \Big) - V(s_k ; \theta_v)\]for the penultimate step, we’d get:
\[A(s_{k-1},a_{k-1}) \approx \Big( r_{k-1} + \gamma r_k + \gamma^2 V(s_{k+1};\theta_v) \Big) - V(s_{k-1} ; \theta_v)\]then the next:
\[A(s_{k-2},a_{k-2}) \approx \Big( r_{k-2} + \gamma r_{k-1} + \gamma^2 r_k + \gamma^3 V(s_{k+1};\theta_v) \Big) - V(s_{k-2} ; \theta_v)\]and so on. See the pseudocode in the A3C paper if this is not clear.
The rewards were already determined from executing trajectories in the environment, and by summing them this way, we get the empirical advantage estimate. The value function which gets subtracted has subscripts that match the advantage (because \(A(s,a) = Q(s,a)-V(s)\)), but not the value function used for the \(n\)-step return. Incidentally, that value will often be zero, and it should be zero if this trajectory ended due to a terminal state.
Now let’s talk about A2C: Advantage Actor Critic. Given the name (A2C vs A3C) why am I discussing A2C after A3C if it seems like it might be simpler? Ah, it turns out that (from OpenAI):
After reading the paper, AI researchers wondered whether the asynchrony led to improved performance (e.g. “perhaps the added noise would provide some regularization or exploration?“), or if it was just an implementation detail that allowed for faster training with a CPU-based implementation.
As an alternative to the asynchronous implementation, researchers found you can write a synchronous, deterministic implementation that waits for each actor to finish its segment of experience before performing an update, averaging over all of the actors.
Thus, think of the figure I have above, but with all 16 of the threads waiting until they all have an update to perform. Then we average gradients over the 16 threads with one update to the network(s). Indeed, this should be more effective due to larger batch sizes.
In the OpenAI baselines repository, the A2C implementation is nicely split into four clear scripts:
-
The main call,
run_atari.py, in which we supply the type of policy and learning rate we want, along with the actual (Atari) environment. By default, the code sets the number of CPUs (i.e., number of environments) to 16 and then creates a vector of 16 standard gym environments, each specified by a unique integer rank. I think the rank is mostly for logging purposes, as they don’t seem to be usingmpi4pyfor the Atari games. The environments and CPUs utilize the Pythonmultiprocessinglibrary. -
Building policies (
policies.py), for the agent. These build the TensorFlow computational graphs and use CNNs or LSTMs as in the A3C paper. -
The actual algorithm (
a2c.py), with alearnmethod that takes the policy function (frompolicies.py) as input. It uses aModelclass for the overall model and aRunnerclass to handle the different environments executing in parallel. When the runner takes a step, this performs a step for each of the 16 environments. -
Utilities (
utils.py), since helper and logger methods help make any modern DeepRL algorithm easier to implement.
The environment steps are still a CPU-bound bottleneck, though. Nonetheless, I think A2C is likely my algorithm of choice over A3C for actor-critic based methods.
Update: as of September 2018, the baselines code has been refactored. In
particular, there is now an algorithm-agnostic run script that gets
called, and they moved some of the policy-building (i.e., neural network
building) code into the common sub-package. Despite the changes, the general
structure of their A2C algorithm is consistent with what I’ve written above.
Feel free to check out my other blog post which describes some of these
changes in more detail.
-
It’s still unclear to me if the term “vanilla policy gradients” (which should be the same as “REINFORCE”) includes the learned value function which determines the state-dependent baseline. Different sources I’ve read say different things, in part because I think vanilla policy gradients just doesn’t work unless you add in the baseline, as in the image I showed earlier. (And even then, it’s still bad.) Fortunately, my reading references are in agreement that once you start including any sort of learned value function for reducing gradient variance, that’s a critic, and hence an actor-critic method. ↩
-
I also noticed that on Lil’log, there’s an excellent blog post on various policy policy algorithms. I was going to write a post like this, but looks like Lilian Weng beat me to it. I’ve added Lil’Log to my bookmarks. ↩
-
The A3C paper already has 726 citations as of the writing of this blog post. I wonder if it was more deserving of the ICML 2016 best paper award than the other RL DeepMind winner, Dueling Architectures? Don’t get me wrong; both papers are great, but the A3C one seems to have had more research impact, which is whole the point, right? ↩
-
If one is using a CPU that enables hyperthreading, which is likely the case for those with modern machines, then perhaps this enables twice the number of parallel environments? I think this is the case, but I wouldn’t bet my life on it. ↩
Papers That Have Cited Policy Distillation
About a week and a half ago, I carefully read the Policy Distillation paper from DeepMind. The algorithm is easy to understand yet surprisingly effective. The basic idea is to have student and teacher agents (typically parameterized as neural networks) acting on an environment, such as the Atari 2600 games. The teacher is already skilled at the game, but the student isn’t, and need to learn somehow. Rather than run standard deep reinforcement learning, DeepMind showed that simply running supervised learning where the student trains its network to match a (tempered) softmax of the Q-values of the teacher is sufficient to learn how to play an Atari 2600 game. It’s surprising that this works; for one, Q-values are not even a probability distribution, so it’s not straightforward to conclude that a student trained to match the softmaxes would be able to learn a sequential decision-making task.
It was published in ICLR 2016, and one of the papers that cited this was Born Again Neural Networks (to appear in ICML 2018), a paper which I blogged about recently. The algorithms in these two papers are similar, and they apply in the reinforcement learning (PD) and supervised learning (BANN) domains.
After reading both papers, I developed the urge to understand all the Policy Distillation follow-up work. Thus, I turned to Google Scholar, one of the greatest research conveniences of modern times; as of this writing, the Policy Distillation paper has 68 citations. (Google Scholar sometimes has a delay in registering certain citations, and it also lists PhD theses and textbooks, so the previous sentence isn’t entirely accurate, but it’s close enough.)
I resolved to understand the main idea of every paper that cited Policy Distillation, especially with how relevant the paper is to the algorithm. I wanted to understand if papers directly extended the algorithm, or if they simply cited it as related work to try and boost up the citation count for DeepMind.
I have never done this before to a paper with more than 15 Google Scholar citations, so this was new to me. After spending a week and a half on this, I think I managed to get the gist of Policy Distillation’s “follow-up space.” You can see my notes in this shareable PDF which I’ve hosted on Dropbox. Feel free to send me recommendations about other papers I should read!
Born Again Neural Networks
I recently read Born Again Neural Networks (to appear at ICML 2018) and enjoyed the paper. Why? First, the title is cool. Second, it’s related to the broader topics of knowledge distillation and machine teaching that I have been gravitating to lately. The purpose of this blog post is primarily to review the math in Section 3. To start, let’s briefly review the high-level ideas of the paper.
-
It analyzes knowledge transfer between teacher and student neural networks, where (critically) the two networks are identically parameterized. Hence, it is slightly different from prior work in knowledge distillation which attempts to compress a teacher model into a smaller student model (typically trained by matching teacher logits). Incidentally, this means experiments can disentangle the effects of model compression.
-
Surprisingly, it shows that on vision- and language-based tasks, the student can outperform the teacher! All this requires is to (a) train the teacher until convergence, then (b) initialize a stuent and train it to predict the correct labels and to match the output distribution of the teacher.
-
The obvious next question is, can this process continue for generation after generation? The answer is, also surprisingly, yes, but to a point, and then one gets diminishing returns. After all, the process can’t continue indefinitely — eventually, there must be an upper bound on performance.
Now let’s go over Section 3. As a warning, notation is going to be a bit tricky/cumbersome but I will generally match what the paper uses and supplement it with my preferred notation for clarity.
We have \(\mathbf{z}\) and \(\mathbf{t}\) representing vectors corresponding to the student and teacher logits, respectively. I’ll try to stick to the convention of boldface meaning vectors, even if they have subscripts to them, which instead of components means that they are part of a sequence of such vectors. Hence, we have:
\[\mathbf{z} = \langle z_1, \ldots, z_n \rangle \in \mathbb{R}^n\]or we can also write \(\mathbf{z} = \mathbf{z}_k\) if we’re considering a minibatch \(\{\mathbf{z}_1, \ldots, \mathbf{z}_b\}\) of these vectors.
Let \(\mathbf{x}\) denote input samples (also vectors) and let \(Z=\sum_{k=1}^n e^{z_k}\) and \(T=\sum_{k=1}^n e^{t_k}\) to simplify the subsequent notation, and consider the cross entropy loss function
\[\mathcal{L}(\mathbf{x}_1, \mathbf{t}_1)= -\sum_{k=1}^{n} \left(\frac{e^{t_k}}{T} \log \frac{e^{z_k}}{Z} \right)\]which here corresponds to a single-sample cross entropy between the student logits and the teacher’s logits, assuming we’ve applied the usual softmax (with temperature one) to turn these into probability distributions. The teacher’s probability distribution could be a one-hot vector if we consider the “usual” classification problem, but the argument made in many knowledge distillation papers is that if we consider targets that are not one-hot, the student obtains richer information and achieves lower test error.
The derivative of the cross entropy with respect to a single output \(z_i\) is often applied as an exercise in neural network courses, and is good practice:
\[\begin{align*} \frac{\partial \mathcal{L}(\mathbf{x}_1, \mathbf{t}_1)}{\partial z_i} &= -\sum_{k=1}^{n} \frac{\partial}{\partial z_i} \left(\frac{e^{t_k}}{T} \log \frac{e^{z_k}}{Z} \right) \\ &= -\frac{\partial}{\partial z_i} \left(\frac{e^{t_i}}{T} \log \frac{e^{z_i}}{Z} \right) -\sum_{k=1, k\ne i}^{n} \frac{\partial}{\partial z_i} \left(\frac{e^{t_k}}{T} \log \frac{e^{z_k}}{Z} \right) \\ &= -\frac{e^t_i}{T}\frac{Z}{e^{z_i}} \left\{ \frac{\partial}{\partial z_i} \frac{e^{z_i}}{T} \right\} -\sum_{k=1, k\ne i}^{n} \frac{e^{t_k}}{T} \frac{Z}{e^{z_k}} \left\{ \frac{\partial}{\partial z_i} \frac{e^{z_k}}{Z} \right\} \\ &= -\frac{e^{t_i}}{T}\left(1 - \frac{e^{z_i}}{Z}\right) + \sum_{k=1, k\ne i}^{n} \frac{e^{t_k}}{T} \frac{e^{z_k}}{Z} \\ &= \frac{e^{z_i}}{Z} \sum_{k=1}^n\frac{e^{t_k}}{T} - \frac{e^{t_i}}{T} \\ &= \frac{e^{z_i}}{Z} - \frac{e^{t_i}}{T} \end{align*}\]or \(q_i - p_i\) in the paper’s notation. (As a side note, I don’t understand why the paper uses \(\mathcal{L}_i\) with a subscript \(i\) when the loss is the same for all components?) We have \(i \in \{1, 2, \ldots, n\}\), and following the paper’s notation, let \(*\) represent the true label. Without loss of generality, though, we assume that \(n\) is always the appropriate label (just re-shuffle the labels as necessary) and now consider the more complete case of a minibatch with \(b\) elements and considering all the possible logits. We have:
\[\mathcal{L}(\mathbf{x}_1, \mathbf{t}_1, \ldots, \mathbf{x}_b, \mathbf{t}_b) = \frac{1}{b}\sum_{s=1}^b \mathcal{L}(\mathbf{x}_s, \mathbf{t}_s)\]and so the derivative we use is:
\[\frac{1}{b}\sum_{s=1}^b \sum_{i=1}^n \frac{\partial \mathcal{L}(\mathbf{x}_s,\mathbf{t}_s)}{\partial z_{i,s}} = \frac{1}{b}\sum_{s=1}^b (q_{*,s} - p_{*,s}) +\frac{1}{b} \sum_{s=1}^b \sum_{i=1}^{n-1} (q_{i,s} - p_{i,s})\]Just to be clear, we sum up across the minibatch and scale by \(1/b\), which is often done in practice so that gradient updates are independent of minibatch size. We also sum across the logits, which might seem odd but remember that the \(z_{i,s}\) terms are not neural network parameters (in which case we wouldn’t be summing them up) but are the outputs of the network. In backpropagation, computing the gradients with respect to weights requires computing derivatives with respect to network nodes, of which the \(z\)s (usually) form the final-layer of nodes, and the sum here arises from an application of the chain rule.
Indeed, as the paper claims, if we have the ground-truth label \(y_{*,s} = 1\) then the first term is:
\[\frac{1}{b}\sum_{s=1}^b (q_{*,s} - p_{*,s}y_{*,s})\]and thus the output of the teacher, \(p_{*,s}\) is a weighting factor on the original ground-truth label. If we were doing the normal one-hot target, then the above is the gradient assuming \(p_{*,s}=1\), and it gets closer and closer to it the more confident the teacher gets. Again, all of this seems reasonable.
The paper also argues that this is related to importance weighting of the samples:
\[\frac{1}{b}\sum_{s=1}^b \frac{p_{*,s}}{\sum_{u=1}^b p_{*,u}} (q_{*,s} - y_{*,s})\]So the question is, does knowledge distillation (called “dark knowledge”) from (Hinton et al., 2014) work because it is performing a version of importance weighting? And by “a version of” I assume the paper refers to this because it seems like the \(q_{*,s}\) is included in importance weighting, but not in their interpretation of the gradient.
Of course, it could also work due to to the information here:
\[\frac{1}{b} \sum_{s=1}^b \sum_{i=1}^{n-1} (q_{i,s} - p_{i,s})\]which is in the “wrong” labels. This is the claim made by (Hinton et al., 2014), though it was not backed up by much evidence. It would be interesting to see the relative contribution of these two gradients in these refined, more sophisticated experiments with ResNets and DenseNets. How do we do that? The authors apply two evaluation metrics:
- Confidence Weighted by Teacher Max (CWTM): One which “formally” applies importance weighting with the argmax of the teacher.
- Dark Knowledge with Permuted Predictions (DKPP): One which permutes the non-argmax labels.
These techniques apply the argmax of the teacher, not the ground-truth label as discussed earlier. Otherwise, we might as well not be doing machine teaching.
It appears that if CWTM performs very well, one can conclude most of the gains are from the importance weighting scheme. If not, then it is the information in the non-argmax labels that is critical. A similar thing applies to DKPP, because if it performs well, then it can’t be due to the non-argmax labels. I was hoping to see a setup which could remove the importance weighting scheme, but I think that’s too embedded into the real/original training objective to disentangle.
The experiments systematically test a variety of setups (identical teacher and student architectures, ResNet teacher to DenseNet student, applying CWTM and DKPP, etc.). They claim improvements across different setups, validating their hypothesis.
Since I don’t have experience programming or using ResNets or DenseNets, it’s hard for me to fully internalize these results. Incidentally, all the values reported in the various tables appear to have been run with one random seed … which is extremely disconcerting to me. I think it would be advantageous to pick fewer of these experiment setups and run 50 seeds to see the level of significance. It would also make the results seem less like a laundry list.
It’s also disappointing to see the vast majority of the work here on CIFAR-100, which isn’t ImageNet-caliber. There’s a brief report on language modeling, but there needs to be far more.
Most of my criticisms are a matter of doing more training runs, which hopefully should be less problematic given more time and better computing power (the authors are affiliated with Amazon, after all…), so hopefully we will have stronger generalization claims in future work.
Update 29 May 2018: After reading the Policy Distillation paper, it looks like that paper already showed that matching a tempered softmax (of Q-values) from the teacher using the same architecture resulted in better performance in a deep reinforcement learning task. Given that reinforcement learning on Atari is arguably a harder problem than supervised learning of CIFAR-100 images, I’m honestly surprised that the Born Again Neural Networks paper got away without mentioning the Policy Distillation comparison in more detail, even when considering that the Q-values do not form a probability distribution.
Update 11 Nov 2020: Made some edits to the post for clarity. I also by now have significant experience with Res-Nets, making it easier to understand some of the results.
International Conference on Robotics and Automation (ICRA) 2018, Day 5 of 5
ICRA, like many academic conferences, schedules workshops and/or tutorials on the beginning and ending days. The 2018 edition was no exception, so for the fifth and final day, it offered about 10 workshops on a variety of topics. Succinctly, these are venues where a smaller group of researchers can discuss a common research sub-theme. Typically, workshops invite guest speakers and have their own poster sessions for works-in-progress or for shorter papers. These are less prestigious for full conference papers, which is why I don’t submit to workshops.
I attended most of the cognitive robotics workshop, since it included multi-robot and human-robot collaboration topics.
In the morning session, at least two of the guest speakers hinted some skepticism of Deep Learning. One, for instance, had this slide:
 An amusing slide at the day's workshop, featuring our very own Michael I.
Jordan.
An amusing slide at the day's workshop, featuring our very own Michael I.
Jordan.
which features Berkeley professor Michael I. Jordan’s (infamous) IEEE interview from four years ago. I would later get to meet the speaker when he walked over to me to inquire about the sign language interpreting services (yay, networking!!). I obviously did not have much to offer him in terms of technical advice, so I recommended that he read Michael I. Jordan’s recent Medium blog post about how the AI revolution “hasn’t happened yet.”
 The workshops were located near each other, so there were lots of people during
the food breaks.
The workshops were located near each other, so there were lots of people during
the food breaks.
I stayed for the full morning, and then for a few more talks in the afternoon. Eventually, I decided that the topics being presented — while interesting in their own right — were less relevant to my immediate research agenda than I had originally thought, so I left at about 2:00pm, my academic day done. For the rest of the afternoon, I stayed at the convention center and finally finished reading Enlightenment Now: The Case for Reason, Science, Humanism, and Progress.
While I was reading the book, I took part in my bad habit of checking my phone and social media. I had access to a Berkeley Facebook group chat, and it turns out that many of the students went traveling today to other areas in Brisbane.
Huh, I wonder if frequent academic conference attendees often skip the final “workshop day”? Just to be clear, I don’t mean these workshops are pointless or useless, but maybe the set of workshops is too heavily specialized or just not as interesting? I noticed a similar trend with UAI 2017, in that the final workshop day had relatively low attendance.
Now that the conference is over, my thoughts generally lean positive. Sure, there are nitpicks here and there: ICRA isn’t double-blind (which seems contrary to best science practices) and is pricey, as I mentioned in an earlier blog post. But as a consequence, ICRA is well-funded and exudes a sophisticated feel. The Brisbane venue was fantastic, as was the food and drink.
As always, I don’t think I networked enough, but I noticed that most Berkeley students ended up sticking with people they already knew, so maybe students don’t network as much as I thought?
I also have praise for my sign language interpreters, who tried hard. They also taught me about Auslan and the differences in sign language between Australia and the United States.
Well, that’s a wrap for ICRA. It is time for me to fly back to Vancouver and then to San Francisco … life will return to normal.
International Conference on Robotics and Automation (ICRA) 2018, Day 4 of 5
For the fourth day of ICRA, I again went running (for the fourth consecutive morning). This time, rather than run across the bridge to get to the South Bank, I ran on a long pathway that extended below some roads:
 Below the roads, there is a long paved path.
Below the roads, there is a long paved path.
Normally, I would feel hesitant to run underneath roads, since (at least in America) those places tend to be messy and populated by those with nowhere else to live. But the pathway here was surprisingly clean, and even at 6:30am, there were a considerable amount of walkers, runners, and bikers.
After my usual preparation, I went over to the conference for the 9:00am plenary talk, provided by Queensland Professor Mandyam Srinivasan.
 Professor Mandyam Srinivasan gave the third plenary talk for ICRA 2018.
Professor Mandyam Srinivasan gave the third plenary talk for ICRA 2018.
As usual, it was hard to follow the technical details of the talk. The good news is that the talk was high-level, probably (almost) as high-level as Professor Brooks’ talk, and certainly less technical than Raia Hadsell’s talk. I remember there being lots of videos in this plenary, which presents logistical “eye-challenges” since I have to figure out a delicate balance of looking at the video or the sign language interpreter.
Due to the biological nature of the talk, I also remembered Professor Robert Full’s thrilling keynote at the Bay Area Robotics Symposium last November. I wonder if those two have ever collaborated?
I stayed for the keynote talk after that, about soft robotics, and then we had the morning poster session. As usual, there was plenty of food and drink, and I had to resist the urge to keep making trips to the food tables. The food items followed the by-now familiar pattern of one “sweet” and one “savory” item:
 The food selection for today's morning poster session.
The food selection for today's morning poster session.
Later, we had the sixth and final poster session of the conference. The most interesting thing for me was … me, since that was when I presented my poster:

I, standing by my poster.
I stood there for 2.5 hours and talked with a number of conference attendees. Thankfully, none of the conversations were hostile or overly combative. People by and large seemed happy with what I was doing and saying. Also, my sign language interpreters finally had something to do during the poster sessions, since for the other five I had mostly been walking around without talking to people.
After the poster session, we had the farewell reception, which (as you can expect) was filled with lots of food and drinks. It took place in the plaza level of the convention center, which included an outside area along with several adjacent indoor rooms.
The food items included the usual bread, rice, and veggie dishes. For meat, we had salmon, sausages, and steak:
 Some delicious steaks being cooked.
Some delicious steaks being cooked.
The steak was delicious!
Interestingly enough, the “dessert” turned out to be fruit, breaking the trend from past meals.
 The farewell reception was crowded and dark, but the food was great.
The farewell reception was crowded and dark, but the food was great.
The reception was crowded with long lines for food, particularly for the steak (obviously!). The other food stations providing the salmon and sausages were frequently out of stock. These are, however, natural problems since most of us were grabbing as much meat as we could during our first trips to the food tables. Maybe we need an honor code about the amount of meat we consume?
As an aside, I think for future receptions, ICRA should provide backpack and poster tube storage. We had that yesterday for the conference dinner and it was very helpful since cocktail-style dining means both hands are often holding something — one for alcoholic beverages and the other for food. Since I had just finished presenting my poster/paper, I was awkwardly lugging around a poster tube. My sign language interpreter kindly offered to hold it for the time I was there.
Again, ICRA does not skimp on the food and beverages. Recall that we had a welcome reception (day one), a conference dinner (day three) and the farewell reception (day four, today), so it’s only the second and fifth evenings that the conference doesn’t officially sponsor a dinner.
International Conference on Robotics and Automation (ICRA) 2018, Day 3 of 5
For the third day, I did my usual morning run and then went to the conference. Today’s plenary was from DeepMind’s Raia Hadsell.
 DeepMind scientist Raia Hadsell giving the plenary talk on navigation.
DeepMind scientist Raia Hadsell giving the plenary talk on navigation.
Her talk was about navigation, and in the picture above you see her mention London taxi drivers. I was aware of them after reading Peak, and it was a pleasure to see the example appear here. On the other hand, I’m not sure how much we will be needing taxi drivers with Uber and automated cars so … maybe it’s not good try and be a taxi driver nowadays, even in London?
Anyway, a lot of the talk was focused on the navigation parts, and the emphasis was on real-world driving because, as Hadsell admitted, many of the examples that DeepMind uses in their papers (particularly, the Labyrinth) are simulated.
After her talk, we had Pieter Abbeel’s keynote on Learning to Learn. It was similar to his other talks, with discussion on the RL^2 algorithm and his other meta-learning papers.
The standard poster session followed Abbeel’s keynote. The food for the morning was a “vegetable bun” (some starch with veggies inside) and cupcakes.
I didn’t mention this in my last post, but ICRA also contains some late-breaking results, which you can see in the poster session here:
 ICRA contains late-breaking results, which you can see here behind the
pre-arranged dietary catering.
ICRA contains late-breaking results, which you can see here behind the
pre-arranged dietary catering.
This is necessary because ICRA has such a long turnaround time compared to other computer science conferences. The deadline for papers is September 15, with decisions by January 15, and then the conference in May 21-25. By contrast, ICML, NIPS, and other conferences have far faster turnaround times, so it’s good for ICRA to allocate a little space for outstanding yet recent results.
We had lunch, an afternoon keynote, another poster session, and so forth. I found a Berkeley student who I had been wanting to talk to for a while, so that was good. Other than that, I spent most of my time walking around, taking pictures of interesting posters (but not really talking to anyone) and then I sat down in a resting area and did some blogging.
Soon, the social highlight of the day would occur: the conference-sponsored, cocktail-style dinner. (Well, actually, there were two dinners, this one and a “Global Entrepreneurs” dinner held at the same time slot, but for the latter you had to pay extra, and I’m guessing most conference attendees opted for the dinner I went to.)
The conference dinner was at the Queensland Gallery of Modern Art, built just a few blocks away from the conference venue. I didn’t know what a “cocktail-style dinner” meant, so I was initially worried that the event was going to be a sit-down dinner with lots of tables, and that I would be sitting by myself or with some random strangers with foreign accents.
My concerns were alleviated by seeing all the open space by the entrance:
 The start of the dinner, before we were allowed inside.
The start of the dinner, before we were allowed inside.
I like cocktail-style dinners since it means I can move around quickly in case I get bored or trapped in a conversation with someone who I can’t understand — it’s best to cut ties and walk away politely if it’s clear that communication will not work out.
Here was what the crowd looked like at dinner. These are pictures of the outside areas, but there was also considerable space inside the building.


The lines were very long, and that’s probably my only criticism for the night. There were a few staff members who walked out with food for us to pick, and I think we needed more of those. The long lines notwithstanding, the food and drinks were really good, so I don’t want to take too much away from the event — it was far more impressive than what I had imagined for a conference dinner.
I would also be remiss if I didn’t mention that there was some impressive art in the museum. (No food and drink allowed in these areas!)
 There was some nice art!
There was some nice art!
I stayed for an hour and a half and then headed back to my hotel room.
International Conference on Robotics and Automation (ICRA) 2018, Day 2 of 5
The second day started out much like the first one. I went for a run, this time in the opposite direction as I did yesterday to explore a different part of the bay. I ran for a few miles, then went back to the hotel to get ready for the conference. This time, I skipped the hotel’s breakfast, since I wanted to save money and I figured the conference would give us a heaping of food today, as they did yesterday (I was right).
After some customary opening remarks, we had the first plenary talk. Just to be clear, ICRA has two main talk styles:
-
Plenary talks are each one hour, held from the 9:00am to 10:00am slots on Tuesday, Wednesday, and Thursday. These take place in the largest room, the Great Hall, and are designed to be less about the technical details and more about engaging everyone in the conference.
-
Keynote talks are each a half-hour, held from 10:00am to 10:30am and then later from 2:00pm to 2:30pm on Tuesday, Wednesday, and Thursday. At these time slots, three keynotes are provided at any given time, so you have to pick which one you want to be in. These are still designed to be less technical than most academic talks, but more technical and specialized than the plenary talks.
Professor and entrepreneur Rodney Brooks was scheduled to give the first plenary talk, and in many ways he is an ideal speaker. Brooks is widely regarded in the field of robotics and AI, with papers galore. He’s also an entrepreneur, having founded iRobot and Rethink Robotics. I’ll refer you to his website so that you can feel inadequate.
The other reason why Brooks must have been invited as a speaker is that he’s a native Australian (Peter Corke emphasized: “with an Australian passport!”), and 2018 is the first year that ICRA has been held in Australia. (Though, having said that, I wonder why they didn’t invite my advisor, John Canny, who like Brooks is also Australian — in fact, Canny is also from the Adelaide area. Of course, with only three plenaries, it would look too much like “home cooking” with two Australians speaking …)
Brooks gave an engaging, high-level talk on some of the challenges that we face today in robotics applied to the real world. He talked about demographics, climate change (see next image), and issues with self-driving cars deployed to the real world. There was also an entertaining rant about the state of modern Human-Robot Interaction research, since we’re using Amazon Mechanical Turk (ugh) and still relying on dumb-ass \(p\)-values (ugh ugh).
 Professor Rodney Brooks providing information regarding some climate change
effects.
Professor Rodney Brooks providing information regarding some climate change
effects.
After Brooks’ talk, we had a excellent keynote on machine learning and robotics by Toronto professor Angela Schoellig. I didn’t take too many pictures for this one since this seemed to be a different flavor of machine learning and robotics than I’m used to, but I might investigate some of her papers later.
Then we had the “morning tea” (or more accurately: tea and coffee and pastries and fruits) plus the morning poster session held simultaneously, in the same room as the welcome reception from last night. This was the first of six major poster sessions (morning and afternoon for each of Tuesday, Wednesday, and Thursday). It consisted of several “pods” that you can see here:
 The pods that were set up in the poster session.
The pods that were set up in the poster session.
I think the arrangement seems interesting, and is different from the usual straight aisles that we see in poster sessions. The pods make it easier to see which papers are related to each other since all one has to do is circle the corresponding pod. They might also be more space-efficient.
The food at the poster session was plentiful:
 The catering services in the morning tea session.
The catering services in the morning tea session.
It again wasn’t the standard kind of food you’d expect at your standard American hotel, reflecting both the diversity of food in Australia and also the amount of money that ICRA has due to sponsors and high registration fees. Oh, and the silly surcharge for extra pages in papers.
Ironically, the coffee and hot water stations appeared to be frequently empty or close to empty, prompting one of the sign language interpreters to argue that this was the reverse of last night, in which we had far too easy access to lots of drinks, but not much access to food.
Closer to noon, while the poster session was still going on — though I think most attendees stated to tire of walking around the pods — the employees brought out some lunch-style food.
 The food scene after the convention employees brought lunch.
The food scene after the convention employees brought lunch.
All of this was happening in half of the gigantic exhibition area. The other half had industry sponsor booths, like in the welcome reception from last night. You can see a few of them in the background of the above photo.
I took a break to relax and read a research paper since my legs were tired, but by 2:00pm, another one of the day’s highlights occurred: Professor Ken Goldberg’s keynote talk on grasping and experiment reproducibility:
 Professor Ken Goldberg's call for reproducibility in his excellent afternoon
keynote.
Professor Ken Goldberg's call for reproducibility in his excellent afternoon
keynote.
It was a terrific talk, and I hope that people will also start putting failure cases in papers. I will remember this, though I think I am only brave enough to put failure cases in appendices, and not the main page-constrained portion of my papers.
After Ken’s talk, there was another poster session with even more food, but frankly, I was so full and a bit weary of constantly walking around, so I mostly just said hi to a few people I knew and then went back to the hotel. There was a brief Nvidia-hosted reception that I attended to get some free food and wine, but I did not stay very long since I did not know anyone else.
Before going to sleep, I handled some administration with my schedule. I tried to reassure the person who was handling the sign language accommodation that, for the poster sessions, it is not necessary to have two or more interpreters since I spend the time mostly wandering around and taking pictures of interesting papers. It’s impossible to deeply understand a paper just by reading a poster and talking with the author, so I take pictures and then follow-up by reading as needed.
I also asked her to cancel the remaining Deaf/Hearing Interpreter (DI/HI) appointments since those were simply too difficult for me to understand and to benefit (see my previous post for what these entail). To be fair, the other “normal” interpreting services were not that beneficial, but I could at least understand perhaps 10-30% of the content in “broken” fashion. But for DI/HI, I simply don’t think it’s helpful to have spoken English translated to Australian sign language, and then translated to American/English sign language. I felt bad about canceling since it wasn’t the fault of the Deaf/Hearing Interpreter team, but at the same time I wanted to be honest about how I was feeling about the interpreting services.
International Conference on Robotics and Automation (ICRA) 2018, Day 1 of 5
Due to my clever sleep schedule, I was able to wake up at 5:00am and feel refreshed. As I complained in my previous blog post, the hotel I was at lacks a fitness center, forcing me to go outside and run since I cannot for the life of me live a few days without doing something to improve my physical fitness.
I killed some time by reviewing details of the conference, then ran outside once the sun was rising. I ran on the bridge that crosses the river and was able to reach the conference location. It is close to a park, which has a splendid display of “BRISBANE” as shown here:
 A nice view of Brisbane's sunrise.
A nice view of Brisbane's sunrise.
After running, I prepared for the conference. I walked over and saw this where we were supposed to register:
 The line for registration on Monday morning.
The line for registration on Monday morning.
This picture doesn’t do justice in showing ICRA’s popularity. There were a lot of attendees here.
But first, I had to meet my sign language interpreters! A few comments:
- I decided to use sign language interpreting services rather than captioning. I have no idea if this will be better but it’s honestly hard to think about how it can be worse than the captioning from UAI 2017.
- Despite how Australia and America are both English-speaking countries, the sign language used there (“Auslan”) is not the same as the one used in America.
- Thankfully, Berkeley’s DSP found an international interpreting agency which could try and find interpreters familiar with American signing. They hired one who specialized in ASL and who has lived in both Australia and the US, making him an ideal choice. The other interpreters specialized in different sign languages or International Sign.
- There was a “Deaf Interpreter/Hearing Interpreter” team. Essentially, this means having a deaf person who knows multiple sign languages (e.g., ASL and Auslan). That deaf interpreter is the one who signs for me, but he/she actually looks at a hearing interpreter who can interpret in one of the sign languages that both of them know (e.g., Auslan) but which I don’t. Thus, the translation would be: spoken English, to Auslan, to American signing. The reason for this is obvious, since in Australia, most interpreters know Auslan, but not ASL. I wouldn’t see this team until the second day of the conference, but the experience turned out to be highly unwieldy and wasn’t beneficial, so I asked to discontinue the service.
- All of the interpreting services were obtained after a four month process of Berkeley’s DSP searching for an international interpreting agency and then booking them for this conference. Despite the long notice, some of the schedule was still in flux and incomplete at the conference start date, so it goes to show that even four months might not be enough to get things booked perfectly. To be fair, it’s more like two or three months, since conference schedules aren’t normally released until a month or so after paper decisions come out. That’s one of my complaints about academic conferences, but I’ll save my ranting for a future blog post.
I met them and after customary introductions, it was soon 9:00am, when the first set of tutorials and workshops began. It seemed to be structured much like UAI 2017, in that there are workshops and tutorials on the first and last days, while the “main conference” lies in between. For us, this meant Monday and Friday were for the workshops/tutorials.
There were several full-day and half-day sessions offered on a variety of topics. I chose to attend the “Deep Learning for Robotics Perception” tutorial, because it had “Deep Learning” in the title.
 The morning tutorial on deep learning for robotics perception.
The morning tutorial on deep learning for robotics perception.
For this conference, I decided not to take detailed notes of every talk. I did that for UAI 2017, and it turned out to be of no use whatsoever as I never once looked at my Google Doc notes after the conference ended. Instead, my strategy now is to take pictures of any interesting slides, and then scan my photos after the conference to see if there’s anything worthwhile to follow-up.
The Deep Learning tutorial was largely on computer vision techniques that we might use for robotics. Much of the first half was basic knowledge to me. In the second half, it was a pleasure to see them mention the AUTOLAB’s work on Grasp-Quality Convolutional Neural Networks.
The interpreters had a massively challenging task with this tutorial. The one who knew ASL well was fine, but another one — who mentioned ASL was her fourth-best sign language — had to quit after just a few seconds (she apologized profusely) and be replaced. The third, who was also somewhat rusty with ASL, lasted his full time set, though admittedly his signing was awkward.
Fortunately, the one who had to quit early was able to recover and for her next 20-minute set, she was able to complete it, albeit with some anxiety coupled with unusual signs that I could tell were international or Auslan. Even with the American interpreter, it was still tremendously challenging for me to even follow the talk sentence-by-sentence, so I felt frustrated.
After lunch, we had the afternoon tutorials in a similar format. I attended the tutorial on visual servoing, featuring four 45-minute talks. The third was from UC Berkeley Professor Pieter Abbeel, who before beginning the talk found me in the crowd1 and congratulated me for making the BAIR blog a success.
You can imagine what his actual talk must have looked like: a packed, full room of amazed attendees trying to absorb as much of Pieter’s rapid-fire presentation as possible. I felt sorry for the person who had to present after Pieter, since about 80% of people the room left after Pieter finished his talk.
The sign language situation in the afternoon tutorials wasn’t much better than that of the morning tutorials, unfortunately. The presentation I understood the most in the afternoon was, surprise surprise, Pieter’s, but that’s because I had already read almost all of the corresponding research papers.
Later in the evening, we all gathered in the Great Hall, the largest room in the exhibition, for some opening remarks from the conference organizer. Before that, we had one of the more interesting conference events: a performance by indigenous Australians. To put a long story short, in Brisbane it’s common (according to my sign language interpreter) to begin large events by allowing indigenous Australians to perform some demonstration. This is a sign of respect for how these people inhabited Australia for many thousands of years.
For the show, several shirtless men with paint on them played music and danced. They rubbed wood with some other device and created some smoke and fire. Perhaps they got this cleared through the building’s security? I hope so. I took a photo of their performance, which you see below. Unfortunately it’s not the one with the smoke and fire.
 Native Australians giving us a show.
Native Australians giving us a show.
I don’t know if anyone else felt this way, but does it feel awkward seeing “natives” (whether Australian or American) wearing almost nothing while “privileged Asians and Whites” like me sit in the audience wearing business attire with our mandatory iPhones and Macbook Pro laptops in hand? Please don’t get me wrong: I fully respect and applaud the conference organizers and the city of Brisbane as a whole for encouraging this type of respect; I just wonder if there are perhaps better ways to do this. It’s an open question, I think, and no, ignoring history in America-style fashion is not a desirable alternative.
After the natives gave their show, to which they received rousing applause, the conference chair (Professor Peter Corke) provided some welcoming remarks and then conference statistics such as the ones shown in the following photo:
 Some statistics from conference chair Peter Corke.
Some statistics from conference chair Peter Corke.
There are lots of papers at ICRA! Here are a few relevant statistics from this and other slides (not shown in this blog post):
- The acceptance rate was 40%, resulting in 1052 papers accepted. That’s … a lot! Remember, at least one author of each paper is supposed to attend the conference, but in reality several often attend, along with industry sponsors and so forth, so the number of attendees is surely much higher than 1052 even when accounting for how several researchers can first-author multiple ICRA papers.
- Papers with authors from Venezuela had a 100% paper acceptance rate. I guess it’s good to find the positives in Venezuela, given the country’s recent free-fall, which won’t be mitigated by their sham election.
- The 2018 edition of ICRA broke the record of the number of paper submissions with 2586. The previous high was from 2016, which had around 2350 paper submissions.
- The United States had the highest number of papers submitted by country, besting the next set of countries which were China, Germany, and France. When you scale it by a country’s population, Singapore comes first (obviously!), followed by Switzerland, Australia (woo hoo, home team!!), Denmark, and Sweden. It’s unclear what these statistics tracked if authors of papers were based in different countries.
After this, we all went over to the welcome reception.
The first thing I noticed: wow, this is going to be noisy and crowded. At least I would have a sign language interpreter who would tag along with me, which despite being awkward from a social perspective is probably the best I can hope for.
The second thing I noticed: wow, there are lots of booths that provide wine and beer. Here’s one of many:
 One of many drinking booths in the welcome reception on Monday night.
One of many drinking booths in the welcome reception on Monday night.
To satisfy our need for food, several convention employees would walk around with some finger food in their large plates. I learned from one of the sign language interpreters who was tagging along with me that one of the food samplings offered was a kangaroo dish. Apparently, kangaroo is a popular meat item in Australia.
It is also quite tasty.
There were a large number of booths for ICRA sponsors, various robotics competitions, or other demonstrations. For instance, here’s one of the many robotics demonstrations, this time for “field robotics,” I suppose:
 One of many robotics booths set up in the welcome reception.
One of many robotics booths set up in the welcome reception.
And it wouldn’t be a (well-funded) Australian conference if we didn’t get to pet some animals. There were snakes and wombats (see below image) for us to touch:
 We could pet a wombat in the welcome reception (plus snakes and other animals).
We could pet a wombat in the welcome reception (plus snakes and other animals).
I’ll tell you this: ICRA does not skimp on putting on a show. There was a lot to process, and unusually for me, I fell asleep extremely quickly once I got back to my hotel room.
-
Not that it was a challenging task, since I was sitting in the front row and he’s seen the sign language interpreters at Berkeley many times. ↩
Prelude to ICRA 2018, Day 0 of 5
On Friday, May 18, I bade farewell to my apartment and my work office to go to San Francisco International Airport (SFO). Why? I was en route to ICRA 2018, the premier conference on robotics and — I believe — its largest in terms of number of papers, conference attendees, and the sheer content offered in the form of various tutorials, workshops, and sponsor events.
For travel, I booked an Air Canada round trip from San Francisco to Vancouver to Brisbane. Yes, I had to go north and then go south …. there unfortunately weren’t any direct flights from San Francisco to Brisbane during my time frame (San Francisco to Sydney is a more popular route). But I didn’t mind, as I could finally stop using United Airlines.
As usual, I got to the airport early, and then hiked over to the International Terminal. At SFO, I’m most familiar with Terminal 3 (United) and the International Terminal (for international travel) and for the latter, my favorite place to eat is Napa Farms Market, which embodies the essence of San Francisco cuisine. I had some excellent pork which was cut in-house, and cauliflower rice (yeah, see what I said about SF?).
 The SFO Napa Farms Market.
The SFO Napa Farms Market.
Incidentally, for Terminal 3 dining, I highly recommend Yankee Pier and their fish dishes.
My original plan was to pass security at around 2:00pm (which I did), then get a nice lunch and relax at the gate before my scheduled 4:20pm departure time. Unfortunately, while I was eating my Napa Farms Market dish, the waterfall of delays would begin. After three separate delays, I soon learned that my flight to Vancouver wouldn’t depart until after 7:10pm. At least, assuming there weren’t any more delays after that.
Ouch, apparently United isn’t the only airline that’s struggling to keep things on time. Maybe it’s a San Francisco issue; is there too much traffic? Or could it be due to the airport’s awkward location? It’s a bit oddly situated in the bay; it borders the inside of the bay, rather than the great Pacific Ocean.
The good news was twofold, though:
- I had a spare United Club pass that I could use to enter a club nearby. Fortunately, I could get into it since Air Canada is a Star Alliance partner airline.
- I had arranged for a five hour layover at Vancouver. My flight to Brisbane was scheduled to leave past 11:00pm.
This is why I aim for layovers of 5+ hours. It gives me an enormous buffer zone in case of any delays (and at SFO, I expect them) and I really don’t want to be late for academic conferences. Furthermore, the delays let me relax at airports for a longer time (assuming you have access to lounges!) which means I can string together a longer time block reading papers, reading books, and blogging, all while “fine dining” from a graduate student’s perspective.
I went to the United Club at Terminal 3 since that’s the largest one, and the lounge I’m most familiar with due to all my domestic United travels. I found a nice place to work (more accurately, read a research paper) and enjoyed some of the free food. I had a cappuccino, some cheese, crackers, fruit, and then enjoyed the standard complimentary house wine.
The good news was that the flight wasn’t delayed too much longer, but I’m not sure how much a 3+ delay reflects on Air Canada. Hopefully it’s a rare event. I boarded the flight and was soon in Vancouver.
The flight itself was non-eventful and I don’t remember what I did. I entered Vancouver, and saw some impressive artwork when I arrived.
 Vancouver artwork.
Vancouver artwork.
I couldn’t waste too much time, though. I had to pass through immigration. Remember, United States =/= Canada. Just be warned: if you are arriving at a country from a different country, even if it is en route to yet another country, you still have to go through immigration and customs and then the whole security pipeline after that. Fortunately, despite how the line looks long in the photo here, I got through it quickly. Note also the sign language interpreter video.
 Immigration at Vancouver.
Immigration at Vancouver.
I quickly hurried over to my gate and managed to get some decent snacks at one of the few places that was open at 10:30pm. The good news is that I informed my credit card company that I was traveling in Canada and Australia, so I could use my Credit Card. Pro tip for anyone who is traveling! You don’t want your card to be declined in the most awkward of moments.
And then … I boarded the fourteen hour and a half flight to Brisbane. Ouch! A few things about it:
- There was free wine, so apparently the Air Canada policy is the same as United for long-haul international flights. I wonder, though, why they offered the wine an hour after we departed (which was past midnight in Vancouver and SFO time) when it seemed like most passengers wanted to sleep. I thought they would have held off providing wine until perhaps the 10-hour mark of the flight, but I guess not. I drank some red wine and it was OK to me, though another conference attendee (who I met once I arrived in Brisbane) told me she hated it.
- The flight offered three meals (!!), whereas I thought only one (or at most two) would be provided. That’s nice of them. I had requested a “fruit plate” dish upon paying for the tickets a few months ago, because I do not trust meat on airline food. To my surprise, the airline respected the request and gave me two fruit plates. I would have had a third, except I declined the last one since I decided to try out the egg dish for the third one, but really, thank you Air Canada for honoring my food request! I’ll remember this for the future.
- The guy who was in my set of three seats (sitting by the window) had an Nvidia backpack, so I asked him about that, and it turned out he’s another conference attendee. I also saw a few Berkeley students who I recognized on the plane. I’m also pretty sure that other conference attendees could tell I was going because I was awkwardly dragging a bulky poster tube.
- I sat in the aisle seat. This is what you want for a 14.5-hour flight, because it makes it so much easier to leave the seat and walk around, which I had to do several times. Always get aisle seats for long flights!! Amazingly, as far as I could tell, the Nvidia guy sitting at the window never left his seat for the entire flight. I don’t think my body could handle that.
- The flight offered the usual fare of electronic entertainment (movies, card games, etc.) but I mostly slept (itself an accomplishment for me!) and read Enlightenment Now — more on the book later!
I arrived in Brisbane, then went through immigration again. But before that, I passed through the following duty-free store which was rather judiciously placed so that passengers had to pass it before getting to immigration and customs:
 The duty-free area we passed through upon arriving to Brisbane.
The duty-free area we passed through upon arriving to Brisbane.
There is a LOT of alcohol here! I enjoy some drinks now and then, but I wonder if society worldwide is putting way too much emphasis on booze.
Going through immigration was no problem at all. Getting my taxi driver to go to my hotel was a different matter. We had a testy conversation when I asked him to drive me to my hotel. I kept asking him to repeat and repeat his question since I couldn’t understand what he was saying, but then I explicitly showed him the address which I had printed on a paper beforehand, and then he was fine. Yeah, lesson learned — just give them a written address and they’ll be fine. Fortunately, I made it to the hotel at 9:00am, but check-in wasn’t until 2:00pm (as expected), so I left my luggage there and decided to explore the surrounding Brisbane area.
ICRA this year is located at Brisbane Convention Centre which is in the South Bank Parklands. I could tell that there’s a LOT to do. One of John Canny’s students told me a few days ago that “there isn’t much to do in Brisbane” so I had to send a friendly rebuke to him via text message.
I wandered around before finding a place to eat breakfast (in Australian time) which was more accurately lunch for me. I had some spinach, tomatoes, poached eggs, zucchini bread, and chai tea:
 My lunch in the South Bank, Brisbane.
My lunch in the South Bank, Brisbane.
I’m not much of a poached egg person but it was great! And adding milk to the standard hot water and tea seems like an interesting combination that I’ll try out more frequently in the future.
I took a few more pictures of the South Bank. Here’s one which shows an artificial beach within the park on the left, with the real river on the right.
 The artificial beach (left) and South Bank river (right).
The artificial beach (left) and South Bank river (right).
Here’s a better view of the “beach”:
 A view of the "beach."
A view of the "beach."
There’s tons of great stuff here: playgrounds, more restaurants, more extensive beaches, some architectural and artistic pieces, and so forth. I can’t take pictures of everything, unfortunately, so please check out the South Bank website which should make you want to start booking some flights.
Just make sure you schedule your mandatory five-hour layover if SFO is part of your itinerary.
I wandered around a bit and found a nice place to relax:
 One of many places to relax in South Bank.
One of many places to relax in South Bank.
I sat on a bench and read, Enlightenment Now: The Case for Reason, Science, Humanism, and Progress. This is Bill Gates’ favorite book, and is close to being one of my favorites as well. I’ll blog about it later, but the main theme is that, despite what we may think of from the media and what politicians say, life has continued to be much better for humanity as a whole, and there is never any better time to live in the world than today. I think my trip to Brisbane epitomizes this:
- I can board a 14.5 hour flight to go from Canada to Vancouver and trust that the safety record will result in a safe landing.
- I can study robotics and AI, instead of engaging in backbreaking agriculture labor.
- I have the freedom to walk around safely and read books as I please, rather than constantly worry about warfare or repercussions for reading non-government sanctioned books.
- I have the ability to easily check in a hotel well in advance, to know that I will have a roof over my head.
- I can blog and share the news about this to friends and family around the world.
Pinker doesn’t ignore the obvious hardships that many people face nowadays, but he makes a strong case that we are not focusing enough on the positive trends (e.g., decline in worldwide extreme poverty) and, more importantly, what we can learn from them so that they continue rather than slide back.
I devoured Enlightenment Now for about an hour or two and took a break — it’s a 500-page book filled with dense endnotes — and toured more of the South Bank. Overall, the place is extremely impressive and great for tourists of all shapes and sizes. Here are some (undoubtedly imprecise and biased) tradeoffs between this and the Darling Harbor area that I went to for UAI 2017:
- Darling Harbor advantages: more high-end restaurants, better cruises, feels cleaner and wealthier
- South Bank advantages: a larger variety of events (many family-friendly), perhaps cheaper food, better running routes
The bottom line is that both areas are great and if I had to pick any place to visit, it would probably be the one that I haven’t been to the longest.
I then went back to my hotel at around 3pm, desperate to relax and shower. The hotel I was in, Ibis Brisbane, is one of the cheaper ones here, and it shows in what it provides. The WiFi is sketchy, the electrical outlets are located in awkward configurations, there is no moisturizing cream, only two large towels are offered, and there is no fitness center (really?!?!?!?!?!?!?!?!?).
It’s not as good as the hotel I stayed at in Sydney, but at least it’s a functioning hotel and I can stay here for six nights without issues.
I showered and went out to explore to get some sources of nutrition. I found a burger place and was going to eat quickly and head back to the hotel … when, as luck would have it, six other Berkeley students decided to come to the place as soon as I was about to leave. They generously allowed me to join their group. It’s a good thing I was wearing a “Berkeley Computer Science” jacket!
I followed them to their hotel, which was heads and shoulders better than mine. Their place was a full studio with a balcony, and the view was great:
 The view of the South Bank at night from high up.
The view of the South Bank at night from high up.
I stayed for a while, then walked back to my hotel. I slept early, reaping the benefits of judiciously drinking coffee and timing meals so that I can wake up early and feel refreshed for tomorrow.
Practicing ROS Programming
I am currently engaging in a self-directed, badly-needed crash course on ROS Programming. ROS (Robot Operating System) is commonly used for robotics programming and research, and is robot-agnostic so knowledge of ROS should generalize to different robot types. Yet even after publishing a robotics paper, I still didn’t feel like I understood how my ROS code was working under the hood since other students had done much of the lower-level stuff earlier. This blog post thus summarizes what I did to try and absorb ROS as fast as possible.
To start learning about ROS, it’s a good idea (indeed, perhaps mandatory) to take a look at the excellent ROS Wiki. ROS is summarized as:
ROS (Robot Operating System) provides libraries and tools to help software developers create robot applications. It provides hardware abstraction, device drivers, libraries, visualizers, message-passing, package management, and more. ROS is licensed under an open source, BSD license.
The ROS wiki is impressively rich and detailed. If you scroll down and click “Tutorials”, you will see (as of this writing) twenty for beginners, and eight for more advanced users. In addition, the Wiki offers a cornucopia of articles related to ROS libraries, guidelines, and so on.
It’s impossible to read all of this at once, so don’t! Stick with the beginner tutorials for now, and try and remember as much as you can. I recorded my notes in my GitHub repository for my “self-studying” here. (Incidentally, that repository is something I’m planning to greatly expand this summer with robotics and machine learning concepts.)
As always, it is faster to learn by doing and reading, rather than reading alone, so it is critical to run the code in the ROS tutorials. Unfortunately, the code they use involves manipulating a “Turtle Sim” robot. This is perhaps my biggest disappointment with the tutorials: the turtle is artificial and hard to relate to real robots. Of course, this is somewhat unavoidable if the Wiki (and ROS as a whole) wants to avoid providing favoritism to certain robots, so perhaps it’s not fair criticism, but I thought I’d bring it up anyway.
To alleviate the disconnect between a turtle and what I view as a “real robot,” it is critical to start running this on a real robot. But since real robots run on the order of many thousands of dollars and exhibit all the vagaries of what you would expect from complex, physical systems (wear and tear, battery drainage, breakdowns, etc.), I highly recommend that you start by using a simulator.
In the AUTOLAB, I have access to a Fetch and a Toyota HSR, both of which
provide a built-in simulator using Gazebo. This simulator is designed to
create a testing environment where I can move and adjust the robot in a variety
of ways, without having to deal with physical robots. The advantage of investing
time in testing the simulator is that the code one uses for that should
directly translate to the real, physical robot without any changes, apart from
adjusting the ROS_MASTER_URI environment variable.
Details on the simulator should be provided in the manuals that you get for the
robots. Once the simulator is installed (usually via sudo apt-get install)
and working, the next step is to figure out how to code. One way to do this is
to borrow someone’s existing code base and tweak it as desired.
For the Fetch, my favorite code base is the one used in the University of Washington’s robotics course. It is a highly readable, modular code base which provides a full-blown Python Fetch API with much of the stuff I need: arm movement, base movement, head movement, etc. On top of that, there’s a whole set of GitHub wiki pages which provides high-level descriptions of how ROS and other things work. When I was reading these — which was after I had done a bit of ROS programming — I was smiling and nodding frequently, as the tutorials had confirmed some of what I had assumed was happening.
The primary author of the code base and Wiki is Justin Huang, a PhD student with Professor Maya Cakmak. Justin, you are awesome!
I ended up taking bits and pieces from Justin’s code, and added a script for dealing with camera images. My GitHub code repository here contains the resulting code, and this is the main thing I used to learn ROS programming. I documented my progress in various README files in that repository, so if you’re just getting started with ROS, you might find it helpful.
Playing around with the Gazebo simulator, I was able to move the Fetch torso to its highest position and then assign the joint angles so that it’s gripper actually coincides with the base. Oops, heh, I suppose that’s a flaw with the simulator?
The amusing result when you command the Fetch's arm to point directly downards.
The gripper "cuts" through the base, which can't happen on the physical robot.
Weird physics notwithstanding, the Gazebo simulator has been a lifesaver for me in understanding ROS, since I can now see the outcome on a simulated version of the real robot. I hope to continue making progress in learning ROS this summer, and to use other tools (such as rviz and MoveIt) that could help accelerate my understanding.
I’m currently en route to the International Conference on Robotics and Automation (ICRA) 2018, which should provide me with another environment for massive learning on anything robotics. If you’re going to ICRA and would like to chat, please drop me a line.
Interpretable and Pedagogical Examples
In my last post, I discussed a paper on algorithmic teaching. I mentioned in the last paragraph that there was a related paper, Interpretable and Pedagogical Examples, that I’d be interested in reading in detail. I was able to do that sooner than expected, so naturally, I decided to blog about it. A few months ago, OpenAI had a blog post discussing the contribution and ramifications of the paper, so I’m hoping to focus more on stuff they didn’t cover to act as a complement.
This paper is currently “only” on arXiv as it was rejected from ICLR 2018 — not due to lack of merit, it seems, but because the authors had their names on the manuscript, violating the double-blind nature of ICLR. I find it quite novel, though, and hope it finds a home somewhere in a conference.
There are several contributions of this over prior work in machine teaching and the like. First, they use deep recurrent neural networks for both the student and the teacher. Second and more importantly, they show that with iterative — not joint — training, the teacher will teach using an interpretable strategy that matches human intuition, and which furthermore is efficient in conveying concepts with the fewest possible samples (hence, “pedagogical”). This paper focus on teaching by example, but there are other ways to teach, such as using pairwise comparisons as in this other OpenAI paper.
How does this work? We consider a two-agent environment with a student \(\mathbf{S}\) and a teacher \(\mathbf{T}\), both of which are parameterized by deep recurrent neural networks \(\theta_{\mathbf{S}}\) and \(\theta_{\mathbf{T}}\), respectively. The setting also involves a set of concepts \(\mathcal{C}\) (e.g., different animals) and examples \(\mathcal{E}\) (e.g., images of those animals).
The student needs to map a series of \(K\) examples to concepts. At each time step \(t\), it guesses the concept \(\hat{c}\) that the teacher is trying to convey. The teacher, at each time step, takes in \(\hat{c}\) along with the concept it is trying to convey, and must output an example that (ideally) will make \(\hat{c}\) “closer” to \(c\). Examples may be continuous or discrete.
As usual, to train \(\mathbf{S}\) and \(\mathbf{T}\), it is necessary to devise an appropriate loss function \(\mathcal{L}\). In this paper, the authors chose to have \(\mathcal{L}\) be a function from \(\mathcal{C}\times \mathcal{C} \to \mathbb{R}\) where the input is the true concept and the student’s concept after the \(K\) examples. This is applied to both the student and teacher; they use the same loss function and are updated via gradient descent. Intuitively, this makes sense: both the student and teacher want the student to know the teacher’s concept. The loss is usually the \(L_2\) (continuous) or the cross-entropy (discrete).
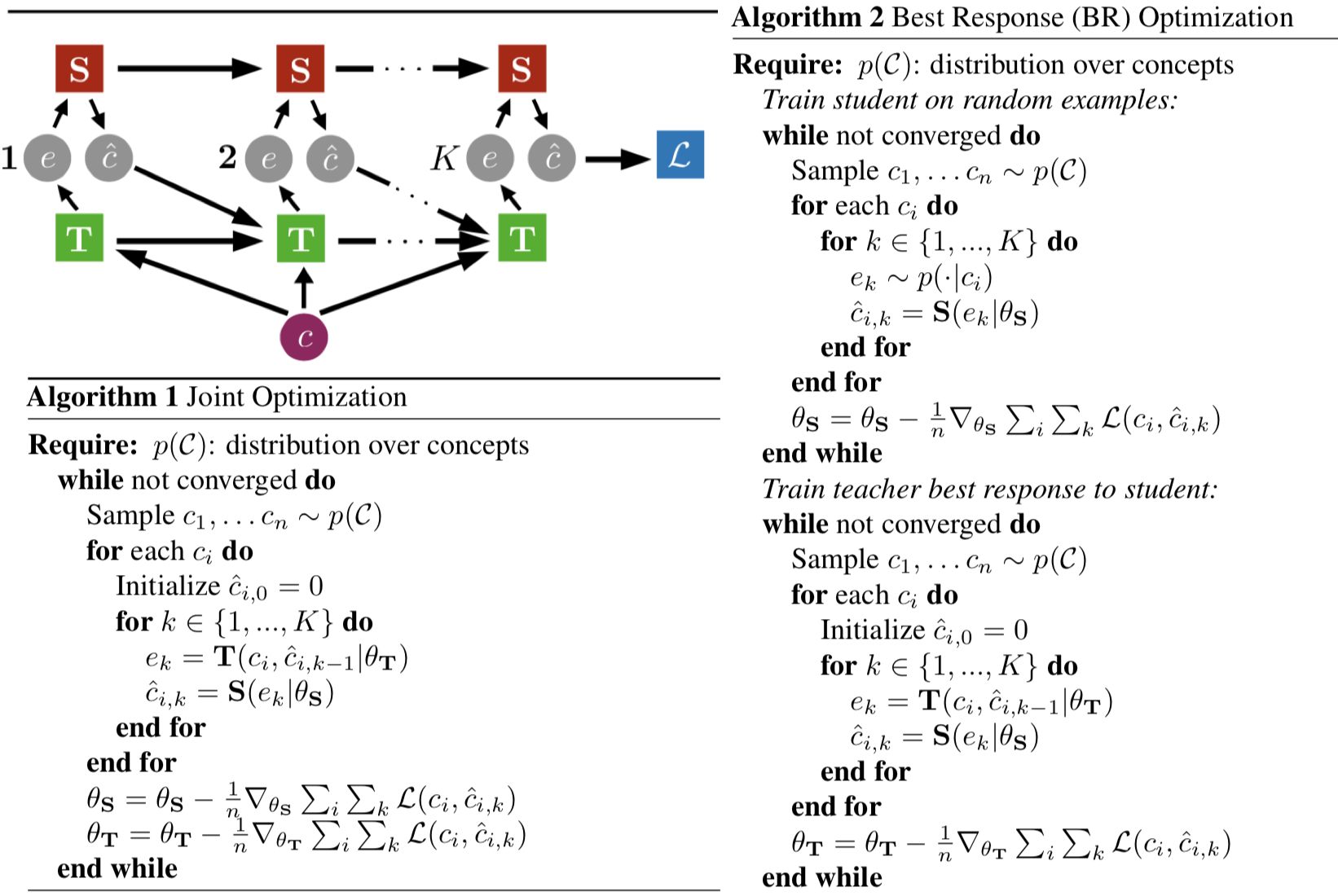
A collection of important aspects from the paper "Interpretable and Pedagogical
Examples." Top left: a visualization of the training process. Bottom left: joint
training baseline which should train the student but not create interpretable
teaching strategies. Right: iterative training procedure which should create
interpretable teaching strategies.
The figure above includes a visualization of the training process. It also includes both the joint and iterative training procedures. The student’s function is written as \(\mathbf{S}(e_k | \theta_{\mathbf{S}})\), and this is what is used to produce the next concept. The authors don’t explicitly pass in the previous examples or the student’s previously predicted concepts (the latter of which would make this an “autoregressive” model) because, presumably, the recurrence means the hidden layers implicitly encode the essence of this prior information. A similar thing is seen with how one writes the teacher’s function: \(\mathbf{T}(c_i, \hat{c}_{i,k-1} | \theta_{\mathbf{T}})\).
The authors argue that joint training means the teacher and student will “collude” and produce un-interpretable teaching, while iterative training lets them obtain interpretable teaching strategies. Why? They claim:
The intuition behind separating the optimization into two steps is that if \(\mathbf{S}\) learns an interpretable learning strategy in Step 1, then \(\mathbf{T}\) will be forced to learn an interpretable teaching strategy in Step 2. The reason we expect \(\mathbf{S}\) to learn an “interpretable” strategy in Step 1 is that it allows \(\mathbf{S}\) to learn a strategy that exploits the natural mapping between concepts and examples.
I think the above reason boils down to the fact that the teacher “knows” the true concepts \(c_1,\ldots,c_n\) in the minibatch of concepts above, and those are fixed throughout the student’s training portion. Of course, this would certainly be easier to understand after implementing it in code!
The experimental results are impressive and cover a wide range of scenarios:
-
Rule-Based: this is the “rectangle game” from cognitive science, where teachers provide points within a rectangle, and the student must guess the boundary. The intuitive teaching strategy would be to provide two points at opposite corners.
-
Probabilistic: the teacher must teach a bimodal mixture of Gaussians distribution, and the intuitive strategy is to provide points at the two modes (I assume, based on the relative weights of the two Gaussians).
-
Boolean: how does the teacher teach an object property, when objects may have multiple properties? The intuitive strategy is to provide two points where, of all the properties in the provided/original dataset, the only one that the two have in common is what the teacher is teaching.
-
Hierarchical: how does a teacher teach a hierarchy of concepts? The teacher learns the intuitive strategy of picking two examples whose lowest common ancestor is the concept node. Here, the authors use images from a “subtree” of ImageNet and use a pre-trained Res-Net to cut the size of all images to be vectors in \(\mathbb{R}^{2048}\).
For the first three above, the loss is \(\mathcal{L}(c,\hat{c}) = \|c-\hat{c}\|_2^2\), whereas the fourth problem setting uses the cross entropy.
There is also evaluation that involves human subjects, which is the second definition of “interpretability” the authors invoke: how effective is \(\mathbf{T}\)’s strategy at teaching humans? They do this using the probabilistic and rule-based experiments.
Overall, this paper is enjoyable to read, and the criticism that I have is likely beyond the scope that any one paper can cover. One possible exception: understanding the neural network architecture and training. The architecture, for instance, is not specified anywhere. Furthermore, some of the training seemed excessively hand-tuned. For example, the authors tend to train using \(X\) examples for \(K\) iterations but I wonder if these needed to be tuned.
I think I would like to try implementing this algorithm (using PyTorch to boot!), since it’s been a while since I’ve seriously tried replicating a prior result.
Algorithmic and Human Teaching of Sequential Decision Tasks
I spent much of the last few months preparing for the UC Berkeley EECS PhD qualifying exams, as you might have been able to tell by the style of my recent blogging (mostly paper notes) and my lack of blogging for the last few weeks. The good news is that I passed the qualifying exam. Like I did for my prelims, I wrote a “transcript” of the event. I will make it public in a future date. In this post, I discuss an interesting paper that I skimmed for my quals but didn’t have time to read in detail until after the fact: Algorithmic and Human Teaching of Sequential Decision Tasks, a 2012 AAAI paper by Maya Cakmak and Manuel Lopes.
This paper is interesting because it offers a different perspective on how to do imitation learning. Normally, in imitation learning, there is a fixed set of expert demonstrations \(D_{\rm expert} = \{\tau_1, \ldots, \tau_K \}\) where each demonstration \(\tau_i = (s_0,a_0,s_1\ldots,a_{N-1},s_N)\) is a sequence of states and actions. Then, a learner has to run some algorithm (classically, either behavior cloning or inverse reinforcement learning) to train a policy \(\pi\) that, when executed in the same environment, is as good as the expert.
In many cases, however, it makes sense that the teacher can select the most informative demonstrations for the student to learn a task. This paper thus falls under the realm of Active Teaching. This is not to be confused with Active Learning, as they clarify here:
A closely related area for the work presented in this paper is Active Learning (AL) (Angluin 1988; Settles 2010). The goal of AL, like in AT, is to reduce the number of demonstrations needed to train an agent. AL gives the learner control of what examples it is going to learn from, thereby steering the teacher’s input towards useful examples. In many cases, a teacher that chooses examples optimally will teach a concept significantly faster than an active learner choosing its own examples (Goldman and Kearns 1995).
This paper sets up the student to internally run inverse reinforcement learning (IRL), and follows prior work in assuming that the value function can be written as:
\[\begin{align*} V^{\pi}(s) \;&{\overset{(i)}=}\; \mathbb{E}_{\pi, s}\left[ \sum_{t=0}^\infty \gamma^t R(s_t)\right] \\ &{\overset{(ii)}=}\; \mathbb{E}_{\pi, s}\left[ \sum_{t=0}^\infty \gamma^t \sum_{i=1}^k w_i f_i(s_t) \right] \\ &{\overset{(iii)}=}\; \sum_{i=1}^k w_i \cdot \mathbb{E}_{\pi, s}\left[ \sum_{t=0}^\infty \gamma^t f_i(s_t)\right] \\ &{\overset{(iv)}=}\; \bar{w}^T \bar{\mu}_{\pi,s} \end{align*}\]where in (i) I applied the definition of a value function when following policy \(\pi\) (for notational simplicity, when I write a state under the expectation, like \(\mathbb{E}_s\), that means the expectation assumes we start at state \(s\)), in (ii) I substituted the reward function by assuming it is a linear combination of \(k\) features, in (iii) I re-arranged, and finally in (iv) I simplified in vector form using new notation.
We can augment the \(\bar{\mu}\) notation to also have the initial action that was chosen, as in \(s_a\). Then, using the fact that the IRL agent assumes that: “if the teacher chooses action \(a\) in state \(s\), then \(a\) must be at least as good as all the other available actions in \(s\)”, we have the following set of constraints from the demonstration data \(D\) consisting of all trajectories:
\[\forall (s,a) \in D, \forall b, \quad \bar{w}^T(\bar{\mu}_{\pi,s_a}-\bar{\mu}_{\pi,s_b}) \ge 0\]The paper’s main technical contribution is as follows. They argue that the above set of (half-space) constraints results in a subspace \(c(D)\) that contains the true weight vector, which is equivalent to obtaining the true reward function assuming we know the features. The weights are assumed to be bounded into some hypercube, \(-M_w < \bar{w} < M_w\). By sampling \(N\) different weight vectors \(\bar{w}_i\) within that hypercube, they can check the percentage of sampled weights that lie within that true subspace with this (indirect) metric:
\[G(D) = -\frac{1}{N}\sum_{i=1}^N \mathbb{1}\{\bar{w}_i \in c(D)\}\]Mathematically their problem is to find the set of demonstrations \(D\) that maximizes \(G(D)\), because if that value is larger, then the sampled weights are more likely to satisfy all the constraints, meaning that it has the property of representing the true reward function.
Note carefully: we’re allowed to change \(D\), the demonstration set, but we can’t change the way the weights are sampled: they have to be sampled from a fixed hypercube.
Their algorithm is simple: do a greedy approximation. First, select a starting state. Then, select the demonstration \(\tau_j\) that increases the current \(G( \{D \cup \tau_j \} )\) value the most. Repeat until \(G(D)\) is high enough.
For experiments, the paper relies on two sets of Grid-World mazes, shown below:
The two grid-worlds used in the paper.
Each of these domains has three features, and furthermore, only one is “active” at a given square in the map, so the vectors are all one-hot. Both domains have two tasks (hence, there are four tasks total), each of which is specified by a particular value of the feature weights. This is the same as specifying a reward function, so the optimal path for an agent may vary.
The paper argues that their algorithm results in the most informative demonstration in the teacher’s set. For the first maze, only one demonstration is necessary to convey each of the two tasks offered: for the second, only two are needed for the two tasks.
From observing example outcomes of the optimal teaching algorithm we get a better intuition about what constitutes an informative demonstration for the learner. A good teacher must show the range of important decision points that are relevant for the task. The most informative trajectories are the ones where the demonstrator makes rational choices among different alternatives, as opposed to those where all possible choices would result in the same behavior.
That the paper’s experiments involve these hand-designed mazes is probably one of the main weaknesses. There’s no way this could extend to high dimensions, when sampling from a hypercube (even if it’s “targeted” in some way, and not sampled naively) would never result in a weight vector that satisfies all the IRL constraints.
To conclude, this AAAI paper, though short and limited in some ways, provided me with a new way of thinking about imitation learning with an active teacher.
Out of curiosity about follow-up, I looked at the Google Scholar of papers that have cited this. Some interesting ones include:
- Cooperative Inverse Reinforcement Learning, NIPS 2016
- Showing versus Doing: Teaching by Demonstration, NIPS 2016
- Enabling Robots to Communicate Their Objectives, RSS 2017
I’m surprised, though, that one of my recent favorite papers, Interpretable and Pedagogical Examples, didn’t cite this one. That one is somewhat similar to this work except it uses more sophisticated Deep Neural Networks within an iterative training procedure, and has far more impressive experimental results. I hope to talk about that paper in a future blog post and to re-implement it in code.